
Requisitos de Diversidade de Fontes em IA
Descubra como os sistemas de IA decidem entre citar múltiplas fontes ou concentrar-se em fontes autoritativas. Entenda os padrões de citação do ChatGPT, Google ...
10 min de leitura
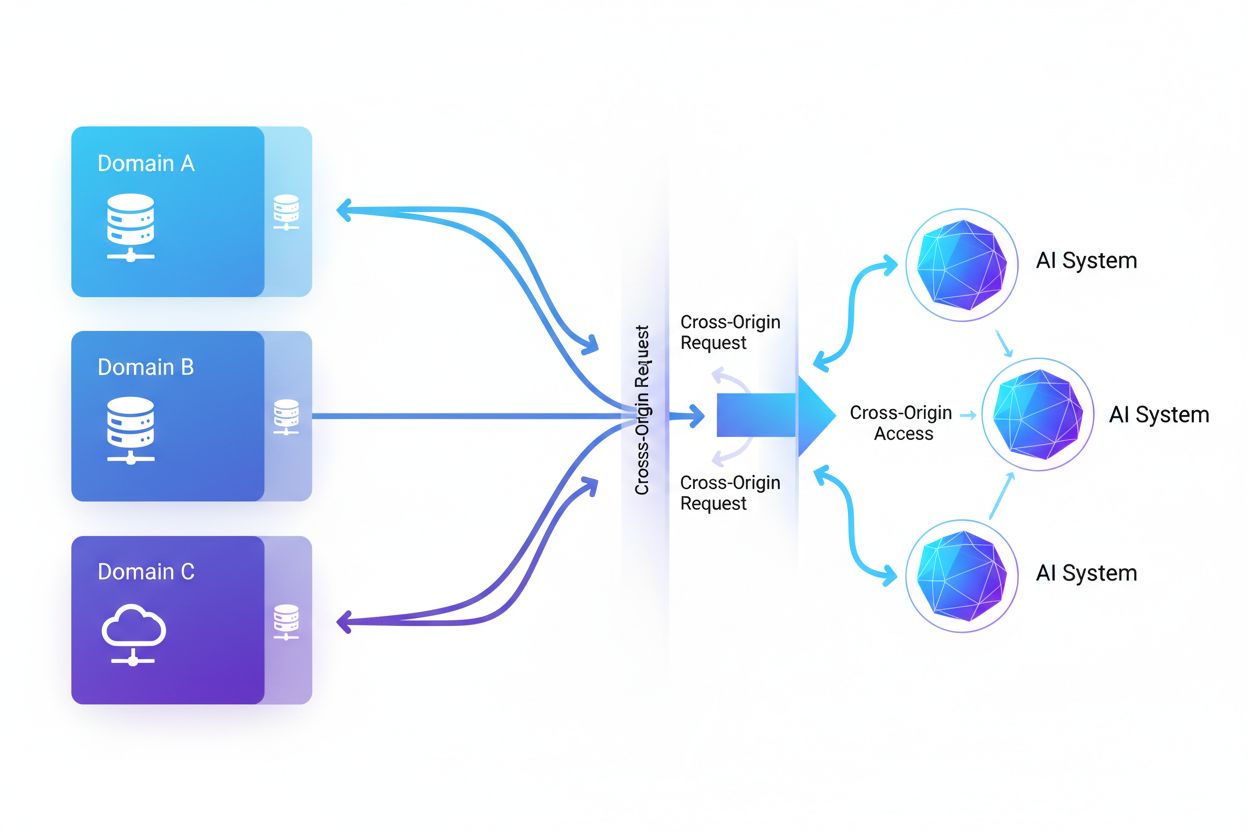
Acesso de IA entre Origens refere-se à capacidade de sistemas de inteligência artificial e rastreadores web solicitarem e recuperarem conteúdo de domínios diferentes de sua origem, regidos por mecanismos de segurança como CORS. Abrange como empresas de IA ampliam a coleta de dados para treinar grandes modelos de linguagem enquanto navegam por restrições de cross-origin. Compreender esse conceito é fundamental para criadores de conteúdo e proprietários de sites protegerem propriedade intelectual e manterem o controle sobre como seu conteúdo é utilizado por sistemas de IA. A visibilidade sobre a atividade de IA entre origens ajuda a distinguir entre acesso legítimo de IA e extração não autorizada.
