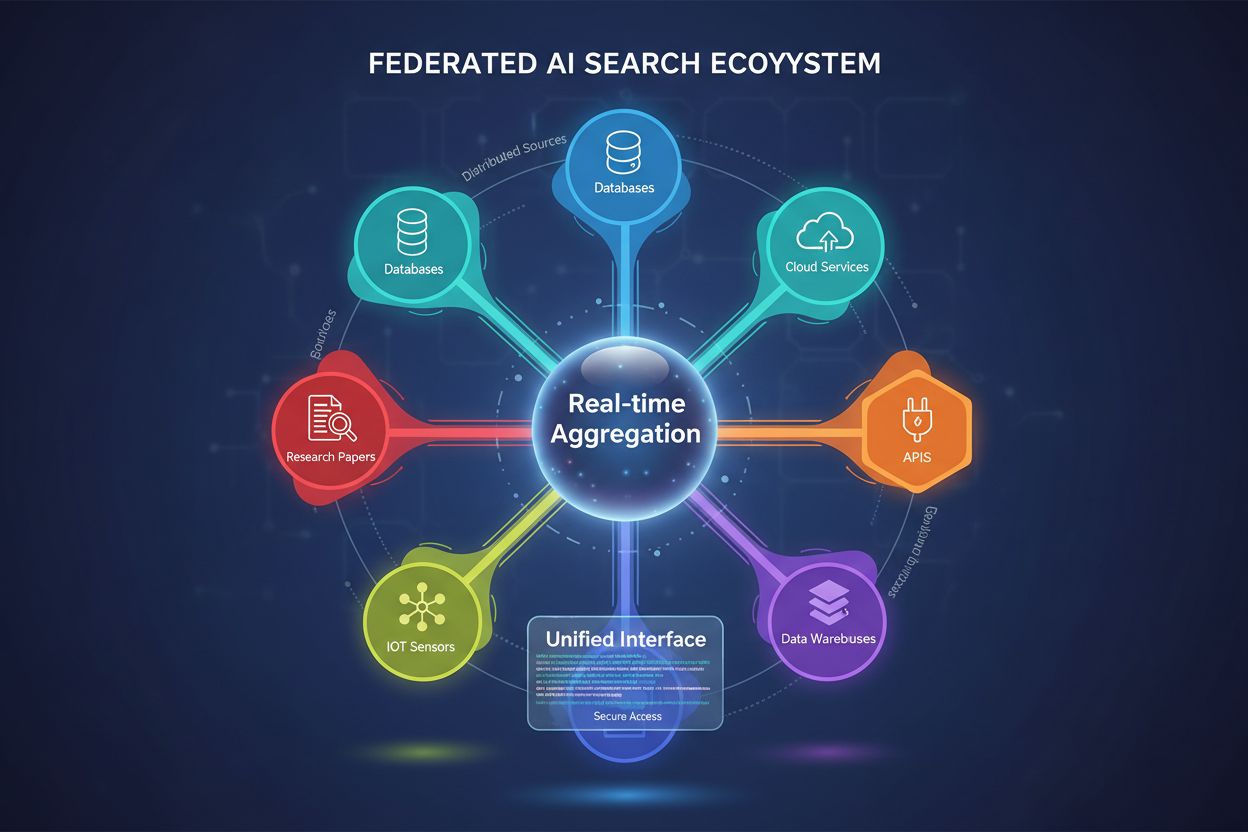
Busca Federada de IA é um sistema que consulta múltiplas fontes de dados independentes simultaneamente usando uma única consulta de busca e agrega os resultados em tempo real sem mover ou duplicar dados. Permite que organizações acessem informações distribuídas entre bancos de dados, APIs e serviços em nuvem, mantendo a segurança e conformidade dos dados. Diferente dos mecanismos de busca centralizados tradicionais, sistemas federados preservam a autonomia dos dados enquanto oferecem descoberta unificada de informações. Essa abordagem é especialmente valiosa para empresas que gerenciam fontes de dados diversas entre departamentos, regiões geográficas ou organizações diferentes.
Busca Federada de IA
Busca Federada de IA é um sistema que consulta múltiplas fontes de dados independentes simultaneamente usando uma única consulta de busca e agrega os resultados em tempo real sem mover ou duplicar dados. Permite que organizações acessem informações distribuídas entre bancos de dados, APIs e serviços em nuvem, mantendo a segurança e conformidade dos dados. Diferente dos mecanismos de busca centralizados tradicionais, sistemas federados preservam a autonomia dos dados enquanto oferecem descoberta unificada de informações. Essa abordagem é especialmente valiosa para empresas que gerenciam fontes de dados diversas entre departamentos, regiões geográficas ou organizações diferentes.
Definição Central & Principais Características
Busca Federada de IA é um sistema distribuído de recuperação de informações que consulta simultaneamente múltiplas fontes de dados heterogêneas e agrega os resultados de forma inteligente utilizando técnicas de inteligência artificial. Diferente dos mecanismos de busca centralizados tradicionais, que mantêm um único repositório indexado, a busca federada de IA opera em redes descentralizadas de bancos de dados independentes, bases de conhecimento e sistemas de informação sem exigir consolidação de dados ou indexação centralizada.
O princípio central subjacente à busca federada de IA é a consulta agnóstica à fonte, na qual uma única consulta do usuário é roteada de forma inteligente para as fontes de dados relevantes, processada independentemente por cada fonte e sintetizada em um conjunto de resultados unificado. Essa abordagem preserva a autonomia dos dados, ao mesmo tempo que viabiliza a descoberta abrangente de informações através de fronteiras organizacionais e técnicas.
As principais características dos sistemas de busca federada de IA incluem:
Arquitetura Distribuída: Os dados permanecem em seu local original, distribuídos por múltiplos repositórios, eliminando a necessidade de migração ou armazenamento centralizado. Cada fonte mantém sua própria indexação, controles de acesso e mecanismos de atualização de forma independente.
