Practica strategică de a permite sau bloca selectiv crawlerele AI pentru a controla modul în care conținutul este folosit pentru antrenare versus recuperare în timp real. Acest lucru implică utilizarea fișierelor robots.txt, controale la nivel de server și instrumente de monitorizare pentru a gestiona ce sisteme AI pot accesa conținutul dumneavoastră și în ce scopuri.
Managementul crawlerelor AI
Practica strategică de a permite sau bloca selectiv crawlerele AI pentru a controla modul în care conținutul este folosit pentru antrenare versus recuperare în timp real. Acest lucru implică utilizarea fișierelor robots.txt, controale la nivel de server și instrumente de monitorizare pentru a gestiona ce sisteme AI pot accesa conținutul dumneavoastră și în ce scopuri.
Ce este Managementul crawlerelor AI?
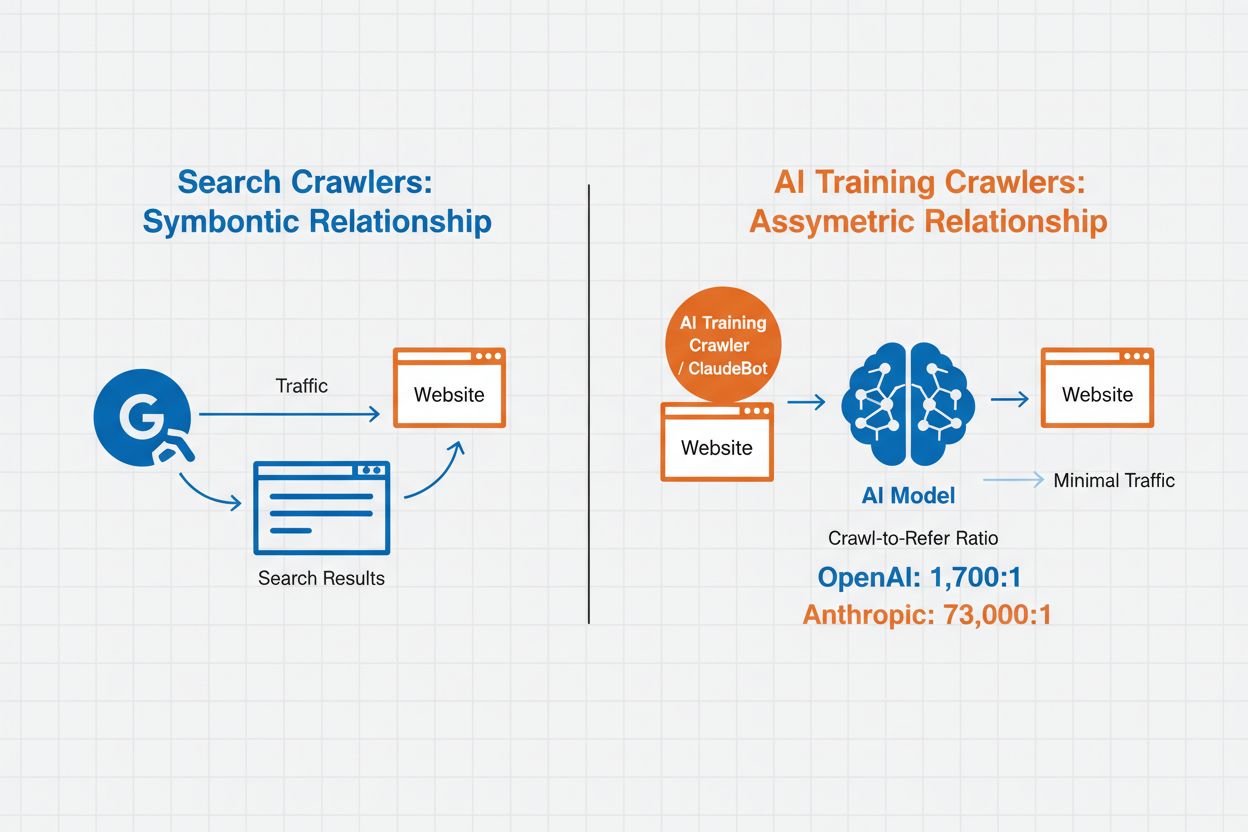
Managementul crawlerelor AI se referă la practica de a controla și monitoriza modul în care sistemele de inteligență artificială accesează și utilizează conținutul unui site web în scopuri de antrenare și căutare. Spre deosebire de crawlerele tradiționale ale motoarelor de căutare care indexează conținutul pentru rezultate web, crawlerele AI sunt concepute special pentru a colecta date destinate antrenării modelelor mari de limbaj sau alimentării funcțiilor de căutare asistate de AI. Scara acestei activități variază dramatic între organizații—crawlerele OpenAI operează la un raport crawl-to-refer de 1.700:1, ceea ce înseamnă că accesează conținutul de 1.700 de ori pentru fiecare referință oferită, în timp ce raportul Anthropic ajunge la 73.000:1, evidențiind consumul masiv de date necesar antrenării sistemelor AI moderne. Un management eficient al crawlerelor permite proprietarilor de site-uri să decidă dacă conținutul lor contribuie la antrenarea AI, apare în rezultatele de căutare AI sau rămâne protejat de accesul automatizat.
Tipuri de crawlere AI
