
Kompletny przewodnik blokowania (lub zezwalania) na roboty AI
Dowiedz się, jak blokować lub zezwalać robotom AI, takim jak GPTBot i ClaudeBot, za pomocą robots.txt, blokowania na poziomie serwera oraz zaawansowanych metod ...
6 min czytania

Strategiczna praktyka selektywnego dopuszczania lub blokowania robotów AI w celu kontrolowania, jak treści są wykorzystywane do trenowania modeli AI lub do wyszukiwania w czasie rzeczywistym. Obejmuje to użycie plików robots.txt, kontroli na poziomie serwera oraz narzędzi monitorujących do zarządzania tym, które systemy AI mają dostęp do Twoich treści i w jakim celu.
Strategiczna praktyka selektywnego dopuszczania lub blokowania robotów AI w celu kontrolowania, jak treści są wykorzystywane do trenowania modeli AI lub do wyszukiwania w czasie rzeczywistym. Obejmuje to użycie plików robots.txt, kontroli na poziomie serwera oraz narzędzi monitorujących do zarządzania tym, które systemy AI mają dostęp do Twoich treści i w jakim celu.
Zarządzanie robotami AI to praktyka kontrolowania i monitorowania, w jaki sposób systemy sztucznej inteligencji uzyskują dostęp do treści strony internetowej oraz jak je wykorzystują do celów trenowania i wyszukiwania. W przeciwieństwie do tradycyjnych robotów wyszukiwarek, które indeksują treści na potrzeby wyników wyszukiwania w sieci, roboty AI są specjalnie zaprojektowane do zbierania danych do trenowania dużych modeli językowych lub zasilania funkcji wyszukiwania opartych na AI. Skala tej działalności różni się znacząco w zależności od organizacji—roboty OpenAI osiągają stosunek crawl-to-refer wynoszący 1 700:1, co oznacza, że uzyskują dostęp do treści 1 700 razy na każdą cytowaną referencję, podczas gdy współczynnik Anthropic sięga 73 000:1, co pokazuje ogromne zapotrzebowanie na dane do trenowania nowoczesnych systemów AI. Skuteczne zarządzanie robotami pozwala właścicielom stron zdecydować, czy ich treści będą wykorzystywane do trenowania AI, pojawiać się w wynikach wyszukiwania AI, czy pozostaną chronione przed automatycznym dostępem.
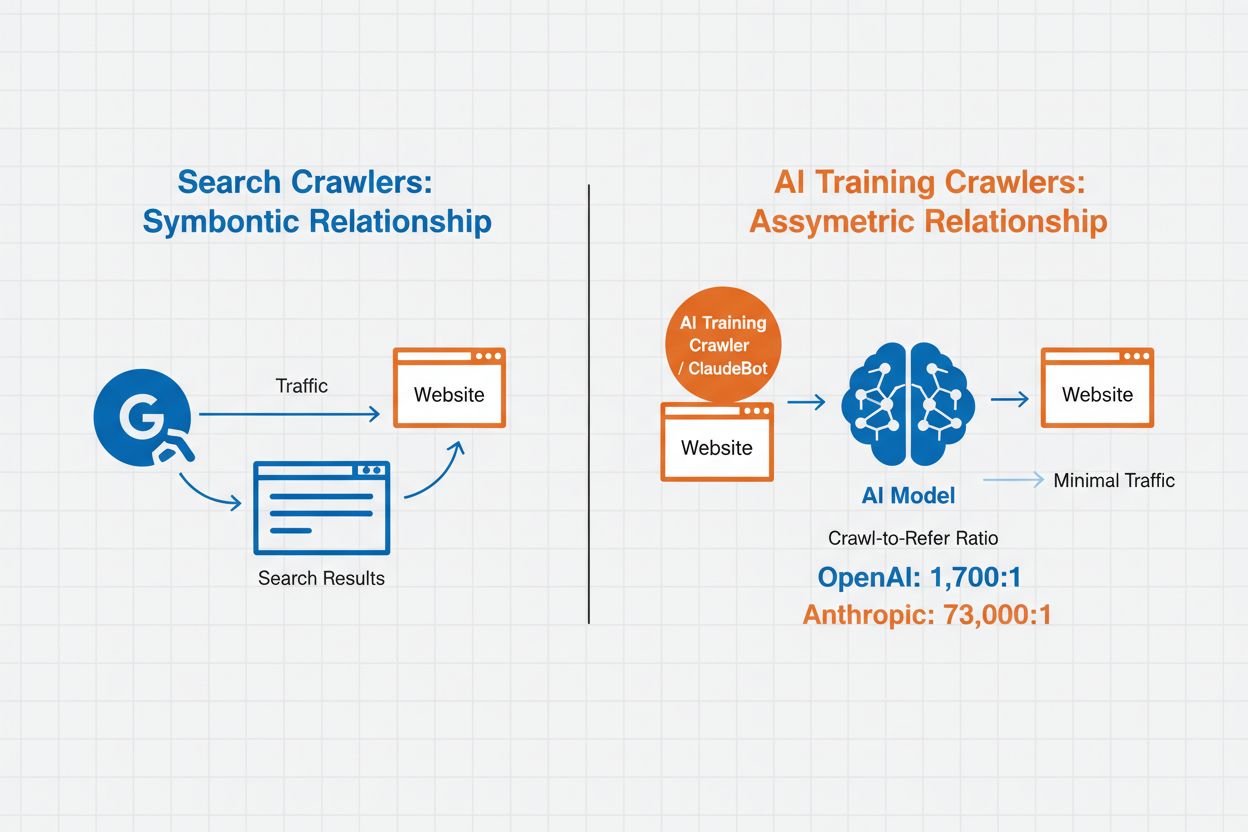