Acesso de IA entre Origens refere-se à capacidade de sistemas de inteligência artificial e rastreadores web solicitarem e recuperarem conteúdo de domínios diferentes de sua origem, regidos por mecanismos de segurança como CORS. Abrange como empresas de IA ampliam a coleta de dados para treinar grandes modelos de linguagem enquanto navegam por restrições de cross-origin. Compreender esse conceito é fundamental para criadores de conteúdo e proprietários de sites protegerem propriedade intelectual e manterem o controle sobre como seu conteúdo é utilizado por sistemas de IA. A visibilidade sobre a atividade de IA entre origens ajuda a distinguir entre acesso legítimo de IA e extração não autorizada.
Acesso de IA entre Origens refere-se à capacidade de sistemas de inteligência artificial e rastreadores web solicitarem e recuperarem conteúdo de domínios diferentes de sua origem, regidos por mecanismos de segurança como o Compartilhamento de Recursos entre Origens Diferentes (CORS). À medida que empresas de IA ampliam seus esforços de coleta de dados para treinar grandes modelos de linguagem e outros sistemas inteligentes, compreender como esses sistemas navegam por restrições entre origens tornou-se fundamental para criadores de conteúdo e proprietários de sites. O desafio está em distinguir entre o acesso legítimo de IA para indexação de buscas e a extração não autorizada para treinamento de modelos, tornando a visibilidade sobre a atividade de IA entre origens essencial para proteger a propriedade intelectual e manter o controle sobre o uso do conteúdo.
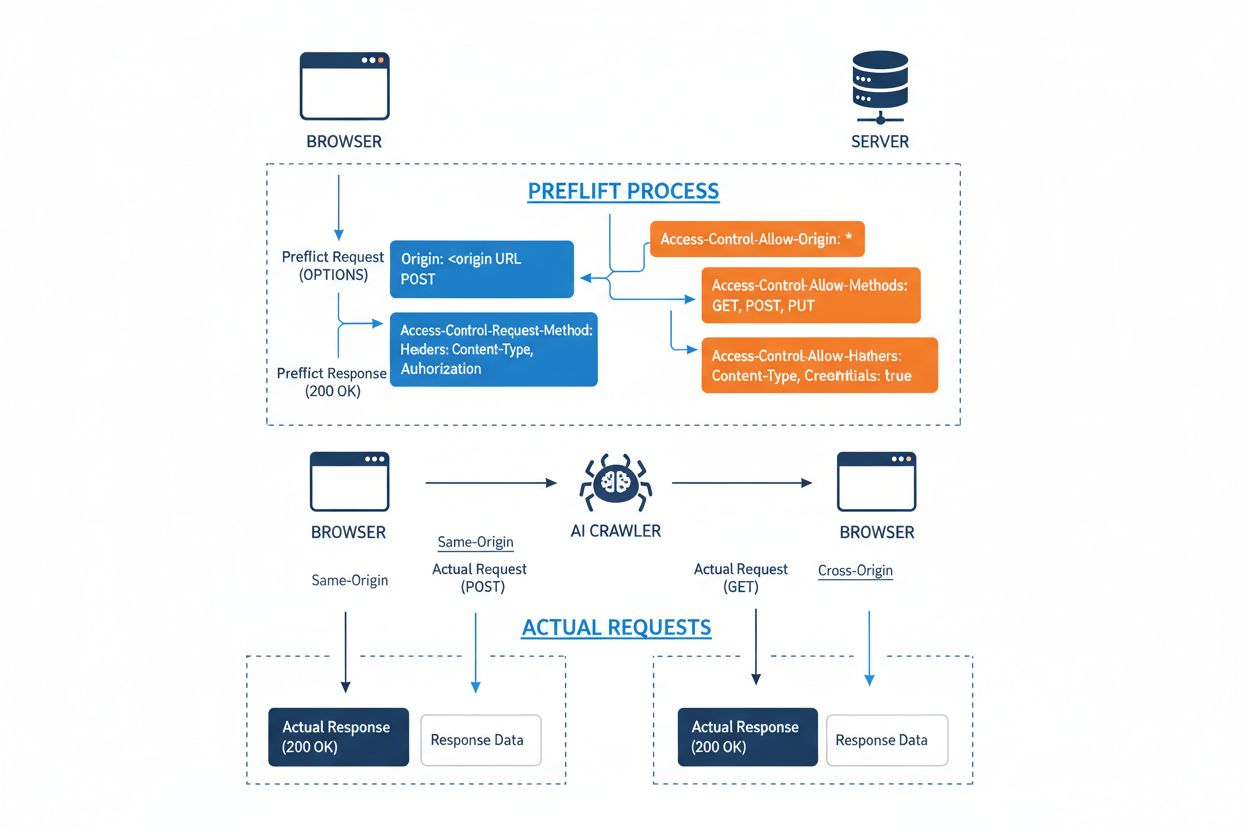
O Compartilhamento de Recursos entre Origens Diferentes (CORS) é um mecanismo de segurança baseado em HTTP-headers que permite aos servidores especificar quais origens (domínios, esquemas ou portas) podem acessar seus recursos. Quando um rastreador de IA ou qualquer cliente tenta acessar um recurso de uma origem diferente, o navegador ou cliente inicia uma requisição preflight usando o método OPTIONS do HTTP para verificar se o servidor permite a requisição real. O servidor responde com headers CORS específicos que determinam as permissões de acesso, incluindo quais origens são permitidas, quais métodos HTTP são autorizados, quais headers podem ser incluídos e se credenciais como cookies ou tokens de autenticação podem ser enviadas com a requisição.
