
Hvordan sikre at AI-crawlere ser alt innholdet ditt
Lær hvordan du gjør innholdet ditt synlig for AI-crawlere som ChatGPT, Perplexity og Googles AI. Oppdag tekniske krav, beste praksis og overvåkningsstrategier f...
11 min lesing
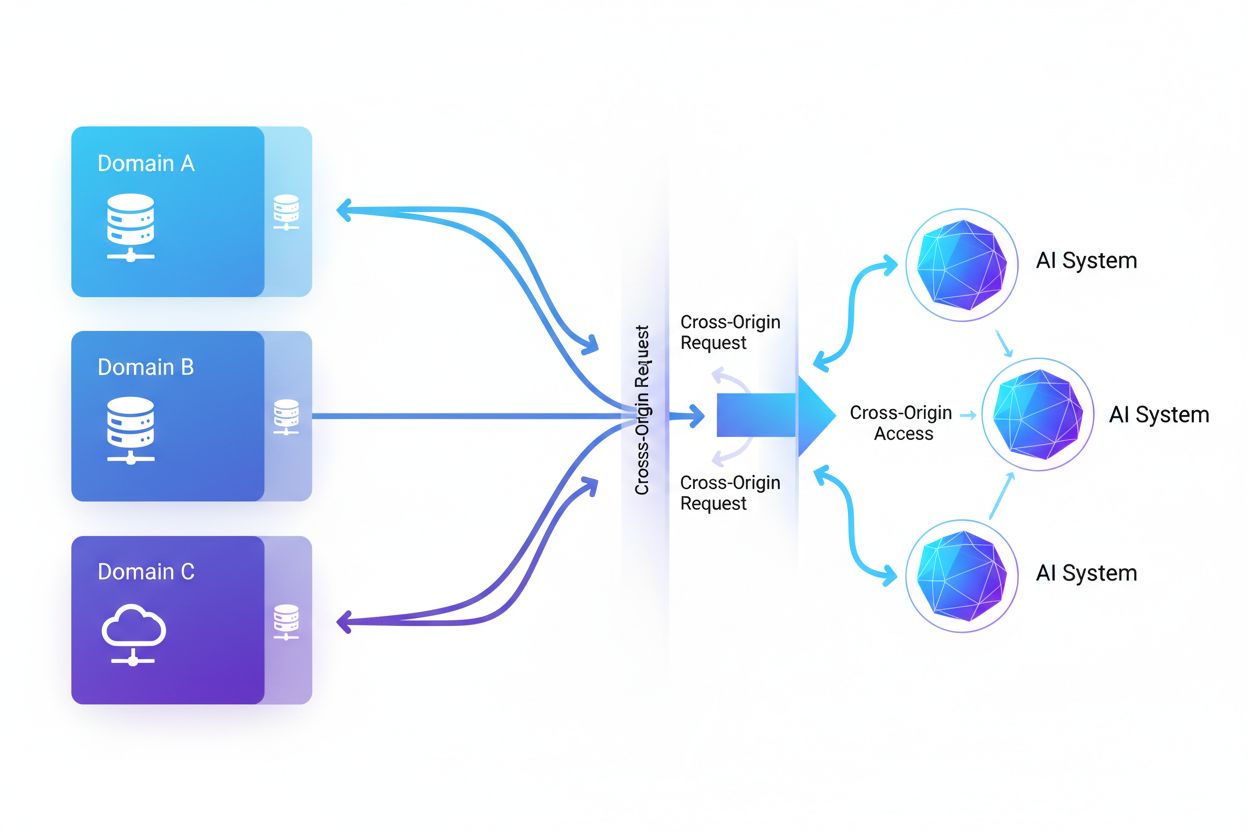
Cross-Origin AI Access refererer til muligheten kunstige intelligenssystemer og nettroboter har til å be om og hente innhold fra domener som er forskjellige fra deres opprinnelse, styrt av sikkerhetsmekanismer som CORS. Det omfatter hvordan AI-selskaper skalerer datainnsamling for å trene store språkmodeller, samtidig som de navigerer restriksjoner på tvers av domener. Å forstå dette konseptet er avgjørende for innholdsskapere og nettstedseiere for å beskytte immaterielle rettigheter og opprettholde kontroll over hvordan innholdet deres brukes av AI-systemer. Innsikt i aktivitet på tvers av domener hjelper til å skille mellom legitim AI-tilgang og uautorisert skraping.
