
Wat is Burstiness in AI-Content en Hoe Beïnvloedt Het Detectie
Ontdek wat burstiness betekent in AI-gegenereerde inhoud, hoe het verschilt van menselijke schrijfpatronen en waarom het belangrijk is voor AI-detectie en conte...
8 min lezen
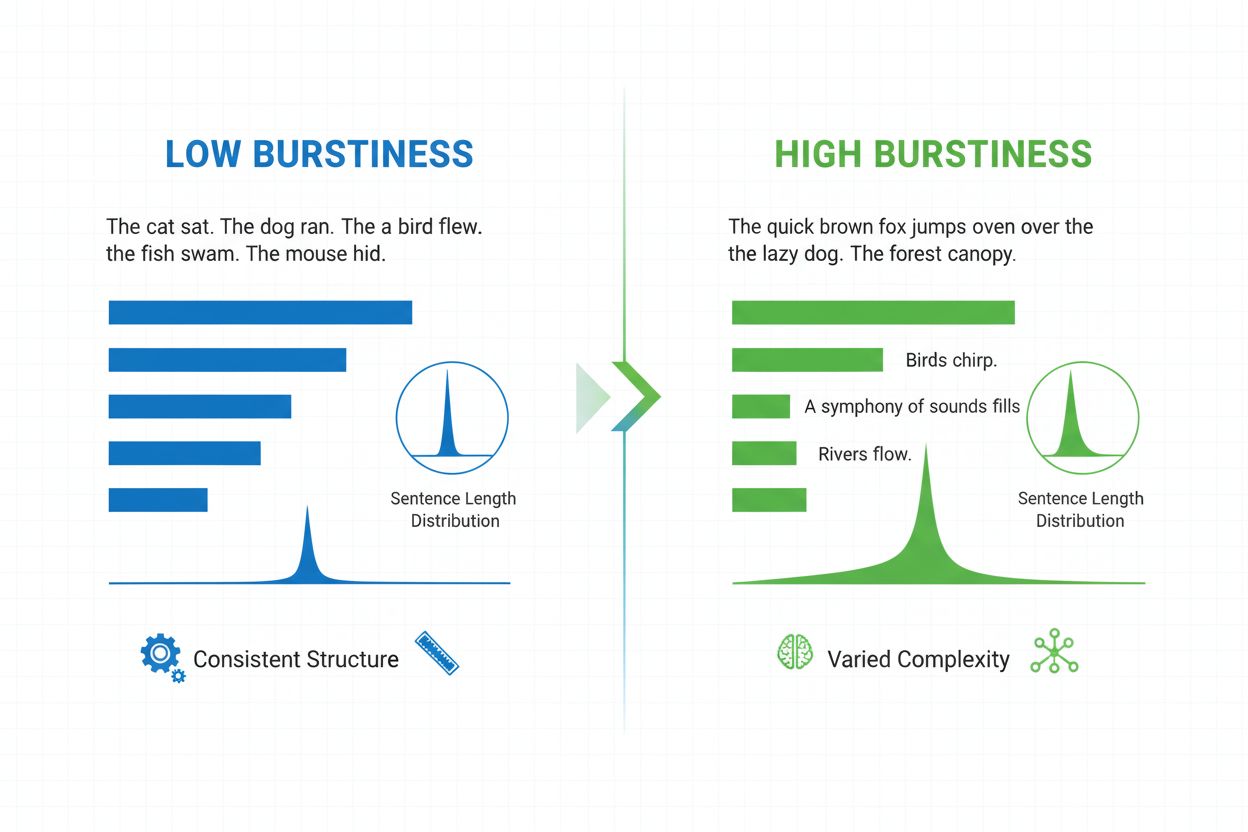
Burstiness is een taalkundige maatstaf die de variabiliteit van zinslengte, structuur en complexiteit binnen een document meet. Het kwantificeert hoezeer een schrijver afwisselt tussen korte, krachtige zinnen en langere, complexere zinnen, en dient als een belangrijke indicator bij AI-contentdetectie en taalanalyse.
Burstiness is een taalkundige maatstaf die de variabiliteit van zinslengte, structuur en complexiteit binnen een document meet. Het kwantificeert hoezeer een schrijver afwisselt tussen korte, krachtige zinnen en langere, complexere zinnen, en dient als een belangrijke indicator bij AI-contentdetectie en taalanalyse.
