Cum funcționează indexarea pentru motoarele de căutare AI?
Află cum indexarea AI convertește datele în vectori căutabili, permițând sistemelor AI precum ChatGPT și Perplexity să recupereze și să citeze informații releva...
7 min citire
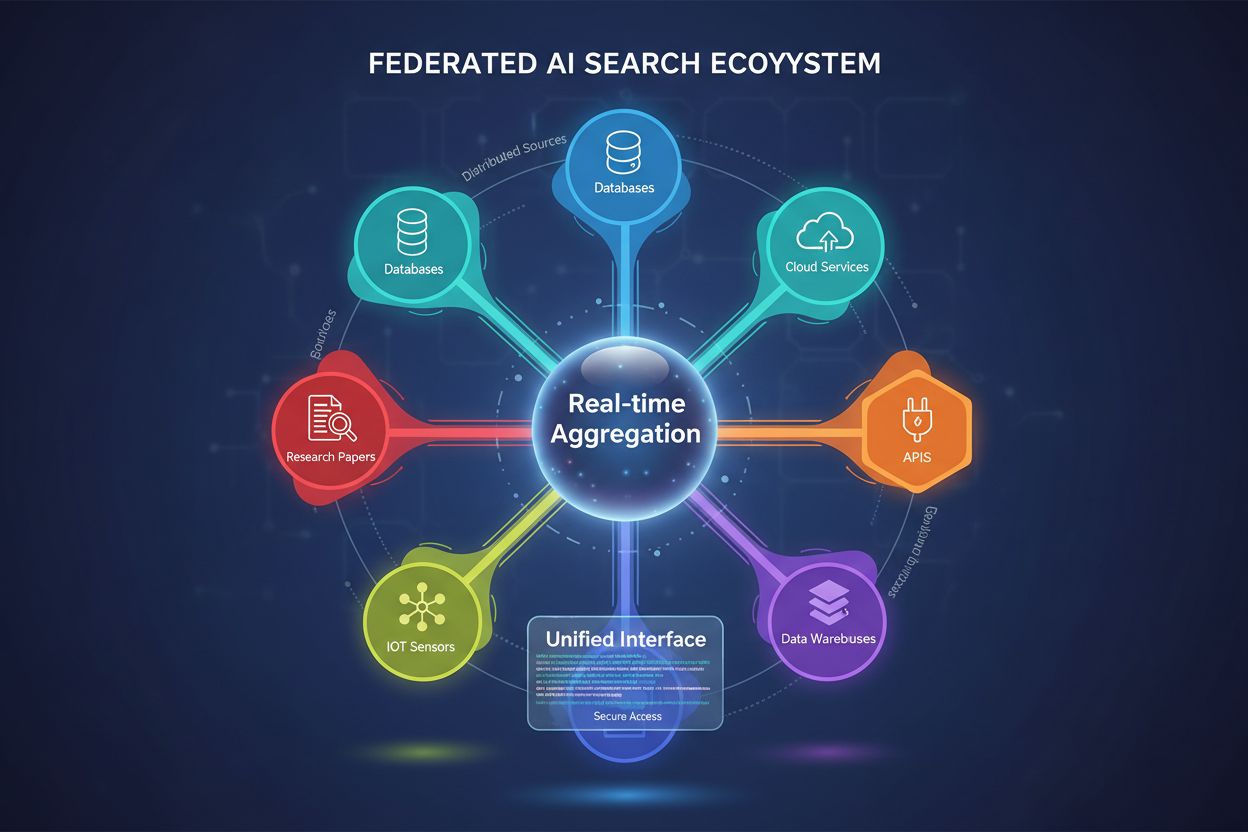
Căutarea AI federată este un sistem care interoghează simultan mai multe surse de date independente folosind o singură interogare și agregă rezultatele în timp real fără a muta sau duplica datele. Aceasta permite organizațiilor să acceseze informații distribuite din baze de date, API-uri și servicii cloud, menținând în același timp securitatea și conformitatea datelor. Spre deosebire de motoarele de căutare centralizate tradiționale, sistemele federate păstrează autonomia datelor, oferind descoperirea unificată a informațiilor. Această abordare este deosebit de valoroasă pentru companiile care gestionează surse de date diverse în departamente, geografii sau organizații diferite.