Roboty AI dzielą się na trzy odrębne kategorie w zależności od ich celu i sposobu wykorzystania danych. Roboty do trenowania gromadzą dane na potrzeby rozwoju modeli uczenia maszynowego, pochłaniając ogromne ilości treści w celu poprawy możliwości AI. Roboty wyszukiwarek i cytujące indeksują treści, aby zasilać funkcje wyszukiwania AI oraz zapewniać atrybucję w odpowiedziach generowanych przez AI, umożliwiając użytkownikom odkrywanie Twoich treści przez interfejsy AI. Roboty uruchamiane przez użytkownika działają na żądanie, gdy użytkownicy korzystają z narzędzi AI, na przykład gdy użytkownik ChatGPT przesyła dokument lub prosi o analizę konkretnej strony. Zrozumienie tych kategorii pozwala podejmować świadome decyzje, które roboty dopuszczać, a które blokować, w zależności od strategii treści i celów biznesowych.
| Typ robota | Cel | Przykłady | Wykorzystuje dane do trenowania |
|---|---|---|---|
| Trenowanie | Rozwój i ulepszanie modeli | GPTBot, ClaudeBot | Tak |
| Wyszukiwanie/Cytowanie | Wyniki wyszukiwania AI i atrybucja | Google-Extended, OAI-SearchBot, PerplexityBot | Zależy |
| Uruchamiany przez użytkownika | Analiza treści na żądanie | ChatGPT-User, Meta-ExternalAgent, Amazonbot | Zależne od kontekstu |
Zarządzanie robotami AI bezpośrednio wpływa na ruch, przychody oraz wartość Twoich treści. Gdy roboty pobierają Twoje treści bez rekompensaty, tracisz możliwość skorzystania z ruchu w postaci odsłon, kliknięć w reklamy czy zaangażowania użytkowników. Strony internetowe zgłaszają istotne spadki ruchu, gdy użytkownicy znajdują odpowiedzi bezpośrednio w generowanych przez AI podsumowaniach, zamiast klikać do oryginalnego źródła, co skutkuje utratą ruchu zwrotnego i przychodów reklamowych. Poza kwestiami finansowymi istotne są również aspekty prawne i etyczne—Twoje treści to własność intelektualna i masz prawo kontrolować, jak są wykorzystywane oraz czy otrzymujesz za nie atrybucję lub wynagrodzenie. Dodatkowo, umożliwienie nieograniczonego dostępu robotom może zwiększyć obciążenie serwera i koszty transferu, zwłaszcza w przypadku agresywnych robotów, które nie respektują ograniczeń tempa pobierania.
