
Erori de acces AI
Află despre erorile de acces AI - probleme tehnice care împiedică roboții AI să acceseze conținutul. Înțelege redarea JavaScript, robots.txt, datele structurate...
9 min citire
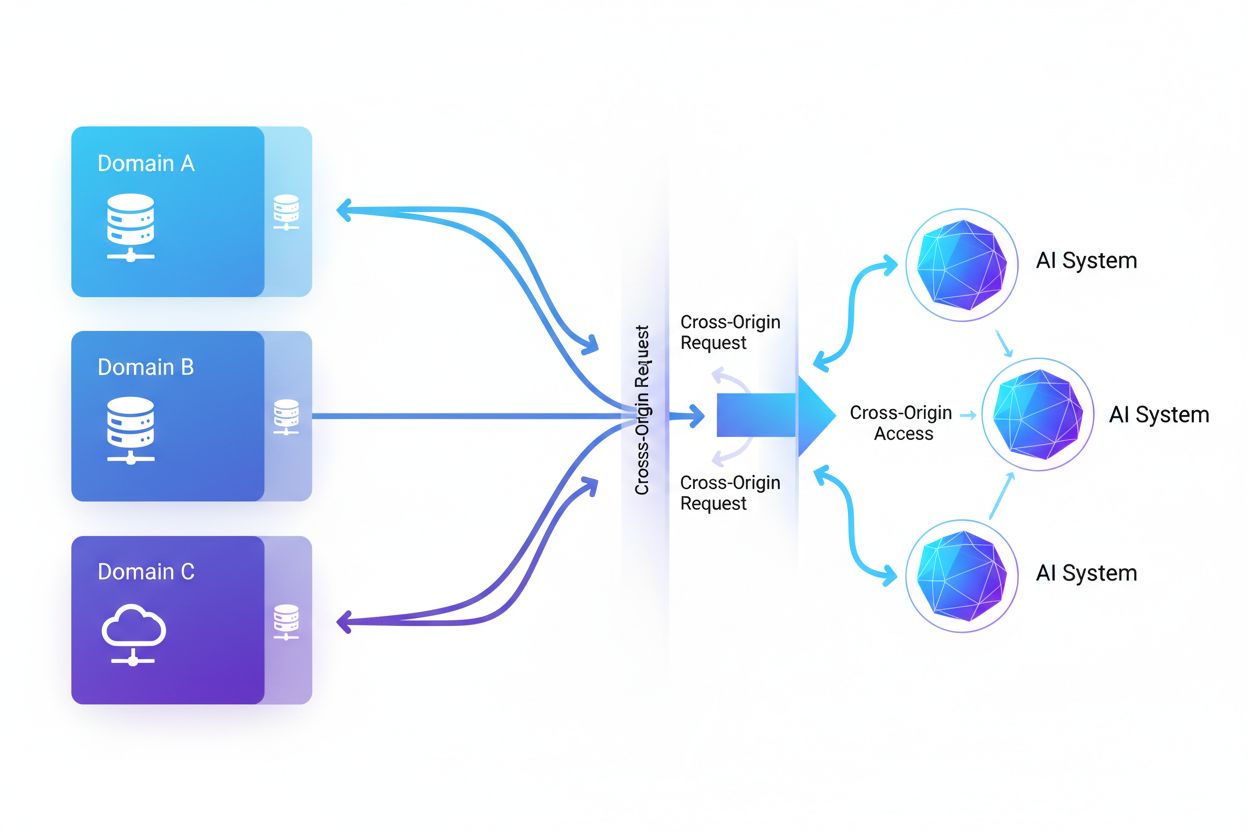
Accesul AI între origini se referă la capacitatea sistemelor de inteligență artificială și a crawlerelor web de a solicita și prelua conținut de pe domenii diferite de cel de origine, guvernată de mecanisme de securitate precum CORS. Acest concept cuprinde modul în care companiile AI își extind colectarea de date pentru antrenarea modelelor lingvistice mari, navigând în același timp restricțiile între origini. Înțelegerea acestui concept este esențială pentru creatorii de conținut și proprietarii de site-uri pentru a-și proteja proprietatea intelectuală și a menține controlul asupra modului în care conținutul lor este folosit de sistemele AI. Vizibilitatea activității AI între origini ajută la diferențierea între accesul AI legitim și scraping-ul neautorizat.
