Query Fanout
Află cum funcționează Query Fanout în sistemele de căutare AI. Descoperă cum AI extinde o singură interogare în mai multe sub-interogări pentru a îmbunătăți acu...
11 min citire
Descoperă cum sistemele moderne de AI, precum Google AI Mode și ChatGPT, descompun o singură interogare în mai multe căutări. Află mecanismele fanout-ului de interogări, implicațiile pentru vizibilitatea în AI și optimizarea strategiei de conținut.
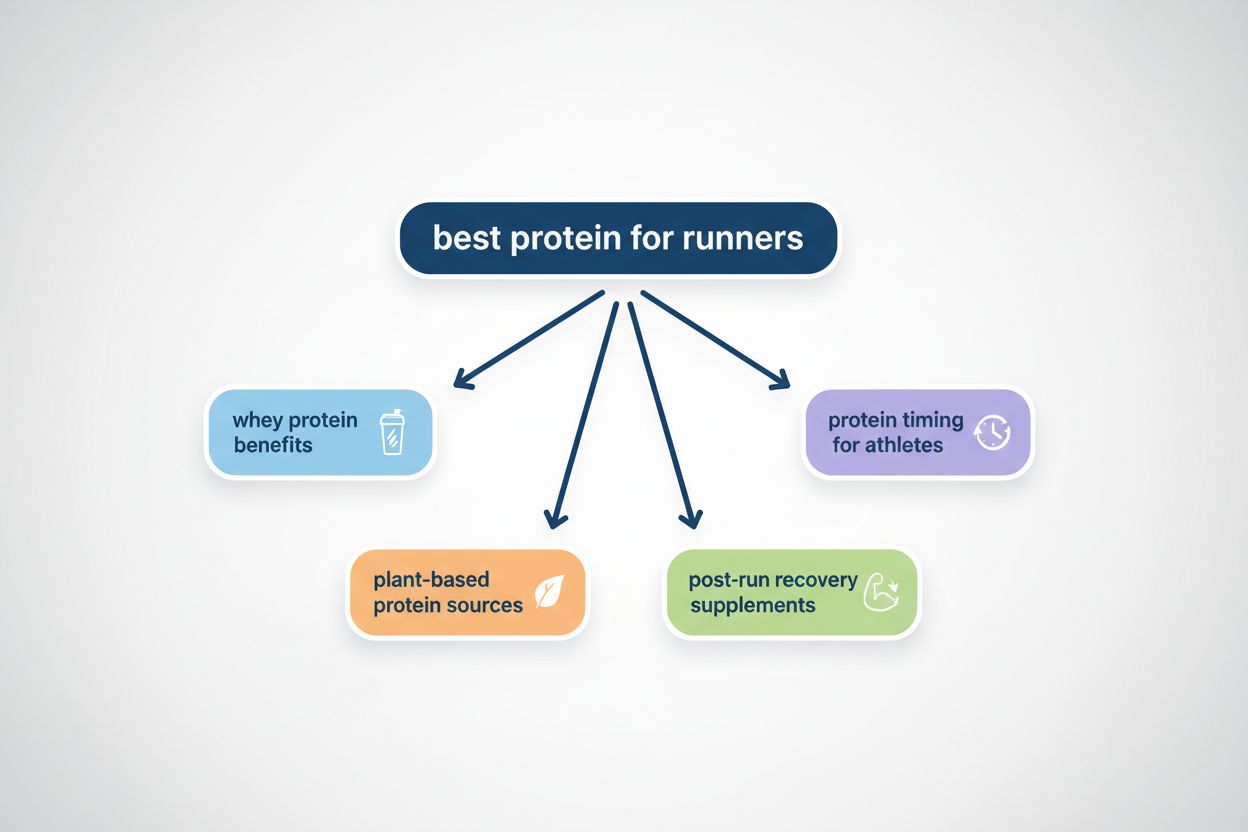
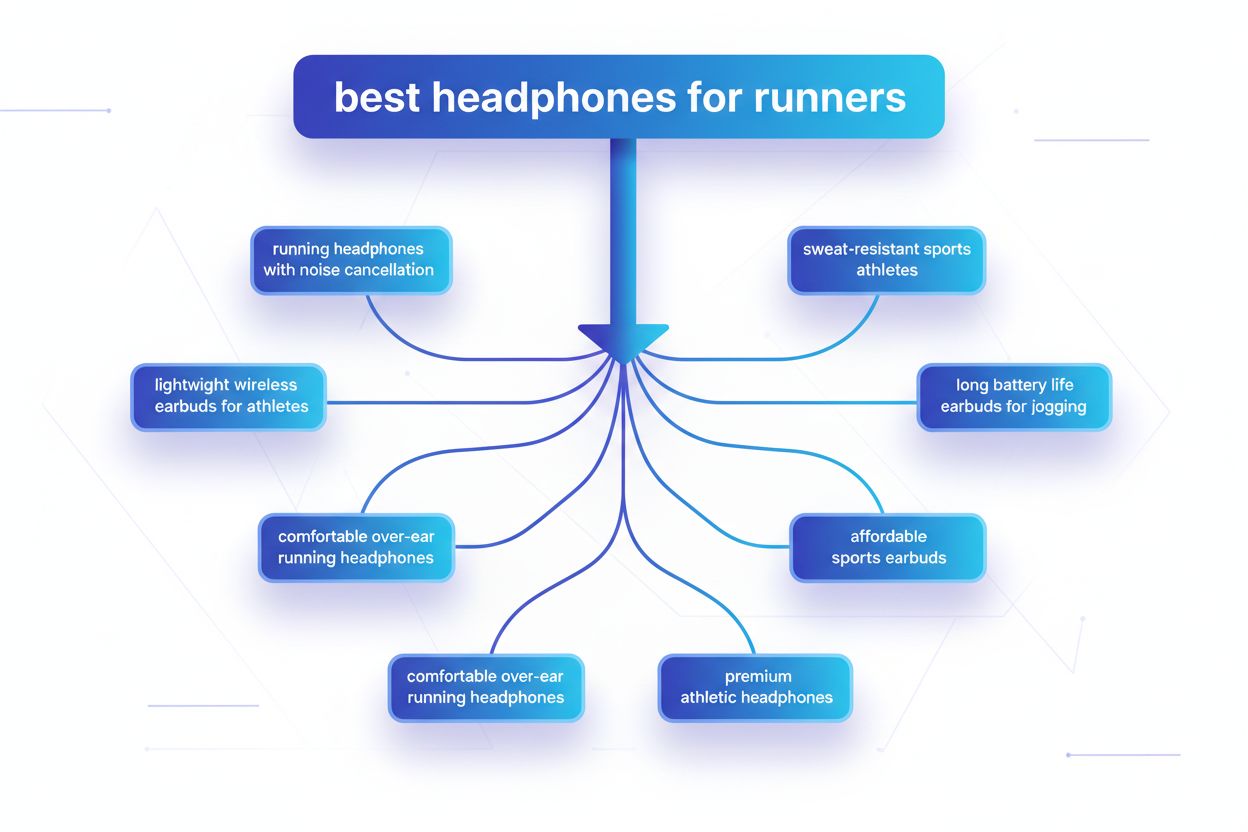
Fanout-ul de interogări este procesul prin care marile modele lingvistice împart automat o singură interogare a utilizatorului în mai multe sub-interogări pentru a aduna informații mai cuprinzătoare din surse diverse. În loc să execute o singură căutare, sistemele moderne de AI descompun intenția utilizatorului în 5-15 interogări conexe care surprind diferite unghiuri, interpretări și aspecte ale cererii inițiale. De exemplu, când un utilizator caută „cele mai bune căști pentru alergători” în modul AI al Google, sistemul generează aproximativ 8 căutări diferite, incluzând variații precum „căști pentru alergat cu anulare a zgomotului”, „căști wireless ușoare pentru sportivi”, „căști sport rezistente la transpirație” și „căști cu autonomie mare pentru jogging”. Aceasta reprezintă o schimbare fundamentală față de căutarea tradițională, unde un singur șir de interogare era potrivit cu un index. Caracteristicile cheie ale fanout-ului de interogări includ:
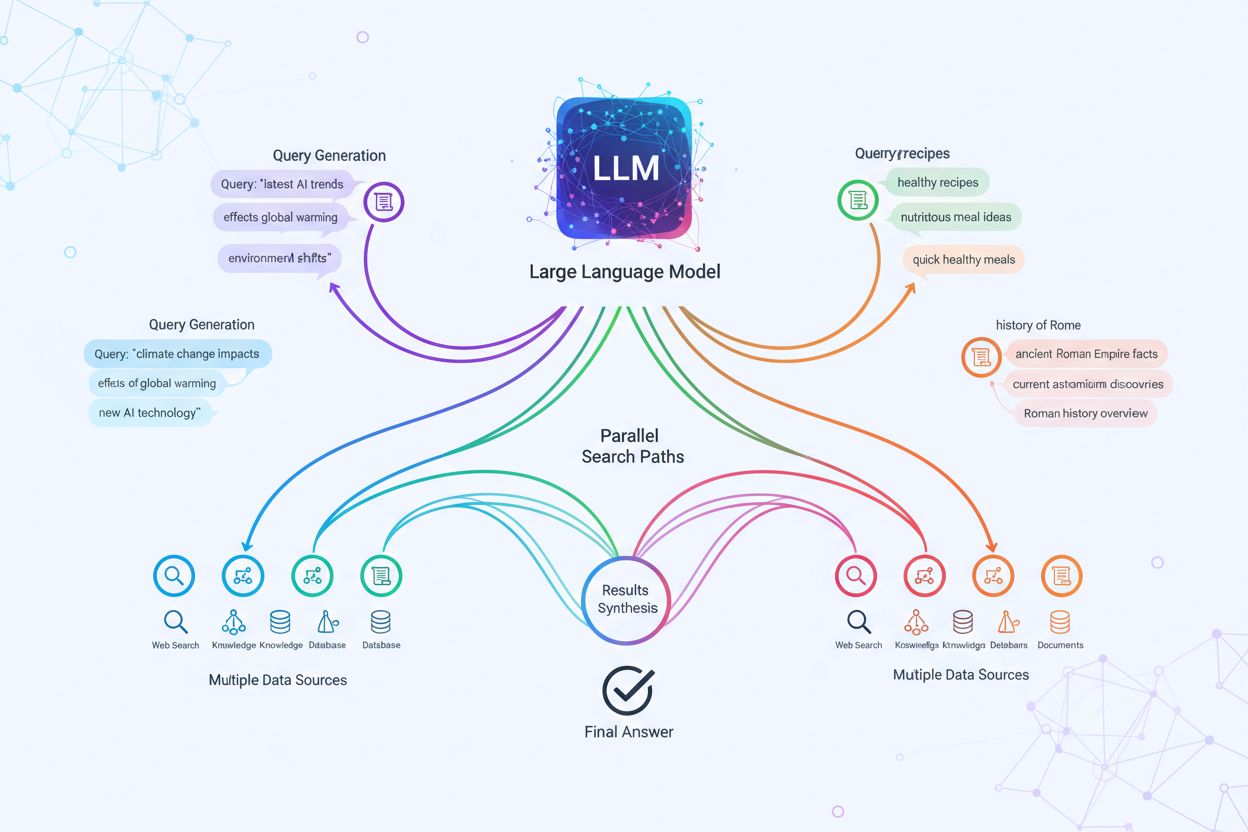