Cross-Origin AI Access refererer til muligheten kunstige intelligenssystemer og nettroboter har til å be om og hente innhold fra domener som er forskjellige fra deres opprinnelse, styrt av sikkerhetsmekanismer som CORS. Det omfatter hvordan AI-selskaper skalerer datainnsamling for å trene store språkmodeller, samtidig som de navigerer restriksjoner på tvers av domener. Å forstå dette konseptet er avgjørende for innholdsskapere og nettstedseiere for å beskytte immaterielle rettigheter og opprettholde kontroll over hvordan innholdet deres brukes av AI-systemer. Innsikt i aktivitet på tvers av domener hjelper til å skille mellom legitim AI-tilgang og uautorisert skraping.
Cross-Origin AI Access refererer til muligheten kunstige intelligenssystemer og nettroboter har til å be om og hente innhold fra domener som er forskjellige fra deres opprinnelse, styrt av sikkerhetsmekanismer som Cross-Origin Resource Sharing (CORS). Etter hvert som AI-selskaper utvider datainnsamlingen for å trene store språkmodeller og andre AI-systemer, har det blitt avgjørende for innholdsskapere og nettstedseiere å forstå hvordan disse systemene navigerer restriksjoner på tvers av domener. Utfordringen ligger i å skille mellom legitim AI-tilgang for søkeindeksering og uautorisert skraping for modelltrening, noe som gjør innsikt i aktivitet på tvers av domener essensielt for å beskytte immaterielle rettigheter og opprettholde kontroll over hvordan innhold brukes.
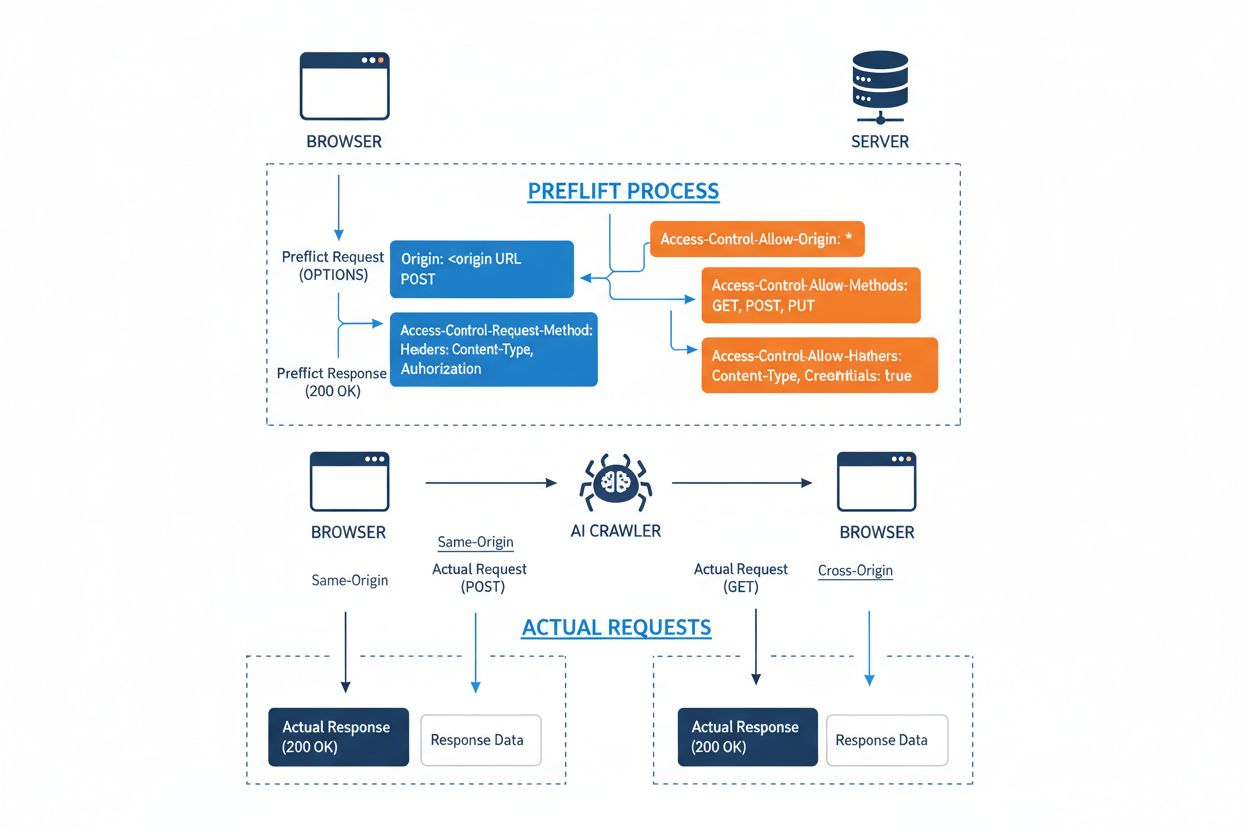
Cross-Origin Resource Sharing (CORS) er en sikkerhetsmekanisme basert på HTTP-headere som lar servere spesifisere hvilke opprinnelser (domener, skjemaer eller porter) som kan få tilgang til ressursene deres. Når en AI-robot eller annen klient forsøker å få tilgang til en ressurs fra en annen opprinnelse, initierer nettleseren eller klienten en preflight-forespørsel ved å bruke OPTIONS HTTP-metoden for å sjekke om serveren tillater den faktiske forespørselen. Serveren svarer med spesifikke CORS-headere som angir tilgangstillatelser, inkludert hvilke opprinnelser som er tillatt, hvilke HTTP-metoder som er tillatt, hvilke headere som kan inkluderes, og om legitimasjon som informasjonskapsler eller autentiseringstokener kan sendes med forespørselen.