Accesul AI între origini se referă la capacitatea sistemelor de inteligență artificială și a crawlerelor web de a solicita și prelua conținut de pe domenii diferite de cel de origine, guvernată de mecanisme de securitate precum CORS. Acest concept cuprinde modul în care companiile AI își extind colectarea de date pentru antrenarea modelelor lingvistice mari, navigând în același timp restricțiile între origini. Înțelegerea acestui concept este esențială pentru creatorii de conținut și proprietarii de site-uri pentru a-și proteja proprietatea intelectuală și a menține controlul asupra modului în care conținutul lor este folosit de sistemele AI. Vizibilitatea activității AI între origini ajută la diferențierea între accesul AI legitim și scraping-ul neautorizat.
Accesul AI între origini se referă la capacitatea sistemelor de inteligență artificială și a crawlerelor web de a solicita și prelua conținut de pe domenii diferite de cel de origine, guvernată de mecanisme de securitate precum Cross-Origin Resource Sharing (CORS). Pe măsură ce companiile AI își extind eforturile de colectare a datelor pentru antrenarea modelelor lingvistice mari și a altor sisteme AI, înțelegerea modului în care aceste sisteme navighează restricțiile între origini a devenit esențială pentru creatorii de conținut și proprietarii de site-uri. Provocarea constă în a distinge între accesul AI legitim pentru indexarea căutărilor și scraping-ul neautorizat pentru antrenarea modelelor, ceea ce face ca vizibilitatea activității AI între origini să fie crucială pentru protejarea proprietății intelectuale și menținerea controlului asupra modului în care este folosit conținutul.
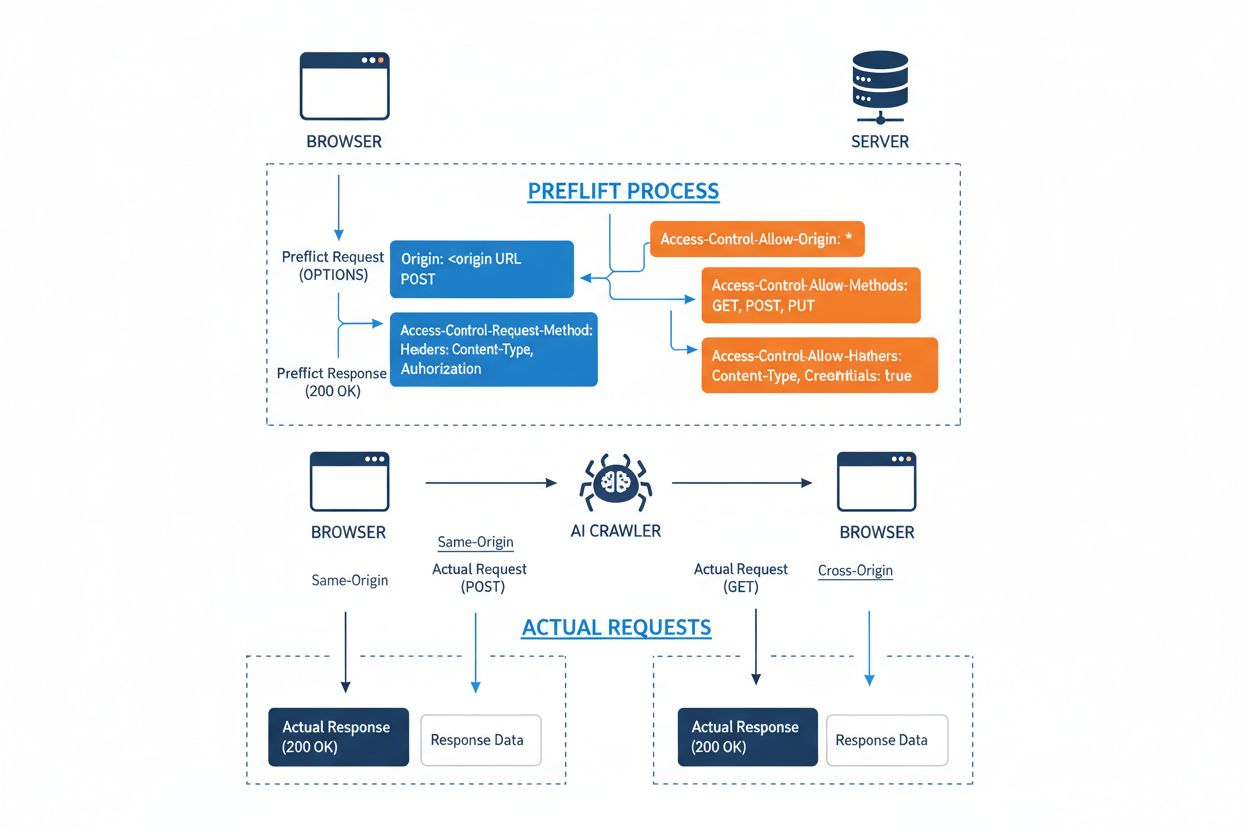
Cross-Origin Resource Sharing (CORS) este un mecanism de securitate bazat pe anteturi HTTP care permite serverelor să specifice ce origini (domenii, scheme sau porturi) pot accesa resursele lor. Atunci când un crawler AI sau orice client încearcă să acceseze o resursă de pe o altă origine, browserul sau clientul inițiază o cerere prealabilă folosind metoda HTTP OPTIONS pentru a verifica