Descubra como a Geração Aumentada por Recuperação transforma as citações em IA, permitindo atribuição precisa de fontes e respostas fundamentadas em ChatGPT, Perplexity e Google AI Overviews.
Publicado em Jan 3, 2026.Última modificação em Jan 3, 2026 às 3:24 am
Modelos de linguagem em larga escala revolucionaram a IA, mas possuem uma falha crítica: limites de conhecimento. Esses modelos são treinados com dados até um determinado momento, o que significa que não conseguem acessar informações além dessa data. Além da defasagem, LLMs tradicionais sofrem com alucinações — gerando informações falsas com confiança e sem dar atribuição de fonte às suas afirmações. Quando uma empresa precisa de dados de mercado atuais, pesquisas proprietárias ou fatos verificáveis, os LLMs tradicionais deixam a desejar, entregando respostas que não podem ser confiadas ou verificadas.
O que é RAG — Definição Central & Componentes
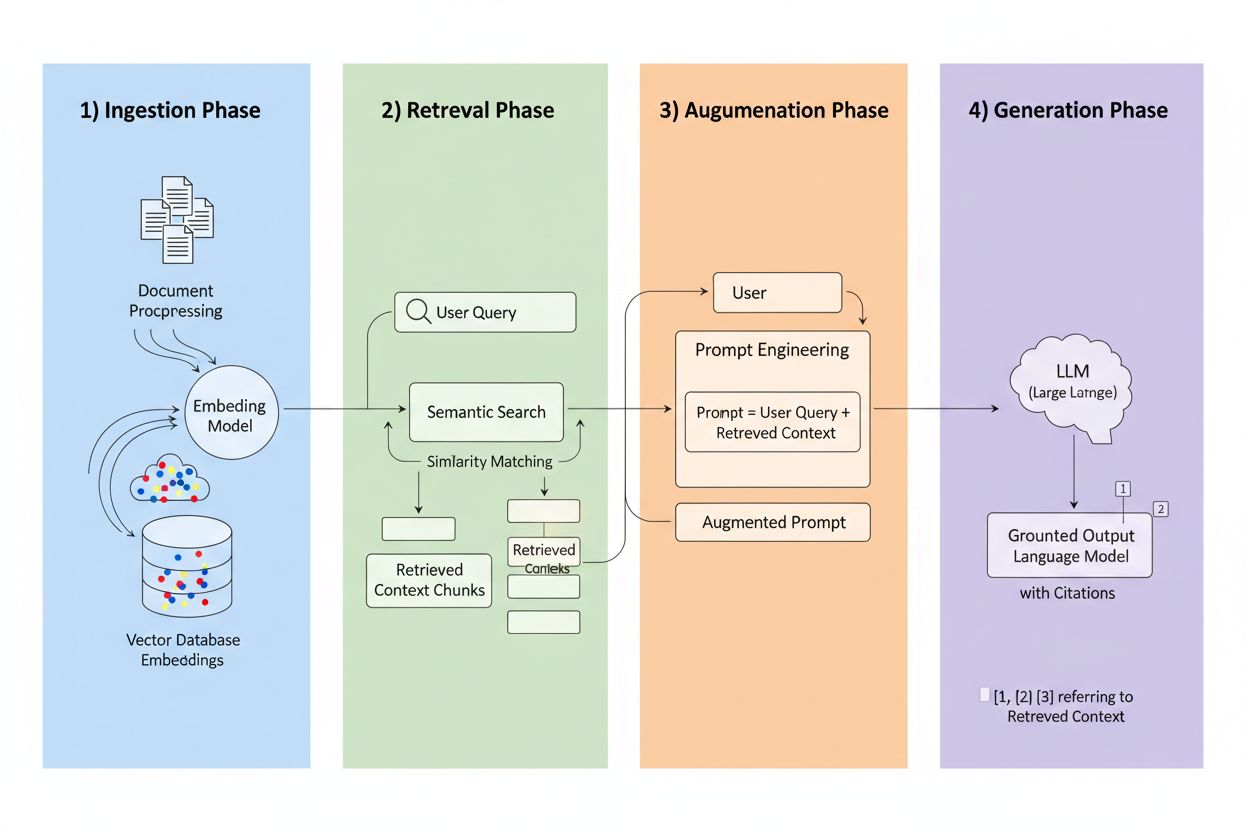
Geração Aumentada por Recuperação (RAG) é um framework que combina o poder generativo dos LLMs com a precisão dos sistemas de recuperação de informação. Em vez de depender apenas dos dados de treinamento, sistemas RAG buscam informações relevantes em fontes externas antes de gerar respostas, criando um fluxo que fundamenta as respostas em dados reais. Os quatro componentes centrais atuam em conjunto: Ingestão (convertendo documentos em formatos pesquisáveis), Recuperação (encontrando as fontes mais relevantes), Aumento (enriquecendo o prompt com contexto recuperado) e Geração (criando a resposta final com citações). Veja como o RAG se compara às abordagens tradicionais:
Aspecto
LLM Tradicional
Sistema RAG
Fonte de Conhecimento
Dados de treinamento estáticos
Fontes externas indexadas
Capacidade de Citação
Nenhuma/alucinada
Rastreável às fontes
Precisão
Propenso a erros
Fundamentado em fatos
Dados em Tempo Real
Não
Sim
Risco de Alucinação
Alto
Baixo
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Como Funciona a Recuperação RAG — Mergulho Técnico
O mecanismo de recuperação é o coração pulsante do RAG, e é muito mais sofisticado do que uma simples busca por palavras-chave. Documentos são convertidos em vetores de embedding — representações matemáticas que capturam o significado semântico — permitindo ao sistema encontrar conteúdos conceitualmente similares mesmo quando as palavras exatas não coincidem. O sistema divide documentos em pedaços gerenciáveis, normalmente de 256-1024 tokens, equilibrando preservação de contexto com precisão na recuperação. Os sistemas RAG mais avançados usam busca híbrida, que combina similaridade semântica com busca tradicional por palavras-chave para captar tanto correspondências conceituais quanto exatas. Um mecanismo de reranqueamento então pontua esses candidatos, frequentemente usando modelos cross-encoder que avaliam relevância com mais precisão do que a recuperação inicial. A relevância é calculada por múltiplos sinais: pontuações de similaridade semântica, sobreposição de palavras-chave, correspondência de metadados e autoridade do domínio. Todo o processo ocorre em milissegundos, garantindo respostas rápidas e precisas sem latência perceptível.
A Vantagem da Citação
