
ClaudeBot förklarad: Anthropic's crawler och ditt innehåll
Lär dig hur ClaudeBot fungerar, hur den skiljer sig från Claude-Web och Claude-SearchBot, och hur du hanterar Anthropics webb crawlers på din webbplats med robo...
7 min läsning

ClaudeBot är Anthropics webbspindel som används för att samla in träningsdata till Claude AI-modeller. Den genomsöker systematiskt publikt tillgängliga webbplatser för att samla innehåll till maskininlärningsmodeller. Webbplatsägare kan styra ClaudeBots åtkomst via robots.txt-konfiguration. Spindeln följer standarddirektiv i robots.txt, vilket gör att webbplatser kan blockera eller tillåta dess besök.
ClaudeBot är Anthropics webbspindel som används för att samla in träningsdata till Claude AI-modeller. Den genomsöker systematiskt publikt tillgängliga webbplatser för att samla innehåll till maskininlärningsmodeller. Webbplatsägare kan styra ClaudeBots åtkomst via robots.txt-konfiguration. Spindeln följer standarddirektiv i robots.txt, vilket gör att webbplatser kan blockera eller tillåta dess besök.
ClaudeBot är en webbspindel som drivs av Anthropic för att ladda ner träningsdata till dess stora språkmodeller (LLM:er) som driver AI-produkter som Claude. Denna AI-datainsamlare genomsöker systematiskt webbplatser för att samla in innehåll specifikt för maskininlärning, vilket skiljer den från traditionella sökmotorers spindlar som indexerar innehåll för återhämtning. ClaudeBot kan identifieras via sin user agent-sträng och kan blockeras eller tillåtas via robots.txt-konfiguration, vilket ger webbplatsägare kontroll över om deras innehåll används för att träna Anthropics AI-modeller.

ClaudeBot arbetar genom systematiska metoder för webbupptäckt, inklusive att följa länkar från indexerade sidor, bearbeta sitemaps och använda seed-URL:er från publika webbplatslistor. Spindeln laddar ner webbplatsinnehåll för att inkluderas i dataset som används för att träna Claudes språkmodeller, och samlar data från publikt tillgängliga sidor utan krav på autentisering. Till skillnad från sökmotorers spindlar som prioriterar indexering för återhämtning är ClaudeBots crawlande mönster typiskt otydliga, där Anthropic sällan avslöjar specifika urvalskriterier, crawl-frekvens eller prioriteringar för olika innehållstyper.
Följande tabell jämför ClaudeBot med andra Anthropics spindlar:
| Bot-namn | Syfte | User Agent | Omfattning |
|---|---|---|---|
| ClaudeBot | Hämtning av chatthänvisningar och träningsdata | ClaudeBot/1.0 | Allmän webb-crawling för modellträning |
| anthropic-ai | Insamling av träningsdata i stor skala | anthropic-ai | Storskalig insamling av träningsdataset |
| Claude-Web | Webbinriktad crawling för Claude-funktioner | Claude-Web | Webbsök och realtidsinformation |
ClaudeBot fungerar liknande andra stora AI-träningsspindlar som GPTBot (OpenAI) och PerplexityBot (Perplexity), men med tydliga skillnader i omfattning och metodik. Medan GPTBot fokuserar på OpenAIs träningsbehov och PerplexityBot tjänar både sök- och träningssyften, riktar sig ClaudeBot specifikt mot innehåll för Claudes modellträning. Enligt Dark Visitors-data blockerar cirka 18 % av världens 1 000 största webbplatser aktivt ClaudeBot, vilket visar på betydande oro bland publicister kring dess datainsamling. Den största skillnaden ligger i hur varje företag prioriterar insamling av innehåll—Anthropics strategi betonar systematisk, bred crawling för träningsdata, medan sökfokuserade spindlar balanserar indexering med att generera hänvisningstrafik.
Webbplatsägare kan identifiera ClaudeBot-besök genom att övervaka serverloggar efter den särskilda user agent-strängen: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com). ClaudeBot kommer vanligtvis från IP-intervall i USA, och besök kan spåras med serverlogganalys eller dedikerade övervakningsverktyg. Att installera agentanalysplattformar ger realtidsöversikt över ClaudeBot-besök, vilket gör det möjligt för webbplatsägare att mäta frekvens och mönster för crawlande.