dacă serverul permite cererea reală. Serverul răspunde cu anteturi CORS specifice care stabilesc permisiunile de acces, inclusiv ce origini sunt permise, ce metode HTTP sunt acceptate, ce anteturi pot fi incluse și dacă credențiale precum cookie-uri sau tokenuri de autentificare pot fi trimise împreună cu cererea.
| Antet CORS | Scop |
|---|---|
Access-Control-Allow-Origin | Specifică ce origini pot accesa resursa (* pentru toate sau domenii specifice) |
Access-Control-Allow-Methods | Enumeră metodele HTTP permise (GET, POST, PUT, DELETE etc.) |
Access-Control-Allow-Headers | Definește ce anteturi de cerere sunt permise (Authorization, Content-Type etc.) |
Access-Control-Allow-Credentials | Stabilește dacă credențialele (cookie-uri, tokenuri de autentificare) pot fi incluse în cereri |
Access-Control-Max-Age | Specifică cât timp pot fi memorate în cache răspunsurile la cererile prealabile (în secunde) |
Access-Control-Expose-Headers | Enumeră anteturile de răspuns pe care clienții le pot accesa |
Crawler-ele AI interacționează cu CORS respectând aceste anteturi atunci când sunt configurate corect, deși multe boți sofisticați încearcă să ocolească aceste restricții imitând user agent-ul sau utilizând rețele proxy. Eficiența CORS ca apărare împotriva accesului AI neautorizat depinde în totalitate de configurarea corectă a serverului și de disponibilitatea crawler-ului de a respecta restricțiile—o distincție crucială, tot mai importantă pe măsură ce companiile AI concurează pentru date de antrenament.
Peisajul crawler-elor AI care accesează web-ul s-a extins dramatic, cu câțiva jucători majori care domină modelele de acces între origini. Potrivit analizei traficului de rețea realizate de Cloudflare, cei mai răspândiți crawler-i AI sunt:
Acești crawler-i generează miliarde de cereri lunar, iar unii precum Bytespider și GPTBot accesează majoritatea conținutului public al internetului. Volumul și agresivitatea acestei activități au determinat platforme mari precum Reddit, Twitter/X, Stack Overflow și numeroase organizații de știri să implementeze măsuri de blocare.