Roteamento Inteligente de Consultas: Algoritmos de IA analisam as consultas recebidas para determinar quais fontes têm maior probabilidade de conter informações relevantes, otimizando a eficiência da busca e reduzindo consultas desnecessárias a bases irrelevantes.
Agregação e Classificação de Resultados: Modelos de aprendizado de máquina sintetizam resultados de múltiplas fontes, aplicando algoritmos sofisticados de classificação que consideram credibilidade da fonte, relevância do resultado, atualidade e contexto do usuário.
Suporte a Fontes Heterogêneas: Sistemas federados acomodam diversos formatos de dados, esquemas, linguagens de consulta e protocolos de acesso, incluindo bancos de dados relacionais, repositórios de documentos, grafos de conhecimento, APIs e coleções de texto não estruturado.
Integração em Tempo Real: Diferente das abordagens de data warehousing em lote, a busca federada oferece acesso quase em tempo real às informações atuais de todas as fontes conectadas, garantindo atualidade e precisão dos resultados.
Compreensão Semântica: Sistemas modernos de busca federada de IA utilizam processamento de linguagem natural e análise semântica para entender a intenção da consulta além da correspondência de palavras-chave, permitindo seleção mais precisa de fontes e interpretação de resultados.
Como Funciona a Busca Federada de IA
O fluxo operacional da busca federada de IA envolve múltiplas etapas coordenadas, cada uma aprimorada por inteligência artificial para otimizar desempenho e qualidade dos resultados.
Etapa
Processo
Componente de IA
Saída
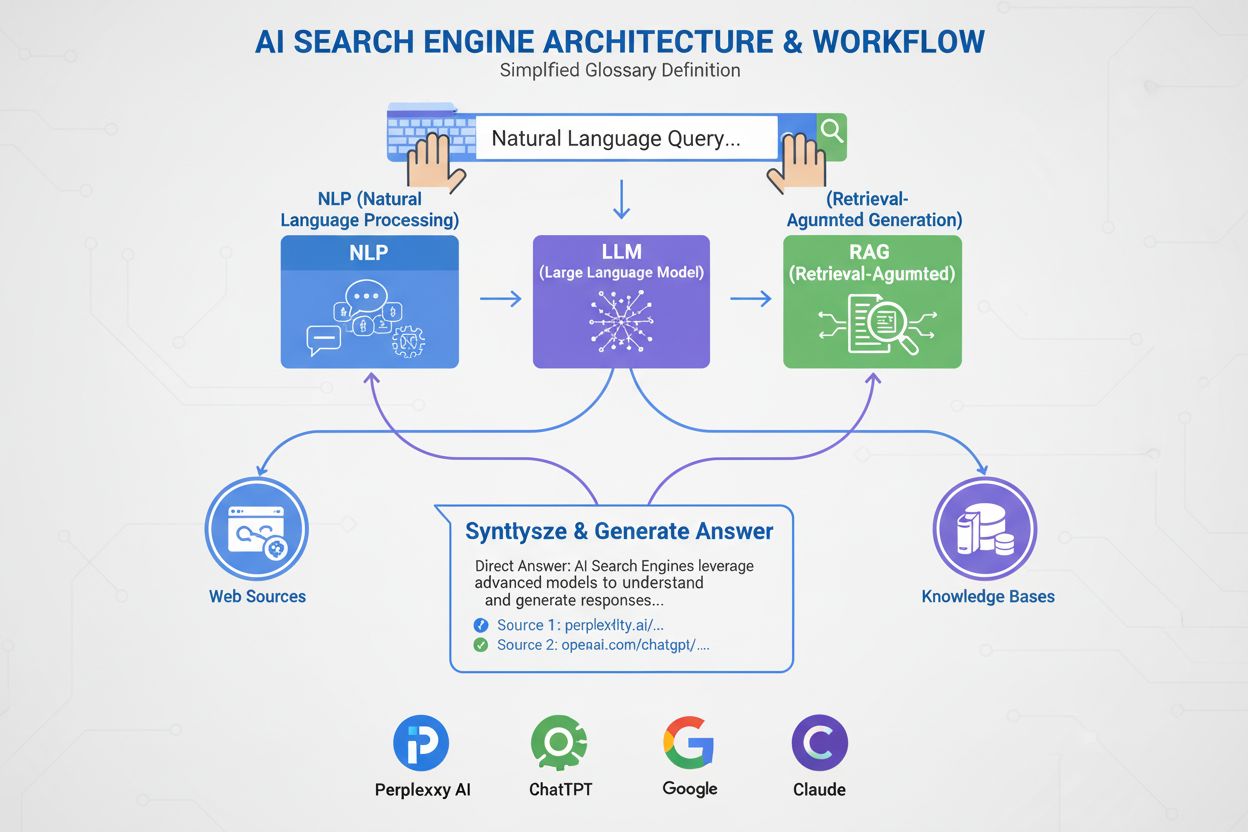
Análise da Consulta
A consulta do usuário é analisada para intenção, entidades e contexto
PLN, Reconhecimento de Entidades Nomeadas, Classificação de Intenção
Representação estruturada da consulta, entidades identificadas, sinais de intenção
Seleção de Fontes
O sistema determina quais fontes são mais relevantes para a consulta
Modelos de Classificação e Ranqueamento, Classificadores de Relevância de Fontes
Lista priorizada de fontes-alvo, escores de confiança
Tradução da Consulta
A consulta é convertida para formatos e linguagens específicos das fontes
Mapeamento de Esquema, Modelos de Tradução de Consultas, Correspondência Semântica
Consultas específicas por fonte (SQL, SPARQL, chamadas de API, etc.)
