
Ce este Burstiness în Conținutul AI și Cum Afectează Detectarea
Află ce înseamnă burstiness în conținutul generat de AI, cum diferă față de modelele de scriere umană și de ce este important pentru detectarea AI și autenticit...
9 min citire
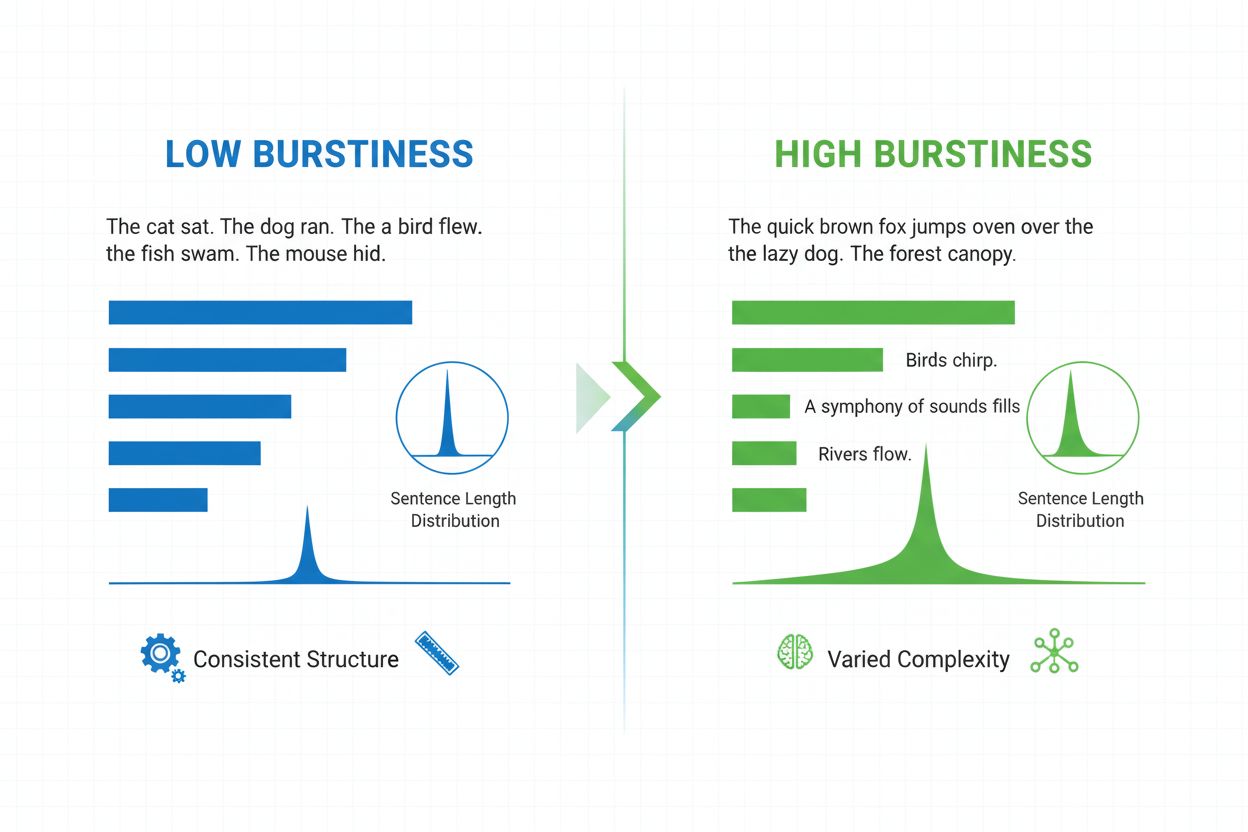
Burstiness este o metrică lingvistică ce măsoară variabilitatea lungimii, structurii și complexității propozițiilor într-un document. Ea cuantifică cât de mult variază un scriitor între propoziții scurte, incisive și altele mai lungi și complexe, servind drept indicator cheie în detecția conținutului generat de AI și analiza limbajului natural.