Implementarea tehnică a fanout-ului de interogări se bazează pe algoritmi NLP sofisticați care analizează complexitatea interogării și generează variante semantic relevante. LLM-urile produc opt tipuri principale de variante de interogare: interogări echivalente (reformulări cu același sens), interogări de continuare (explorarea subiectelor conexe), interogări de generalizare (extinderea domeniului), interogări de specificare (focalizare), interogări de canonicalizare (standardizarea terminologiei), interogări de traducere (conversie între domenii), interogări de implicație (explorarea implicațiilor logice) și interogări de clarificare (dezambiguizarea termenilor ambigui). Sistemul utilizează modele lingvistice neuronale pentru a evalua complexitatea interogării—măsurând factori precum numărul de entități, densitatea relațiilor și ambiguitatea semantică—pentru a determina câte sub-interogări să genereze. Odată generate, aceste interogări se execută în paralel pe mai multe sisteme de recuperare, inclusiv crawlere web, grafuri de cunoștințe (precum Knowledge Graph-ul Google), baze de date structurate și indici de similaritate vectorială. Platformele diferite implementează această arhitectură cu grade variate de transparență și sofisticare:
| Platformă | Mecanism | Transparență | Număr de interogări | Metodă de clasificare |
|---|---|---|---|---|
| Google AI Mode | Fanout explicit cu interogări vizibile | Ridicată | 8-12 interogări | Clasificare pe mai multe etape |
| Microsoft Copilot | Orchestrator Bing iterativ | Medie | 5-8 interogări | Scor de relevanță |