Căutarea AI federată este un sistem care interoghează simultan mai multe surse de date independente folosind o singură interogare și agregă rezultatele în timp real fără a muta sau duplica datele. Aceasta permite organizațiilor să acceseze informații distribuite din baze de date, API-uri și servicii cloud, menținând în același timp securitatea și conformitatea datelor. Spre deosebire de motoarele de căutare centralizate tradiționale, sistemele federate păstrează autonomia datelor, oferind descoperirea unificată a informațiilor. Această abordare este deosebit de valoroasă pentru companiile care gestionează surse de date diverse în departamente, geografii sau organizații diferite.
Căutarea AI federată este un sistem distribuit de regăsire a informației care interoghează simultan mai multe surse de date eterogene și agregă inteligent rezultatele utilizând tehnici de inteligență artificială. Spre deosebire de motoarele de căutare centralizate tradiționale care mențin un singur depozit indexat, căutarea AI federată operează peste rețele descentralizate de baze de date independente, baze de cunoștințe și sisteme de informații, fără a necesita consolidarea datelor sau indexare centralizată.
Principiul de bază care stă la baza căutării AI federate este interogarea agnostică față de sursă, unde o singură interogare a utilizatorului este direcționată inteligent către sursele de date relevante, procesată independent de fiecare sursă și apoi sintetizată într-un set unificat de rezultate. Această abordare păstrează autonomia datelor, permițând descoperirea cuprinzătoare a informațiilor peste granițe organizaționale și tehnice.
Caracteristicile cheie ale sistemelor de căutare AI federată includ:
Arhitectură Distribuită: Datele rămân în locația lor originală, în mai multe depozite, eliminând necesitatea migrării datelor sau a stocării centralizate. Fiecare sursă își menține independent indexarea, controalele de acces și mecanismele de actualizare.
Direcționare Inteligentă a Interogărilor: Algoritmii AI analizează interogările primite pentru a determina care surse au cele mai mari șanse să conțină informații relevante, optimizând eficiența căutării și reducând interogările inutile către baze de date nerelevante.
Agregare și Clasificare a Rezultatelor: Modelele de învățare automată sintetizează rezultatele din mai multe surse, aplicând algoritmi sofisticați de clasificare care iau în considerare credibilitatea sursei, relevanța rezultatului, actualitatea și contextul utilizatorului.
Suport pentru Surse Eterogene: Sistemele federate acceptă formate de date diverse, scheme, limbaje de interogare și protocoale de acces, inclusiv baze de date relaționale, depozite de documente, grafuri de cunoștințe, API-uri și depozite de text nestructurat.
Integrare în Timp Real: Spre deosebire de abordările batch de tip data warehousing, căutarea federată oferă acces aproape în timp real la informații actuale din toate sursele conectate, asigurând prospețimea și acuratețea rezultatelor.
Înțelegere Semantică: Căutarea AI federată modernă utilizează procesarea limbajului natural și analiza semantică pentru a înțelege intenția interogării dincolo de potrivirea cuvintelor cheie, permițând o selecție mai precisă a surselor și interpretarea rezultatelor.