Burstiness este o metrică lingvistică ce măsoară variabilitatea lungimii, structurii și complexității propozițiilor într-un document. Ea cuantifică cât de mult variază un scriitor între propoziții scurte, incisive și altele mai lungi și complexe, servind drept indicator cheie în detecția conținutului generat de AI și analiza limbajului natural.
Burstiness este o metrică lingvistică cuantificabilă ce măsoară variabilitatea și fluctuația lungimii, structurii și complexității propozițiilor într-un document scris sau pasaj de text. Termenul provine din conceptul de „explozii” de tipare variate de propoziții—alternarea între propoziții scurte, concise, și altele mai lungi, mai complexe. În contextul procesării limbajului natural și al detecției conținutului generat de AI, burstiness servește ca un indicator critic dacă textul a fost scris de un om sau generat de un sistem de inteligență artificială. Scriitorii umani produc în mod natural texte cu burstiness ridicat deoarece variază instinctiv construcția propozițiilor în funcție de accent, ritm și intenție stilistică. În schimb, textul generat de AI prezintă de obicei burstiness scăzut deoarece modelele de limbaj sunt antrenate pe tipare statistice ce favorizează consistența și previzibilitatea. Înțelegerea burstiness este esențială pentru creatori de conținut, educatori, cercetători și organizații ce monitorizează conținutul generat de AI pe platforme precum ChatGPT, Perplexity, Google AI Overviews și Claude.
Conceptul de burstiness a apărut în urma cercetărilor din lingvistica computațională și teoria informației, unde oamenii de știință au căutat să cuantifice proprietățile statistice ale limbajului natural. Primele lucrări din stilometrie—analiza statistică a stilului de scriere—au identificat că scrierea umană prezintă tipare distinctive de variație, fundamental diferite de textele generate de mașini. Pe măsură ce modelele de limbaj mari (LLM) au devenit tot mai sofisticate la începutul anilor 2020, cercetătorii au recunoscut că burstiness, combinat cu perplexity (o măsură a previzibilității cuvintelor), poate servi ca indicator fiabil al conținutului generat de AI. Potrivit cercetărilor de la QuillBot și instituții academice, aproximativ 78% dintre companii folosesc acum instrumente de monitorizare a conținutului AI ce includ analiza burstiness în algoritmii de detecție. Studiul Stanford University din 2023 pe eseuri TOEFL a arătat că metodele de detecție bazate pe burstiness, deși utile, au limitări semnificative—mai ales în privința rezultatelor fals pozitive la scrierea non-nativă în engleză. Aceste cercetări au condus la dezvoltarea unor sisteme de detecție AI mai sofisticate, multilayer, care iau în considerare burstiness alături de alți indicatori lingvistici, coerență semantică și adecvare contextuală.
Burstiness se calculează prin analiza distribuției statistice a lungimilor propozițiilor și a tiparelor structurale dintr-un text. Metrica cuantifică variația—practic, măsoară cât de mult diferă fiecare propoziție de lungimea medie a propozițiilor din document. Un document cu burstiness ridicat conține propoziții ce variază semnificativ ca lungime; de exemplu, un scriitor poate urma o propoziție de trei cuvinte („Vezi?”) cu una de douăzeci și cinci de cuvinte, cu mai multe propoziții subordonate și fraze. În schimb, burstiness scăzut indică faptul că majoritatea propozițiilor se concentrează în jurul unei lungimi similare, de obicei între doisprezece și optsprezece cuvinte, creând un ritm monoton. Calculul implică mai mulți pași: mai întâi, sistemul măsoară lungimea fiecărei propoziții în cuvinte; apoi, calculează media aritmetică; în final, determină abaterea standard pentru a vedea cât de mult se abat propozițiile individuale de la medie. O abatere standard mai mare indică variație mai mare, deci burstiness mai ridicat. Detectorii moderni de AI precum Winston AI și Pangram folosesc algoritmi sofisticați care nu numără doar cuvinte, ci analizează și complexitatea sintactică—aranjamentul structural al propozițiilor, frazelor și elementelor gramaticale. Această analiză detaliată arată că scriitorii umani folosesc structuri diverse de propoziții (simple, compuse, complexe și compuse-complexe) în tipare imprevizibile, în timp ce modelele AI favorizează anumite șabloane structurale întâlnite frecvent în datele de antrenament.