Crawlerele AI se împart în trei categorii distincte în funcție de scopul și modul de utilizare a datelor. Crawlerele de antrenare sunt concepute pentru a colecta date destinate dezvoltării modelelor de învățare automată, consumând cantități uriașe de conținut pentru a îmbunătăți capacitățile AI. Crawlerele de căutare și citare indexează conținut pentru a alimenta funcții de căutare AI și pentru a oferi atribuire în răspunsurile generate de AI, permițând utilizatorilor să descopere conținutul tău prin interfețe AI. Crawlerele declanșate de utilizator funcționează la cerere, atunci când utilizatorii interacționează cu instrumente AI, cum ar fi atunci când un utilizator ChatGPT încarcă un document sau solicită analiza unei anumite pagini web. Înțelegerea acestor categorii te ajută să iei decizii informate despre ce crawlere să permiți sau să blochezi, în funcție de strategia ta de conținut și obiectivele de business.
Tip crawler
Scop
Exemple
Date de antrenare folosite
Antrenare
Dezvoltare și îmbunătățire model
GPTBot, ClaudeBot
Da
Căutare/Citare
Rezultate căutare AI și atribuire
Google-Extended, OAI-SearchBot, PerplexityBot
Variază
Declanșat de utilizator
Analiză de conținut la cerere
ChatGPT-User, Meta-ExternalAgent, Amazonbot
Context-specific
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Managementul crawlerelor AI afectează direct traficul, veniturile și valoarea conținutului site-ului tău. Atunci când crawlerele îți consumă conținutul fără compensație, pierzi posibilitatea de a beneficia de acel trafic prin referințe, afișări de reclame sau interacțiune cu utilizatorii. Site-urile au raportat reduceri semnificative de trafic pe măsură ce utilizatorii găsesc răspunsuri direct în răspunsurile generate de AI, fără a mai da click pe sursa originală, ceea ce duce la pierderea traficului de referință și venitului asociat. Dincolo de implicațiile financiare, există și considerente legale și etice importante—conținutul tău reprezintă proprietate intelectuală și ai dreptul să controlezi modul în care este folosit și dacă primești atribuire sau compensație. În plus, permiterea accesului necontrolat al crawlerelor poate crește încărcarea serverului și costurile de lățime de bandă, în special din partea crawlerelor cu rate agresive de crawling care nu respectă directivele de limitare a ratei.