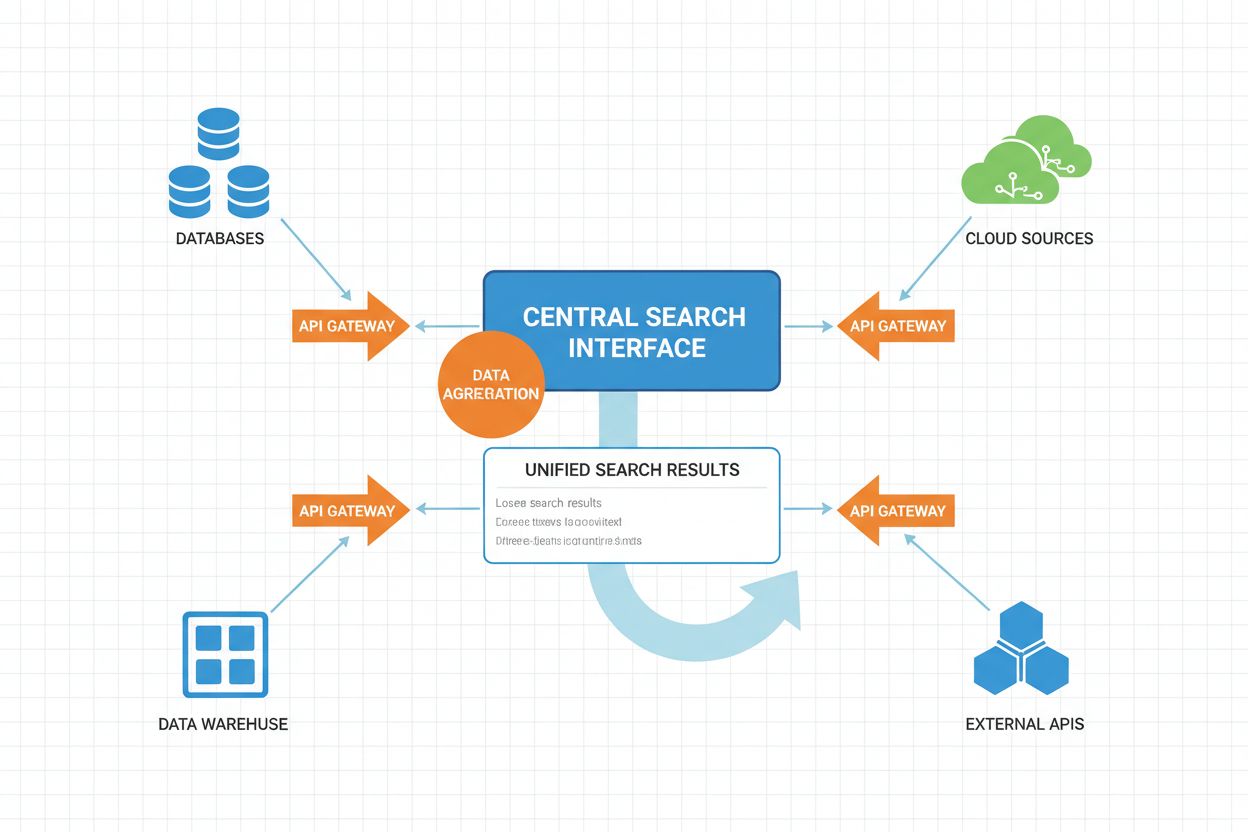
Fluxul operațional al căutării AI federate implică mai multe etape coordonate, fiecare fiind îmbunătățită cu inteligență artificială pentru optimizarea performanței și calității rezultatelor.