| Metrică | Burstiness | Perplexity | Focalizare măsurare |
|---|---|---|---|
| Definiție | Variația lungimii și structurii propozițiilor | Previziunea cuvintelor individuale | La nivel de propoziție vs. nivel de cuvânt |
| Scriere umană | Ridicată (structuri variate) | Ridicată (cuvinte imprevizibile) | Ritm natural și vocabular |
| Text generat de AI | Scăzută (structuri uniforme) | Scăzută (cuvinte previzibile) | Consistență statistică |
| Aplicație în detecție | Identifică monotonia structurală | Identifică tiparele de alegere a cuvintelor | Metode de detecție complementare |
| Risc fals pozitiv | Mai mare la scriitori ESL | Mai mare la scriere tehnică/academic | Ambele au limitări |
| Metodă de calcul | Abaterea standard a lungimilor propozițiilor | Analiza distribuției de probabilitate | Abordări matematice diferite |
| Fiabilitate de sine stătătoare | Insuficient pentru detecție definitivă | Insuficient pentru detecție definitivă | Eficient în combinație |
Modelele de limbaj mari precum ChatGPT, Claude și Google Gemini sunt antrenate printr-un proces numit predicția următorului token, unde modelul învață să prezică cel mai probabil cuvânt care urmează într-o secvență. În timpul antrenamentului, aceste modele sunt optimizate explicit pentru a minimiza perplexity pe seturile de date de antrenament, ceea ce duce indirect la burstiness scăzut ca efect secundar. Când un model întâlnește în datele de antrenament o anumită structură de propoziție în mod repetat, o reproduce cu probabilitate mare, rezultând lungimi de propoziții consistente și previzibile. Cercetările Netus AI și Winston AI arată că modelele AI prezintă o amprentă stilometrică distinctă, caracterizată de construcții uniforme de propoziții, suprasolicitarea expresiilor de tranziție (precum „În plus”, „Prin urmare”, „De asemenea”) și o preferință pentru diateza pasivă în detrimentul celei active. Dependența modelelor de distribuțiile de probabilitate face ca ele să graviteze spre cele mai frecvente tipare din datele de antrenament, nu să exploreze întreaga gamă de construcții posibile. Astfel, cu cât modelul este antrenat pe mai multe date, cu atât va reproduce mai mult tiparele comune, având deci burstiness mai scăzut. În plus, modelele AI nu prezintă spontaneitate și variație emoțională specifice scrierii umane—nu scriu diferit când sunt entuziasmate, frustrate sau accentuează un anumit punct. Ele mențin un stil consistent care reflectă media statistică a datelor de antrenament.
Platformele de detecție AI au integrat analiza burstiness ca element central al algoritmilor de detecție, însă cu grade diferite de sofisticare. Primele sisteme de detecție se bazau puternic pe burstiness și perplexity ca metrici principale, dar cercetările au arătat limitări semnificative ale acestei abordări. Conform Pangram Labs, detectorii bazate pe perplexity și burstiness produc rezultate fals pozitive când analizează texte din seturile de antrenament ale modelelor de limbaj—de exemplu, Declarația de Independență este frecvent etichetată ca generată de AI deoarece apare atât de des în datele de antrenament încât modelul îi atribuie perplexity uniform scăzut. Sistemele moderne precum Winston AI și Pangram folosesc abordări hibride ce combină analiza burstiness cu modele de deep learning antrenate pe mostre diverse de texte umane și generate de AI. Aceste sisteme analizează simultan mai multe dimensiuni lingvistice: variația structurii propozițiilor, diversitatea lexicală (bogăția vocabularului), tiparele de punctuație, coerența contextuală și alinierea semantică. Integrarea burstiness în cadre de detecție mai ample a crescut semnificativ acuratețea—Winston AI raportează o acuratețe de 99,98% în distingerea conținutului generat de AI de cel scris de oameni, analizând multipli indicatori, nu doar burstiness. Totuși, această metrică rămâne valoroasă ca parte a unei strategii de detecție cuprinzătoare, în special când este combinată cu analiza perplexity, tipare stilometrice și consistență semantică.