Här är ett exempel på hur ClaudeBot syns i serverloggar:
203.0.113.45 - - [03/Jan/2025:09:15:32 +0000] "GET /blog/article-title HTTP/1.1" 200 5432 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)"
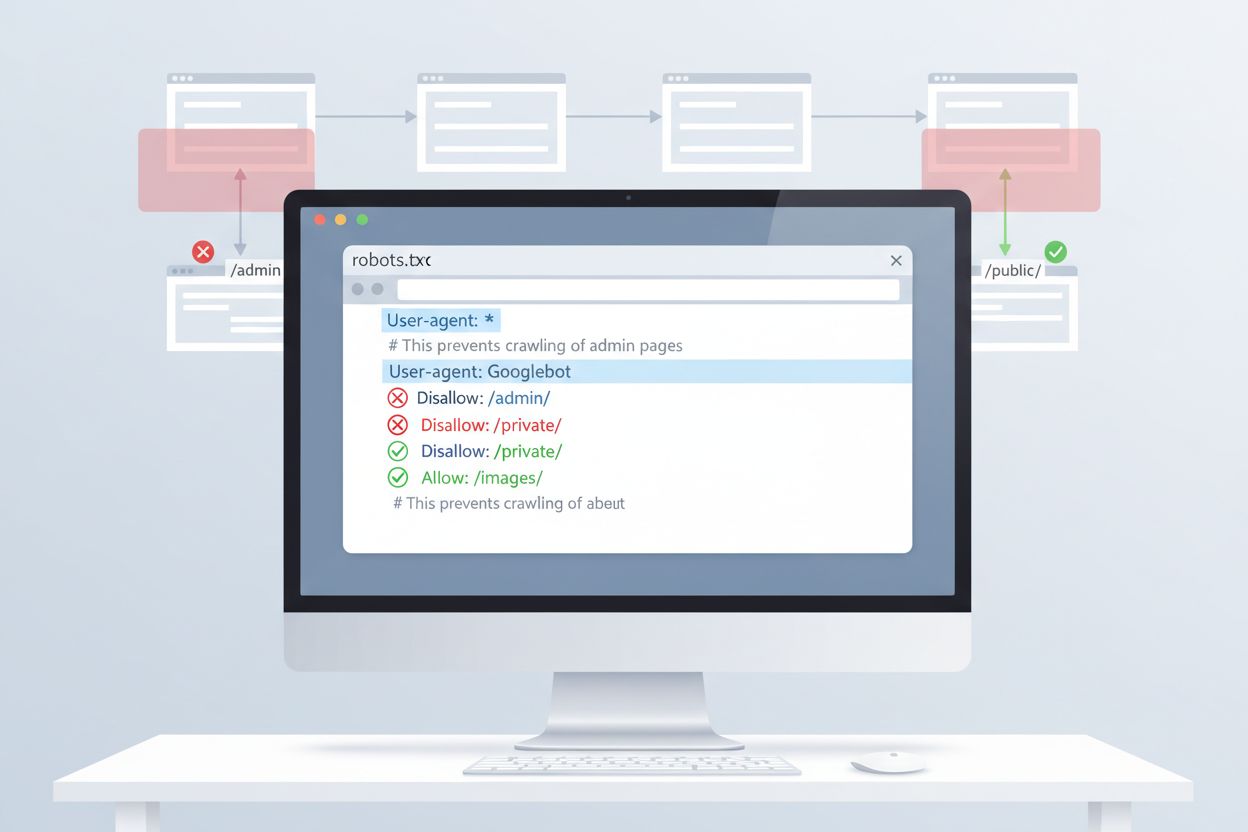
Det enklaste sättet att kontrollera ClaudeBots åtkomst är via robots.txt-konfiguration i din webbplats rotkatalog. Denna fil anger för spindlar vilka delar av din webbplats de får komma åt, och Anthropics ClaudeBot följer dessa direktiv. För att blockera all ClaudeBot-aktivitet, lägg till följande regler i din robots.txt-fil:
User-agent: ClaudeBot
Disallow: /
För mer selektiv blockering som hindrar ClaudeBot från att komma åt vissa kataloger men tillåter annat innehåll att crawlas, använd:
User-agent: ClaudeBot
Disallow: /private/
Disallow: /admin/
Allow: /public/
Om du vill blockera alla Anthropics spindlar (inklusive anthropic-ai och Claude-Web), lägg till separata regler för varje:
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Claude-Web
Disallow: /
Även om robots.txt ger ett första försvarslinje bygger den på frivillig efterlevnad. För publicister som kräver starkare skydd finns flera ytterligare blockeringsmetoder:
Dessa metoder kräver mer teknisk kunskap än robots.txt-konfiguration men ger starkare skydd mot spindlar som inte följer regler.