| Header CORS | Finalidade |
|---|---|
Access-Control-Allow-Origin | Especifica quais origens podem acessar o recurso (* para todas, ou domínios específicos) |
Access-Control-Allow-Methods | Lista métodos HTTP permitidos (GET, POST, PUT, DELETE etc.) |
Access-Control-Allow-Headers | Define quais headers de requisição são permitidos (Authorization, Content-Type etc.) |
Access-Control-Allow-Credentials | Determina se credenciais (cookies, tokens de autenticação) podem ser incluídas nas requisições |
Access-Control-Max-Age | Especifica por quanto tempo as respostas preflight podem ser armazenadas em cache (em segundos) |
Access-Control-Expose-Headers | Lista headers de resposta que os clientes podem acessar |
Rastreadores de IA interagem com o CORS respeitando esses headers quando estão devidamente configurados, embora muitos bots sofisticados tentem contornar essas restrições falsificando user agents ou usando redes proxy. A eficácia do CORS como defesa contra acesso não autorizado de IA depende totalmente da configuração correta do servidor e da disposição do rastreador em honrar as restrições — uma distinção crítica que se tornou cada vez mais relevante à medida que empresas de IA competem por dados de treinamento.
O cenário de rastreadores de IA acessando a web expandiu-se dramaticamente, com vários grandes players dominando os padrões de acesso entre origens. Segundo análise de tráfego de rede da Cloudflare, os rastreadores de IA mais prevalentes incluem:
Esses rastreadores geram bilhões de requisições mensalmente, com alguns como Bytespider e GPTBot acessando a maioria do conteúdo público disponível na internet. O volume e a agressividade dessa atividade motivaram grandes plataformas como Reddit, Twitter/X, Stack Overflow e diversos veículos de notícias a implementar medidas de bloqueio.