| Perplexity | Recuperare hibridă cu clasificare pe etape | Ridicată | 6-10 interogări | Pe bază de citare |
| ChatGPT | Generare implicită de interogări | Redusă | Necunoscut | Ponderare internă |
Interogările complexe trec printr-o descompunere sofisticată, unde sistemul le sparge în entități, atribute și relații constitutive înainte de a genera variantele. Când procesează o interogare precum „căști Bluetooth cu design peste ureche confortabil și baterie de durată potrivită pentru alergători”, sistemul realizează o înțelegere centrată pe entități identificând entitățile cheie (căști Bluetooth, alergători) și extrăgând atributele critice (confortabil, peste ureche, baterie de durată). Procesul de descompunere folosește grafuri de cunoștințe pentru a înțelege cum se relaționează aceste entități și ce variații semantice există—recunoscând că „căști peste ureche” și „căști circumaurale” sunt echivalente, sau că „baterie de durată” poate însemna 8+ ore, 24+ ore sau autonomie de mai multe zile, în funcție de context. Sistemul identifică concepte conexe prin măsurători de similaritate semantică, înțelegând că interogările despre „rezistență la transpirație” și „rezistență la apă” sunt înrudite dar distincte, și că „alergătorii” pot fi interesați și de „cicliști”, „persoane care merg la sală” sau „sportivi în aer liber”. Această descompunere permite generarea unor sub-interogări țintite care surprind diverse fațete ale intenției utilizatorului, nu doar reformularea cererii inițiale.