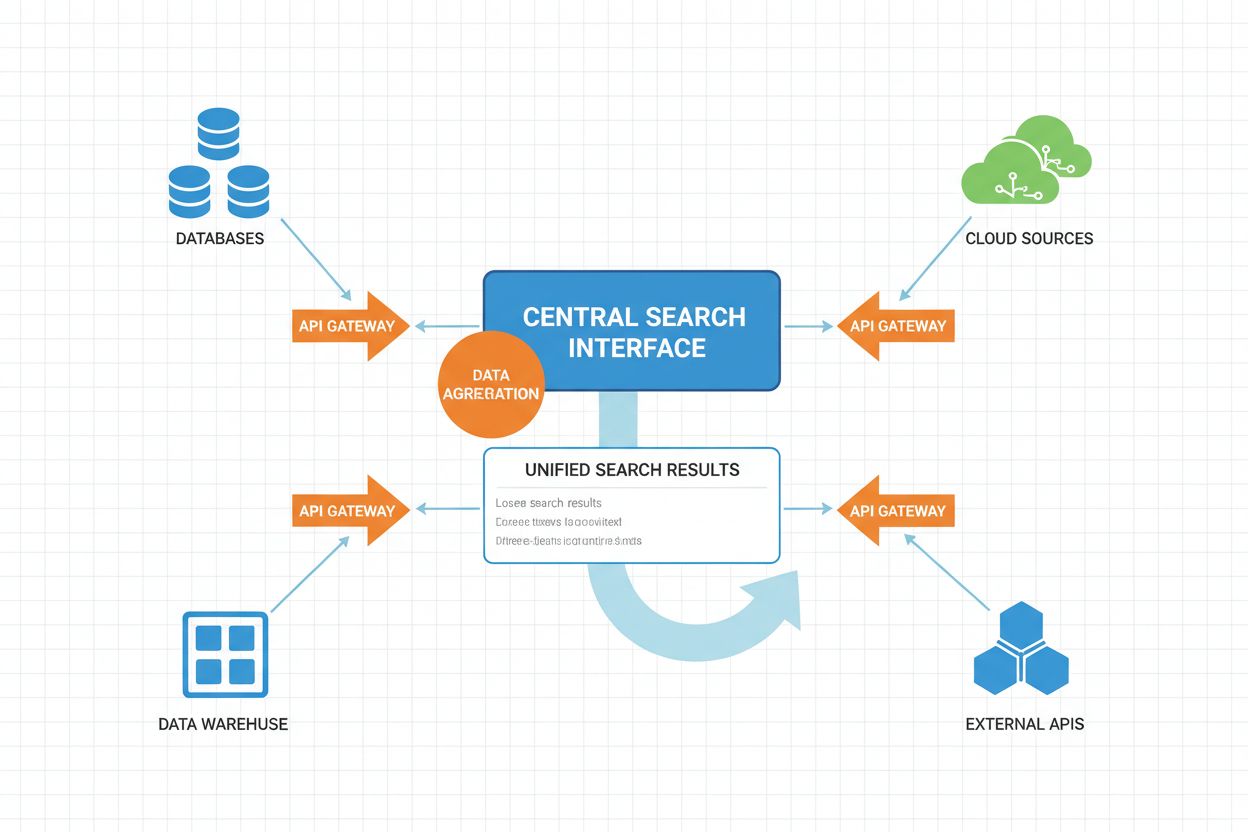
Execução Distribuída
Consultas são executadas em paralelo nas fontes selecionadas
Balanceamento de Carga, Gerenciamento de Timeout, Processamento Paralelo
Resultados brutos de cada fonte, metadados de execução
Normalização de Resultados
Resultados de diferentes fontes são convertidos para formato comum
Alinhamento de Esquemas, Conversão de Tipos de Dados, Padronização
Conjunto de resultados normalizados com estrutura consistente
Enriquecimento Semântico
Resultados enriquecidos com contexto e metadados adicionais
Vinculação de Entidades, Marcação Semântica, Integração com Grafos de Conhecimento
Resultados enriquecidos com anotações semânticas
Classificação e Deduplicação
Resultados classificados por relevância e duplicatas removidas
Modelos Learning-to-Rank, Detecção de Similaridade, Ranqueamento de Relevância
Lista de resultados deduplicada e ranqueada
Personalização
Resultados customizados conforme perfil e preferências do usuário
Filtro Colaborativo, Modelagem de Usuário, Consciência de Contexto
Ordenação personalizada dos resultados
Apresentação
Resultados formatados para visualização pelo usuário
Geração de Linguagem Natural, Resumo de Resultados
Exibição dos resultados para o usuário
O fluxo opera com execução paralela como princípio, onde múltiplas fontes são consultadas simultaneamente ao invés de sequencialmente. Essa paralelização reduz drasticamente a latência total da consulta, apesar do overhead de coordenação entre diversas fontes. Sistemas federados avançados implementam planejamento adaptativo de consultas, aprendendo com padrões históricos para otimizar seleção de fontes e estratégias de execução ao longo do tempo.
Mecanismos de Timeout e Fallback são componentes críticos para garantir a confiabilidade do sistema. Quando uma fonte responde lentamente ou falha, o sistema pode aguardar com timeouts adaptativos ou prosseguir com os resultados das fontes disponíveis, degradando graciosamente a completude dos resultados ao invés de falhar totalmente.
Sistemas de busca federada de IA podem ser categorizados em múltiplas dimensões:
Por Modelo de Arquitetura:
Busca Federada Centralizada: Um coordenador central gerencia o roteamento das consultas e a agregação dos resultados, mantendo metadados de todas as fontes. Simplifica a coordenação, mas cria um ponto único de falha.
Busca Federada Descentralizada: Arquitetura peer-to-peer onde qualquer nó pode iniciar buscas e coordenar resultados sem autoridade central. Oferece resiliência, mas aumenta a complexidade de coordenação.
Busca Federada Híbrida: Combina coordenação centralizada para funções principais com capacidades descentralizadas para redundância e escalabilidade.
Por Tipo de Fonte de Dados:
Federação de Dados Estruturados: Integra bancos de dados relacionais, data warehouses e repositórios estruturados com esquemas bem definidos.
Federação de Dados Não Estruturados: Busca em repositórios de documentos, coleções de texto e sistemas de gerenciamento de conteúdo sem restrições rígidas de esquema.