Políticas CORS mal configuradas criam vulnerabilidades de segurança significativas que rastreadores de IA podem explorar para acessar dados sensíveis sem autorização. Quando servidores definem Access-Control-Allow-Origin: * sem validação adequada, acabam permitindo que qualquer origem — incluindo rastreadores de IA maliciosos — acesse recursos que deveriam ser restritos. Uma configuração especialmente perigosa ocorre ao combinar Access-Control-Allow-Credentials: true com configurações de origem coringa, permitindo que atacantes roubem dados de usuários autenticados ao realizar requisições entre origens que incluam cookies de sessão ou tokens de autenticação.
Falhas comuns de configuração de CORS incluem refletir dinamicamente o header Origin diretamente na resposta Access-Control-Allow-Origin sem validação, o que efetivamente permite que qualquer origem acesse o recurso. Listas permissivas demais que deixam de validar adequadamente os limites de domínio podem ser exploradas por ataques via subdomínios ou manipulação de prefixos. Além disso, muitas organizações não validam corretamente o próprio header Origin, tornando-se vulneráveis a requisições forjadas. As consequências dessas vulnerabilidades vão além do roubo de dados, incluindo treinamento não autorizado de modelos de IA com conteúdo proprietário, coleta de inteligência competitiva e violação de direitos de propriedade intelectual — riscos que ferramentas como o AmICited.com ajudam as empresas a monitorar e quantificar.
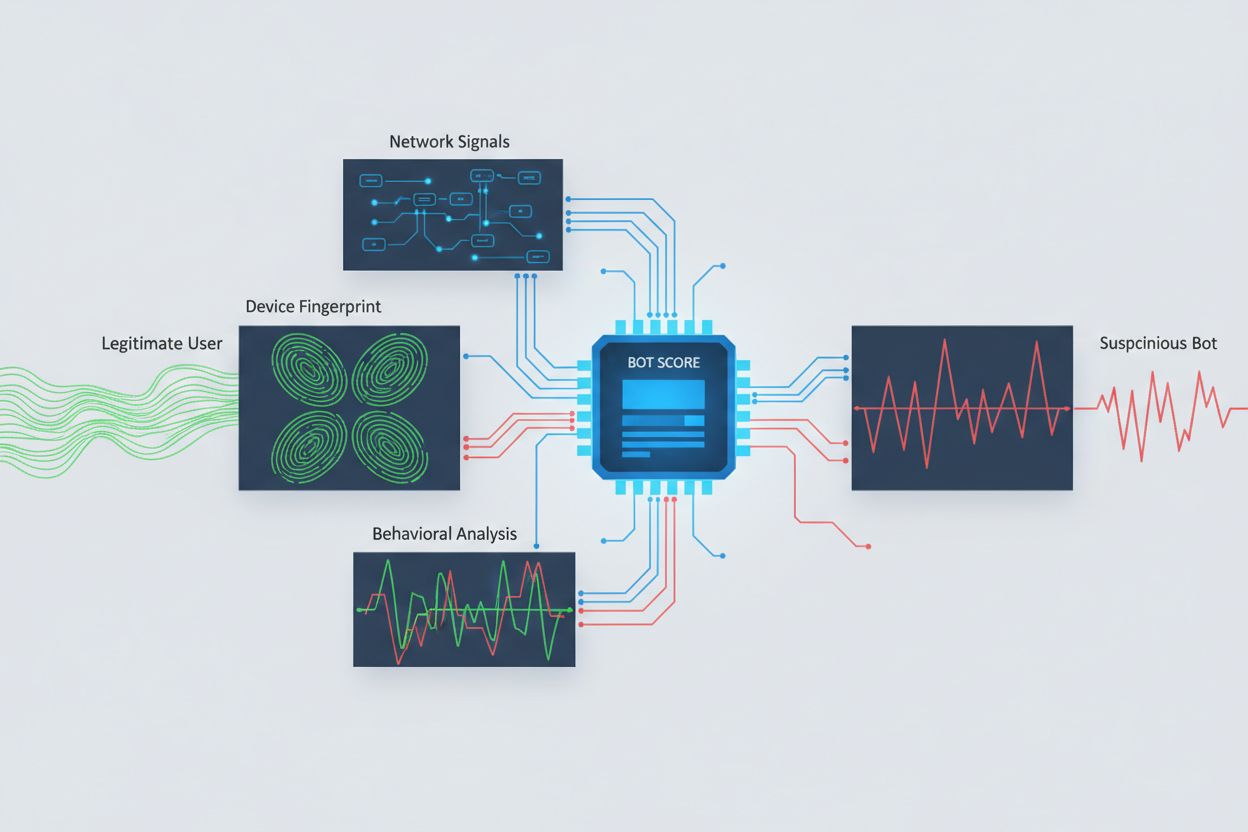
Identificar rastreadores de IA tentando acesso entre origens exige análise de múltiplos sinais além de simples strings de user agent, que são facilmente falsificadas. A análise de user agent permanece como método inicial de detecção, já que muitos rastreadores de IA se identificam por strings como “GPTBot/1.0” ou “ClaudeBot/1.0”, embora rastreadores sofisticados deliberadamente ocultem sua identidade imitando navegadores legítimos. O fingerprinting comportamental analisa como as requisições são feitas — examinando padrões como tempo entre requisições, sequência de páginas acessadas, presença ou ausência de execução de JavaScript e padrões de interação que diferem fundamentalmente do comportamento humano de navegação.