| Etapă | Proces | Componentă AI | Ieșire |
|---|---|---|---|
| Analiza Interogării | Interogarea utilizatorului este parsată și analizată pentru intenție, entități și context | NLP, Recunoaștere de Entități Denumite, Clasificare a Intenției | Reprezentare structurată a interogării, entități identificate, semnale de intenție |
| Selecția Sursei | Sistemul determină care surse de date sunt cele mai relevante pentru interogare | Modele de Clasificare & Ranking ML, Clasificatoare de relevanță a sursei | Listă prioritizată de surse țintă, scoruri de încredere |
| Translatarea Interogării | Interogarea este tradusă în formate și limbaje de interogare specifice sursei | Mapare de scheme, Modele de traducere a interogărilor, Potrivire semantică | Interogări specifice sursei (SQL, SPARQL, apeluri API etc.) |
| Execuție Distribuită | Interogările se execută în paralel pe sursele selectate | Balansare de încărcare, Managementul timeout-urilor, Procesare paralelă | Rezultate brute din fiecare sursă, metadate de execuție |
| Normalizarea Rezultatelor | Rezultatele din surse diferite sunt convertite într-un format comun | Aliniere de scheme, Conversie de tipuri de date, Standardizare de format | Set de rezultate normalizate cu structură consistentă |
| Îmbogățire Semantică | Rezultatele sunt îmbogățite cu context și metadate suplimentare | Legare de entități, Etichetare semantică, Integrare grafuri de cunoștințe | Rezultate îmbogățite cu adnotări semantice |
| Clasificare și Deduplicare | Rezultatele sunt clasificate după relevanță și duplicatele sunt eliminate | Modele Learning-to-Rank, Detectare de similaritate, Scorare a relevanței | Listă de rezultate deduplicate și clasificate |
| Personalizare | Rezultatele sunt personalizate după profilul și preferințele utilizatorului | Filtrare colaborativă, Modelare a utilizatorului, Conștientizare a contextului | Ordine personalizată a rezultatelor |
| Prezentare | Rezultatele sunt formatate pentru afișare către utilizator | Generare de limbaj natural, Rezumare a rezultatelor | Afișare a rezultatelor către utilizator |
Fluxul operează cu execuție paralelă în centru, unde mai multe surse sunt interogate simultan și nu secvențial. Această paralelizare reduce dramatic latența totală a interogării, în ciuda efortului de coordonare a multiplelor surse. Sistemele federate avansate implementează planificare adaptivă a interogărilor, unde sistemul învață din tiparele istorice pentru a optimiza selecția surselor și strategiile de execuție în timp.
Mecanismele de timeout și fallback sunt componente critice care asigură fiabilitatea sistemului. Atunci când o sursă răspunde lent sau eșuează, sistemul poate fie să aștepte cu timeout-uri adaptive, fie să continue cu rezultatele disponibile, degradând grațios completitudinea rezultatelor în loc să eșueze total.
Sistemele de căutare AI federată pot fi clasificate pe mai multe dimensiuni:
După Modelul de Arhitectură:
După Tipul de Sursă de Date:
După Scop și Scală:
După Nivelul de Inteligență:
Autonomie și Guvernanță a Datelor: Organizațiile păstrează controlul asupra datelor, eliminând necesitatea transferului informațiilor sensibile către depozite centralizate. Acest lucru păstrează politicile de guvernanță, cerințele de conformitate și controalele de securitate la nivel de sursă.
Scalabilitate Fără Consolidare: Sistemele federate se scalează prin adăugarea de noi surse, fără a necesita migrarea datelor sau restructurarea depozitelor. Organizațiile pot integra incremental surse noi pe măsură ce nevoile evoluează.
Acces la Informații în Timp Real: Prin interogarea directă a surselor, căutarea federată oferă acces la informații actuale fără latența inerentă depozitării batch. Acest lucru este valoros pentru aplicații sensibile la timp ce necesită informații proaspete.
Eficiență a Costurilor: Elimină costurile substanțiale de infrastructură și operaționale asociate construirii și menținerii depozitelor de date centralizate. Organizațiile evită duplicarea datelor, stocarea redundantă și procesele ETL complexe.
Reducerea Redundanței Datelor: Spre deosebire de abordările de tip data warehousing care duplică datele peste sisteme, căutarea federată menține surse unice de adevăr, reducând supraîncărcarea de stocare și asigurând consistența.
Flexibilitate și Adaptabilitate: Surse noi pot fi integrate fără a modifica infrastructura existentă sau a reindexa depozite centralizate. Această flexibilitate permite reacții rapide la cerințele de business în schimbare.
Calitate Îmbunătățită a Datelor: Prin interogarea directă a surselor autorizate, căutarea federată reduce învechirea și inconsistențele care apar din sincronizarea periodică a datelor în abordările clasice.
Securitate Sporită: Datele sensibile nu părăsesc niciodată locația originală, reducând expunerea la acces neautorizat sau breșe. Controalele de acces rămân gestionate la nivel de sursă.