| CORS-header | Formål |
|---|---|
Access-Control-Allow-Origin | Angir hvilke opprinnelser som kan få tilgang til ressursen (* for alle, eller spesifikke domener) |
Access-Control-Allow-Methods | Lister tillatte HTTP-metoder (GET, POST, PUT, DELETE, osv.) |
Access-Control-Allow-Headers | Definerer hvilke forespørselsheadere som er tillatt (Authorization, Content-Type, osv.) |
Access-Control-Allow-Credentials | Bestemmer om legitimasjon (informasjonskapsler, autentiseringstokener) kan inkluderes i forespørsler |
Access-Control-Max-Age | Angir hvor lenge preflight-svar kan caches (i sekunder) |
Access-Control-Expose-Headers | Lister responsheadere som klienter kan få tilgang til |
AI-roboter samhandler med CORS ved å respektere disse headerne når de er riktig konfigurert, selv om mange avanserte roboter forsøker å omgå disse restriksjonene ved å forfalske brukeragenter eller bruke proxynettverk. Effektiviteten til CORS som forsvar mot uautorisert AI-tilgang avhenger helt av korrekt serverkonfigurasjon og robotens vilje til å respektere restriksjonene—et kritisk skille som har blitt stadig viktigere ettersom AI-selskaper konkurrerer om treningsdata.
Landskapet for AI-roboter som får tilgang til nettet har ekspandert dramatisk, med flere store aktører som dominerer tilgangsmønstrene på tvers av domener. Ifølge Cloudflares analyse av nettverkstrafikk er de mest utbredte AI-robotene:
Disse robotene genererer milliarder av forespørsler hver måned, og noen som Bytespider og GPTBot får tilgang til mesteparten av internettets offentlig tilgjengelige innhold. Det enorme volumet og den aggressive naturen til denne aktiviteten har fått store plattformer som Reddit, Twitter/X, Stack Overflow og flere nyhetsorganisasjoner til å innføre blokkeringstiltak.