Federação de Grafos de Conhecimento: Consulta grafos de conhecimento distribuídos e redes semânticas, utilizando ontologias para integração inteligente.
Federação Baseada em API: Agrega resultados de múltiplos serviços web e APIs REST, lidando com diversos formatos de resposta e protocolos.
Federação de Conteúdo Híbrido: Combina múltiplos tipos de dados em um único sistema federado de busca.
Por Escopo e Escala:
Busca Federada Corporativa: Integra fontes de dados dentro de limites organizacionais, geralmente com acesso controlado e características conhecidas das fontes.
Busca Federada em Larga Escala: Opera em fontes acessíveis via internet com características desconhecidas ou variáveis, requerendo robustez frente a fontes não confiáveis.
Federação Específica de Domínio: Focada em setores ou domínios de conhecimento específicos, com tipos de fontes e critérios de ranqueamento especializados.
Por Nível de Inteligência:
Federação Básica: Roteamento simples de consultas e mesclagem de resultados, sem componentes avançados de IA.
Federação Inteligente: Incorpora aprendizado de máquina para seleção de fontes, ranqueamento e otimização da qualidade dos resultados.
Federação Semântica: Utiliza grafos de conhecimento, ontologias e compreensão semântica para integração profunda entre fontes heterogêneas.
Federação Autônoma: Sistemas auto-otimizáveis que aprendem e adaptam continuamente estratégias de seleção de fontes e ranqueamento.
Principais Benefícios & Vantagens
Autonomia e Governança de Dados: Organizações mantêm controle sobre seus dados, eliminando a necessidade de transferir informações sensíveis para repositórios centralizados. Isso preserva políticas de governança, requisitos de conformidade e controles de segurança no nível das fontes.
Escalabilidade sem Consolidação: Sistemas federados escalam com a adição de novas fontes sem exigir migração de dados ou reestruturação de data warehouses. Permite integração incremental de novas fontes conforme as necessidades de negócio evoluem.
Acesso em Tempo Real à Informação: Ao consultar as fontes diretamente, a busca federada fornece acesso a informações atuais sem a latência inerente a processos de data warehousing em lote. Isso é especialmente valioso para aplicações sensíveis ao tempo que exigem informação atualizada.
Eficiência de Custos: Elimina custos substanciais de infraestrutura e operação associados à construção e manutenção de data warehouses centralizados. As organizações evitam duplicação de dados, armazenamento redundante e processos complexos de ETL.
Redução de Redundância de Dados: Diferente do data warehousing, que duplica dados em múltiplos sistemas, a busca federada mantém fontes únicas de verdade, reduzindo o overhead de armazenamento e assegurando consistência.
Flexibilidade e Adaptabilidade: Novas fontes podem ser integradas sem modificar a infraestrutura existente ou reindexar repositórios centralizados. Essa flexibilidade permite resposta rápida a mudanças nas demandas de negócio.
Melhoria da Qualidade dos Dados: Ao consultar fontes autoritativas diretamente, a busca federada reduz a obsolescência e inconsistência dos dados provenientes de sincronizações periódicas em abordagens de warehousing.
Segurança Aprimorada: Dados sensíveis nunca deixam sua localização original, reduzindo exposição a acessos não autorizados ou violações. Os controles de acesso permanecem sob gestão das fontes, não de sistemas centralizados.
Suporte a Fontes Heterogêneas: Sistemas federados acomodam tecnologias, formatos e protocolos diversos sem exigir padronização ou migração para plataformas comuns.
Síntese Inteligente de Resultados: Ranqueamento e agregação impulsionados por IA produzem resultados de maior qualidade que simples mesclas, considerando credibilidade das fontes, relevância dos resultados e contexto do usuário.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Arquitetura Técnica & Componentes
Sistemas modernos de busca federada de IA são compostos por diversos componentes técnicos interconectados trabalhando em conjunto para fornecer capacidades integradas de busca.
Motor de Processamento de Consultas: Componente central que recebe as consultas dos usuários e orquestra o fluxo de busca federada. Inclui módulos de análise de consulta, análise semântica e reconhecimento de intenção. Implementações avançadas utilizam modelos de linguagem baseados em transformers para compreensão de semântica complexa e intenção implícita.
Registro de Fontes e Gerenciamento de Metadados: Mantém metadados abrangentes sobre as fontes disponíveis, incluindo informações de esquema, características do conteúdo, frequência de atualização, padrões de disponibilidade e métricas de desempenho. Permite seleção inteligente de fontes e otimização de consultas. Modelos de aprendizado de máquina analisam padrões históricos para prever relevância de fontes em novas consultas.
Módulo Inteligente de Seleção de Fontes: Utiliza classificadores de aprendizado de máquina para determinar quais fontes têm maior probabilidade de conter informações relevantes para uma consulta. Considera cobertura de conteúdo, taxas de sucesso históricas, disponibilidade e tempos de resposta estimados. Sistemas avançados empregam aprendizado por reforço para otimizar estratégias de seleção de fontes baseadas em resultados.
Camada de Tradução e Adaptação de Consultas: Converte consultas dos usuários em formatos e linguagens específicas de cada fonte. Inclui geração de SQL para bancos relacionais, SPARQL para grafos de conhecimento, chamadas REST para serviços web e consultas em linguagem natural para sistemas de texto não estruturado. O mapeamento semântico assegura que a intenção da consulta seja preservada em diferentes modelos e linguagens.
Coordenador de Execução Distribuída: Gerencia a execução paralela de consultas em múltiplas fontes, cuidando de gerenciamento de timeouts, balanceamento de carga e recuperação de falhas. Implementa estratégias adaptativas de timeout ajustadas por padrões de resposta das fontes e carga do sistema.
Motor de Normalização de Resultados: Converte resultados de fontes heterogêneas em formato comum para agregação e ranqueamento. Inclui alinhamento de esquemas, conversão de tipos de dados e padronização de formatos. Lida com campos ausentes, tipos conflitantes e diferenças estruturais entre fontes.
