URL-uri canonice și AI: Prevenirea problemelor de conținut duplicat
Află cum previn URL-urile canonice problemele de conținut duplicat în sistemele de căutare AI. Descoperă cele mai bune practici pentru implementarea canonicalelor pentru a îmbunătăți vizibilitatea în AI și a asigura atribuirea corectă a conținutului.
Publicat la Jan 3, 2026.Ultima modificare la Jan 3, 2026 la 3:24 am
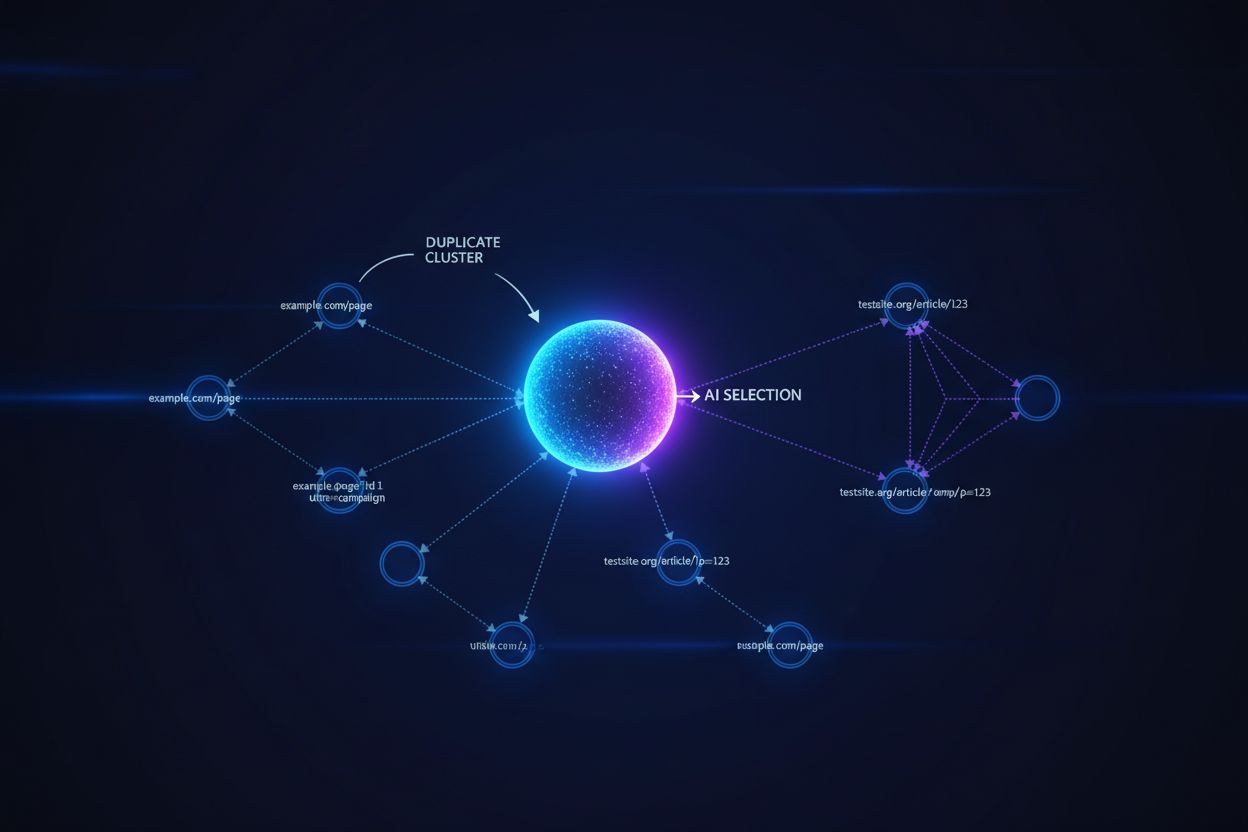
Modelele lingvistice mari și sistemele de căutare AI utilizează algoritmi sofisticați de grupare pentru a identifica și a grupa URL-urile aproape identice, tratând mai multe versiuni ale aceluiași conținut ca o singură entitate pentru scopuri de clasare și citare. Când sistemele AI întâlnesc conținut duplicat, trebuie să aleagă ce versiune să prioritizeze—o decizie care influențează direct ce URL primește vizibilitate, semnale de autoritate și atribuirea utilizatorului. Problema critică apare când AI-ul selectează versiunea greșită: dacă URL-ul tău canonic indică pagina preferată, dar sistemul AI grupează și clasează un duplicat de calitate inferioară, conținutul tău pierde vizibilitate și credit pentru citare. Semnalele de intenție devin diluate între diferite versiuni, fragmentând autoritatea ce ar trebui să se concentreze pe un singur URL, iar fiecare duplicat primește semnale de clasare mai slabe decât dacă toată autoritatea ar fi fost unificată pe versiunea canonică.