Feilkonfigurerte CORS-policyer skaper betydelige sikkerhetssårbarheter som AI-roboter kan utnytte for å få tilgang til sensitiv data uten autorisasjon. Når servere setter Access-Control-Allow-Origin: * uten riktig validering, tillater de utilsiktet enhver opprinnelse—inkludert ondsinnede AI-skrapere—å få tilgang til ressurser som burde vært begrenset. En spesielt farlig konfigurasjon oppstår når Access-Control-Allow-Credentials: true kombineres med jokertegn for opprinnelse, noe som lar angripere stjele data fra autentiserte brukere ved å gjøre forespørsler på tvers av domener som inkluderer sesjonskapsler eller autentiseringstokener.
Vanlige CORS-feilkonfigurasjoner inkluderer dynamisk å speile Origin-headeren direkte inn i Access-Control-Allow-Origin-svaret uten validering, som i praksis lar enhver opprinnelse få tilgang til ressursen. Overdrevent tillatende lister som ikke validerer domeneboundaries riktig kan utnyttes gjennom subdomeneangrep eller prefiksmanipulasjon. I tillegg unnlater mange organisasjoner å validere Origin-headeren i det hele tatt, noe som gjør dem sårbare for forfalskede forespørsler. Konsekvensene av disse sårbarhetene strekker seg utover datatyveri til å inkludere uautorisert trening av AI-modeller på proprietært innhold, innsamling av konkurranseintelligens og brudd på immaterielle rettigheter—risikoer som verktøy som AmICited.com hjelper organisasjoner å overvåke og kvantifisere.
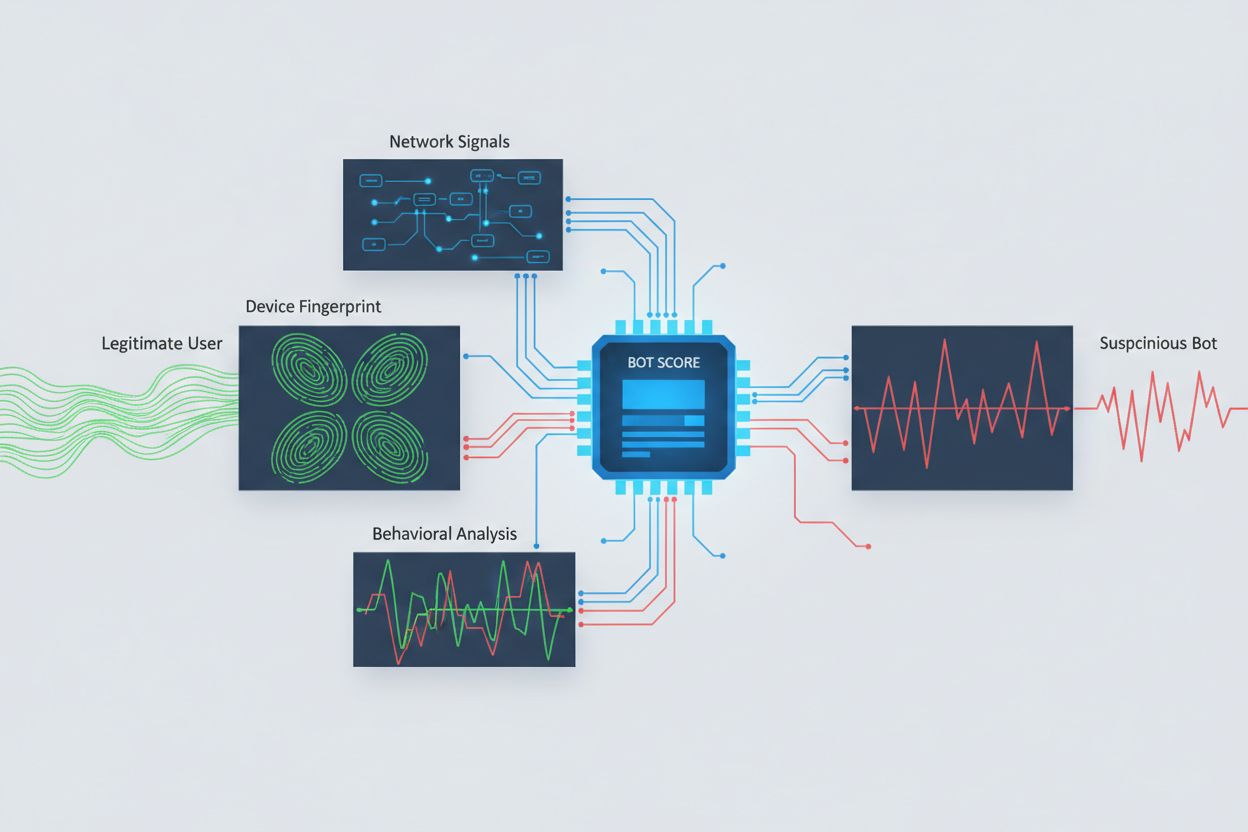
Å identifisere AI-roboter som forsøker å få tilgang på tvers av domener krever analyse av flere signaler enn bare brukeragent-strenger, som lett kan forfalskes. Brukeragentanalyse er fortsatt en førstelinjemetode, ettersom mange AI-roboter identifiserer seg med egne brukeragent-strenger som “GPTBot/1.0” eller “ClaudeBot/1.0”, selv om avanserte roboter bevisst skjuler identiteten sin ved å utgi seg for å være legitime nettlesere. Atferdsfingeravtrykk analyserer hvordan forespørsler gjøres—ved å se på mønstre som forespørselstidspunkt, rekkefølgen av sider som aksesseres, tilstedeværelse eller fravær av JavaScript-kjøring, og interaksjonsmønstre som fundamentalt skiller seg fra menneskelig nettleseratferd.