Módulo de Enriquecimento Semântico: Enriquece os resultados com contexto adicional e informações semânticas. Inclui vinculação de entidades a bases de conhecimento, marcação semântica via ontologias e extração de relacionamentos de texto não estruturado. Esses enriquecimentos melhoram a precisão do ranqueamento e compreensão dos resultados.
Modelo Learning-to-Rank: Modelo de aprendizado de máquina treinado em pares consulta-resultado históricos para prever relevância dos resultados. Considera centenas de características como credibilidade da fonte, atualidade do conteúdo, alinhamento com perfil do usuário e similaridade semântica entre consulta e resultado. Implementações modernas utilizam boosting ou redes neurais para ranqueamento.
Motor de Deduplicação: Identifica e remove resultados duplicados ou quase duplicados de diferentes fontes. Usa métricas de similaridade incluindo correspondência exata, fuzzy matching e similaridade semântica baseada em embeddings.
Motor de Personalização: Personaliza a ordenação dos resultados com base em perfis de usuário, preferências históricas e contexto. Implementa técnicas de recomendação colaborativa e baseada em conteúdo para melhorar a relevância individual.
Camada de Cache e Otimização: Implementa estratégias inteligentes de cache para reduzir consultas redundantes às fontes. Inclui cache de resultados, cache de metadados de fontes e padrões de consulta aprendidos para prever futuras necessidades de informação.
Módulo de Monitoramento e Analytics: Monitora desempenho do sistema, confiabilidade das fontes, padrões de consulta e métricas de qualidade dos resultados. Os dados realimentam componentes de otimização, permitindo melhoria contínua do sistema.
Casos de Uso em Diversos Setores
Saúde e Pesquisa Médica: Integra prontuários de pacientes entre sistemas hospitalares, bancos de dados de pesquisa, registros de ensaios clínicos e repositórios de literatura médica. Médicos consultam históricos completos sem centralizar dados sensíveis. Pesquisadores acessam dados clínicos distribuídos para estudos epidemiológicos mantendo conformidade com HIPAA e privacidade.
Serviços Financeiros: Bancos e corretoras usam busca federada para consultar simultaneamente dados de negociação, informações de mercado, bancos regulatórios e registros internos de transações. Permite avaliação de risco em tempo real, monitoramento de conformidade e análise de mercado sem consolidar dados sensíveis.
Jurídico e Compliance: Escritórios de advocacia e departamentos jurídicos buscam em bases de jurisprudência, repositórios regulatórios, sistemas internos de documentos e bancos de contratos. Permite pesquisa jurídica abrangente mantendo sigilo profissional e confidencialidade.
E-commerce e Varejo: Varejistas online integram catálogos de produtos entre múltiplos armazéns, sistemas de fornecedores e marketplaces. Busca federada oferece descoberta unificada de produtos enquanto fornecedores mantêm sistemas e preços independentes.
Governo e Administração Pública: Órgãos governamentais buscam em bancos de dados distribuídos como dados do censo, registros fiscais, sistemas de licenças e registros públicos sem centralizar informações sensíveis. Oferece serviços públicos abrangentes mantendo segurança e privacidade.
Manufatura e Cadeia de Suprimentos: Indústrias integram bancos de fornecedores, sistemas de estoque, registros de produção e plataformas logísticas. Busca federada oferece visibilidade da cadeia sem obrigar parceiros a abrir sistemas e informações proprietárias.
Educação e Pesquisa: Universidades buscam em repositórios institucionais, sistemas de bibliotecas, bases de pesquisa e publicações de acesso aberto. Permite descoberta acadêmica completa respeitando autonomia institucional e direitos de propriedade intelectual.
Telecomunicações: Operadoras buscam em bases de clientes, registros de infraestrutura, sistemas de faturamento e catálogos de serviços. Proporciona atendimento unificado mantendo sistemas separados por linha de serviço e região.
Energia e Utilidades: Empresas de energia buscam em usinas, redes de distribuição, bancos de clientes e sistemas regulatórios. Oferece visibilidade operacional sem exigir integração total entre operadores regionais.
Mídia e Editoração: Organizações de mídia buscam em repositórios de conteúdo, arquivos, sistemas de direitos autorais e plataformas de distribuição. Permite descoberta de conteúdo completa preservando propriedade e restrições de licenciamento.
Desafios & Limitações
Heterogeneidade das Fontes e Complexidade de Integração: Integrar fontes de dados diversas com esquemas, linguagens de consulta e protocolos distintos exige grande esforço de engenharia. Mapeamento de esquemas e alinhamento semântico ainda são desafios, especialmente quando fontes representam conceitos de formas diferentes.
Latência e Desempenho das Consultas: Buscar em múltiplas fontes naturalmente introduz latência em relação a sistemas centralizados. Fontes lentas ou não responsivas degradam o desempenho global. O gerenciamento de timeouts precisa de ajuste cuidadoso para equilibrar completude e resposta.
Confiabilidade e Disponibilidade das Fontes: Sistemas federados dependem da disponibilidade e responsividade das fontes externas. Falhas de rede, indisponibilidade ou degradação das fontes afetam diretamente a qualidade da busca. É necessária degradação graciosa quando fontes falham.
Qualidade dos Resultados e Precisão de Ranqueamento: Agregar resultados de fontes com níveis distintos de qualidade, cobertura e critérios de relevância é desafiador. Modelos de ranqueamento precisam considerar variações de credibilidade e evitar enviesamento para certas fontes.
Atualização e Consistência dos Dados: Sistemas federados acessam dados atuais das fontes, mas estas podem ter frequências de atualização e garantias de consistência diferentes. Conciliar informações conflitantes exige estratégias sofisticadas de resolução de conflitos.
Limitações de Escalabilidade: Com o aumento do número de fontes, cresce o overhead de coordenação das consultas. Selecionar fontes relevantes entre milhares se torna computacionalmente caro. Execução paralela em larga escala requer infraestrutura robusta.