A análise de sinais de rede oferece capacidades de detecção mais profundas ao examinar assinaturas de handshake TLS, reputação de IP, padrões de resolução DNS e características de conexão que revelam atividade de bots mesmo quando os user agents são falsificados. O fingerprinting de dispositivos agrega dezenas de sinais incluindo versão do navegador, resolução de tela, fontes instaladas, detalhes do sistema operacional e impressões digitais JA3 de TLS para criar identificadores únicos para cada fonte de requisição. Sistemas avançados de detecção podem identificar quando múltiplas sessões se originam do mesmo dispositivo ou script, capturando tentativas distribuídas de extração de dados que tentam burlar limites de taxa espalhando requisições por vários IPs. As organizações podem usar esses métodos de detecção por meio de plataformas de segurança e serviços de monitoramento para obter visibilidade sobre quais sistemas de IA estão acessando seu conteúdo e como estão tentando contornar restrições.
Organizações empregam múltiplas estratégias complementares para bloquear ou controlar o acesso de IA entre origens, reconhecendo que nenhum método isolado oferece proteção total:
User-agent: GPTBot seguido por Disallow: /) fornece um mecanismo educado, porém voluntário; eficaz para rastreadores bem-comportados, mas facilmente ignorado por extrações determinadasA defesa mais eficaz combina múltiplas camadas, pois atacantes determinados explorarão fraquezas em qualquer abordagem única. Organizações devem monitorar continuamente quais métodos de bloqueio estão funcionando e adaptar-se à medida que rastreadores evoluem suas técnicas de evasão.
Gerenciar de forma eficaz o acesso de IA entre origens exige uma abordagem abrangente e em camadas, equilibrando segurança e necessidades operacionais. Organizações devem implementar uma estratégia escalonada começando com controles básicos como robots.txt e filtragem de user agent, acrescentando mecanismos de detecção e bloqueio mais sofisticados conforme as ameaças observadas. O monitoramento contínuo é essencial — acompanhar quais sistemas de IA estão acessando seu conteúdo, com que frequência fazem requisições e se estão respeitando suas restrições oferece a visibilidade necessária para tomar decisões informadas sobre políticas de acesso.