Nettverkssignalanalyse gir dypere deteksjon ved å undersøke TLS-handshake-signaturer, IP-omdømme, DNS-oppløsningsmønstre og tilkoblingskarakteristikker som avslører robotaktivitet selv når brukeragenter er forfalsket. Enhetsfingeravtrykk samler dusinvis av signaler som nettleserversjon, skjermoppløsning, installerte skrifttyper, operativsystemdetaljer og JA3 TLS-fingeravtrykk for å lage unike identifikatorer for hver forespørsel. Avanserte deteksjonssystemer kan identifisere når flere økter stammer fra samme enhet eller skript, og fanger opp distribuerte skrapeforsøk som prøver å omgå raterestriksjoner ved å spre forespørsler på mange IP-adresser. Organisasjoner kan bruke disse deteksjonsmetodene gjennom sikkerhetsplattformer og overvåkningstjenester for å få innsikt i hvilke AI-systemer som får tilgang til innholdet deres og hvordan de forsøker å omgå restriksjoner.
Organisasjoner benytter flere komplementære strategier for å blokkere eller kontrollere AI-tilgang på tvers av domener, da ingen enkeltmetode gir fullstendig beskyttelse:
User-agent: GPTBot etterfulgt av Disallow: /) gir en høflig men frivillig mekanisme; effektivt for veloppdragne roboter, men lett å ignorere for bestemte skrapereDen mest effektive beskyttelsen kombinerer flere lag, da bestemte angripere vil utnytte svakheter i enhver enkelttilnærming. Organisasjoner må kontinuerlig overvåke hvilke blokkeringstiltak som fungerer og tilpasse seg etter hvert som roboter utvikler sine omgåelsesteknikker.
Effektiv håndtering av AI-tilgang på tvers av domener krever en helhetlig, lagdelt tilnærming som balanserer sikkerhet med driftsbehov. Organisasjoner bør implementere en trinnvis strategi som starter med grunnleggende kontroller som robots.txt og brukeragentfiltrering, og deretter gradvis legge til mer sofistikerte deteksjons- og blokkeringstiltak basert på observerte trusler. Kontinuerlig overvåkning er avgjørende—å spore hvilke AI-systemer som får tilgang til innholdet ditt, hvor ofte de gjør forespørsler, og om de respekterer restriksjonene dine gir den synligheten som trengs for å ta informerte avgjørelser om tilgangspolicyer.