Robots.txt și controale tehnice
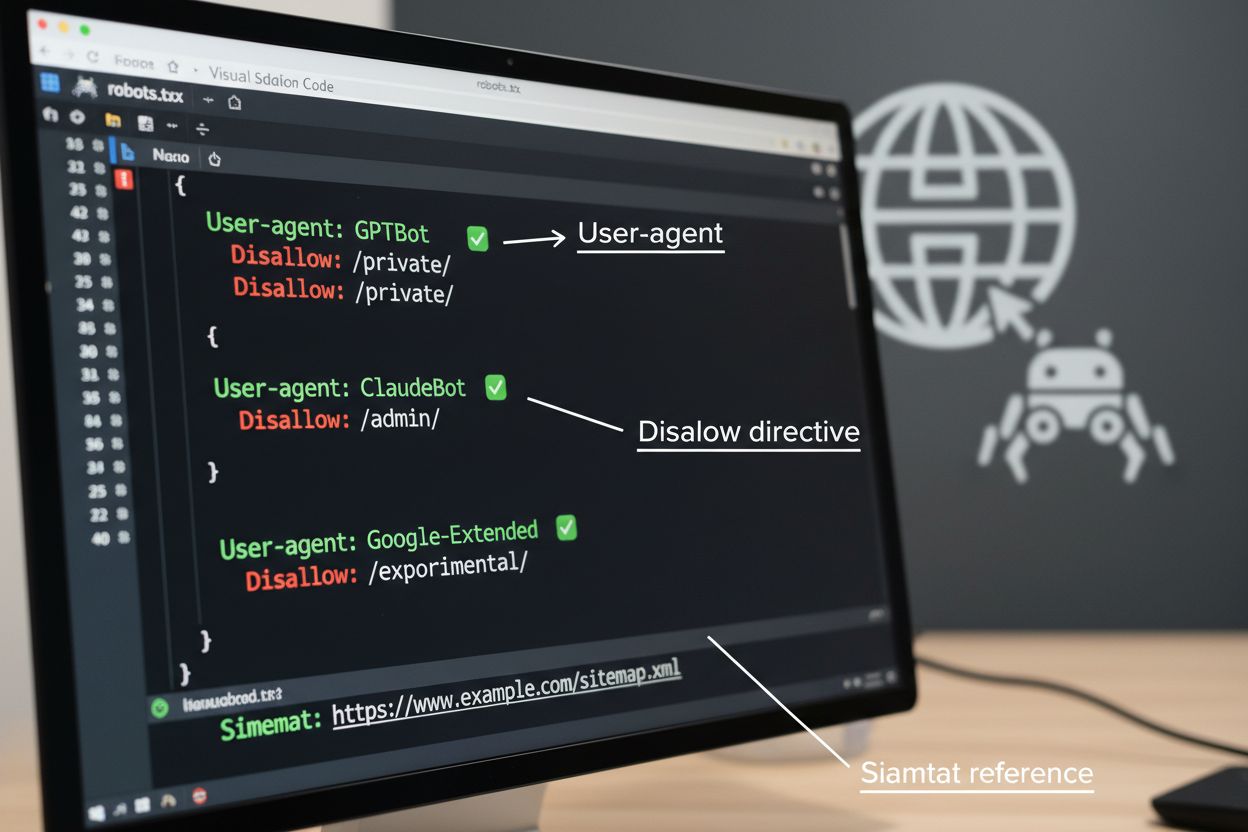
Fișierul robots.txt este instrumentul de bază pentru gestionarea accesului crawlerelor, plasat în directorul rădăcină al site-ului pentru a comunica preferințele de crawling către agenții automatizați. Acest fișier folosește directive User-agent pentru a viza crawlere specifice și reguli Disallow sau Allow pentru a permite sau restricționa accesul la anumite căi și resurse. Totuși, robots.txt are limitări importante—este un standard voluntar care se bazează pe conformitatea crawlerelor, iar boții rău intenționați sau prost proiectați îl pot ignora complet. În plus, robots.txt nu împiedică crawlerele să acceseze conținutul public disponibil; doar solicită să fie respectate preferințele tale. Din aceste motive, robots.txt ar trebui să facă parte dintr-o abordare stratificată de management al crawlerelor și nu să fie singura ta apărare.