De ce contează URL-urile canonice pentru vizibilitatea în AI
Etichetele canonice servesc drept semnale explicite pentru sistemele AI despre ce versiune a unui conținut duplicat ar trebui considerată autoritară, influențând direct dacă URL-ul tău preferat apare în răspunsurile generate de AI și primește atribuirea corectă. Fără etichete canonice, sistemele AI trebuie să ia propriile decizii de grupare pe baza similarității conținutului, pattern-urilor de linkuri și semnalelor de prospețime—adesea rezultând în alegerea greșită drept sursă canonică. Când există conținut duplicat fără implementare canonicală corectă, răspunsurile AI pot cita o versiune republicată, o copie cache sau o variantă de calitate inferioară în locul conținutului tău original, fragmentând vizibilitatea pe mai multe URL-uri. URL-urile canonice asigură că, atunci când AI-urile întâlnesc conținutul tău pe diferite domenii, parametri sau versiuni, ele înțeleg ce URL unic trebuie să primească credit și să fie evidențiat în răspunsuri.
Scenariu
Fără canonic
Cu canonic
Impact asupra AI
AI grupează duplicatele independent; poate selecta versiunea greșită pentru clasare
AI recunoaște sursa autoritară; consolidează toate semnalele pe URL-ul canonic
Credit pentru citare
Atribuirea este dispersată pe mai multe URL-uri; autoritate mai slabă pe fiecare URL
Toate citările și autoritatea se transferă către URL-ul canonic; vizibilitate mai puternică
Rezultat
Conținutul apare în răspunsurile AI, dar URL-ul greșit primește credit; vizibilitate fragmentată
URL-ul preferat apare în răspunsurile AI cu semnale de autoritate consolidate
URL-uri canonice vs. redirecționări: când să le folosești
Etichetele canonice și redirecționările au scopuri diferite în gestionarea conținutului duplicat pentru sistemele AI: etichetele canonice indică motoarelor de căutare și AI care versiune este preferată, păstrând ambele URL-uri accesibile, în timp ce redirecționările trimit permanent utilizatorii și crawlerii de la un URL la altul. Redirecționările (301 pentru mutări permanente, 302 pentru temporare) sunt semnale mai puternice deoarece consolidează toată autoritatea pe un singur URL și elimină complet duplicatul de pe web, fiind ideale când retragi definitiv un URL sau consolidezi domenii. Etichetele canonice sunt preferabile atunci când trebuie să menții mai multe URL-uri din motive de business—precum parametri de tracking pentru analytics, păstrarea URL-urilor vechi pentru bookmarks sau servirea unor versiuni diferite pentru audiențe diferite—semnalând totodată AI-urilor ce versiune este autoritară. Folosește redirecționări când consolidezi domenii după o migrare, elimini versiuni învechite sau elimini variații de parametri fără scop distinct. Folosește etichete canonice atunci când trebuie să menții mai multe URL-uri, dar vrei să previi penalizările pentru conținut duplicat și să te asiguri că AI-urile înțeleg versiunea preferată.