Aqui o RAG transforma o cenário das citações: quando um sistema recupera informações de uma fonte indexada específica, essa fonte se torna rastreável e verificável. Cada trecho de texto pode ser mapeado para seu documento, URL ou publicação original, tornando a citação automática em vez de alucinada. Essa mudança fundamental cria uma transparência inédita na tomada de decisão em IA — os usuários podem ver exatamente quais fontes informaram a resposta, verificar afirmações de forma independente e avaliar a credibilidade da fonte. Diferentemente dos LLMs tradicionais, onde as citações frequentemente são inventadas ou genéricas, as citações RAG são baseadas em eventos reais de recuperação. Essa rastreabilidade aumenta dramaticamente a confiança dos usuários, já que podem validar informações em vez de aceitá-las por fé. Para criadores de conteúdo e publicadores, isso significa que seu trabalho pode ser descoberto e creditado por sistemas de IA, abrindo novos canais de visibilidade.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Fatores de Qualidade de Citação em Sistemas RAG
Nem todas as fontes são iguais em sistemas RAG, e diversos fatores determinam quais conteúdos são mais citados:
Autoridade: Reputação do domínio, perfil de backlinks e presença em grafos de conhecimento sinalizam confiabilidade para os algoritmos de recuperação
Atualidade: Conteúdo atualizado em ciclos de 48-72 horas tem melhor ranqueamento, pois frescor indica manutenção ativa e confiabilidade
Relevância: Alinhamento semântico com a consulta do usuário determina se o conteúdo aparece nos resultados de recuperação
Estrutura: Hierarquia clara, cabeçalhos descritivos e marcação semântica ajudam os sistemas a entender e extrair informação com precisão
Densidade Factual: Conteúdo rico em dados específicos, estatísticas e citações oferece mais “nuggets” recuperáveis do que resumos genéricos
Grafo de Conhecimento: Presença na Wikipedia, Wikidata ou bases de conhecimento do setor aumenta dramaticamente a probabilidade de citação
Cada fator potencializa os demais — um artigo bem estruturado, frequentemente atualizado, de um domínio autoritativo com bons backlinks e presença em grafo de conhecimento se torna um ímã de citações em sistemas RAG. Isso cria um novo paradigma de otimização, onde a visibilidade depende menos de SEO para tráfego e mais em ser uma fonte estruturada e confiável de informação.
Como Diferentes Plataformas de IA Usam RAG para Citações
Diferentes plataformas de IA implementam RAG com estratégias distintas, criando padrões variados de citação. O ChatGPT valoriza fortemente fontes da Wikipedia, com estudos mostrando que cerca de 26-35% das citações vêm exclusivamente da Wikipedia, refletindo sua autoridade e formato estruturado. Google AI Overviews emprega uma seleção mais diversa de fontes, buscando em sites de notícias, artigos acadêmicos e fóruns, com o Reddit aparecendo em cerca de 5% das citações, mesmo com menor autoridade tradicional. O Perplexity AI normalmente cita de 3 a 5 fontes por resposta e mostra forte preferência por publicações do setor e notícias recentes, otimizando para abrangência e atualidade. Essas plataformas ponderam autoridade de domínio de formas distintas — algumas priorizam marcadores tradicionais como backlinks e idade do domínio, enquanto outras enfatizam frescor do conteúdo e relevância semântica. Entender essas estratégias específicas de cada plataforma é fundamental para criadores de conteúdo, já que a otimização para o RAG de uma pode diferir significativamente de outra.