Fanout-ul de interogări consolidează fundamental componenta de recuperare a framework-urilor Retrieval-Augmented Generation (RAG) prin facilitarea unei colectări mai bogate și mai diverse de dovezi înainte de faza de generare. În fluxurile tradiționale RAG, o singură interogare este încorporată și potrivită cu o bază de date vectorială, ceea ce poate rata informații relevante care folosesc altă terminologie sau încadrări conceptuale diferite. Fanout-ul de interogări adresează această limitare prin executarea mai multor operațiuni de recuperare în paralel, fiecare optimizată pentru o anumită variantă de interogare, care colectiv adună dovezi din unghiuri și surse diferite. Această strategie paralelă de recuperare reduce semnificativ riscul de halucinație ancorând răspunsurile LLM în surse independente—când sistemul recuperează informații despre „căști peste ureche”, „design circumaural” și „căști full-size” separat, poate verifica și valida afirmațiile între aceste rezultate diverse. Arhitectura integrează chunking semantic și recuperare pe bază de pasaje, unde documentele sunt împărțite în unități semantice relevante și nu doar în fragmente de lungime fixă, permițând sistemului să recupereze cele mai relevante pasaje indiferent de structura documentului. Prin combinarea dovezilor din multiple recuperări de sub-interogări, sistemele RAG produc răspunsuri mai cuprinzătoare, mai bine sursate și mai puțin predispuse la rezultate greșite dar sigure, care apar la abordările cu o singură interogare.