# Blochează crawlerele AI de antrenare
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
# Permite motoarele de căutare
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Regulă implicită pentru alte crawlere
User-agent: *
Allow: /
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Metode avansate de control
Dincolo de robots.txt, mai multe tehnici avansate oferă o aplicare mai puternică și un control mai granular asupra accesului crawlerelor. Aceste metode funcționează la diferite niveluri ale infrastructurii tale și pot fi combinate pentru o protecție completă:
Reguli .htaccess: Directive la nivel de server care pot bloca user agent-uri sau intervale IP specifice înainte ca resursele să fie servite
Allowlisting/blocklisting IP: Restricționează accesul pe baza adreselor IP asociate cu crawlere AI cunoscute, dar necesită menținerea unor liste IP actualizate
Soluții Cloudflare WAF: Utilizează reguli Web Application Firewall pentru a identifica și bloca traficul crawler pe baza tiparelor de comportament și semnăturilor
Headere HTTP (X-Robots-Tag): Trimite directive pentru crawlere direct în headerele de răspuns, oferind control pe pagină sau pe resursă, mai greu de ignorat decât robots.txt
Limitarea ratei: Impune limite stricte pentru traficul crawlerelor pentru a face colectarea pe scară largă de date nefezabilă economic
Fingerprinting boți: Analizează tiparele de solicitări, headerele și comportamentul pentru a identifica crawlere sofisticate ce își ascund identitatea
Echilibrarea protecției cu vizibilitatea
Decizia de a bloca crawlerele AI implică compromisuri importante între protecția conținutului și vizibilitate. Blocarea tuturor crawlerelor AI elimină posibilitatea ca conținutul tău să apară în rezultate de căutare AI, rezumate generate de AI sau să fie citat de instrumente AI—ceea ce poate reduce vizibilitatea pentru utilizatorii care descoperă conținut prin aceste canale emergente. Pe de altă parte, permiterea accesului necontrolat înseamnă că conținutul tău alimentează antrenarea AI fără compensație și poate reduce traficul de referință, întrucât utilizatorii obțin răspunsuri direct de la sisteme AI. O abordare strategică implică blocarea selectivă: permiterea crawlerelor de citare precum OAI-SearchBot și PerplexityBot, care generează trafic de referință, în timp ce blochezi crawlerele de antrenare precum GPTBot și ClaudeBot care consumă date fără atribuire. Poți lua în calcul și permiterea Google-Extended pentru a menține vizibilitatea în Google AI Overviews, care poate genera trafic semnificativ, blocând în același timp crawlerele de antrenare ale competitorilor. Strategia optimă depinde de tipul de conținut, modelul de afaceri și audiență—site-urile de știri și publisherii pot prioritiza blocarea, în timp ce creatorii de conținut educațional pot beneficia de o vizibilitate AI mai largă.
Monitorizare și aplicare
Implementarea controalelor pentru crawlere este eficientă doar dacă verifici dacă acestea chiar respectă directivele tale. Analiza jurnalelor serverului este metoda principală de monitorizare a activității crawlerelor—examinează jurnalele de acces pentru string-urile User-Agent și tiparele de solicitări pentru a identifica ce crawlere îți accesează site-ul și dacă respectă regulile robots.txt. Multe crawlere pretind că respectă directivele, dar continuă să acceseze căi blocate, de aceea monitorizarea continuă este esențială. Instrumente precumCloudflare Radar oferă vizibilitate în timp real asupra tiparelor de trafic și pot ajuta la identificarea comportamentului suspicios sau neconform al crawlerelor. Configurează alerte automate pentru încercările de acces la resurse blocate și auditează periodic jurnalele pentru a depista crawlere noi sau schimbări de comportament ce pot indica tentative de evitare a controalelor.