Diferențe cheie între canonicale și redirecționări:
Experiența utilizatorului: Redirecționările trimit utilizatorii către un singur URL; canonicalele îi mențin pe URL-ul original, semnalând preferința către AI
Consolidarea autorității: Redirecționările transferă complet autoritatea pe un singur URL; canonicalele distribuie autoritatea, semnalând totodată preferința
Eficiența crawlingului: Redirecționările reduc crawl-ul inutil eliminând duplicatele; canonicalele necesită crawling pe ambele versiuni
Complexitatea implementării: Canonicalele necesită implementare HTML/header; redirecționările necesită configurare la nivel de server
Reversibilitate: Canonicalele pot fi schimbate ușor; redirecționările sunt permanente și mai greu de inversat fără a afecta experiența utilizatorului
Probleme comune de conținut duplicat în căutarea AI
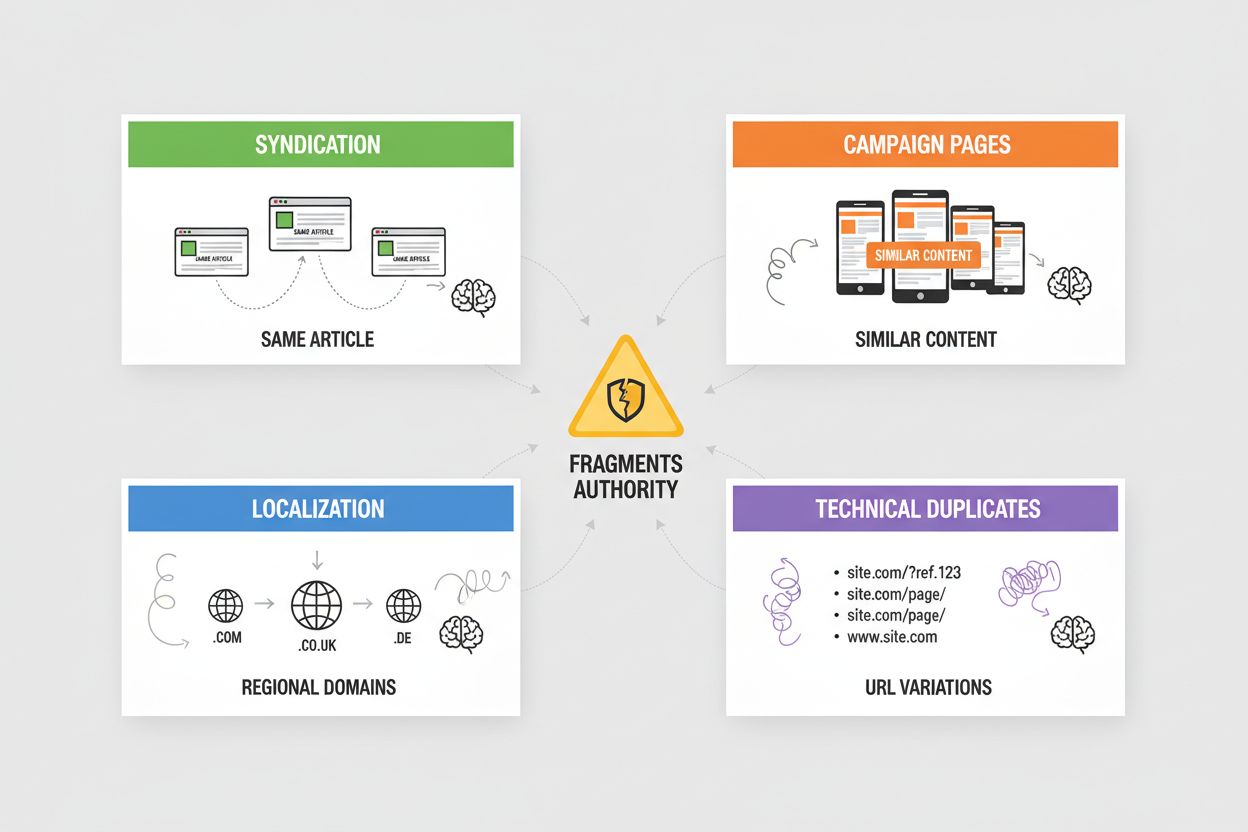
Republicarea generează conținut duplicat pe scară largă când articolele tale sunt republicate pe site-uri partenere, agregatoare de știri sau rețele de conținut—AI-urile trebuie să determine dacă să acorde credit sursei originale sau versiunii republicate, deseori alegând pe cea întâlnită prima dată la crawling. Paginile de campanie creează duplicate când realizezi mai multe landing page-uri cu conținut identic sau aproape identic pentru diverse canale de marketing, parametri UTM sau testare A/B, determinând AI-urile să fragmenteze autoritatea între variații care de fapt ar trebui consolidate. Localizarea și internaționalizarea generează duplicate când servești conținut similar pe domenii regionale (exemplu.com, exemplu.co.uk, exemplu.de) sau pe versiuni lingvistice, necesitând etichete hreflang și implementare canonicală pentru a preveni tratarea de către AI a acestor variante ca duplicate și nu ca variații intenționate. Duplicatele tehnice apar din ID-uri de sesiune, parametri de tracking, versiuni printer-friendly și variații de URL (www vs. non-www, http vs. https, slash la final) care duc toate la același conținut—AI-urile le văd ca duplicate și trebuie să decidă ce versiune să prioritizeze. Fiecare scenariu diluează autoritatea ce ar trebui să se concentreze pe URL-ul preferat, reducând vizibilitatea în răspunsurile AI și dispersând creditul pentru citare pe mai multe versiuni.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Cele mai bune practici pentru implementarea URL-urilor canonice
Folosește întotdeauna URL-uri absolute în etichetele canonice, nu relative, pentru a asigura identificarea fără echivoc a URL-ului țintă de către sistemele AI și motoarele de căutare, indiferent unde apare eticheta. Include canonicale auto-referențiale pe paginile preferate—chiar și paginile fără duplicate ar trebui să se refere la ele însele ca fiind canonice, prevenind inferențele AI bazate pe pattern-uri de linkuri sau similaritate de conținut. Plasează etichetele canonice în secțiunea <head> a documentului HTML, iar pentru conținut non-HTML (PDF-uri, imagini), implementează canonicale prin headere HTTP pentru ca AI-urile să-ți recunoască preferința indiferent de tipul de conținut.