Relația dintre burstiness și lizibilitate este bine documentată în cercetarea lingvistică. Scorurile Flesch Reading Ease și Flesch-Kincaid Grade Level, care măsoară accesibilitatea textului, corelează puternic cu tiparele de burstiness. Textele cu burstiness ridicat tind să obțină scoruri mai bune de lizibilitate deoarece variația lungimii propozițiilor previne oboseala cognitivă și menține atenția cititorului. Când cititorii întâlnesc un ritm constant de propoziții de dimensiuni similare, creierul lor se adaptează la un tipar previzibil, ceea ce poate duce la dezinteres și scăderea înțelegerii. În schimb, burstiness ridicat creează un efect de flux și reflux care menține implicarea mentală a cititorului, variind încărcătura cognitivă—propozițiile scurte oferă informații rapide și ușor de digerat, iar cele lungi permit dezvoltarea de idei complexe și nuanțe. Cercetarea de la Metrics Masters arată că burstiness ridicat generează aproximativ cu 15-20% mai bună retenție a memoriei comparativ cu texte cu burstiness scăzut, deoarece ritmul variat ajută la codificarea mai eficientă a informației în memoria pe termen lung. Acest principiu se aplică tuturor tipurilor de conținut: postări pe blog, lucrări academice, texte de marketing și documentație tehnică beneficiază de burstiness strategic. Totuși, relația nu este liniară—burstiness excesiv, care pune variația înaintea clarității, poate face textul fragmentat și dificil de urmărit. Abordarea optimă implică variație intenționată în care structura propozițiilor servește sensului conținutului și scopului comunicativ, nu doar metricii.
În ciuda utilizării largi în sistemele de detecție AI, detecția bazată pe burstiness are limitări semnificative pe care cercetătorii și practicienii trebuie să le înțeleagă. Pangram Labs a publicat o cercetare cuprinzătoare ce evidențiază cinci mari dezavantaje: în primul rând, textele din seturile de antrenament AI sunt clasificate greșit ca generate de AI deoarece modelele sunt optimizate pentru a minimiza perplexity pe datele de antrenament; în al doilea rând, valorile burstiness sunt relative anumitor modele de limbaj, diferite modele producând profiluri de perplexity diferite; în al treilea rând, modelele comerciale închise precum ChatGPT nu expun probabilitățile token-urilor, făcând imposibil calculul perplexity; în al patrulea rând, vorbitorii non-nativi de engleză sunt disproporționat etichetați ca generând text AI din cauza structurilor de propoziții mai uniforme; iar în al cincilea rând, detectorii bazate pe burstiness nu se pot auto-îmbunătăți iterativ cu date suplimentare. Studiul Stanford 2023 pe eseuri TOEFL a arătat că aproximativ 26% din textele non-native de engleză au fost etichetate incorect ca generate de AI de detectorii pe bază de perplexity și burstiness, comparativ cu doar 2% rată de fals pozitiv la textele native. Această biasare ridică probleme etice serioase în educație, unde detecția AI e folosită pentru evaluarea studenților. În plus, conținutul șablonizat din marketing, scriere academică și documentație tehnică prezintă în mod natural burstiness redus din cauza cerințelor de stil și convențiilor structurale, ceea ce duce la rezultate fals pozitive în aceste domenii. Aceste limitări au determinat dezvoltarea unor abordări de detecție mai sofisticate, unde burstiness este doar unul dintre mulți indicatori, nu un semnal definitiv al generării AI.