A documentação das políticas de acesso deve ser clara e aplicável, com termos de uso explícitos que proíbam extrações não autorizadas e especifiquem consequências para violações. Auditorias regulares das configurações de CORS ajudam a identificar falhas antes que sejam exploradas, enquanto manter um inventário atualizado de user agents e faixas de IP conhecidos de rastreadores de IA permite resposta rápida a novas ameaças. Organizações também devem considerar os impactos de negócio do bloqueio de acesso de IA — alguns rastreadores fornecem valor por meio de indexação de busca ou parcerias legítimas, de modo que as políticas devem distinguir entre padrões de acesso benéficos e prejudiciais. Implementar essas práticas exige coordenação entre equipes de segurança, jurídica e de negócios para garantir que as políticas estejam alinhadas com os objetivos organizacionais e requisitos regulatórios.
Ferramentas e plataformas especializadas surgiram para ajudar organizações a monitorar e controlar o acesso de IA entre origens com precisão e visibilidade ampliadas. O AmICited.com oferece monitoramento abrangente de como sistemas de IA referenciam e acessam sua marca em GPTs, Perplexity, Google AI Overviews e outras plataformas de IA, oferecendo visibilidade sobre quais modelos de IA estão usando seu conteúdo e com que frequência sua marca aparece em respostas geradas por IA. Essa capacidade de monitoramento se estende ao acompanhamento dos padrões de acesso entre origens e à compreensão do ecossistema mais amplo de sistemas de IA interagindo com suas propriedades digitais.
Além do monitoramento, o Cloudflare oferece recursos de gestão de bots com bloqueio em um clique para rastreadores de IA conhecidos, utilizando modelos de machine learning treinados em padrões de tráfego globais para identificar bots mesmo quando falsificam user agents. O AWS WAF (Web Application Firewall) fornece regras personalizáveis para bloquear user agents e faixas de IP específicas, enquanto a Imperva oferece detecção avançada de bots combinando análise comportamental com inteligência de ameaças. A Bright Data é especializada na compreensão de padrões de tráfego de bots e pode ajudar organizações a distinguir entre diferentes tipos de rastreadores. A escolha das ferramentas depende do porte da organização, sofisticação técnica e requisitos específicos — desde uma simples gestão de robots.txt para pequenos sites até plataformas de gerenciamento de bots de nível corporativo para grandes organizações que lidam com dados sensíveis. Independentemente da ferramenta escolhida, o princípio fundamental permanece: visibilidade sobre o acesso de IA entre origens é a base para o controle e proteção eficaz dos ativos digitais.
CORS (Compartilhamento de Recursos entre Origens Diferentes) é um mecanismo de segurança que controla quais origens podem acessar recursos em um servidor. Acesso de IA entre Origens refere-se especificamente a como sistemas de IA e rastreadores interagem com o CORS para solicitar conteúdo de diferentes domínios. Enquanto o CORS é a estrutura técnica, o Acesso de IA entre Origens descreve o desafio prático de gerenciar o comportamento de rastreadores de IA dentro dessa estrutura, incluindo detecção e bloqueio de acessos não autorizados de IA.
A maioria dos rastreadores de IA bem-comportados se identifica por meio de strings específicas de user agent como 'GPTBot/1.0' ou 'ClaudeBot/1.0', que indicam claramente sua finalidade. No entanto, muitos rastreadores sofisticados deliberadamente falsificam o user agent, imitando navegadores legítimos como Chrome ou Safari para burlar bloqueios baseados em user agent. Por isso, métodos avançados de detecção usando fingerprinting comportamental e análise de sinais de rede são necessários para identificar bots independentemente da identidade declarada.
robots.txt fornece um mecanismo voluntário para solicitar que rastreadores respeitem restrições de acesso, e rastreadores de IA bem-comportados como o GPTBot geralmente seguem essas diretivas. Contudo, robots.txt não é compulsório — extrações determinadas podem simplesmente ignorá-lo. Muitas empresas de IA já foram flagradas contornando restrições do robots.txt, tornando-o uma defesa necessária, mas insuficiente, que deve ser combinada com métodos técnicos como filtragem de user agent, limitação de taxa e fingerprinting de dispositivos.