Dokumentasjonen av tilgangspolicyer bør være tydelig og håndhevbar, med eksplisitte bruksvilkår som forbyr uautorisert skraping og angir konsekvenser ved brudd. Regelmessige revisjoner av CORS-konfigurasjoner hjelper med å oppdage feil før de utnyttes, mens en oppdatert oversikt over kjente AI-brukeragenter og IP-intervaller gir rask respons på nye trusler. Organisasjoner bør også vurdere de forretningsmessige konsekvensene av å blokkere AI-tilgang—noen AI-roboter gir verdi gjennom søkeindeksering eller legitime partnerskap, så policyer bør skille mellom nyttig og skadelig tilgang. Implementeringen av disse praksisene krever koordinering mellom sikkerhets-, juridiske og forretningsmessige team for å sikre at policyene er i samsvar med organisatoriske mål og regulatoriske krav.
Spesialiserte verktøy og plattformer har dukket opp for å hjelpe organisasjoner med å overvåke og kontrollere AI-tilgang på tvers av domener med større presisjon og synlighet. AmICited.com gir omfattende overvåkning av hvordan AI-systemer refererer til og får tilgang til merkevaren din på GPT-er, Perplexity, Google AI Overviews og andre AI-plattformer, og gir oversikt over hvilke AI-modeller som bruker innholdet ditt og hvor ofte merkevaren din dukker opp i AI-genererte svar. Denne overvåkningen strekker seg til å spore tilgangsmønstre på tvers av domener og forstå det bredere økosystemet av AI-systemer som samhandler med dine digitale eiendeler.
I tillegg tilbyr Cloudflare robotstyringsfunksjoner med blokkering av kjente AI-roboter med ett klikk, ved å bruke maskinlæringsmodeller trent på trafikkmønstre i hele nettverket for å identifisere roboter selv når de forfalsker brukeragenter. AWS WAF (Web Application Firewall) gir tilpassbare regler for blokkering av bestemte brukeragenter og IP-intervaller, mens Imperva tilbyr avansert robotdeteksjon som kombinerer atferdsanalyse med trusselintelligens. Bright Data spesialiserer seg på å forstå robottrafikkmønstre og kan hjelpe organisasjoner med å skille mellom ulike typer roboter. Valget av verktøy avhenger av organisasjonens størrelse, tekniske modenhet og spesifikke behov—fra enkel robots.txt-håndtering for små nettsteder til plattformer for robotstyring i bedriftsklassen for store organisasjoner med sensitiv data. Uavhengig av verktøyvalg er det grunnleggende prinsippet: synlighet i AI-tilgang på tvers av domener er grunnlaget for effektiv kontroll og beskyttelse av digitale eiendeler.
CORS (Cross-Origin Resource Sharing) er en sikkerhetsmekanisme som kontrollerer hvilke opprinnelser som kan få tilgang til ressurser på en server. Cross-Origin AI Access refererer spesifikt til hvordan AI-systemer og roboter samhandler med CORS for å be om innhold fra ulike domener. Mens CORS er det tekniske rammeverket, beskriver Cross-Origin AI Access den praktiske utfordringen med å håndtere AI-roboters oppførsel innenfor dette rammeverket, inkludert deteksjon og blokkering av uautorisert AI-tilgang.
De fleste veloppdragne AI-roboter identifiserer seg gjennom spesifikke brukeragent-strenger som 'GPTBot/1.0' eller 'ClaudeBot/1.0' som tydelig indikerer formålet deres. Mange avanserte roboter forfalsker imidlertid brukeragenter ved å utgi seg for legitime nettlesere som Chrome eller Safari for å omgå blokkering basert på brukeragent. Derfor er avanserte deteksjonsmetoder som atferdsbasert fingeravtrykk og nettverkssignalanalyse nødvendige for å identifisere roboter uansett hvilken identitet de påstår å ha.
robots.txt gir en frivillig mekanisme for å be roboter respektere tilgangsbegrensninger, og veloppdragne AI-roboter som GPTBot følger vanligvis disse direktivene. robots.txt er imidlertid ikke håndhevbart—bestemte skrapere kan enkelt ignorere det. Mange AI-selskaper har blitt tatt i å omgå robots.txt-restriksjoner, noe som gjør det til et nødvendig, men utilstrekkelig forsvar som bør kombineres med tekniske blokkeringstiltak som brukeragentfiltrering, raterestriksjoner og enhetsfingeravtrykk.