Burstiness is een kwantificeerbare taalkundige maatstaf die de variabiliteit en fluctuatie van zinslengte, structuur en complexiteit binnen een geschreven document of tekstfragment meet. De term is afkomstig van het concept van “uitbarstingen” van verschillende zinsstructuren—het afwisselen van korte, bondige zinnen en langere, meer ingewikkelde zinnen. In de context van natuurlijke taalverwerking en AI-contentdetectie dient burstiness als een kritische indicator of tekst door een mens is geschreven of door een artificieel intelligentiesysteem is gegenereerd. Menselijke schrijvers produceren van nature tekst met hoge burstiness omdat ze instinctief hun zinsbouw variëren op basis van nadruk, tempo en stilistische intentie. Omgekeerd vertoont AI-gegenereerde tekst doorgaans lage burstiness omdat taalmodellen zijn getraind op statistische patronen die consistentie en voorspelbaarheid bevorderen. Inzicht in burstiness is essentieel voor contentmakers, docenten, onderzoekers en organisaties die AI-gegenereerde inhoud monitoren op platforms zoals ChatGPT, Perplexity, Google AI Overviews en Claude.
Het concept burstiness is ontstaan uit onderzoek in computationele taalkunde en informatietheorie, waar wetenschappers probeerden de statistische eigenschappen van natuurlijke taal te kwantificeren. Vroeg werk in stylometrie—de statistische analyse van schrijfstijl—wees uit dat menselijk schrijven onderscheidende variatiepatronen vertoont die fundamenteel verschillen van machinaal gegenereerde tekst. Naarmate grote taalmodellen (LLM’s) in het begin van de jaren 2020 steeds geavanceerder werden, beseften onderzoekers dat burstiness, in combinatie met perplexity (een maatstaf voor woordvoorspelbaarheid), als betrouwbare indicator voor AI-gegenereerde inhoud kon dienen. Volgens onderzoek van QuillBot en academische instellingen gebruikt ongeveer 78% van de bedrijven nu AI-gedreven contentmonitoringtools die burstiness-analyse als onderdeel van hun detectie-algoritmen integreren. De Stanford University-studie uit 2023 naar TOEFL-essays toonde aan dat burstiness-gebaseerde detectiemethoden, hoewel nuttig, aanzienlijke beperkingen hebben—vooral wat betreft vals-positieven bij niet-moedertaalsprekers van het Engels. Dit onderzoek heeft geleid tot de ontwikkeling van geavanceerdere, gelaagde AI-detectiesystemen die burstiness combineren met andere taalkundige kenmerken, semantische samenhang en contextuele geschiktheid.
Burstiness wordt berekend door de statistische verdeling van zinslengtes en structurele patronen binnen een tekst te analyseren. De maatstaf kwantificeert variantie—oftewel hoeveel individuele zinnen afwijken van de gemiddelde zinslengte in een document. Een document met hoge burstiness bevat zinnen die sterk verschillen in lengte; een schrijver kan bijvoorbeeld een driewoordzin (“Zie je?”) laten volgen door een zin van vijfentwintig woorden met meerdere bijzinnen en ondergeschikte zinsdelen. Omgekeerd duidt lage burstiness erop dat de meeste zinnen rond een vergelijkbare lengte liggen, meestal tussen twaalf en achttien woorden, wat een eentonig ritme oplevert. De berekening omvat meerdere stappen: eerst meet het systeem de lengte van elke zin in woorden; vervolgens wordt de gemiddelde (gemiddelde) zinslengte berekend; daarna wordt de standaardafwijking berekend om te bepalen hoeveel individuele zinnen afwijken van dat gemiddelde. Een hogere standaardafwijking wijst op meer variatie en dus hogere burstiness. Moderne AI-detectoren zoals Winston AI en Pangram gebruiken geavanceerde algoritmen die niet alleen woorden tellen, maar ook syntactische complexiteit analyseren—de structurele opbouw van bijzinnen, woordgroepen en grammaticale elementen. Deze diepere analyse laat zien dat menselijke schrijvers diverse zinsstructuren gebruiken (eenvoudig, samengesteld, complex en samengesteld-complex) in onvoorspelbare patronen, terwijl AI-modellen de voorkeur geven aan bepaalde structurele sjablonen die vaak voorkomen in hun trainingsdata.