Bune practici și implementare
Implementarea unui management eficient al crawlerelor AI necesită o abordare sistematică ce echilibrează protecția cu vizibilitatea strategică. Urmează acești opt pași pentru a stabili o strategie completă de management al crawlerelor:
Audit acces curent: Analizează jurnalele serverului pentru a identifica ce crawlere AI accesează în prezent site-ul tău, frecvența și resursele vizate
Definirea politicii: Decide care crawlere se aliniază cu obiectivele tale de business—ia în calcul crawlerele de antrenare vs. cele de căutare, impactul asupra traficului și valoarea conținutului
Documentează deciziile: Creează documentație clară pentru politica ta de crawlere și rațiunea fiecărei decizii, pentru referință viitoare și aliniere în echipă
Implementează controalele: Aplică reguli robots.txt, headere HTTP și controale avansate precum limitarea ratei sau blocarea IP, conform politicii tale
Monitorizează conformitatea: Revizuiește regulat jurnalele serverului și folosește instrumente de monitorizare pentru a verifica dacă crawlerele respectă directivele
Configurează alerte: Setează alerte automate pentru acces neconform sau încercări de evitare a controalelor
Revizuiește trimestrial: Reevaluează strategia de management al crawlerelor în fiecare trimestru, pe măsură ce apar crawlere noi și nevoile tale de business evoluează
Actualizează la apariția crawlerelor noi: Fii la curent cu crawlerele AI noi și actualizează-ți controalele proactiv, nu reactiv
AmICited.com: Monitorizează referințele AI
AmICited.com oferă o platformă specializată pentru monitorizarea modului în care sistemele AI fac referire și utilizează conținutul tău în diverse modele și aplicații. Serviciul oferă monitorizare în timp real a citărilor tale în răspunsurile generate de AI, ajutându-te să înțelegi ce crawlere îți folosesc cel mai activ conținutul și cât de frecvent apare munca ta în rezultatele AI. Prin analiza tiparelor crawlerelor și a datelor de citare, AmICited.com permite luarea unor decizii informate în privința strategiei tale de management al crawlerelor—poți vedea exact care crawlere aduc valoare prin citări și trafic de referință versus cele care consumă conținut fără atribuire. Această inteligență transformă managementul crawlerelor dintr-o practică defensivă într-un instrument strategic pentru optimizarea vizibilității și impactului conținutului tău în web-ul alimentat de AI.
Întrebări frecvente
Care este diferența dintre blocarea crawlerelor AI de antrenare și cele de căutare?
Crawlerele de antrenare precum GPTBot și ClaudeBot colectează conținut pentru a construi seturi de date destinate dezvoltării modelelor mari de limbaj, consumând conținutul tău fără a genera trafic de referință. Crawlerele de căutare precum OAI-SearchBot și PerplexityBot indexează conținutul pentru rezultate de căutare alimentate de AI și pot trimite vizitatori înapoi pe site-ul tău prin citări. Blocarea crawlerelor de antrenare îți protejează conținutul de a fi încorporat în modele AI, în timp ce blocarea crawlerelor de căutare îți poate reduce vizibilitatea pe platformele de descoperire alimentate de AI.
Blocarea crawlerelor AI îmi afectează clasamentul SEO?
Nu. Blocarea crawlerelor AI de antrenare precum GPTBot, ClaudeBot și CCBot nu afectează clasamentele tale Google sau Bing. Motoarele de căutare tradiționale folosesc crawlere diferite (Googlebot, Bingbot) care operează independent de boții AI de antrenare. Blocarea crawlerelor tradiționale de căutare trebuie făcută doar dacă vrei să dispari complet din rezultatele căutării, ceea ce ar afecta negativ SEO-ul.
Cum pot afla ce crawlere accesează site-ul meu?
Examinează jurnalele de acces ale serverului pentru identificarea string-urilor User-Agent ale crawlerelor. Caută intrări care conțin 'bot', 'crawler' sau 'spider' în câmpul User-Agent. Instrumente precum Cloudflare Radar oferă vizibilitate în timp real asupra crawlerelor AI care accesează site-ul tău și a tiparelor de trafic. Poți folosi și platforme de analiză care diferențiază traficul de bot de cel al vizitatorilor umani.