Suport pentru Surse Eterogene: Sistemele federate acceptă tehnologii, formate și protocoale diverse, fără a necesita standardizare sau migrare pe platforme comune.
Sinteză Inteligentă a Rezultatelor: Clasificarea și agregarea bazate pe AI produc rezultate de calitate superioară față de simpla fuziune, luând în considerare credibilitatea sursei, relevanța rezultatului și contextul utilizatorului.
Sistemele moderne de căutare AI federată cuprind mai multe componente tehnice interconectate care lucrează împreună pentru a furniza capabilități de căutare integrate.
Motor de Procesare a Interogărilor: Componenta centrală care primește interogările utilizatorului și orchestrează fluxul căutării federate. Include module de parsare a interogărilor, analiză semantică și recunoaștere a intenției. Implementările avansate folosesc modele lingvistice bazate pe transformer pentru a înțelege semantica complexă și intenția implicită a utilizatorilor.
Registru de Surse și Managementul Metadatelor: Păstrează metadate complete despre sursele de date disponibile, inclusiv informații de schemă, caracteristici de conținut, frecvența actualizărilor, tipare de disponibilitate și metrici de performanță. Acest registru permite selecția inteligentă a surselor și optimizarea interogărilor. Modelele de învățare automată analizează tipare istorice pentru a prezice relevanța surselor la interogări noi.
Modul Inteligent de Selecție a Sursei: Folosește clasificatoare de învățare automată pentru a determina care surse au cele mai mari șanse să conțină informații relevante pentru o anumită interogare. Modulul ia în considerare acoperirea conținutului sursei, rata de succes istorică, disponibilitatea sursei și timpul estimat de răspuns. Sistemele avansate utilizează învățarea prin întărire pentru a optimiza continuu strategiile de selecție pe baza rezultatelor.
Strat de Translatare și Adaptare a Interogărilor: Convertește interogările utilizatorilor în formate și limbaje specifice surselor. Include generare SQL pentru baze de date relaționale, SPARQL pentru grafuri de cunoștințe, apeluri REST API pentru servicii web și interogări în limbaj natural pentru sisteme nestructurate. Maparea semantică asigură menținerea intenției interogării peste diferite modele de date.
Coordonator de Execuție Distribuită: Gestionează execuția paralelă a interogărilor peste mai multe surse, gestionând timeout-uri, balansare de încărcare și recuperare la eșec. Componenta implementează strategii adaptive de timeout bazate pe tiparele de răspuns și încărcarea sistemului.
Motor de Normalizare a Rezultatelor: Convertește rezultatele din surse eterogene într-un format comun pentru agregare și clasificare. Include alinierea de scheme, conversia tipurilor de date și standardizarea formatelor. Motorul gestionează câmpuri lipsă, tipuri de date conflictuale și diferențe structurale între surse.
Modul de Îmbogățire Semantică: Îmbogățește rezultatele cu context suplimentar și informații semantice. Include legarea de entități la baze de cunoștințe, etichetare semantică pe ontologii și extragerea relațiilor din text nestructurat. Aceste îmbogățiri cresc acuratețea clasificării și comprehensibilitatea rezultatelor.
Model Learning-to-Rank: Model de învățare automată antrenat pe perechi interogare-rezultat istorice pentru a prezice relevanța rezultatului. Modelul ia în considerare sute de caracteristici, inclusiv credibilitatea sursei, prospețimea conținutului, alinierea cu profilul utilizatorului și similaritatea semantică între interogare și rezultat. Implementările moderne folosesc boosting gradienți sau modele neurale de ranking.
Motor de Deduplicare: Identifică și elimină rezultatele duplicate sau aproape duplicate provenite din surse diferite. Folosește metrici de similaritate, inclusiv potrivire exactă, potrivire fuzzy și similaritate semantică pe bază de embedding.
Motor de Personalizare: Personalizează ordinea rezultatelor pe baza profilului utilizatorului, preferințelor istorice și informațiilor de context. Componenta implementează tehnici de filtrare colaborativă și recomandare bazată pe conținut pentru a îmbunătăți relevanța individuală.