Segurança e Controle de Acesso: Sistemas federados devem impor controles de acesso por fonte, mesmo fornecendo interfaces unificadas. Garantir que usuários só acessem informações permitidas em múltiplas fontes é complexo, especialmente em ambientes multi-inquilino.
Privacidade e Proteção de Dados: A busca federada deve atender a regulamentos como GDPR, CCPA e exigências setoriais. É fundamental evitar vazamento de dados sensíveis por agregação de resultados ou análise de metadados.
Descoberta e Gerenciamento de Fontes: Identificar, catalogar, manter metadados e gerenciar o ciclo de vida (adição, remoção, atualização) das fontes exige esforço operacional contínuo.
Interoperabilidade Semântica: Alcançar verdadeira interoperabilidade semântica entre fontes com ontologias e modelos de dados diferentes é desafiador. Técnicas automáticas de mapeamento de esquemas e resolução de entidades têm limitações.
Custo de Coordenação: Embora elimine custos de consolidação, a busca federada introduz overhead de coordenação. Gerenciar execução distribuída, falhas e otimização de roteamento requer infraestrutura sofisticada.
Baixa Padronização: A ausência de padrões universais para protocolos e interfaces de busca federada dificulta a integração e aumenta o risco de dependência de fornecedores.
Busca Federada de IA vs. Tecnologias Relacionadas
Busca Federada de IA vs. Data Warehousing: O data warehousing consolida dados de múltiplas fontes em um repositório centralizado, permitindo consultas rápidas, mas exigindo grande esforço de ETL e introduzindo latência. A busca federada consulta fontes diretamente, oferecendo acesso em tempo real, porém com maior latência de consulta. O warehousing é adequado para análise histórica e relatórios, enquanto a busca federada se destaca na descoberta de informações atuais.
Busca Federada de IA vs. Data Lakes: Data lakes armazenam dados brutos de múltiplas fontes em local centralizado com mínima transformação. Oferecem flexibilidade, mas exigem grande capacidade de armazenamento e governança. Busca federada evita consolidação total, mantendo autonomia das fontes, mas requer processamento de consultas mais sofisticado.
Busca Federada de IA vs. APIs e Microsserviços: APIs fornecem acesso programático a serviços individuais, mas exigem conhecimento prévio de suas interfaces. Busca federada abstrai detalhes específicos das fontes, permitindo consultas unificadas entre serviços. APIs são adequadas para integração entre aplicações, enquanto busca federada viabiliza descoberta de informações cruzando serviços.
Busca Federada de IA vs. Grafos de Conhecimento: Grafos de conhecimento representam informações como entidades e relacionamentos, permitindo raciocínio semântico. Busca federada pode consultar grafos distribuídos, mas não exige construção centralizada de grafos. Grafos oferecem entendimento semântico profundo, enquanto busca federada prioriza a autonomia das fontes.
Busca Federada de IA vs. Motores de Busca: Motores de busca tradicionais mantêm índices centralizados do conteúdo rastreado. Busca federada consulta diretamente as fontes, sem pré-indexação. Motores cobrem conteúdo público, enquanto busca federada integra fontes privadas, proprietárias ou especializadas.
Busca Federada de IA vs. Master Data Management (MDM): MDM cria registros mestres autoritativos consolidando dados de várias fontes. Busca federada consulta fontes de modo independente, sem criar registros mestres. MDM é adequado para governança e consistência, enquanto busca federada prioriza autonomia e acesso em tempo real.
Busca Federada de IA vs. Busca Corporativa: Busca corporativa normalmente indexa documentos e bancos internos em um índice centralizado. Busca federada consulta as fontes diretamente, sem indexação central. Busca corporativa oferece pesquisa textual rápida, enquanto busca federada acomoda tipos de fontes diversos e atualizações em tempo real.
Busca Federada de IA vs. Blockchain e Ledgers Distribuídos: Blockchain mantém consenso distribuído, garantindo integridade e imutabilidade. Busca federada coordena consultas em fontes independentes, sem exigir consenso. Blockchain é adequado para confiança e verificação, enquanto busca federada prioriza descoberta de informações.
Melhores Práticas de Implementação
Avaliação Abrangente das Fontes: Antes de integrar, avalie qualidade dos dados, frequência de atualização, disponibilidade, complexidade do esquema e protocolos de acesso de cada fonte. Essa avaliação orienta algoritmos de seleção de fontes e define expectativas realistas de desempenho.
Integração Incremental: Comece com poucas fontes bem compreendidas, expandindo gradualmente o sistema federado. Permite identificar desafios cedo e refinar processos antes de escalar.
Gestão Robusta de Metadados: Invista em metadados abrangentes sobre esquemas, cobertura, métricas de qualidade e desempenho das fontes. Mantenha a precisão dos metadados por monitoramento automático e validação periódica.
Seleção Inteligente de Fontes: Implemente seleção baseada em aprendizado de máquina, aprendendo com resultados das consultas. Monitore quais fontes trazem resultados relevantes e otimize as estratégias continuamente.
Gerenciamento Adaptativo de Timeouts: Implemente timeouts adaptativos baseados nos padrões de resposta das fontes e carga do sistema. Evite timeouts fixos que prejudicam tanto fontes lentas quanto rápidas.
Garantia de Qualidade dos Resultados: Defina métricas de qualidade como relevância, atualidade e completude. Implemente mecanismos de feedback dos usuários para alimentar o treinamento dos modelos de ranqueamento.
Monitoramento Abrangente: Monitore disponibilidade das fontes, tempos de resposta, qualidade dos resultados e satisfação do usuário. Use esses dados para identificar fontes problemáticas e otimizar o sistema.
Segurança e Controle de Acesso: Implemente controles de acesso por fonte, assegurando que usuários só vejam o que lhes é permitido, mesmo ao consultar múltiplas fontes.
Estratégias de Cache: Implemente cache inteligente de resultados de consultas, metadados de fontes e padrões aprendidos. Equilibre frescor dos dados com benefícios de desempenho.