| Maatstaf | Burstiness | Perplexity | Meetfocus |
|---|---|---|---|
| Definitie | Variatie in zinslengte en structuur | Voorspelbaarheid van individuele woorden | Zin-niveau vs. woord-niveau |
| Menselijk Schrijven | Hoog (gevarieerde structuren) | Hoog (onvoorspelbare woorden) | Natuurlijk ritme en woordenschat |
| AI-gegenereerde Tekst | Laag (uniforme structuren) | Laag (voorspelbare woorden) | Statistische consistentie |
| Toepassing Detectie | Identificeert structurele eentonigheid | Herkent woordkeuzepatronen | Complementaire detectiemethoden |
| Vals-positief Risico | Hoger bij NT2-schrijvers | Hoger bij technisch/academisch schrijven | Beiden hebben beperkingen |
| Berekeningsmethode | Standaardafwijking van zinslengtes | Analyse van waarschijnlijkheidsverdeling | Verschillende wiskundige aanpakken |
| Betrouwbaarheid Alleen | Onvoldoende voor definitieve detectie | Onvoldoende voor definitieve detectie | Meest effectief in combinatie |
Grote taalmodellen zoals ChatGPT, Claude en Google Gemini worden getraind via een proces dat next-token prediction heet, waarbij het model leert het meest waarschijnlijke volgende woord te voorspellen gegeven een reeks woorden. Tijdens de training worden deze modellen expliciet geoptimaliseerd om perplexity op hun trainingsdatasets te minimaliseren, wat onbedoeld als bijeffect zorgt voor lage burstiness. Wanneer een model een bepaalde zinsstructuur herhaaldelijk in zijn trainingsdata tegenkomt, leert het die structuur met hoge waarschijnlijkheid te reproduceren, wat resulteert in consistente, voorspelbare zinslengtes. Onderzoek van Netus AI en Winston AI toont aan dat AI-modellen een onderscheidende stylometrische vingerafdruk vertonen, gekenmerkt door uniforme zinsopbouw, overmatig gebruik van verbindingswoorden (zoals “Bovendien”, “Daarom”, “Daarnaast”) en een voorkeur voor de lijdende vorm boven de bedrijvende vorm. Door de afhankelijkheid van waarschijnlijkheidsverdelingen kiezen modellen voor de meest voorkomende patronen uit hun trainingsdata, in plaats van het volledige spectrum aan zinsconstructies te verkennen. Dit creëert een paradox: hoe meer data een model krijgt, hoe meer het algemene patronen leert reproduceren, en hoe lager de burstiness wordt. Bovendien ontbreekt het AI-modellen aan spontaniteit en emotionele variatie die menselijk schrijven kenmerken—ze schrijven niet anders als ze enthousiast, gefrustreerd zijn of een punt willen benadrukken. In plaats daarvan behouden ze een consistente stijl die het statistische gemiddelde van hun trainingsdistributie weerspiegelt.
AI-detectieplatforms hebben burstiness-analyse geïntegreerd als kernonderdeel van hun detectie-algoritmen, met wisselend niveau van verfijning. Vroege detectiesystemen vertrouwden sterk op burstiness en perplexity als primaire maatstaven, maar onderzoek heeft aanzienlijke beperkingen van deze aanpak blootgelegd. Volgens Pangram Labs produceren detectors die gebaseerd zijn op perplexity en burstiness vals-positieven wanneer ze tekst analyseren uit de trainingsdatasets van taalmodellen—vooral de Amerikaanse Onafhankelijkheidsverklaring wordt vaak als AI-tekst aangemerkt omdat deze zo vaak in trainingsdata voorkomt dat het model deze tekst een uniforme, lage perplexity toekent. Moderne detectiesystemen zoals Winston AI en Pangram gebruiken nu hybride benaderingen die burstiness combineren met deep learning-modellen getraind op diverse voorbeelden van zowel menselijke als AI-gegenereerde teksten. Deze systemen analyseren meerdere taalkundige dimensies tegelijk: variatie in zinsstructuur, lexicale diversiteit (woordenschatrijkdom), interpunctiepatronen, contextuele samenhang en semantische afstemming. De integratie van burstiness in bredere detectiekaders heeft de nauwkeurigheid aanzienlijk verbeterd—Winston AI rapporteert 99,98% nauwkeurigheid in het onderscheiden van AI-gegenereerde van menselijk geschreven content door meerdere kenmerken te analyseren in plaats van alleen burstiness. Toch blijft de maatstaf waardevol als onderdeel van een allesomvattende detectiestrategie, vooral in combinatie met analyse van perplexity, stylometrische patronen en semantische consistentie.