Pot crawlerele AI să ignore directivele robots.txt?
Da. robots.txt este un standard consultativ care se bazează pe conformitatea crawlerelor—nu este obligatoriu. Crawlerele bine intenționate ale companiilor mari precum OpenAI, Anthropic și Google respectă în general directivele robots.txt, dar unele crawlere le ignoră complet. Pentru protecție mai puternică, implementează blocarea la nivel de server prin .htaccess, reguli de firewall sau restricții bazate pe IP.
Ar trebui să blochez toate crawlerele AI sau să folosesc blocarea selectivă?
Depinde de prioritățile tale de afaceri. Blocarea tuturor crawlerelor de antrenare îți protejează conținutul de a fi încorporat în modele AI, permițând în același timp crawlerele de căutare ce pot genera trafic de referință. Mulți publisheri utilizează blocarea selectivă, vizând crawlerele de antrenare și permițând crawlerele de căutare sau citare. Ia în considerare tipul de conținut, sursele de trafic și modelul de monetizare atunci când îți stabilești strategia.
Cât de des ar trebui să-mi actualizez politica de management al crawlerelor?
Efectuează o revizuire și actualizare a politicii de management al crawlerelor cel puțin trimestrial. Apar frecvent noi crawlere AI, iar cele existente își actualizează User-Agent-urile fără notificare. Urmărește resurse precum proiectul ai.robots.txt de pe GitHub pentru liste întreținute de comunitate și verifică lunar jurnalele serverului pentru a identifica noi crawlere care accesează site-ul tău.
Care este impactul crawlerelor AI asupra traficului și veniturilor site-ului meu?
Crawlerele AI pot avea un impact semnificativ asupra traficului și veniturilor tale. Când utilizatorii primesc răspunsuri direct de la sisteme AI în loc să viziteze site-ul tău, pierzi trafic de referință și afișări de reclame asociate. Studiile arată rapoarte crawl-to-refer de până la 73.000:1 pentru unele platforme AI, ceea ce înseamnă că acestea accesează conținutul tău de mii de ori pentru fiecare vizitator trimis înapoi. Blocarea crawlerelor de antrenare poate proteja traficul, în timp ce permiterea crawlerelor de căutare poate oferi unele beneficii de referință.
Cum pot verifica dacă configurația robots.txt funcționează?
Verifică jurnalele serverului pentru a vedea dacă crawlerele blocate mai apar în jurnalele de acces. Folosește instrumente de testare precum Robots.txt Tester din Google Search Console sau Merkle's Robots.txt Tester pentru a valida configurația. Accesează direct fișierul robots.txt la yoursite.com/robots.txt pentru a verifica dacă este corect. Monitorizează regulat jurnalele pentru a identifica crawlere care ar trebui să fie blocate, dar încă apar.
Monitorizează modul în care sistemele AI fac referire la conținutul tău
AmICited.com urmărește în timp real referințele AI către brandul tău în ChatGPT, Perplexity, Google AI Overviews și alte sisteme AI. Ia decizii bazate pe date pentru strategia ta de management al crawlerelor.
Impactul crawlerelor AI asupra resurselor serverului: La ce să te aștepți
Află cum crawlerii AI influențează resursele serverului, lățimea de bandă și performanța. Descoperă statistici reale, strategii de reducere și soluții de infras...
Cum să Identifici Crawlerele AI în Jurnalele Serverului: Ghid Complet de Detectare
Află cum să identifici și să monitorizezi crawlerele AI precum GPTBot, PerplexityBot și ClaudeBot în jurnalele serverului tău. Descoperă șiruri user-agent, meto...
Ce crawlere AI ar trebui să permit accesul? Ghid complet pentru 2025
Află ce crawlere AI să permiți sau să blochezi în robots.txt. Ghid cuprinzător despre GPTBot, ClaudeBot, PerplexityBot și peste 25 de crawlere AI, cu exemple de...
11 min citire
Consimțământ Cookie Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.