Tiparele de burstiness variază semnificativ între diferite genuri și contexte de scriere, reflectând scopurile comunicative și așteptările publicului fiecărui domeniu. Scrierea academică, mai ales în domeniile STEM, tinde să prezinte burstiness scăzut deoarece autorii respectă ghiduri stricte de stil și folosesc șabloane structurale constante pentru claritate și precizie. Documentele juridice, specificațiile tehnice și lucrările științifice prioritizează consistența și previzibilitatea în detrimentul variației stilistice, rezultând scoruri de burstiness natural mai mici. În schimb, scrierea creativă, jurnalismul și copywriting-ul de marketing demonstrează de obicei burstiness ridicat deoarece aceste genuri urmăresc implicarea și impactul emoțional prin variații de ritm și tempo. Ficțiunea literară, în special, folosește schimbări dramatice de lungime a propozițiilor pentru a crea accent, tensiune și controlul ritmului narativ. Comunicarea de business ocupă o zonă de mijloc—emailurile profesionale și rapoartele mențin burstiness moderat pentru a echilibra claritatea cu angajamentul. Indicatorul Flesch-Kincaid Grade Level arată că scrierea academică destinată publicului cu studii superioare folosește adesea propoziții lungi și complexe, ceea ce poate părea că reduce burstiness; totuși, variația structurii subordonatelor și tiparele de subordonare creează în continuare burstiness semnificativ. Înțelegerea acestor variații contextuale este esențială pentru sistemele de detecție AI, care trebuie să țină cont de convențiile specifice genului pentru a evita rezultate fals pozitive. Un manual tehnic cu propoziții uniform lungi nu ar trebui etichetat ca generat de AI doar pentru că prezintă burstiness scăzut—acest burstiness redus reflectă alegeri stilistice adecvate genului, nu dovada generării automate.
Viitorul analizei burstiness în detecția AI se îndreaptă spre abordări mai sofisticate, conștiente de context, care recunosc limitările metricii, valorificând în același timp avantajele sale. Pe măsură ce modelele de limbaj mari devin tot mai avansate, ele încep să includă variație de burstiness în output, făcând detecția bazată exclusiv pe această metrică mai puțin fiabilă. Cercetătorii dezvoltă sisteme adaptive de detecție ce analizează burstiness împreună cu coerența semantică, acuratețea factuală și adecvarea contextuală. Apariția uneltelor de „umanizare” AI care cresc deliberat burstiness și alte trăsături umane reprezintă o cursă continuă între tehnologiile de detecție și cele de evitare. Totuși, experții prezic că detecția AI cu adevărat fiabilă va depinde în cele din urmă de metode criptografice de verificare și urmărirea provenienței, nu doar de analiza lingvistică. Pentru creatorii de conținut și organizații, implicația strategică este clară: în loc să trateze burstiness ca pe o metrică de manipulat, scriitorii ar trebui să dezvolte stiluri autentice, variate, care reflectă natural tiparele comunicării umane. Platforma de monitorizare AmICited reprezintă o nouă frontieră, urmărind modul în care brandurile apar în răspunsurile generate de AI și analizând caracteristicile lingvistice ale acestor apariții. Pe măsură ce sistemele AI devin tot mai prezente în generarea și distribuția conținutului, înțelegerea burstiness și a metricilor conexe devine esențială pentru menținerea autenticității brandului, asigurarea integrității academice și păstrarea distincției între conținutul uman și cel generat automat. Evoluția spre abordări de detecție multi-semnale sugerează că burstiness va rămâne relevant ca element în sistemele complexe de monitorizare AI, deși rolul său va deveni tot mai nuanțat și dependent de context.
Burstiness și perplexity sunt metrici complementare folosite în detecția AI. Perplexity măsoară cât de previzibile sunt cuvintele individuale într-un text, în timp ce burstiness măsoară variația structurii și lungimii propozițiilor într-un document. Scrierea umană prezintă de obicei perplexity mai mare (alegeri de cuvinte mai imprevizibile) și burstiness mai ridicat (structuri de propoziții mai variate), în timp ce textul generat de AI tinde să aibă valori scăzute pentru ambele metrici din cauza bazării pe tipare statistice din datele de antrenament.
Burstiness ridicat creează un flux ritmic ce sporește angajamentul și înțelegerea cititorului. Când scriitorii alternează între propoziții scurte, de impact, și altele mai lungi și complexe, mențin interesul cititorului și previn monotonia. Cercetările arată că structura variată a propozițiilor îmbunătățește retenția memoriei și face conținutul să pară mai autentic și conversațional. Burstiness scăzut, caracterizat de lungimi uniforme ale propozițiilor, poate face textul să pară robotic și greu de urmărit, reducând scorurile de lizibilitate și angajamentul publicului.