De relatie tussen burstiness en leesbaarheid is goed gedocumenteerd in taalkundig onderzoek. De Flesch Reading Ease en de Flesch-Kincaid Grade Level scores, die de toegankelijkheid van tekst meten, correleren sterk met burstiness-patronen. Tekst met hogere burstiness behaalt doorgaans betere leesbaarheidsscores omdat variatie in zinslengte cognitieve vermoeidheid voorkomt en de aandacht van de lezer vasthoudt. Wanneer lezers een constant ritme van zinnen met vergelijkbare lengte tegenkomen, past hun brein zich aan aan een voorspelbaar patroon, wat kan leiden tot minder betrokkenheid en verminderde begripsvorming. Omgekeerd zorgt hoge burstiness voor een eb-en-vloed-effect dat de lezer mentaal betrokken houdt door de cognitieve belasting te variëren—korte zinnen bieden snelle, behapbare informatie, terwijl langere zinnen ruimte geven voor complexe ideeën en nuance. Onderzoek van Metrics Masters wijst uit dat hoge burstiness zorgt voor ongeveer 15-20% betere geheugenretentie in vergelijking met tekst met lage burstiness, omdat het gevarieerde ritme informatie effectiever in het langetermijngeheugen vastlegt. Dit principe geldt voor alle contenttypes: blogposts, academische artikelen, marketingteksten en technische documentatie profiteren van strategische burstiness. De relatie is echter niet lineair—overmatige burstiness die variatie boven duidelijkheid stelt, kan tekst juist staccato en moeilijk te volgen maken. De optimale aanpak is doelbewuste variatie, waarbij keuzes in zinsstructuur de betekenis en de communicatieve intentie van de schrijver dienen, in plaats van uitsluitend een maatstaf te verhogen.
Ondanks de brede toepassing in AI-detectiesystemen heeft burstiness-gebaseerde detectie aanzienlijke beperkingen die onderzoekers en praktijkmensen moeten begrijpen. Pangram Labs publiceerde uitgebreid onderzoek waarin vijf grote tekortkomingen worden beschreven: ten eerste wordt tekst uit AI-trainingsdatasets foutief geclassificeerd als AI-tekst omdat modellen geoptimaliseerd zijn om perplexity op trainingsdata te minimaliseren; ten tweede zijn burstiness-waarden afhankelijk van specifieke taalmodellen, waardoor verschillende modellen verschillende perplexity-profielen opleveren; ten derde maken gesloten commerciële modellen zoals ChatGPT geen tokenwaarschijnlijkheden openbaar, waardoor perplexity-berekening onmogelijk is; ten vierde worden niet-moedertaalsprekers van het Engels onevenredig vaak als AI-tekst aangemerkt vanwege hun meer uniforme zinsstructuren; en ten vijfde kunnen burstiness-gebaseerde detectors zichzelf niet iteratief verbeteren met extra data. De Stanford-studie uit 2023 naar TOEFL-essays vond dat ongeveer 26% van de niet-moedertaal Engelse teksten onterecht als AI-gegenereerd werd aangemerkt door perplexity- en burstiness-gebaseerde detectors, tegenover slechts 2% vals-positieven bij moedertaalsprekers. Deze bias roept serieuze ethische vragen op in het onderwijs waar AI-detectie wordt gebruikt om studentwerk te beoordelen. Daarnaast vertonen sjabloongedreven content in marketing, academisch schrijven en technische documentatie van nature lagere burstiness vanwege stijlrichtlijnen en structurele conventies, wat in die domeinen tot vals-positieven leidt. Deze beperkingen hebben geleid tot de ontwikkeling van geavanceerdere detectiebenaderingen die burstiness als één signaal onder velen behandelen in plaats van als doorslaggevend bewijs van AI-generatie.