RAG vs Busca Tradicional — Implicações nas Citações
A ascensão do RAG rompe fundamentos da sabedoria tradicional de SEO. Em otimização para motores de busca, citações e visibilidade estão diretamente ligadas ao tráfego — você precisa de cliques para importar. O RAG inverte essa equação: o conteúdo pode ser citado e influenciar respostas de IA sem gerar nenhum tráfego. Um artigo bem estruturado e autoritativo pode aparecer em dezenas de respostas de IA diariamente sem receber um único clique, pois o usuário obtém sua resposta diretamente do resumo da IA. Isso significa que sinais de autoridade importam mais do que nunca, sendo o principal mecanismo pelo qual sistemas RAG avaliam a qualidade das fontes. A consistência entre plataformas torna-se crítica — se seu conteúdo está no seu site, LinkedIn, bases de dados do setor e grafos de conhecimento, os sistemas RAG veem sinais de autoridade reforçados. Presença em grafo de conhecimento deixa de ser um diferencial para se tornar infraestrutura essencial, já que esses bancos de dados estruturados são fontes primárias de recuperação para muitos RAGs. O jogo da citação mudou fundamentalmente de “gerar tráfego” para “tornar-se uma fonte confiável de informação”.
Otimizando Conteúdo para Citações RAG
Para maximizar citações RAG, a estratégia de conteúdo deve migrar de otimização para tráfego para otimização de fonte. Implemente ciclos de atualização de 48-72 horas para conteúdos perenes, sinalizando aos sistemas de recuperação que sua informação está atualizada. Use marcação de dados estruturados (Schema.org, JSON-LD) para ajudar os sistemas a interpretar o significado e as relações do seu conteúdo. Alinhe seu conteúdo semanticamente com padrões comuns de consulta — use linguagem natural que reflita como as pessoas perguntam, não só como pesquisam. Formate conteúdo com seções de FAQ e Q&A, pois elas se encaixam diretamente no padrão de pergunta-resposta usado por sistemas RAG. Desenvolva ou contribua para entradas na Wikipedia e grafos de conhecimento, pois são fontes primárias para a maioria das plataformas. Construa autoridade de backlinks por meio de parcerias estratégicas e citações de outras fontes autoritativas, já que perfis de links permanecem sinais fortes de autoridade. Por fim, mantenha consistência entre plataformas — garanta que suas afirmações, dados e mensagens centrais estejam alinhados em seu site, perfis sociais, bases do setor e grafos de conhecimento, criando sinais reforçados de confiabilidade.
O Futuro do RAG e das Citações
A tecnologia RAG segue evoluindo rapidamente, com várias tendências remodelando o funcionamento das citações. Algoritmos de recuperação mais sofisticados irão além da similaridade semântica, buscando compreensão mais profunda da intenção e contexto da consulta, melhorando a relevância das citações. Bases de conhecimento especializadas vão surgir para domínios específicos — sistemas médicos usando literatura médica curada, sistemas jurídicos usando jurisprudência e legislação — criando novas oportunidades de citação para fontes autoritativas de cada setor. Integração com sistemas multiagente permitirá ao RAG orquestrar múltiplos recuperadores especializados, combinando insights de diferentes bancos de conhecimento para respostas mais abrangentes. Acesso a dados em tempo real vai melhorar dramaticamente, permitindo a incorporação de informações ao vivo de APIs, bancos de dados e fontes em streaming. RAG agentivo — onde agentes de IA decidem autonomamente o que recuperar, como processar e quando iterar — criará padrões de citação mais dinâmicos, potencialmente citando fontes múltiplas vezes à medida que os agentes refinam seu raciocínio.
O Papel do AmICited no Monitoramento de Citações RAG
À medida que o RAG transforma como sistemas de IA descobrem e citam fontes, entender o desempenho das suas citações torna-se essencial. O AmICited monitora citações de IA em várias plataformas, rastreando quais de suas fontes aparecem no ChatGPT, Google AI Overviews, Perplexity e sistemas emergentes de IA. Você verá quais fontes específicas são citadas, com que frequência aparecem e em qual contexto — revelando quais conteúdos ressoam com algoritmos de recuperação RAG. Nossa plataforma ajuda você a entender padrões de citação no seu portfólio de conteúdo, identificando o que torna certos materiais dignos de citação e outros invisíveis. Meça a visibilidade da sua marca em respostas de IA com métricas que realmente importam na era do RAG, indo além da análise tradicional de tráfego. Faça análise competitiva de desempenho de citações, vendo como suas fontes se comparam às dos concorrentes nas respostas geradas por IA. Em um mundo onde citações de IA impulsionam visibilidade e autoridade, ter clareza sobre seu desempenho de citações não é opcional — é como você permanece competitivo.