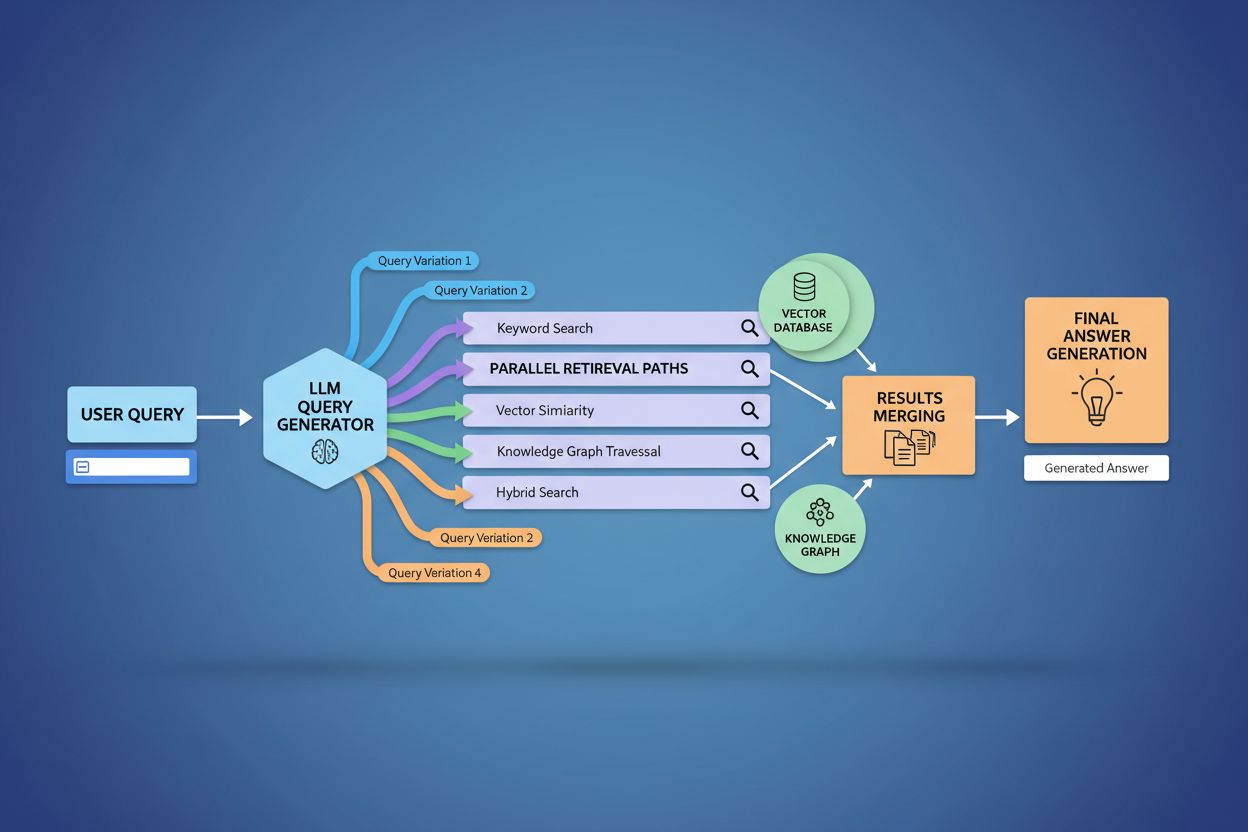
Contextul utilizatorului și semnalele de personalizare modelează dinamic modul în care fanout-ul de interogări extinde cererile individuale, creând trasee de recuperare personalizate care pot diferi semnificativ de la un utilizator la altul. Sistemul încorporează multiple dimensiuni de personalizare, inclusiv atribute ale utilizatorului (locație geografică, profil demografic, rol profesional), tipare de istoric de căutare (interogări anterioare și rezultate accesate), semnale temporale (ora din zi, sezon, evenimente curente) și contextul sarcinii (dacă utilizatorul cercetează, face cumpărături sau învață). De exemplu, o interogare despre „cele mai bune căști pentru alergători” se va extinde diferit pentru un atlet ultramaratonist de 22 de ani din Kenya față de un jogger recreațional de 45 de ani din Minnesota—extinderea pentru primul utilizator ar putea pune accent pe durabilitate și rezistență la căldură, iar pentru al doilea pe confort și accesibilitate. Totuși, această personalizare introduce problema „transformării în două puncte”, unde sistemul tratează interogările curente ca variații ale tiparelor istorice, ceea ce poate restricționa explorarea și întări preferințele existente. Personalizarea poate crea involuntar bule de filtrare, unde extinderea interogărilor favorizează sistematic surse și perspective aliniate cu comportamentul istoric al utilizatorului, limitând accesul la informații alternative sau emergente. Înțelegerea acestor mecanisme de personalizare este esențială pentru creatorii de conținut, întrucât același conținut poate fi recuperat sau nu, în funcție de profilul și istoricul utilizatorului.