Strat de Cache și Optimizare: Implementează strategii inteligente de caching pentru a reduce interogările redundante către surse. Include cache de rezultate, cache de metadate și tipare învățate de interogare care prezic nevoi viitoare de informații.
Modul de Monitorizare și Analiză: Urmărește performanța sistemului, fiabilitatea surselor, tiparele de interogare și metrici de calitate a rezultatelor. Aceste date se reîntorc în componentele de optimizare, permițând îmbunătățirea continuă a sistemului.
Sănătate și Cercetare Medicală: Căutarea federată integrează dosarele pacienților din sisteme spitalicești, baze de date de cercetare, registre de studii clinice și depozite de literatură medicală. Medicii pot interoga istoricul complet al pacienților fără centralizarea datelor sensibile. Cercetătorii accesează date clinice distribuite pentru studii epidemiologice, menținând conformitatea HIPAA și confidențialitatea pacienților.
Servicii Financiare: Băncile și firmele de investiții folosesc căutarea federată pentru a interoga simultan date de tranzacționare, informații de piață, baze de date de reglementare și înregistrări interne. Acest lucru permite evaluarea riscului în timp real, monitorizarea conformității și analiza pieței fără a consolida datele sensibile.
Legal și Conformitate: Cabinetele de avocatură și departamentele juridice caută în baze de date cu jurisprudență, registre de reglementări, sisteme interne și baze de date contracte. Căutarea federată permite cercetare juridică completă, menținând confidențialitatea și privilegiul avocat-client.
E-Commerce și Retail: Comercianții online integrează cataloage de produse din mai multe depozite, sisteme de furnizori și platforme de marketplace. Căutarea federată oferă descoperire unificată a produselor, permițând furnizorilor să mențină sisteme de inventar și strategii de preț independente.
Guvern și Administrație Publică: Agențiile guvernamentale caută în baze de date distribuite, inclusiv date de recensământ, înregistrări fiscale, sisteme de permise și registre publice fără a centraliza informațiile sensibile ale cetățenilor. Acest lucru permite servicii publice complete, menținând securitatea și confidențialitatea datelor.
Producție și Lanț de Aprovizionare: Producătorii integrează baze de date ale furnizorilor, sisteme de inventar, evidențe de producție și platforme logistice. Căutarea federată oferă vizibilitate în lanțul de aprovizionare, permițând partenerilor să mențină sisteme independente.
Educație și Cercetare: Universitățile caută în depozite instituționale, sisteme de bibliotecă, baze de date de cercetare și publicații open-access. Căutarea federată permite descoperire academică completă, respectând autonomia instituțională și drepturile de proprietate intelectuală.
Telecomunicații: Furnizorii de telecomunicații caută în baze de date de clienți, înregistrări de infrastructură, sisteme de facturare și cataloage de servicii. Căutarea federată permite servicii clienți unificate, menținând sisteme separate pentru diferite linii de servicii și regiuni geografice.
Energie și Utilități: Companiile energetice caută în facilități de generare, rețele de distribuție, baze de date clienți și sisteme de conformitate. Căutarea federată oferă vizibilitate operațională, permițând operatorilor regionali să mențină sisteme independente.
Media și Publicare: Organizațiile media caută în depozite de conținut, arhive, sisteme de management al drepturilor și platforme de distribuție. Căutarea federată permite descoperirea completă a conținutului, păstrând proprietatea și restricțiile de licențiere.
Eterogenitatea Sursei și Complexitatea Integrării: Integrarea surselor de date diverse cu scheme, limbaje de interogare și protocoale de acces diferite necesită efort ingineresc semnificativ. Maparea schemelor și alinierea semantică rămân provocări, mai ales când aceleași concepte sunt reprezentate diferit.