Plik robots.txt to podstawowe narzędzie do zarządzania dostępem robotów, umieszczane w katalogu głównym strony internetowej w celu przekazania preferencji dotyczących indeksowania agentom automatycznym. Plik ten wykorzystuje dyrektywy User-agent do kierowania reguł do konkretnych robotów oraz polecenia Disallow lub Allow do pozwalania lub ograniczania dostępu do określonych ścieżek i zasobów. Jednak robots.txt ma istotne ograniczenia—jest to standard dobrowolny, oparty na dobrej woli robotów, a złośliwe lub źle zaprojektowane boty mogą go całkowicie ignorować. Dodatkowo robots.txt nie uniemożliwia dostępu do publicznych treści; jedynie sugeruje preferowane zasady. Dlatego robots.txt powinien być częścią wielowarstwowego podejścia do zarządzania robotami, a nie jedyną linią obrony.
# Blokuj roboty AI do trenowania
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
# Zezwalaj robotom wyszukiwarek
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Domyślna reguła dla innych robotów
User-agent: *
Allow: /
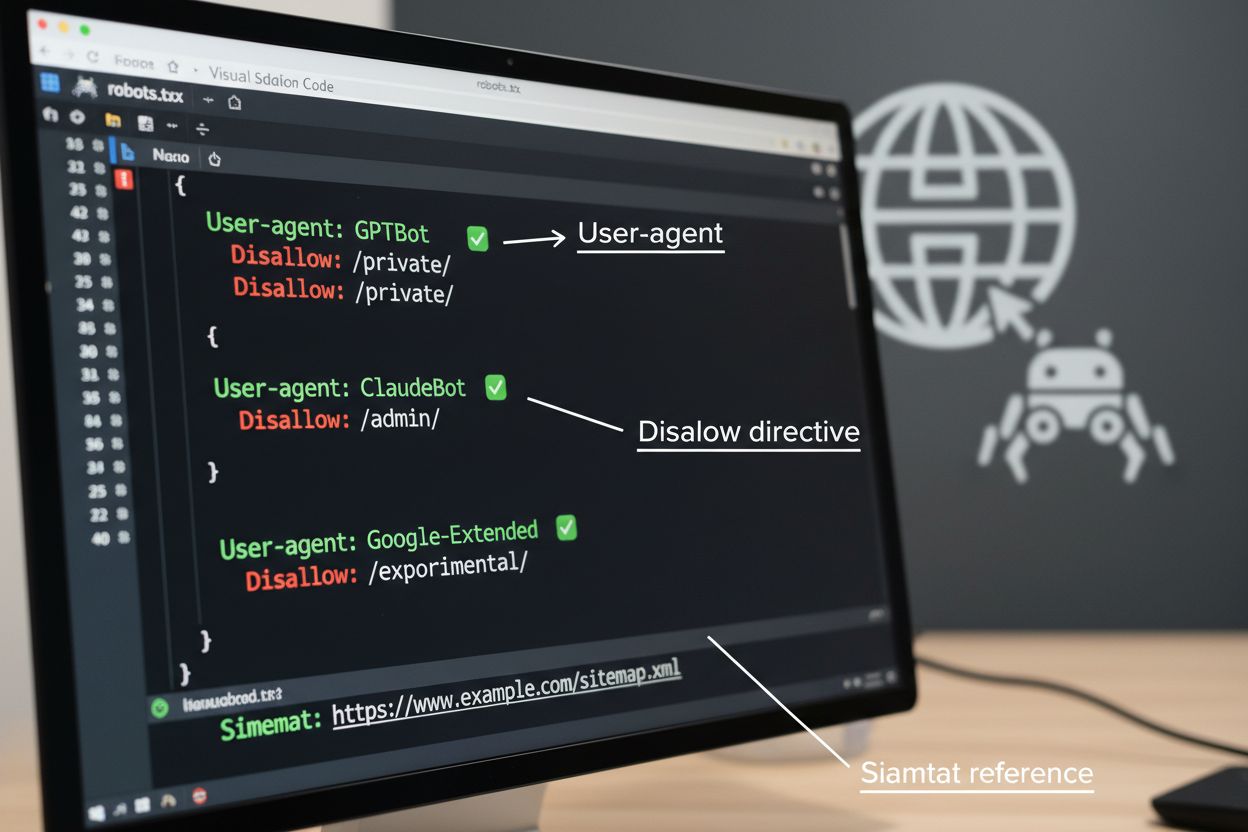
Poza robots.txt istnieje wiele zaawansowanych technik zapewniających silniejszą egzekucję i bardziej szczegółową kontrolę nad dostępem robotów. Metody te działają na różnych warstwach infrastruktury i można je łączyć dla kompleksowej ochrony:
Decyzja o blokowaniu robotów AI wiąże się z istotnymi kompromisami pomiędzy ochroną treści a ich widocznością. Blokowanie wszystkich robotów AI eliminuje możliwość pojawienia się Twoich treści w wynikach wyszukiwania AI, podsumowaniach AI lub cytowaniach przez narzędzia AI—co może ograniczyć widoczność wśród użytkowników odkrywających treści przez te nowe kanały. Z kolei pełna otwartość oznacza, że Twoje treści zasilają trenowanie AI bez rekompensaty i mogą zmniejszać ruch zwrotny, gdy użytkownicy uzyskują odpowiedzi bezpośrednio z systemów AI. Strategiczne podejście to selektywne blokowanie: pozwalanie na roboty cytujące, takie jak OAI-SearchBot i PerplexityBot, które generują ruch zwrotny, przy jednoczesnym blokowaniu robotów do trenowania, takich jak GPTBot i ClaudeBot, które pobierają dane bez atrybucji. Możesz także rozważyć zezwolenie na Google-Extended, aby utrzymać widoczność w Google AI Overviews, które mogą generować znaczny ruch, podczas gdy blokujesz roboty trenujące konkurencji. Optymalna strategia zależy od typu treści, modelu biznesowego i odbiorców—serwisy informacyjne mogą preferować blokowanie, a twórcy treści edukacyjnych mogą zyskać na szerszej widoczności w AI.