Burstiness-patronen verschillen sterk per schrijfgenre en context, waarbij elk domein zijn eigen communicatieve doelen en verwachtingen van het publiek weerspiegelt. Academisch schrijven, vooral in bètavakken, vertoont doorgaans lagere burstiness omdat auteurs strikte stijlrichtlijnen volgen en consistente structuur gebruiken voor duidelijkheid en precisie. Juridische documenten, technische specificaties en wetenschappelijke artikelen geven allemaal prioriteit aan consistentie en voorspelbaarheid boven stilistische variatie, wat resulteert in van nature lagere burstiness-scores. Daarentegen tonen creatief schrijven, journalistiek en marketingteksten juist hoge burstiness omdat deze genres de betrokkenheid en emotionele impact van de lezer willen vergroten door variatie in tempo en ritme. Literatuur gebruikt met name dramatische schommelingen in zinslengte om nadruk, spanning en tempobeheersing te creëren. Zakelijke communicatie neemt een tussenpositie in—professionele e-mails en rapporten hanteren een matige burstiness om duidelijkheid te combineren met betrokkenheid. De Flesch-Kincaid Grade Level-maatstaf laat zien dat academisch schrijven voor hoger opgeleide doelgroepen vaak langere, complexere zinnen gebruikt, wat de burstiness lijkt te verlagen; echter, variatie in bijzinsstructuur en ondergeschikking zorgt alsnog voor betekenisvolle burstiness. Inzicht in deze contextuele variaties is cruciaal voor AI-detectiesystemen, die genrespecifieke schrijfconventies moeten herkennen om vals-positieven te vermijden. Een technische handleiding met uniform lange zinnen mag niet als AI-gegenereerd worden aangemerkt alleen omdat deze lage burstiness heeft—de lage burstiness weerspiegelt passende stijlkeuzes voor het genre, niet het bewijs van machinale generatie.
De toekomst van burstiness-analyse in AI-detectie beweegt richting geavanceerdere, contextbewuste benaderingen die de beperkingen van de maatstaf erkennen maar de inzichten benutten. Naarmate grote taalmodellen steeds geavanceerder worden, beginnen ze burstiness-variatie op te nemen in hun output, waardoor detectie uitsluitend op deze maatstaf minder betrouwbaar wordt. Onderzoekers ontwikkelen adaptieve detectiesystemen die burstiness combineren met semantische samenhang, feitelijke juistheid en contextuele geschiktheid. De opkomst van AI-humanisatietools die bewust burstiness en andere menselijke kenmerken verhogen, vormt een voortdurende wedloop tussen detectie- en ontwijkingstechnologieën. Experts voorspellen echter dat echt betrouwbare AI-detectie uiteindelijk zal afhangen van cryptografische verificatiemethoden en herkomsttracking in plaats van alleen taalanalyse. Voor contentmakers en organisaties is de strategische boodschap duidelijk: beschouw burstiness niet als een maatstaf om te manipuleren, maar ontwikkel authentieke, gevarieerde schrijfstijlen die van nature menselijke communicatiepatronen weerspiegelen. Het AmICited-monitoringsplatform markeert een nieuw tijdperk, waarbij wordt gevolgd hoe merken verschijnen in AI-gegenereerde antwoorden en de taalkundige kenmerken daarvan worden geanalyseerd. Naarmate AI-systemen steeds vaker content genereren en verspreiden, wordt inzicht in burstiness en aanverwante maatstaven steeds belangrijker voor het behouden van merk-authenticiteit, academische integriteit en het onderscheid tussen door mensen en door machines geschreven inhoud. De evolutie richting multi-signaaldetectie suggereert dat burstiness relevant blijft als onderdeel van uitgebreide AI-monitoringsystemen, ook al wordt de rol ervan genuanceerder en contextafhankelijker.
Burstiness en perplexity zijn complementaire maatstaven die worden gebruikt bij AI-detectie. Perplexity meet hoe voorspelbaar afzonderlijke woorden zijn binnen een tekst, terwijl burstiness de variatie in zinsstructuur en -lengte over een heel document meet. Menselijk schrijven vertoont doorgaans een hogere perplexity (meer onvoorspelbare woordkeuzes) en hogere burstiness (meer gevarieerde zinsstructuren), terwijl AI-gegenereerde tekst meestal lagere waarden voor beide kenmerken vertoont door de afhankelijkheid van statistische patronen uit trainingsdata.
Hoge burstiness creëert een ritmische stroom die de betrokkenheid en het begrip van de lezer vergroot. Wanneer schrijvers afwisselen tussen korte, krachtige zinnen en langere, complexe zinnen, blijft de interesse van de lezer behouden en wordt eentonigheid voorkomen. Onderzoek toont aan dat gevarieerde zinsstructuren het geheugen verbeteren en inhoud authentieker en meer conversatiegericht maken. Lage burstiness, gekenmerkt door uniforme zinslengtes, kan tekst robotachtig en moeilijk te volgen maken, wat zowel de leesbaarheid als de betrokkenheid vermindert.