Políticas CORS mal configuradas podem permitir que rastreadores de IA não autorizados acessem dados sensíveis, roubem informações de usuários autenticados por meio de requisições habilitadas para credenciais e capturem conteúdo proprietário para treinamento não autorizado de modelos de IA. As configurações mais perigosas combinam permissões de origem coringa com permissão de credenciais, permitindo que qualquer origem acesse recursos protegidos. Essas falhas podem resultar em roubo de propriedade intelectual, coleta de inteligência competitiva e violação de acordos de licenciamento de conteúdo.
A detecção exige análise de múltiplos sinais além das strings de user agent. É possível examinar logs do servidor em busca de user agents conhecidos de rastreadores de IA, implementar fingerprinting comportamental para identificar bots por seus padrões de interação, analisar sinais de rede como handshakes TLS e padrões DNS, e usar fingerprinting de dispositivos para identificar tentativas distribuídas de extração de dados. Ferramentas como o AmICited.com oferecem monitoramento abrangente de como sistemas de IA referenciam sua marca, enquanto plataformas como o Cloudflare oferecem detecção de bots baseada em machine learning, identificando até mesmo rastreadores que falsificam a identidade.
Nenhum método único oferece proteção total, por isso uma abordagem em camadas é mais eficaz. Comece com robots.txt e filtragem de user agent para defesa básica, adicione limitação de taxa para reduzir o impacto, implemente fingerprinting de dispositivos para capturar bots sofisticados e considere autenticação ou paywalls para conteúdo sensível. As organizações mais eficientes combinam várias técnicas e monitoram continuamente quais métodos estão funcionando, adaptando-se conforme os rastreadores evoluem suas estratégias de evasão.
Não. Embora grandes empresas como OpenAI e Anthropic afirmem respeitar robots.txt e restrições de CORS, investigações revelaram que muitos rastreadores de IA ignoram essas restrições. A Perplexity AI foi flagrada falsificando user agents para burlar bloqueios, e pesquisas mostram que rastreadores da OpenAI e Anthropic já foram observados acessando conteúdo apesar de regras explícitas de disallow no robots.txt. Essa inconsistência torna cada vez mais necessário o uso de métodos técnicos de bloqueio e aplicação jurídica.
O AmICited.com oferece monitoramento abrangente de como sistemas de IA referenciam e acessam sua marca em GPTs, Perplexity, Google AI Overviews e outras plataformas de IA. Ele rastreia quais modelos de IA estão usando seu conteúdo, com que frequência sua marca aparece em respostas geradas por IA e fornece visibilidade sobre o ecossistema mais amplo de sistemas de IA interagindo com suas propriedades digitais. Esse monitoramento ajuda você a entender o escopo do acesso de IA e tomar decisões informadas sobre sua estratégia de proteção de conteúdo.
Tenha visibilidade total sobre quais sistemas de IA estão acessando sua marca em GPTs, Perplexity, Google AI Overviews e outras plataformas. Acompanhe padrões de acesso de IA entre origens e entenda como seu conteúdo está sendo utilizado em treinamentos e inferências de IA.
Descubra como os sistemas de IA decidem entre citar múltiplas fontes ou concentrar-se em fontes autoritativas. Entenda os padrões de citação do ChatGPT, Google ...

Saiba como os sistemas de IA acessam conteúdos com paywall e restritos, as técnicas utilizadas e como proteger seu conteúdo enquanto mantém a visibilidade da su...
Descubra o que é atribuição de visibilidade em IA, como ela difere do SEO tradicional e por que monitorar a aparição da sua marca em respostas geradas por IA é ...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.