Wprowadzenie kontroli nad robotami jest skuteczne tylko wtedy, gdy faktycznie weryfikujesz, czy roboty przestrzegają Twoich reguł. Analiza logów serwera to podstawowa metoda monitorowania aktywności robotów—analizuj logi dostępu pod kątem User-Agentów i wzorców żądań, aby zidentyfikować, które roboty odwiedzają Twoją stronę i czy szanują reguły robots.txt. Wiele robotów deklaruje zgodność, ale nadal pobiera zablokowane zasoby, dlatego ciągłe monitorowanie jest niezbędne. Narzędzia takie jak Cloudflare Radar umożliwiają śledzenie ruchu w czasie rzeczywistym oraz identyfikowanie podejrzanych lub nieprzestrzegających reguł robotów. Skonfiguruj automatyczne alerty dla prób dostępu do zablokowanych zasobów i okresowo audytuj logi, by wykryć nowe roboty lub zmiany wzorców mogące świadczyć o próbach obejścia zabezpieczeń.
Skuteczne zarządzanie robotami AI wymaga systematycznego podejścia, które równoważy ochronę i strategiczną widoczność. Wykonaj poniższe osiem kroków, aby wdrożyć kompleksową strategię zarządzania robotami:
AmICited.com to specjalistyczna platforma umożliwiająca monitorowanie, jak systemy AI cytują i wykorzystują Twoje treści w różnych modelach i aplikacjach. Usługa oferuje śledzenie w czasie rzeczywistym cytowań Twoich materiałów w odpowiedziach generowanych przez AI, pomagając zrozumieć, które roboty najaktywniej korzystają z Twoich treści i jak często Twoja praca pojawia się w wynikach AI. Analizując wzorce robotów i dane o cytowaniach, AmICited.com umożliwia podejmowanie decyzji o zarządzaniu robotami w oparciu o dane—dokładnie widzisz, które roboty przynoszą korzyść poprzez cytowania i ruch zwrotny, a które jedynie pobierają treści bez atrybucji. Taka wiedza zamienia zarządzanie robotami z praktyki defensywnej w strategiczne narzędzie optymalizujące widoczność i wpływ Twoich treści w świecie zdominowanym przez AI.
Roboty do trenowania, takie jak GPTBot i ClaudeBot, zbierają treści do budowy zbiorów danych na potrzeby rozwoju dużych modeli językowych, wykorzystując Twoje treści bez generowania ruchu zwrotnego. Roboty wyszukiwarek, takie jak OAI-SearchBot i PerplexityBot, indeksują treści na potrzeby wyników wyszukiwania AI i mogą odsyłać użytkowników z powrotem na Twoją stronę poprzez cytaty. Blokowanie robotów do trenowania chroni Twoje treści przed użyciem w modelach AI, podczas gdy blokowanie robotów wyszukiwarek może zmniejszyć Twoją widoczność w platformach opartych na AI.