Politicile CORS configurate greșit creează vulnerabilități majore de securitate pe care crawler-ele AI le pot exploata pentru a accesa date sensibile fără autorizare. Atunci când serverele setează Access-Control-Allow-Origin: * fără validare corespunzătoare, permit involuntar oricărei origini—inclusiv scraper-elor AI malițioase—să acceseze resurse care ar trebui restricționate. O configurație deosebit de periculoasă apare când Access-Control-Allow-Credentials: true este combinat cu setări wildcard pentru origine, permițând atacatorilor să fure datele utilizatorilor autentificați prin cereri între origini care includ cookie-uri de sesiune sau tokenuri de autentificare.
Configurări frecvente greșite ale CORS includ reflectarea dinamică a antetului Origin direct în răspunsul Access-Control-Allow-Origin fără validare, ceea ce permite practic oricărei origini să acceseze resursa. Listele permisive de allow-list care nu validează corect limitele domeniului pot fi exploatate prin atacuri de tip subdomeniu sau manipulare de prefix. De asemenea, multe organizații nu implementează validarea corectă a antetului Origin, devenind vulnerabile la cereri imitate. Consecințele acestor vulnerabilități depășesc furtul de date și includ antrenarea neautorizată a modelelor AI pe conținut proprietar, colectare de informații competitive și încălcarea drepturilor de proprietate intelectuală—riscuri pe care instrumente precum AmICited.com ajută organizațiile să le monitorizeze și cuantifice.
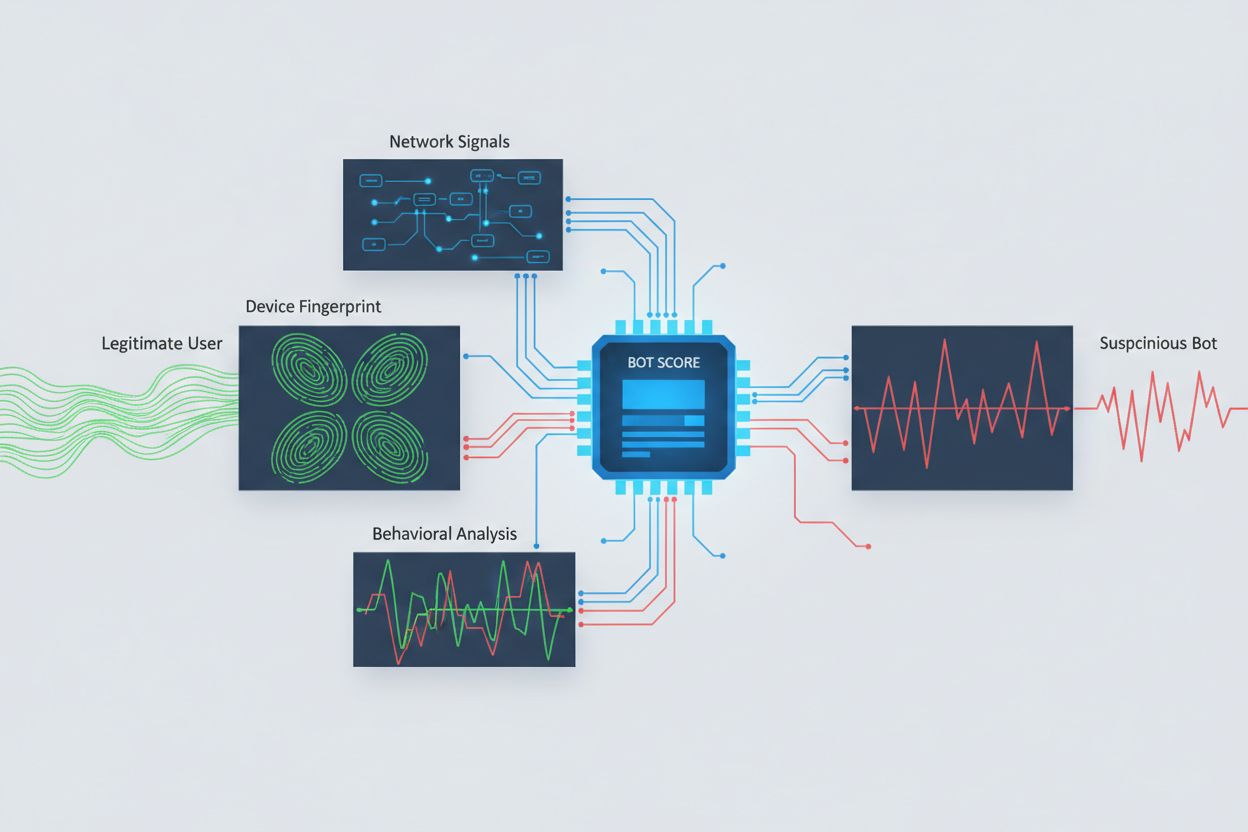
Identificarea crawler-elor AI care încearcă accesul între origini necesită analizarea mai multor semnale dincolo de simpla verificare a stringurilor user agent, care pot fi ușor imitate. Analiza user agent-ului rămâne o primă linie de detecție, deoarece multe crawler-e AI se identifică prin stringuri specifice precum “GPTBot/1.0” sau “ClaudeBot/1.0”, deși crawler-ele sofisticate își ascund intenționat identitatea imitând browsere legitime. Amprentarea comportamentală analizează modul în care sunt făcute cererile—examinând modele precum momentul cererilor, secvența paginilor accesate, prezența sau absența execuției JavaScript și tipare de interacțiune diferite fundamental de comportamentul uman.