Hoewel burstiness opzettelijk kan worden verhoogd door bewust te variëren in zinsstructuren, levert dit vaak onnatuurlijk klinkende tekst op die andere detectiemechanismen kan activeren. Moderne AI-detectoren analyseren meerdere taalkundige kenmerken naast burstiness, zoals semantische samenhang, contextuele geschiktheid en stylometrische patronen. Authentieke burstiness ontstaat vanzelf bij echt menselijk schrijven en weerspiegelt de unieke stem van de schrijver, terwijl geforceerde variatie meestal het organische karakter mist dat echte menselijke inhoud kenmerkt.
Niet-moedertaalsprekers van het Engels vertonen vaak lagere burstiness-scores omdat hun schrijfpatronen een beperktere woordenschat en eenvoudigere zinsconstructie weerspiegelen. Taalstudenten gebruiken doorgaans meer uniforme, voorspelbare zinsstructuren tijdens het verwerven van vaardigheid, waarbij ze complexe bijzinnen en gevarieerde syntactische patronen vermijden. Dit creëert een stylometrisch profiel dat lijkt op AI-gegenereerde tekst, wat leidt tot vals-positieve resultaten in AI-detectiesystemen. Onderzoek van Stanford University in 2023 naar TOEFL-essays bevestigde deze bias en wees op een belangrijke beperking van burstiness-gebaseerde detectiemethoden.
Grote taalmodellen worden getraind op enorme datasets waarbij ze leren het volgende woord te voorspellen op basis van statistische patronen. Tijdens de training worden deze modellen geoptimaliseerd om de perplexity op hun trainingsdata te minimaliseren, wat als neveneffect zorgt voor uniforme zinsstructuren en voorspelbare woordreeksen. Dit resulteert in consequent lage burstiness omdat de modellen tekst genereren door statistisch waarschijnlijke woordcombinaties te kiezen in plaats van de gevarieerde, spontane zinsconstructies die menselijk schrijven kenmerken. De afhankelijkheid van waarschijnlijkheidsverdelingen creëert een homogene stijl.
AmICited volgt hoe merken en domeinen verschijnen in AI-gegenereerde antwoorden op platforms zoals ChatGPT, Perplexity en Google AI Overviews. Inzicht in burstiness helpt het monitoringsysteem van AmICited om onderscheid te maken tussen authentieke, door mensen geschreven citaties en AI-gegenereerde inhoud waarin uw merk wordt genoemd. Door burstiness-patronen te analyseren samen met andere taalkundige kenmerken, biedt AmICited nauwkeurigere inzichten in de vraag of uw merk wordt genoemd in echt menselijk geschreven inhoud of in AI-gegenereerde antwoorden, zodat u uw merkreputatie beter kunt beheren.
Schrijvers kunnen burstiness organisch verbeteren door bewust te variëren in zinsconstructie, met behoud van duidelijkheid en doel. Technieken zijn onder andere het afwisselen van eenvoudige stellende zinnen en complexe zinnen met meerdere bijzinnen, het gebruik van retorische middelen zoals fragmenten en gedachtestreepjes voor nadruk, en het variëren van alinea-lengtes. De sleutel is dat de variatie de betekenis van de inhoud dient en niet alleen bestaat omwille van de variatie. Hardop lezen, verschillende schrijfstijlen bestuderen en bij het herschrijven letten op ritme, helpt om op natuurlijke wijze authentieke, boeiende tekst met hoge burstiness te creëren.
Begin met het volgen van hoe AI-chatbots uw merk vermelden op ChatGPT, Perplexity en andere platforms. Krijg bruikbare inzichten om uw AI-aanwezigheid te verbeteren.
Ontdek wat burstiness betekent in AI-gegenereerde inhoud, hoe het verschilt van menselijke schrijfpatronen en waarom het belangrijk is voor AI-detectie en conte...
Discussie binnen de community over burstiness in AI-inhouddetectie - wat het betekent, hoe het AI-zichtbaarheid beïnvloedt en of contentmakers hierop moeten opt...

Ontdek hoe vloeiendheidsoptimalisatie de zichtbaarheid van je content in AI-zoekresultaten verbetert. Leer schrijftips die AI-systemen helpen je content natuurl...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.