Latența Interogărilor și Performanța: Căutarea federată presupune interogarea mai multor surse, ceea ce introduce latență comparativ cu sistemele centralizate. Sursele lente sau nereceptive pot degrada performanța generală. Managementul timeout-urilor necesită ajustări fine pentru a echilibra completitudinea cu viteza.
Fiabilitatea și Disponibilitatea Sursei: Sistemele federate depind de sursele externe să fie disponibile și receptive. Eșecurile rețelei, indisponibilitatea surselor sau degradarea performanței afectează direct calitatea căutării. Degradarea grațioasă devine necesară când sursele eșuează.
Calitatea Rezultatelor și Acuratețea Clasificării: Agregarea rezultatelor din surse cu niveluri diferite de calitate, acoperire și criterii de relevanță este dificilă. Modelele de clasificare trebuie să ia în calcul variațiile de credibilitate și să evite biasarea rezultatelor către anumite surse.
Prospețimea și Consistența Datelor: Sistemele federate accesează date actuale, dar sursele pot avea frecvențe de actualizare și garanții de consistență diferite. Reconcilierea informațiilor conflictuale necesită strategii sofisticate de rezolvare a conflictelor.
Limitări de Scalabilitate: Creșterea numărului de surse crește efortul de coordonare a interogărilor. Selectarea surselor relevante din mii de opțiuni devine costisitoare computațional. Execuția paralelă necesită infrastructură robustă.
Securitate și Controlul Accesului: Sistemele federate trebuie să aplice controale de acces la nivel de sursă, oferind totodată interfețe unificate. Asigurarea accesului doar la informațiile autorizate este complexă, mai ales în medii multi-tenant.
Confidențialitate și Protecția Datelor: Căutarea federată trebuie să respecte reglementări privind confidențialitatea, precum GDPR, CCPA și cerințe specifice industriei. Prevenirea scurgerii datelor sensibile prin agregarea rezultatelor sau analiza metadatelor necesită proiectare atentă.
Descoperirea și Managementul Sursei: Identificarea și catalogarea surselor disponibile, menținerea metadatelor actualizate și gestionarea ciclului de viață necesită efort operațional continuu.
Interoperabilitate Semantică: Realizarea interoperabilității semantice între surse cu ontologii și modele de date diferite rămâne o provocare. Tehnicile automate de mapare de scheme și rezolvare de entități au limitări.
Costul Coordonării: Deși căutarea federată elimină costurile de consolidare a datelor, introduce efort de coordonare. Gestionarea execuției distribuite, a eșecurilor și optimizarea rutării interogărilor necesită infrastructură sofisticată.
Standardizare Limitată: Lipsa unor standarde universale pentru protocoale de căutare federată și interfețe face integrarea sistemelor mai dificilă și crește riscul de lock-in la furnizor.
Căutarea AI Federată vs. Data Warehousing: Data warehousing-ul consolidează datele din mai multe surse într-un depozit centralizat, permițând interogări rapide, dar necesitând efort ETL semnificativ și introducând latență. Căutarea federată interoghează sursele direct, oferind acces în timp real, dar cu o latență mai mare. Warehousing-ul este potrivit pentru analiză istorică și raportare, în timp ce căutarea federată excelează la descoperirea informațiilor actuale.
Căutarea AI Federată vs. Data Lakes: Data lakes stochează date brute din mai multe surse într-o locație centralizată, cu transformare minimă. Oferă flexibilitate, dar implică costuri de stocare și guvernanță semnificative. Căutarea federată evită consolidarea completă a datelor, păstrând autonomia sursei, dar necesitând procesare avansată a interogărilor.
Căutarea AI Federată vs. API-uri și Microservicii: API-urile oferă acces programatic la servicii individuale, dar necesită cunoașterea fiecărei interfețe. Căutarea federată ascunde detaliile specifice sursei, permițând interogare unificată. API-urile sunt potrivite pentru integrare aplicație-la-aplicație, iar căutarea federată pentru descoperirea informațiilor cross-serviciu.