Platformele majore AI implementează fanout-ul de interogări cu arhitecturi, niveluri de transparență și abordări strategice marcant diferite, reflectând infrastructura și filosofia de design subiacente. Modul AI al Google folosește fanout explicit și vizibil, unde utilizatorii pot vedea cele 8-12 sub-interogări generate afișate lângă rezultate, declanșând sute de căutări individuale în indexul Google pentru a aduna dovezi cuprinzătoare. Microsoft Copilot utilizează o abordare iterativă alimentată de Bing Orchestrator, care generează 5-8 interogări secvențial, rafinând setul de interogări pe baza rezultatelor intermediare înainte de faza finală de recuperare. Perplexity implementează o strategie de recuperare hibridă cu clasificare pe mai multe etape, generând 6-10 interogări și executându-le atât împotriva surselor web, cât și a indexului său proprietar, aplicând apoi algoritmi sofisticați de clasificare pentru a evidenția cele mai relevante pasaje. Abordarea ChatGPT rămâne în mare parte opacă pentru utilizatori, generarea interogărilor având loc implicit în procesarea internă a modelului, ceea ce face dificil de înțeles câte interogări sunt generate sau cum sunt executate. Aceste diferențe arhitecturale au implicații importante pentru transparență, reproductibilitate și capacitatea creatorilor de conținut de a optimiza pentru fiecare platformă:
| Aspect | Google AI Mode | Microsoft Copilot | Perplexity | ChatGPT |
|---|---|---|---|---|
| Vizibilitate interogări | Complet vizibil pentru utilizatori | Parțial vizibil | Vizibil în citări | Ascuns |
| Model de execuție | Pachet paralel | Iterativ secvențial | Paralel cu clasificare | Intern/implicit |
| Diversitate surse | Doar index Google | Bing + proprietar | Web + index proprietar | Date de antrenament + pluginuri |
| Transparență citare | Ridicată | Medie | Foarte ridicată | Redusă |
| Opțiuni de personalizare | Limitate | Medii | Ridicate | Medii |
Fanout-ul de interogări introduce multiple provocări tehnice și semantice care pot determina sistemul să se abată de la intenția reală a utilizatorului, recuperând informații conexe tehnic, dar nefolositoare în esență. Derapajul semantic apare prin extindere generativă, când LLM-ul creează variante de interogare care, deși semantic apropiate de original, deplasează treptat sensul—o interogare despre „cele mai bune căști pentru alergători” poate fi extinsă la „căști sportive”, apoi la „echipament sportiv”, apoi la „accesorii fitness”, îndepărtându-se progresiv de intenția inițială. Sistemul trebuie să distingă între intenția latentă (ce ar putea dori utilizatorul dacă ar ști mai multe) și intenția explicită (ce a cerut efectiv), iar extinderea agresivă poate confunda aceste categorii, recuperând informații despre produse pe care utilizatorul nu intenționa să le ia în considerare. Derivarea divergentă iterativă apare când fiecare interogare generată produce alte sub-interogări, creând un arbore ramificat de căutări din ce în ce mai tangente, care împreună recuperează informații tot mai îndepărtate de cererea inițială. Bulele de filtrare și biasul de personalizare înseamnă că doi utilizatori care pun întrebări identice primesc expansiuni de interogări sistematic diferite în funcție de profilurile lor, creând potențial camere de ecou unde fiecare expansiune întărește preferințele existente. Scenarii reale demonstrează aceste capcane: un utilizator care caută „căști accesibile” poate avea interogarea extinsă către branduri de lux pe baza istoricului de navigare, sau o interogare despre „căști pentru persoane cu deficiențe de auz” poate fi extinsă la produse generale de accesibilitate, diluând specificitatea intenției inițiale.