Deși burstiness poate fi crescută intenționat prin variarea deliberată a structurii propozițiilor, această abordare artificială produce adesea un text cu sonoritate nenaturală, care poate declanșa alte mecanisme de detecție. Detectorii moderni de AI analizează multiple trăsături lingvistice dincolo de burstiness, inclusiv coerența semantică, adecvarea contextuală și tiparele stilometrice. Burstiness autentică apare natural din scrierea umană veritabilă și reflectă vocea unică a autorului, pe când variația forțată nu are de obicei calitatea organică specifică textelor scrise de oameni.
Vorbitorii non-nativi de engleză prezintă frecvent scoruri mai mici la burstiness deoarece modelele lor de scriere reflectă un vocabular mai limitat și strategii de construcție a propozițiilor mai simple. Cei care învață limba folosesc de obicei structuri de propoziții uniforme și previzibile pe măsură ce își dezvoltă competențele, evitând propozițiile complexe și tiparele sintactice variate. Acest lucru creează un profil stilometric similar cu cel al textelor generate de AI, ducând la rezultate fals pozitive în sistemele de detecție AI. Cercetarea de la Universitatea Stanford din 2023 pe eseuri TOEFL a confirmat această tendință, evidențiind o limitare majoră a metodelor de detecție bazate pe burstiness.
Modelele de limbaj de mari dimensiuni sunt antrenate pe seturi masive de date din care învață să prezică următorul cuvânt pe baza tiparelor statistice. În timpul antrenamentului, aceste modele sunt optimizate pentru a minimiza perplexity-ul pe datele de antrenament, ceea ce determină, indirect, structuri de propoziții uniforme și secvențe de cuvinte previzibile. Acest lucru duce la burstiness scăzut deoarece modelele generează text selectând combinații de cuvinte statistic probabile, nu prin folosirea construcțiilor spontane și variate caracteristice scrierii umane. Dependența modelelor de distribuțiile de probabilitate creează o semnătură stilistică omogenă.
AmICited urmărește modul în care brandurile și domeniile apar în răspunsurile generate de AI pe platforme precum ChatGPT, Perplexity și Google AI Overviews. Înțelegerea burstiness ajută sistemul de monitorizare AmICited să distingă între citări autentice scrise de oameni și conținut generat de AI care menționează brandul tău. Analizând tiparele de burstiness împreună cu alți indicatori lingvistici, AmICited poate oferi perspective mai precise despre dacă brandul tău este citat în conținut uman autentic sau în răspunsuri generate de AI, facilitând o mai bună gestionare a reputației brandului.
Scriitorii pot îmbunătăți burstiness organic, variind conștient construcția propozițiilor, menținând totodată claritatea și scopul. Tehnicile includ alternarea între propoziții declarative simple și propoziții complexe cu mai multe propoziții subordonate, folosirea dispozitivelor retorice precum fragmentele sau cratimele pentru accentuare și variarea lungimii paragrafelor. Cheia este ca variația să servească sensului conținutului, nu să existe de dragul metricii. Cititul cu voce tare, studiul stilurilor diverse și revizuirea cu atenție la ritm dezvoltă în mod natural abilitatea de a produce texte cu burstiness ridicat, autentice și captivante.
Începe să urmărești cum te menționează chatbot-urile AI pe ChatGPT, Perplexity și alte platforme. Obține informații utile pentru a-ți îmbunătăți prezența în AI.
Află ce înseamnă burstiness în conținutul generat de AI, cum diferă față de modelele de scriere umană și de ce este important pentru detectarea AI și autenticit...
Discuție comunitară despre burstiness în detectarea conținutului AI - ce înseamnă, cum afectează vizibilitatea în AI și dacă creatorii de conținut ar trebui să ...
Află ce este densitatea informației și cum îmbunătățește șansele de citare de către AI. Descoperă tehnici practice pentru optimizarea conținutului pentru sistem...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.