**Căutarea AI Federată
Căutarea centralizată tradițională consolidează toate datele într-un singur depozit indexat, necesitând migrarea datelor și introducând latență. Căutarea AI federată interoghează direct, în timp real, mai multe surse independente, fără a muta sau duplica datele, păstrând autonomia sursei și oferind acces unificat. Acest lucru face căutarea federată ideală pentru organizațiile cu surse de date distribuite și cerințe stricte de guvernanță a datelor.
Căutarea AI federată păstrează datele în locația lor originală și respectă controalele de acces și politicile de securitate ale fiecărei surse. Utilizatorii accesează doar informațiile pentru care sunt autorizați, iar datele sensibile nu părăsesc niciodată sistemul sursă. Această abordare simplifică respectarea reglementărilor precum GDPR și HIPAA, eliminând riscurile asociate cu centralizarea informațiilor sensibile.
Provocările cheie includ gestionarea surselor de date eterogene cu scheme și formate diferite, gestionarea latenței interogărilor din mai multe surse, asigurarea unei clasificări consistente a rezultatelor între surse și menținerea fiabilității sistemului atunci când sursele nu sunt disponibile. Organizațiile trebuie să investească și în managementul robust al metadatelor și în algoritmi inteligenți de selecție a sursei pentru optimizarea performanței.
Da, căutarea AI federată se scalează prin adăugarea de noi surse fără a necesita migrarea datelor sau restructurarea depozitelor. Totuși, pe măsură ce crește numărul surselor, crește și efortul de coordonare a interogărilor. Sistemele moderne folosesc învățarea automată pentru selecția inteligentă a surselor și implementează strategii de cache pentru a menține performanța la scară mare.
Data warehousing-ul consolidează datele într-un depozit centralizat, permițând interogări rapide, dar necesitând ETL semnificativ și introducând latență. Căutarea federată interoghează sursele direct, oferind acces în timp real, dar cu o latență mai mare. Warehousing-ul este potrivit pentru analiză istorică și raportare, în timp ce căutarea federată excelează la descoperirea informațiilor actuale din surse distribuite.
Sănătatea, finanțele, comerțul electronic, sectorul guvernamental și organizațiile de cercetare beneficiază semnificativ de căutarea federată. Sănătatea o folosește pentru integrarea datelor pacienților între furnizori, finanțele pentru conformitate și evaluarea riscurilor, comerțul electronic pentru descoperirea unificată a produselor, iar organizațiile de cercetare pentru căutarea în baze de date academice distribuite.
AI îmbunătățește căutarea federată prin procesare a limbajului natural pentru înțelegerea interogărilor, învățare automată pentru selecția inteligentă a surselor, analiză semantică pentru clasificare mai bună a rezultatelor și deduplicare automată. Modelele AI învață din tipare de interogare pentru a optimiza continuu selecția surselor și agregarea rezultatelor, îmbunătățind performanța sistemului în timp.
Înțelegerea semantică permite sistemelor federate să înțeleagă intenția interogării dincolo de potrivirea cuvintelor cheie, să identifice sursele relevante mai precis și să clasifice rezultatele pe bază de semnificație, nu doar de suprapunerea cuvintelor cheie. Aceasta include recunoașterea entităților, extragerea relațiilor și integrarea grafurilor de cunoștințe, rezultând în răspunsuri mai relevante și potrivite contextului.
AmICited urmărește modul în care sisteme AI precum ChatGPT, Perplexity și Google AI Overviews citează și menționează brandul tău. Înțelege vizibilitatea ta în AI și optimizează prezența în răspunsurile generate de AI.
Află cum indexarea AI convertește datele în vectori căutabili, permițând sistemelor AI precum ChatGPT și Perplexity să recupereze și să citeze informații releva...
Află cum să cercetezi și să monitorizezi interogările de căutare AI pe ChatGPT, Perplexity, Claude și Gemini. Descoperă metode de urmărire a mențiunilor brandul...
Descoperă cele mai bune formate de conținut pentru motoarele de căutare AI precum ChatGPT, Perplexity și Google AI Overviews. Află cum să-ți optimizezi conținut...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.