Analiza semnalelor de rețea oferă capacități de detecție mai profunde prin examinarea semnăturilor handshake TLS, reputația IP-ului, modelele de rezoluție DNS și caracteristicile conexiunii care indică activitate de tip bot chiar și când user agent-ul este imitat. Amprentarea dispozitivului agregă zeci de semnale precum versiunea browserului, rezoluția ecranului, fonturile instalate, detalii despre sistemul de operare și amprente JA3 TLS pentru a crea identificatori unici pentru fiecare sursă de cerere. Sistemele avansate de detecție pot identifica atunci când mai multe sesiuni provin de la același dispozitiv sau script, depistând tentative de scraping distribuit ce încearcă să evite limitarea ratei răspândind cererile pe mai multe adrese IP. Organizațiile pot folosi aceste metode de detecție prin platforme de securitate și servicii de monitorizare pentru a obține vizibilitate asupra sistemelor AI care accesează conținutul lor și asupra modului în care încearcă să ocolească restricțiile.
Organizațiile folosesc mai multe strategii complementare pentru a bloca sau controla accesul AI între origini, recunoscând că nicio metodă unică nu oferă protecție completă:
User-agent: GPTBot urmat de Disallow: /) oferă un mecanism politicos dar voluntar; eficient pentru crawler-ele de bună credință, dar ușor de ignorat de scraper-ele determinateCea mai eficientă apărare combină mai multe straturi, deoarece atacatorii determinați vor exploata slăbiciunile oricărei metode singulare. Organizațiile trebuie să monitorizeze continuu ce metode de blocare funcționează și să se adapteze pe măsură ce crawler-ele evoluează și își perfecționează tehnicile de evitare.
Gestionarea eficientă a accesului AI între origini necesită o abordare cuprinzătoare, stratificată, care să echilibreze securitatea cu nevoile operaționale. Organizațiile ar trebui să implementeze o strategie pe niveluri, începând cu controale de bază precum robots.txt și filtrarea user agent-ului, adăugând apoi mecanisme de detecție și blocare mai sofisticate, pe baza amenințărilor observate. Monitorizarea continuă este esențială—urmărirea sistemelor AI care accesează conținutul, frecvența cererilor și respectarea restricțiilor oferă vizibilitatea necesară pentru a lua decizii informate privind politicile de acces.