Perguntas frequentes
Qual é a diferença entre RAG e LLMs tradicionais?
LLMs tradicionais dependem de dados de treinamento estáticos com limites de conhecimento e não podem acessar informações em tempo real, muitas vezes resultando em alucinações e afirmações não verificáveis. Sistemas RAG recuperam informações de fontes externas indexadas antes de gerar respostas, permitindo citações precisas e respostas fundamentadas com base em dados atuais e verificáveis.
Como o RAG melhora a precisão das citações?
O RAG rastreia cada informação recuperada até sua fonte original, tornando as citações automáticas e verificáveis em vez de alucinadas. Isso cria um vínculo direto entre a resposta e o material fonte, permitindo que os usuários verifiquem afirmações de forma independente e avaliem a credibilidade da fonte.
Quais fatores determinam quais fontes são citadas em sistemas RAG?
Sistemas RAG avaliam as fontes com base em autoridade (reputação do domínio e backlinks), atualidade (conteúdo atualizado em até 48-72 horas), relevância semântica para a consulta, estrutura e clareza do conteúdo, densidade factual com dados específicos e presença em grafos de conhecimento como a Wikipedia. Esses fatores se somam para determinar a probabilidade de citação.
Como posso otimizar meu conteúdo para citações RAG?
Atualize o conteúdo a cada 48-72 horas para manter sinais de atualidade, implemente marcação de dados estruturados (Schema.org), alinhe o conteúdo semanticamente com consultas comuns, use formatação de FAQ e Q&A, desenvolva presença na Wikipedia e em grafos de conhecimento, construa autoridade de backlinks e mantenha consistência em todas as plataformas.
Por que a presença em grafos de conhecimento é importante para citações em IA?
Grafos de conhecimento como Wikipedia e Wikidata são fontes primárias de recuperação para a maioria dos sistemas RAG. A presença nesses bancos de dados estruturados aumenta dramaticamente a probabilidade de citação e cria sinais fundamentais de confiança que sistemas de IA referenciam repetidamente em diversas consultas.
Com que frequência devo atualizar o conteúdo para visibilidade em RAG?
O conteúdo deve ser atualizado a cada 48-72 horas para manter sinais fortes de atualidade em sistemas RAG. Não é necessário reescrever tudo — adicionar novos dados, atualizar estatísticas ou expandir seções com desenvolvimentos recentes já é suficiente para manter elegibilidade de citação.
Qual o papel da autoridade do domínio nas citações RAG?
A autoridade do domínio funciona como um proxy de confiabilidade nos algoritmos RAG, representando cerca de 5% da probabilidade de citação. Ela é avaliada por idade do domínio, certificados SSL, perfil de backlinks, atribuição de especialistas e presença em grafos de conhecimento, todos influenciando a seleção de fontes.
Como o AmICited ajuda a monitorar citações RAG?
O AmICited rastreia quais de suas fontes aparecem em respostas geradas por IA no ChatGPT, Google AI Overviews, Perplexity e outras plataformas. Você verá frequência das citações, contexto e desempenho competitivo, ajudando a entender o que torna um conteúdo digno de citação na era do RAG.
Monitore as Citações de IA da Sua Marca
Entenda como sua marca aparece em respostas geradas por IA no ChatGPT, Perplexity, Google AI Overviews e outros. Acompanhe padrões de citação, meça visibilidade e otimize sua presença no cenário de busca movido por IA.
O que é RAG na Pesquisa em IA: Guia Completo sobre Geração Aumentada por Recuperação
Descubra o que é RAG (Geração Aumentada por Recuperação) na pesquisa em IA. Saiba como o RAG melhora a precisão, reduz alucinações e impulsiona o ChatGPT, Perpl...
Como Funciona a Geração Aumentada por Recuperação: Arquitetura e Processo
Descubra como o RAG combina LLMs com fontes externas de dados para gerar respostas de IA precisas. Entenda o processo de cinco etapas, componentes e por que iss...
Como os Sistemas RAG Lidam com Informações Desatualizadas?
Saiba como sistemas de Geração Aumentada por Recuperação gerenciam a atualização da base de conhecimento, evitam dados obsoletos e mantêm informações atuais por...
12 min de leitura
Consentimento de Cookies Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.