Feilkonfigurerte CORS-policyer kan tillate uautoriserte AI-roboter å få tilgang til sensitiv data, stjele autentisert brukerinformasjon via forespørsler med legitimasjon, og skrape proprietært innhold for uautorisert AI-modelltrening. De farligste konfigurasjonene kombinerer jokertegn for opprinnelse med tillatelse for legitimasjon, noe som effektivt lar hvilken som helst opprinnelse få tilgang til beskyttede ressurser. Disse feilkonfigurasjonene kan føre til tyveri av immaterielle rettigheter, innsamling av konkurranseintelligens og brudd på innholdslisensavtaler.
Deteksjon krever analyse av flere signaler utover brukeragent-strenger. Du kan undersøke serverlogger for kjente AI-robot-brukeragenter, implementere atferdsfingeravtrykk for å identifisere roboter basert på interaksjonsmønstre, analysere nettverkssignaler som TLS-handshakes og DNS-mønstre, og bruke enhetsfingeravtrykk for å avdekke distribuerte skrapeforsøk. Verktøy som AmICited.com gir omfattende overvåkning av hvordan AI-systemer refererer til merkevaren din, mens plattformer som Cloudflare tilbyr maskinlæringsbasert robotdeteksjon som også identifiserer forfalskede roboter.
Ingen enkelt metode gir full beskyttelse, så en lagvis tilnærming er mest effektiv. Start med robots.txt og brukeragentfiltrering for grunnleggende forsvar, legg til raterestriksjoner for å redusere påvirkningen, implementer enhetsfingeravtrykk for å fange opp avanserte roboter, og vurder autentisering eller betalingsmur for sensitivt innhold. De mest effektive organisasjonene kombinerer flere teknikker og overvåker kontinuerlig hvilke metoder som fungerer, og tilpasser seg etter hvert som roboter utvikler sine omgåelsesteknikker.
Nei. Selv om store selskaper som OpenAI og Anthropic hevder å respektere robots.txt og CORS-restriksjoner, har undersøkelser vist at mange AI-roboter omgår disse restriksjonene. Perplexity AI ble tatt for å forfalske brukeragenter for å omgå blokkering, og forskning viser at OpenAI- og Anthropic-roboter er observert å få tilgang til innhold til tross for eksplisitte robots.txt-disallow-regler. Denne inkonsistensen er grunnen til at tekniske blokkeringstiltak og juridisk håndheving blir stadig mer nødvendige.
AmICited.com gir omfattende overvåkning av hvordan AI-systemer refererer til og får tilgang til merkevaren din på GPT-er, Perplexity, Google AI Overviews og andre AI-plattformer. Det sporer hvilke AI-modeller som bruker innholdet ditt, hvor ofte merkevaren din dukker opp i AI-genererte svar, og gir innsikt i det bredere økosystemet av AI-systemer som samhandler med dine digitale eiendeler. Denne overvåkningen hjelper deg å forstå omfanget av AI-tilgang og ta informerte beslutninger om strategi for innholdsbeskyttelse.
Få full oversikt over hvilke AI-systemer som får tilgang til merkevaren din på GPT-er, Perplexity, Google AI Overviews og andre plattformer. Spor AI-tilgangsmønstre på tvers av domener og forstå hvordan innholdet ditt brukes i AI-trening og inferens.
Lær hvordan du gjør innholdet ditt synlig for AI-crawlere som ChatGPT, Perplexity og Googles AI. Oppdag tekniske krav, beste praksis og overvåkningsstrategier f...
Lær hvordan du gjennomfører en AI-tilgjengelighetsrevisjon for å sikre at nettstedet ditt blir oppdaget av AI-crawlere som ChatGPT, Claude og Perplexity. Teknis...
Lær hvordan du lager originale data og forskning som AI-systemer aktivt siterer. Oppdag strategier for å gjøre dine data synlige for ChatGPT, Perplexity, Google...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.