Att blockera ClaudeBot har minimal direkt påverkan på traditionella SEO-rankingar eftersom träningsspindlar inte bidrar till sökmotorindexering—Google, Bing och andra sökmotorer använder separata spindlar (Googlebot, Bingbot) som fungerar självständigt. Att blockera ClaudeBot kan dock minska din synlighet i AI-genererade svar från Claude, vilket eventuellt påverkar framtida upptäckbarhet via AI-sök och chattgränssnitt. Det strategiska beslutet att blockera eller tillåta ClaudeBot beror på din intäktsmodell: om dina intäkter bygger på direkt webbplatstrafik och annonsvisningar förhindrar blockering att ditt innehåll absorberas i träningsdataset som kan minska besökarantalet. Omvänt kan tillåtelse av ClaudeBot öka din synlighet i Claudes svar, vilket potentiellt kan driva hänvisningstrafik från AI-chattanvändare.
Effektiv hantering av ClaudeBot kräver kontinuerlig övervakning och testning av din konfiguration. Använd verktyg som Google Search Consoles robots.txt-tester, Merkles robots.txt-testverktyg eller specialiserade plattformar som Dark Visitors för att verifiera att dina blockeringsregler fungerar som avsett. Granska regelbundet dina serverloggar för att bekräfta att ClaudeBot följer dina robots.txt-direktiv och övervaka eventuella förändringar i crawlande mönster. Eftersom landskapet för AI-spindlar förändras snabbt med nya bots som upptäcks regelbundet, säkerställer kvartalsvisa granskningar av din robots.txt-konfiguration att du hanterar nya spindlar och bibehåller efterlevnad med din strategi för innehållsskydd. Att testa din konfiguration innan du implementerar den förhindrar oavsiktlig blockering av legitima sökmotorer eller andra viktiga spindlar.
ClaudeBot är Anthropics webbspindel som systematiskt besöker webbplatser för att samla in träningsdata till Claude AI-modeller. Den hittar din webbplats genom länkföljning, bearbetning av sitemaps eller publika webbplatslistor. Spindeln samlar publikt tillgängligt innehåll för att förbättra Claudes språkmodellkapacitet.
Du kan blockera ClaudeBot genom att lägga till en robots.txt-regel i din webbplats rotkatalog. Lägg helt enkelt till 'User-agent: ClaudeBot' följt av 'Disallow: /' för att förhindra all åtkomst, eller ange specifika sökvägar för selektiv blockering. Anthropics ClaudeBot följer robots.txt-direktiv.
Nej, att blockera ClaudeBot påverkar inte din ranking på Google eller Bing. Träningsspindlar som ClaudeBot fungerar oberoende av traditionella sökmotorer. Endast blockering av Googlebot eller Bingbot påverkar din SEO-prestanda.
Anthropic driver tre huvudsakliga spindlar: ClaudeBot (hämtning av chatthänvisningar och träning), anthropic-ai (insamling av träningsdata i stor skala) och Claude-Web (webbinriktad crawling för realtidsfunktioner). Var och en har olika syften inom Anthropics AI-infrastruktur.
Kontrollera dina serverloggar efter ClaudeBots user agent-sträng: 'Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)'. Du kan också använda övervakningsverktyg som Dark Visitors eller sätta upp agentanalys för att spåra ClaudeBot-besök i realtid.
Ja, ClaudeBot följer robots.txt-direktiv enligt Anthropics officiella dokumentation. Men liksom alla robots.txt-regler är efterlevnad frivillig. För starkare skydd kan du införa blockering på servernivå, IP-filtrering eller WAF-regler.
ClaudeBot kan använda betydande bandbredd beroende på din webbplats storlek och innehållsmängd. AI-datainsamlare kan crawla mer aggressivt än traditionella sökmotorer. Genom att övervaka dina serverloggar kan du förstå påverkan och besluta om du vill blockera eller tillåta spindeln.
Beslutet beror på din affärsmodell. Blockera ClaudeBot om du är orolig för innehållsattribution, ersättning eller hur ditt arbete kan användas i AI-system. Tillåt den om du vill att ditt innehåll ska synas i Claudes svar och AI-sökresultat. Tänk över din strategi för intäktsgenerering när du beslutar.
Spåra ClaudeBot och andra AI-spindlar som besöker ditt innehåll. Få insikt om vilka AI-system som hänvisar till ditt varumärke och hur ditt innehåll används i AI-genererade svar.
Lär dig hur ClaudeBot fungerar, hur den skiljer sig från Claude-Web och Claude-SearchBot, och hur du hanterar Anthropics webb crawlers på din webbplats med robo...
Claude är Anthropics avancerade AI-assistent som drivs av Constitutional AI. Lär dig hur Claude fungerar, dess nyckelfunktioner, säkerhetsmekanismer och hur den...

Lär dig vad CCBot är, hur den fungerar och hur du blockerar den. Förstå dess roll i AI-träning, övervakningsverktyg och bästa praxis för att skydda ditt innehål...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.