Otimização da Experiência do Usuário: Crie interfaces que comuniquem claramente as fontes dos resultados, níveis de confiança e atualidade. Informe ao usuário quais fontes foram consultadas e por que certos resultados têm destaque.
Otimização de Performance: Analise a execução das consultas para identificar gargalos. Otimize algoritmos de seleção de fontes, tradução de consultas e agregação de resultados. Considere pré-computar padrões comuns de consulta.
Aprendizado Contínuo: Implemente loops de feedback capturando interações do usuário para melhorar continuamente seleção de fontes, modelos de ranqueamento e apresentação dos resultados.
Documentação e Governança: Mantenha documentação completa sobre características das fontes, abordagens de integração e arquitetura do sistema. Estabeleça políticas para adição, remoção e modificação de fontes.
Testes e Validação: Implemente testes abrangentes incluindo unitários para componentes, integração para interações com fontes e ponta a ponta para fluxos completos. Valide a qualidade dos resultados com dados de referência conhecidos.
Tendências Futuras & Integração de IA
Compreensão Avançada de Linguagem Natural: Sistemas federados futuros utilizarão grandes modelos de linguagem e técnicas avançadas de PLN para entender consultas complexas, multifacetadas, com contexto implícito e intenção sutil. Isso permite seleção e interpretação mais precisas.
Descoberta Autônoma de Fontes: Sistemas baseados em aprendizado de máquina descobrirão e catalogarão fontes automaticamente, avaliando relevância e qualidade, e integrando-as com mínima intervenção humana. Isso resolve o desafio atual de gerenciamento manual.
Integração com a Web Semântica: À medida que tecnologias da web semântica amadurecem, sistemas federados utilizarão ontologias e padrões de dados ligados para interoperabilidade semântica profunda. Isso permite raciocínio sofisticado e melhor tratamento de modelos heterogêneos.
IA Explicável e Transparência: Sistemas futuros fornecerão explicações detalhadas sobre decisões de ranqueamento, seleção de fontes e agregação de resultados. Essa transparência aumenta a confiança do usuário e o entendimento do funcionamento do sistema.
Integração com Aprendizado Federado: Técnicas de aprendizado federado permitirão treinar modelos de IA em fontes distribuídas sem centralizar dados. Isso combina a autonomia da busca federada com o poder preditivo do aprendizado de máquina.
Integração com Fluxos em Tempo Real: Sistemas federados integrarão cada vez mais fluxos de dados em tempo real além de bancos tradicionais, permitindo buscas em fontes de informação continuamente atualizadas.
Busca Multimodal: Sistemas federados do futuro buscarão em diversos tipos de conteúdo, incluindo texto, imagens, vídeo e áudio. Modelos de IA multimodais permitirão busca cruzada e síntese de resultados entre diferentes mídias.
Personalização e Consciência de Contexto: Modelagem avançada de usuários e compreensão de contexto permitirão experiências altamente personalizadas. Os sistemas compreenderão níveis de expertise, necessidades e preferências para customizar a apresentação dos resultados.
Aplicações de Computação Quântica: Com a maturidade da computação quântica, sistemas federados poderão utilizar algoritmos quânticos para otimização de seleção de fontes e ranqueamento, potencializando processamento mais rápido.
Integração com Blockchain: Sistemas federados poderão integrar blockchain para verificação de fontes, rastreamento de proveniência dos resultados e coordenação descentralizada, especialmente em aplicações críticas de confiança.
Edge Computing e Processamento Distribuído: A busca federada utilizará edge computing para processar consultas mais próximas das fontes de dados, reduzindo latência, overhead de rede e melhorando privacidade.
Otimização Autônoma: Sistemas federados auto-otimizáveis aprenderão continuamente com padrões de consultas, características das fontes e feedback dos usuários para melhorar o desempenho sem intervenção humana.
Integração de Conhecimento Entre Domínios: Sistemas futuros cruzarão conhecimentos entre domínios tradicionalmente separados, permitindo descoberta de conexões e insights inesperados ao combinar fontes diversas.
Perguntas frequentes
Qual é a principal diferença entre busca federada de IA e busca centralizada tradicional?
A busca centralizada tradicional consolida todos os dados em um único repositório indexado, exigindo migração de dados e introduzindo latência. A busca federada de IA consulta múltiplas fontes independentes diretamente em tempo real sem mover ou duplicar dados, preservando a autonomia das fontes ao mesmo tempo que oferece acesso unificado. Isso torna a busca federada ideal para organizações com fontes de dados distribuídas e requisitos rigorosos de governança de dados.
Como a busca federada de IA mantém segurança e conformidade?
A busca federada de IA mantém os dados em sua localização original e respeita os controles de acesso e políticas de segurança de cada fonte. Os usuários acessam apenas as informações para as quais têm autorização, e dados sensíveis nunca deixam o sistema de origem. Essa abordagem simplifica a conformidade com regulamentações como GDPR e HIPAA ao eliminar os riscos associados à centralização de informações sensíveis.
Quais são os principais desafios na implementação de busca federada de IA?
Os principais desafios incluem gerenciar fontes de dados heterogêneas com diferentes esquemas e formatos, lidar com a latência de consulta proveniente de múltiplas fontes, garantir consistência na classificação dos resultados entre as fontes e manter a confiabilidade do sistema quando fontes ficam indisponíveis. As organizações também precisam investir em gerenciamento robusto de metadados e algoritmos inteligentes de seleção de fontes para otimizar o desempenho.
A busca federada de IA pode escalar à medida que as fontes de dados crescem?
Sim, a busca federada de IA escala adicionando novas fontes sem exigir migração de dados ou reestruturação de data warehouses. No entanto, à medida que o número de fontes aumenta, o overhead de coordenação das consultas também cresce. Sistemas modernos utilizam aprendizado de máquina para seleção inteligente de fontes e implementam estratégias de cache para manter o desempenho em escala.
Como a busca federada de IA difere de data warehousing?