Nie. Blokowanie robotów AI do trenowania, takich jak GPTBot, ClaudeBot i CCBot, nie wpływa na pozycje Twojej strony w Google ani Bing. Tradycyjne wyszukiwarki używają innych robotów (Googlebot, Bingbot), które działają niezależnie od botów do trenowania AI. Blokuj tradycyjne roboty wyszukiwarek tylko wtedy, gdy chcesz całkowicie zniknąć z wyników wyszukiwania – to zaszkodzi Twojemu SEO.
Sprawdź logi dostępu serwera, aby zidentyfikować User-Agent robotów. Szukaj wpisów zawierających 'bot', 'crawler' lub 'spider' w polu User-Agent. Narzędzia takie jak Cloudflare Radar zapewniają wgląd w czasie rzeczywistym w to, które roboty AI odwiedzają Twoją stronę i jakie generują wzorce ruchu. Możesz także używać platform analitycznych pozwalających rozróżniać ruch robotów od ludzkiego.
Tak. robots.txt to standard doradczy, który opiera się na dobrej woli robotów – nie jest egzekwowalny. Roboty renomowanych firm, takich jak OpenAI, Anthropic czy Google, zazwyczaj respektują robots.txt, ale niektóre roboty całkowicie go ignorują. Dla silniejszej ochrony zastosuj blokowanie na poziomie serwera poprzez .htaccess, reguły firewalla lub ograniczenia na podstawie adresów IP.
To zależy od priorytetów biznesowych. Blokowanie wszystkich robotów do trenowania chroni Twoje treści przed wykorzystaniem w modelach AI, pozwalając jednocześnie na roboty wyszukujące, które mogą generować ruch zwrotny. Wielu wydawców stosuje selektywne blokowanie, które celuje w roboty do trenowania, a pozwala na roboty wyszukiwarek i cytujące. Przy podejmowaniu decyzji rozważ typ treści, źródła ruchu i model monetyzacji.
Przeglądaj i aktualizuj politykę zarządzania robotami co najmniej raz na kwartał. Nowe roboty AI pojawiają się regularnie, a istniejące zmieniają User-Agenty bez ostrzeżenia. Śledź zasoby takie jak projekt ai.robots.txt na GitHubie w poszukiwaniu list utrzymywanych przez społeczność i sprawdzaj miesięcznie logi serwera, by wyłapać nowe boty odwiedzające Twoją stronę.
Roboty AI mogą znacząco wpłynąć na Twój ruch i przychody. Gdy użytkownicy otrzymują odpowiedzi bezpośrednio od systemów AI zamiast odwiedzać Twoją stronę, tracisz ruch zwrotny i związane z nim wyświetlenia reklam. Badania pokazują współczynniki crawl-to-refer sięgające nawet 73 000:1 dla niektórych platform AI, co oznacza, że uzyskują one dostęp do Twoich treści tysiące razy na każdego użytkownika, którego odeślą. Blokowanie robotów do trenowania może chronić Twój ruch, podczas gdy zezwalanie na roboty wyszukiwarek może przynieść pewne korzyści z ruchu zwrotnego.
Sprawdź logi serwera, aby zobaczyć, czy zablokowane roboty nadal pojawiają się w logach dostępu. Skorzystaj z narzędzi testujących, takich jak tester robots.txt w Google Search Console lub Merkle, by zweryfikować swoją konfigurację. Otwórz robots.txt bezpośrednio pod adresem twojastrona.com/robots.txt, aby upewnić się, że treść jest poprawna. Regularnie monitoruj logi, by wyłapać roboty, które powinny być blokowane, ale nadal się pojawiają.
AmICited.com śledzi w czasie rzeczywistym odniesienia AI do Twojej marki w ChatGPT, Perplexity, Google AI Overviews i innych systemach AI. Podejmuj decyzje oparte na danych dotyczących strategii zarządzania robotami.
Dowiedz się, jak blokować lub zezwalać robotom AI, takim jak GPTBot i ClaudeBot, za pomocą robots.txt, blokowania na poziomie serwera oraz zaawansowanych metod ...

Dowiedz się, jak podejmować strategiczne decyzje dotyczące blokowania robotów AI. Oceń typ treści, źródła ruchu, modele przychodów i pozycję konkurencyjną dzięk...

Dowiedz się, jak skonfigurować robots.txt, aby kontrolować dostęp botów AI, w tym GPTBot, ClaudeBot i Perplexity. Zarządzaj widocznością swojej marki w odpowied...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.