Documentarea politicilor de acces ar trebui să fie clară și aplicabilă, cu termeni de utilizare expliciți care interzic scraping-ul neautorizat și specifică consecințele încălcărilor. Audituri regulate ale configurațiilor CORS ajută la identificarea greșelilor înainte ca acestea să fie exploatate, iar menținerea unui inventar actualizat al user agent-urilor și intervalelor IP cunoscute pentru crawler-ele AI permite reacții rapide la noi amenințări. Organizațiile trebuie să ia în considerare și implicațiile de business ale blocării accesului AI—unele crawler-e AI aduc valoare prin indexarea pentru motoarele de căutare sau parteneriate legitime, astfel că politicile trebuie să distingă între modelele de acces benefice și cele dăunătoare. Implementarea acestor practici necesită coordonare între echipele de securitate, juridic și business pentru a asigura alinierea politicilor la obiectivele organizaționale și cerințele de reglementare.
Instrumente și platforme specializate au apărut pentru a ajuta organizațiile să monitorizeze și să controleze accesul AI între origini cu precizie și vizibilitate sporite. AmICited.com oferă monitorizare completă a modului în care sistemele AI fac referire și accesează brandul tău prin GPT-uri, Perplexity, Google AI Overviews și alte platforme AI, oferind vizibilitate asupra modelelor AI care folosesc conținutul tău și a frecvenței cu care brandul tău apare în răspunsuri generate de AI. Această capacitate de monitorizare se extinde la urmărirea modelelor de acces între origini și înțelegerea ecosistemului mai larg de sisteme AI care interacționează cu proprietățile tale digitale.
Dincolo de monitorizare, Cloudflare oferă funcții de management al boților cu blocare cu un singur click pentru crawler-e AI cunoscute, folosind modele de machine learning antrenate pe trafic la nivel de rețea pentru a identifica boții chiar și atunci când își ascund identitatea. AWS WAF (Web Application Firewall) oferă reguli personalizabile pentru blocarea anumitor user agent-uri și intervale de IP, iar Imperva oferă detecție avansată de boți, combinând analiza comportamentală cu inteligența privind amenințările. Bright Data este specializată în înțelegerea tiparelor de trafic ale boților și poate ajuta organizațiile să distingă între diferite tipuri de crawler-e. Alegerea instrumentelor depinde de dimensiunea organizației, nivelul tehnic și cerințele specifice—de la gestionarea simplă a robots.txt pentru site-uri mici, la platforme enterprise de management al boților pentru organizații mari care gestionează date sensibile. Indiferent de instrumentul ales, principiul fundamental rămâne: vizibilitatea asupra accesului AI între origini este baza controlului și protecției eficiente a activelor digitale.
CORS (Cross-Origin Resource Sharing) este un mecanism de securitate care controlează ce origini pot accesa resursele de pe un server. Accesul AI între origini se referă în mod specific la modul în care sistemele AI și crawler-ele interacționează cu CORS pentru a solicita conținut de pe domenii diferite. În timp ce CORS este cadrul tehnic, Accesul AI între origini descrie provocarea practică de a gestiona comportamentul crawlerelor AI în cadrul acestui mecanism, inclusiv detectarea și blocarea accesului AI neautorizat.
Cele mai multe crawler-e AI de bună credință se identifică prin stringuri specifice de user agent, precum 'GPTBot/1.0' sau 'ClaudeBot/1.0', care indică clar scopul lor. Totuși, multe crawler-e sofisticate își ascund intenționat identitatea imitând browsere legitime precum Chrome sau Safari pentru a ocoli blocarea bazată pe user agent. De aceea, sunt necesare metode avansate de detecție, folosind amprentarea comportamentală și analiza semnalelor de rețea, pentru a identifica boții indiferent de identitatea declarată.
robots.txt oferă un mecanism voluntar prin care se solicită crawler-elor să respecte restricțiile de acces, iar crawler-ele AI de bună credință precum GPTBot respectă în general aceste directive. Totuși, robots.txt nu este obligatoriu—scraper-ele determinate îl pot ignora cu ușurință. Multe companii AI au fost surprinse ocolind restricțiile robots.txt, ceea ce îl face o apărare necesară, dar insuficientă, ce trebuie combinată cu metode tehnice de blocare precum filtrarea user agent-ului, limitarea ratei și amprentarea dispozitivului.