O data warehousing consolida dados em um repositório centralizado, permitindo consultas rápidas, mas exigindo grande esforço de ETL e introduzindo latência. A busca federada consulta fontes diretamente, oferecendo acesso em tempo real, porém com maior latência de consulta. O warehousing é adequado para análise histórica e relatórios, enquanto a busca federada é ideal para descoberta de informações atuais em fontes distribuídas.
Quais setores se beneficiam mais da busca federada de IA?
Saúde, finanças, e-commerce, governo e organizações de pesquisa se beneficiam significativamente da busca federada. A saúde a utiliza para integrar prontuários de pacientes entre provedores, as finanças para conformidade e avaliação de riscos, o e-commerce para descoberta unificada de produtos e organizações de pesquisa para buscar informações em bancos de dados acadêmicos distribuídos.
Como a IA aprimora as capacidades da busca federada?
A IA aprimora a busca federada através de processamento de linguagem natural para compreensão das consultas, aprendizado de máquina para seleção inteligente de fontes, análise semântica para melhor classificação dos resultados e deduplicação automatizada. Modelos de IA aprendem com padrões de consultas para otimizar continuamente a seleção de fontes e a agregação de resultados, melhorando o desempenho ao longo do tempo.
Qual é o papel do entendimento semântico na busca federada de IA?
O entendimento semântico permite que sistemas federados compreendam a intenção da consulta para além da correspondência de palavras-chave, identifiquem fontes relevantes com mais precisão e classifiquem os resultados com base no significado e não apenas na sobreposição de palavras. Isso inclui reconhecimento de entidades, extração de relacionamentos e integração com grafos de conhecimento, resultando em respostas mais relevantes e adequadas ao contexto.
Monitore Como a IA Referencia Sua Marca
O AmICited rastreia como sistemas de IA como ChatGPT, Perplexity e Google AI Overviews citam e referenciam sua marca. Entenda sua visibilidade em IA e otimize sua presença em respostas geradas por IA.
O que é o Funil de Busca por IA e Como Ele Transforma a Descoberta do Cliente?
Entenda como os funis de busca por IA funcionam de maneira diferente dos funis de marketing tradicionais. Saiba como sistemas de IA como o ChatGPT e o Google AI...
Saiba o que são mecanismos de busca com IA, como diferem dos mecanismos tradicionais e seu impacto na visibilidade de marcas. Explore plataformas como Perplexit...
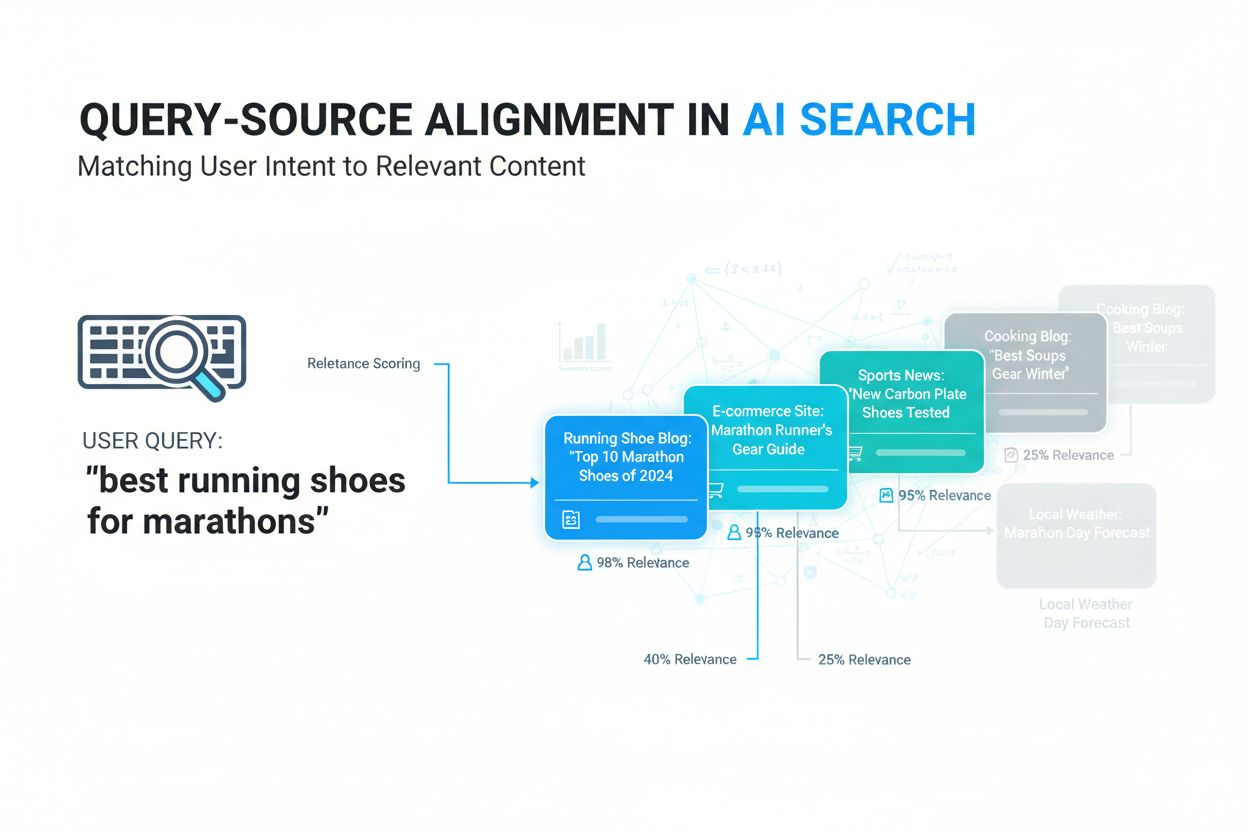
Saiba o que é alinhamento consulta-fonte, como sistemas de IA conectam consultas dos usuários a fontes relevantes e por que isso é importante para a visibilidad...
15 min de leitura
Consentimento de Cookies Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.