<!-- Implementare corectă a canonicalului în head-ul HTML --><linkrel="canonical"href="https://exemplu.com/articol/url-uri-canonice-ai" />
Include URL-urile canonice în sitemap-urile XML pentru a întări care versiuni sunt autoritare și combină canonicalele cu etichete hreflang când gestionezi conținut internațional sau localizat pentru a preveni ca AI-urile să trateze variațiile regionale ca duplicate. Evită greșelile comune: nu crea niciodată lanțuri de canonicale (A→B→C), nu indica canonicale către pagini noindex și nu folosi canonicale pentru a manipula clasările direcționând către conținut fără legătură. Monitorizează implementarea canonicalelor cu unelte precum Google Search Console, Bing Webmaster Tools și AmICited.com pentru a verifica dacă sistemele AI recunosc URL-urile tale preferate și atribuie conținutul corect.
<!-- Implementare corectă cu hreflang pentru conținut internațional --><linkrel="canonical"href="https://exemplu.com/articol/url-uri-canonice-ai" />
<linkrel="alternate"hreflang="en-GB"href="https://exemplu.co.uk/articol/url-uri-canonice-ai" />
<linkrel="alternate"hreflang="de"href="https://exemplu.de/artikel/url-uri-canonice-ai" />
Monitorizare și remediere a problemelor canonice
Auditează URL-urile canonice prin crawling-ul întregului site cu unelte precum Screaming Frog, SEMrush sau Ahrefs pentru a identifica paginile fără canonicale, cu lanțuri canonice greșite sau canonicale care indică spre pagini noindex—aceste probleme împiedică AI-urile să consolideze corect autoritatea. Folosește raportul Coverage din Google Search Console pentru a identifica paginile cu probleme de conținut duplicat și a verifica dacă Google recunoaște preferințele tale canonice, apoi verifică și în Bing Webmaster Tools pentru consistență între sistemele AI. Implementează IndexNow pentru a notifica motoarele de căutare și crawlerii AI imediat ce adaugi, actualizezi sau elimini etichete canonice, accelerând astfel recunoașterea preferințelor tale fără a aștepta ciclurile naturale de crawling. Monitorizează citările AI cu AmICited.com și căutări manuale în ChatGPT, Claude și Perplexity ca să verifici dacă URL-urile preferate primesc atribuirea în răspunsurile generate de AI—dacă duplicatele sunt citate în locul canonicalului, revizuiește implementarea canonicalelor și asigură-te că etichetele sunt formatate și plasate corect. Auditează regulat pentru conținut duplicat nou creat prin parteneriate de republicare, lansări de campanii sau schimbări tehnice, implementând canonicalele proactiv pentru a menține vizibilitatea constantă în AI.
Întrebări frecvente
Ce este un URL canonic și de ce contează pentru căutarea AI?
Un URL canonic este versiunea preferată a unei pagini pe care vrei ca motoarele de căutare și sistemele AI să o recunoască drept autoritară. Contează pentru căutarea AI deoarece LLM-urile grupează URL-urile aproape identice și selectează o versiune care să reprezinte setul. Fără o implementare corectă a canonicalelor, AI-ul poate cita versiunea greșită a conținutului tău, fragmentând vizibilitatea și atribuirea pe mai multe URL-uri.
Cum gestionează sistemele AI conținutul duplicat diferit față de motoarele de căutare tradiționale?