Politicile CORS configurate greșit pot permite crawler-elor AI neautorizate să acceseze date sensibile, să fure informații ale utilizatorilor autentificați prin cereri cu credențiale și să extragă conținut proprietar pentru antrenarea neautorizată a modelelor AI. Cele mai periculoase configurații combină setarea wildcard pentru origine cu permisiuni de credențiale, permițând oricărei origini să acceseze resurse protejate. Aceste configurări greșite pot duce la furt de proprietate intelectuală, colectare de informații competitive și încălcarea acordurilor de licențiere a conținutului.
Detectarea necesită analizarea mai multor semnale, nu doar a stringurilor user agent. Poți examina jurnalele serverului pentru user agent-uri cunoscute ale crawlerelor AI, implementa amprentare comportamentală pentru a identifica boții după modul lor de interacțiune, analiza semnale de rețea precum handshake-urile TLS și modelele DNS și folosi amprentarea dispozitivului pentru a depista încercările distribuite de scraping. Instrumente precum AmICited.com oferă monitorizare completă a modului în care sistemele AI fac referire la brandul tău, iar platforme precum Cloudflare oferă detecție de boți bazată pe machine learning, care identifică și crawler-ele care își ascund identitatea.
Nicio metodă unică nu oferă protecție completă, astfel că o abordare stratificată este cea mai eficientă. Începe cu robots.txt și filtrarea user agent-ului pentru apărare de bază, adaugă limitarea ratei pentru a reduce impactul, implementează amprentarea dispozitivului pentru a identifica boții sofisticați și ia în considerare autentificarea sau paywall-urile pentru conținutul sensibil. Cele mai eficiente organizații combină mai multe tehnici și monitorizează continuu care metode funcționează, adaptându-se pe măsură ce crawler-ele își upgradează tehnicile de evitare.
Nu. Deși companii mari precum OpenAI și Anthropic susțin că respectă robots.txt și restricțiile CORS, investigațiile au arătat că multe crawler-e AI ocolesc aceste restricții. Perplexity AI a fost prinsă imitând user agent-ul pentru a evita blocarea, iar cercetările arată că crawler-ele OpenAI și Anthropic au fost observate accesând conținut chiar și când robots.txt interzicea explicit acest lucru. Această lipsă de consistență face ca metodele tehnice de blocare și aplicarea legală să fie tot mai necesare.
AmICited.com oferă monitorizare completă a modului în care sistemele AI fac referire și accesează brandul tău prin GPT-uri, Perplexity, Google AI Overviews și alte platforme AI. Urmărește ce modele AI folosesc conținutul tău, cât de des apare brandul tău în răspunsurile generate de AI și oferă vizibilitate asupra ecosistemului mai larg de sisteme AI care interacționează cu proprietățile tale digitale. Această monitorizare te ajută să înțelegi amploarea accesului AI și să iei decizii informate privind strategia de protecție a conținutului.
Obține vizibilitate completă asupra sistemelor AI care accesează brandul tău prin GPT-uri, Perplexity, Google AI Overviews și alte platforme. Urmărește modelele de acces AI între origini și înțelege modul în care conținutul tău este folosit în antrenarea și inferența AI.
Află despre erorile de acces AI - probleme tehnice care împiedică roboții AI să acceseze conținutul. Înțelege redarea JavaScript, robots.txt, datele structurate...

Află cum influențează autoritatea autorului rezultatele căutărilor AI și răspunsurile generate de AI. Înțelege semnalele E-E-A-T, demonstrarea expertizei și cum...
Află cum funcționează autoritatea citării în răspunsurile generate de AI, cum diferite platforme citează sursele și de ce contează pentru vizibilitatea brandulu...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.