Ascensiunea fanout-ului de interogări schimbă fundamental strategia de conținut de la optimizarea pentru clasamentul pe cuvinte cheie la vizibilitatea bazată pe citare, obligând creatorii de conținut să regândească structura și prezentarea informației. SEO-ul tradițional se concentra pe clasarea pentru anumite cuvinte cheie; căutarea condusă de AI prioritizează citarea ca sursă autoritativă în multiple variante de interogări și contexte. Creatorii de conținut ar trebui să adopte strategii atomice, bogate în entități, unde informația e structurată în jurul unor entități specifice (produse, concepte, persoane) cu markup semantic bogat ce permite sistemelor AI să extragă și să citeze pasaje relevante. Gruparea pe subiecte și autoritatea tematică devin tot mai importante—în loc să creeze articole izolate despre cuvinte cheie individuale, conținutul de succes realizează acoperirea cuprinzătoare a domeniului, crescând șansele de a fi recuperat prin variantele diverse de interogare generate prin fanout. Implementarea markup-ului schema și a datelor structurate permite sistemelor AI să înțeleagă structura conținutului și să extragă mai eficient informațiile relevante, crescând probabilitatea de citare. Metricile de succes se mută de la monitorizarea clasamentelor la monitorizarea frecvenței citării prin unelte precum AmICited.com, care urmăresc cât de des apar brandurile și conținutul în răspunsurile generate de AI. Practici recomandate includ: crearea de conținut cuprinzător, bine sursat, care abordează multiple perspective ale unui subiect; implementarea unui markup schema bogat (schema Organization, Product, Article); construirea autorității tematice prin conținut interconectat; și auditarea regulată a modului în care apare conținutul tău în răspunsurile AI pe diferite platforme și segmente de utilizatori.
Fanout-ul de interogări reprezintă cea mai importantă schimbare arhitecturală în căutare de la indexarea mobile-first, restructurând fundamental modul în care informația este descoperită și prezentată utilizatorilor. Evoluția către infrastructura semantică înseamnă că sistemele de căutare vor funcționa tot mai mult pe bază de semnificație, nu cuvinte cheie, iar fanout-ul de interogări va deveni mecanismul implicit de recuperare a informației, nu doar o îmbunătățire opțională. Metricile de citare devin la fel de importante ca backlink-urile în determinarea vizibilității și autorității conținutului—un conținut citat în 50 de răspunsuri AI diferite are mai multă greutate decât un conținut aflat pe locul 1 pentru un singur cuvânt cheie. Această schimbare creează atât provocări, cât și oportunități: uneltele SEO tradiționale care urmăresc clasamentele devin mai puțin relevante, fiind nevoie de noi framework-uri de măsurare axate pe frecvența citării, diversitatea surselor și apariția în diferite variante de interogare. Totodată, această evoluție creează oportunități pentru branduri de a se optimiza specific pentru căutarea AI, construind conținut autoritativ, bine structurat, care să servească drept sursă de încredere pentru interpretări multiple ale interogărilor. Viitorul va presupune probabil o transparență sporită privind mecanismele fanout-ului de interogări, cu platforme care vor concura în cât de clar arată utilizatorilor raționamentul din spatele abordării multi-interogare, iar creatorii de conținut vor dezvolta strategii specializate pentru a maximiza vizibilitatea pe traseele diverse de recuperare create de fanout.