Sistemele AI folosesc algoritmi de grupare pentru a organiza URL-urile aproape identice într-o singură entitate, apoi selectează o versiune care să reprezinte întregul cluster. Acest lucru diferă de motoarele de căutare tradiționale pentru că răspunsurile AI necesită un singur URL sursă pentru atribuție. Dacă canonicalul tău nu este implementat corect, AI-ul poate selecta o versiune republicată, o copie cache sau o variantă de calitate inferioară în locul URL-ului preferat.
Ar trebui să folosesc etichete canonice sau redirecționări pentru a gestiona conținutul duplicat?
Folosește etichete canonice atunci când ai nevoie să menții mai multe URL-uri din motive de business (parametri de tracking, URL-uri vechi, audiențe diferite), semnalând totodată preferința către sistemele AI. Folosește redirecționări atunci când retragi definitiv un URL, consolidezi domenii sau elimini variațiile de parametri fără scop. Redirecționările sunt semnale mai puternice pentru că transferă complet autoritatea, în timp ce canonicalele distribuie autoritatea, dar semnalează preferința.
Care sunt cele mai frecvente probleme de conținut duplicat care afectează vizibilitatea în AI?
Cele mai frecvente probleme sunt: republicarea (articole republicate pe site-uri partenere), pagini de campanie (mai multe landing page-uri cu conținut identic), localizarea (conținut similar pe domenii regionale) și duplicatele tehnice (parametri de URL, ID-uri de sesiune, slash-uri la final). Fiecare dintre acestea fragmentează autoritatea pe mai multe URL-uri, reducând vizibilitatea în răspunsurile generate de AI.
Cum implementez corect URL-urile canonice?
Folosește întotdeauna URL-uri absolute (https://exemplu.com/pagina, nu /pagina), plasează etichetele canonice în secțiunea head a HTML-ului, include canonicale auto-referențiale pe toate paginile și evită lanțurile canonice (A→B→C). Pentru conținut non-HTML, precum PDF-uri, folosește headere HTTP. Include canonicale în sitemap-ul XML și combină-le cu etichete hreflang pentru conținut internațional.
Cum pot verifica dacă sistemele AI recunosc URL-urile mele canonice?
Folosește Google Search Console și Bing Webmaster Tools pentru a verifica recunoașterea canonicalelor, monitorizează citările AI folosind AmICited.com și căutări manuale în ChatGPT/Claude/Perplexity și auditează site-ul cu unelte precum Screaming Frog sau SEMrush. Dacă duplicatele sunt citate în locul canonicalului, revizuiește implementarea și asigură-te că etichetele sunt formatate și plasate corect în head-ul HTML.
Ce este IndexNow și cum ajută la implementarea canonicalelor?
IndexNow este un protocol care notifică motoarele de căutare și crawlerii AI imediat ce adaugi, actualizezi sau elimini etichete canonice, în loc să aștepți ciclurile naturale de crawling. Acest lucru accelerează descoperirea preferințelor tale canonice și ajută la recunoașterea rapidă a URL-urilor preferate de către sistemele AI, reducând timpul în care duplicatele apar în răspunsurile AI.
Pot sistemele AI să ignore etichetele mele canonice?
Da, etichetele canonice sunt semnale puternice, dar nu directive obligatorii. Sistemele AI pot ignora preferința canonicală dacă determină că o altă versiune este mai autoritară pe baza calității conținutului, a pattern-urilor de linkuri, a prospețimii sau a altor semnale. De aceea, implementarea corectă combinată cu conținut și semnale de autoritate puternice crește șansa ca AI-urile să respecte preferința ta canonicală.
Monitorizează citările AI cu AmICited
Urmărește modul în care sistemele AI precum ChatGPT, Claude și Perplexity citează conținutul tău. Asigură-te că URL-urile tale canonice sunt recunoscute corect și că brandul tău primește atribuirea potrivită în răspunsurile generate de AI.
Cum gestionează motoarele de căutare AI conținutul duplicat? Este diferit față de Google?
Discuție în comunitate despre modul în care sistemele AI gestionează conținutul duplicat diferit față de motoarele de căutare tradiționale. Profesioniști SEO îm...
Cum să gestionezi conținutul duplicat pentru motoarele de căutare AI
Află cum să gestionezi și să previi conținutul duplicat atunci când folosești instrumente AI. Descoperă etichete canonice, redirecționări, instrumente de detect...
Republicarea conținutului pentru AI: Considerații privind conținutul duplicat
Află cum republicarea conținutului creează probleme de conținut duplicat care afectează vizibilitatea în căutarea AI mai sever decât în căutarea tradițională. D...
9 min citire
Consimțământ Cookie Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.