Fanout-ul de interogări este procesul automatizat prin care sistemele AI descompun o singură interogare a utilizatorului în mai multe sub-interogări și le execută în paralel, în timp ce extinderea interogărilor se referă tradițional la adăugarea de termeni asociați la o singură interogare. Fanout-ul de interogări este mai sofisticat, generând variante semantic diverse care surprind diferite unghiuri și interpretări ale intenției inițiale.
Fanout-ul de interogări are un impact semnificativ asupra vizibilității deoarece conținutul tău trebuie să fie descoperit prin mai multe variante de interogări, nu doar prin interogarea exactă a utilizatorului. Conținutul care abordează diferite perspective, utilizează o terminologie variată și este bine structurat cu markup schema are șanse mai mari să fie preluat și citat prin sub-interogările diverse generate de fanout.
Toate platformele majore de căutare AI folosesc mecanisme de fanout de interogări: Google AI Mode folosește fanout explicit și vizibil (8-12 interogări); Microsoft Copilot folosește fanout iterativ prin Bing Orchestrator; Perplexity implementează o recuperare hibridă cu clasificare pe mai multe etape; iar ChatGPT folosește generare implicită de interogări. Fiecare platformă îl implementează diferit, dar toate descompun interogările complexe în mai multe căutări.
Da. Optimizează prin crearea de conținut atomic, bogat în entități, structurat în jurul unor concepte specifice; implementarea unui markup schema cuprinzător; construirea autorității tematice prin conținut interconectat; utilizarea unei terminologii clare și variate; și abordarea mai multor perspective ale unui subiect. Unelte precum AmICited.com te ajută să monitorizezi cum apare conținutul tău în diferitele descompuneri de interogări.
Fanout-ul de interogări crește latența deoarece mai multe interogări sunt executate în paralel, dar sistemele moderne reduc acest lucru prin procesare paralelă. În timp ce o singură interogare poate dura 200ms, executarea a 8 interogări în paralel adaugă de obicei doar 300-500ms latență totală datorită execuției simultane. Compromisul este justificat pentru o calitate mai bună a răspunsurilor.
Fanout-ul de interogări consolidează Retrieval-Augmented Generation (RAG) prin facilitarea unei colectări de dovezi mai bogate. În loc să recupereze documente pentru o singură interogare, fanout-ul recuperează dovezi pentru mai multe variante de interogări în paralel, oferind LLM-ului un context mai divers și mai cuprinzător pentru generarea de răspunsuri exacte și reducerea riscului de halucinație.
Personalizarea modelează modul în care interogările sunt descompuse pe baza atributelor utilizatorului (locație, istoric, demografie), semnalelor temporale și contextului sarcinii. Aceeași interogare se extinde diferit pentru utilizatori diferiți, creând trasee de recuperare personalizate. Acest lucru poate îmbunătăți relevanța, dar creează și bule de filtrare unde utilizatorii văd rezultate sistematic diferite în funcție de profilul lor.
Fanout-ul de interogări reprezintă cea mai importantă schimbare în căutare de la indexarea mobile-first. Metricile tradiționale de clasare a cuvintelor cheie devin mai puțin relevante deoarece aceeași interogare se extinde diferit pentru utilizatori diferiți. Profesioniștii SEO trebuie să își mute atenția de la clasamentele pe cuvinte cheie la vizibilitatea bazată pe citare, structura conținutului și optimizarea entităților pentru a avea succes în căutarea condusă de AI.
Înțelege cum apare brandul tău pe platformele de căutare AI atunci când interogările sunt extinse și descompuse. Urmărește citările și mențiunile în răspunsurile generate de AI.
Află cum funcționează Query Fanout în sistemele de căutare AI. Descoperă cum AI extinde o singură interogare în mai multe sub-interogări pentru a îmbunătăți acu...

Află primii pași esențiali pentru a-ți optimiza conținutul pentru motoarele de căutare AI precum ChatGPT, Perplexity și Google AI Overviews. Descoperă cum să st...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.