
Jak získat produkty doporučené umělou inteligencí?
Zjistěte, jak fungují doporučení produktů pomocí umělé inteligence, jaké algoritmy je pohánějí a jak optimalizovat svou viditelnost v systémech doporučování vyu...
8 min čtení
Systémy strojového učení, které analyzují chování a preference uživatelů za účelem poskytování personalizovaných návrhů produktů a obsahu. Tyto systémy využívají algoritmy jako kolaborativní filtrování a filtrování na základě obsahu k předpovídání toho, o co by uživatelé mohli mít zájem, což firmám umožňuje zvýšit zapojení, prodeje a spokojenost zákazníků prostřednictvím cílených doporučení.
Systémy strojového učení, které analyzují chování a preference uživatelů za účelem poskytování personalizovaných návrhů produktů a obsahu. Tyto systémy využívají algoritmy jako kolaborativní filtrování a filtrování na základě obsahu k předpovídání toho, o co by uživatelé mohli mít zájem, což firmám umožňuje zvýšit zapojení, prodeje a spokojenost zákazníků prostřednictvím cílených doporučení.
Doporučení poháněná AI představují sofistikovanou technologii, která využívá algoritmy strojového učení k analýze chování a preferencí uživatelů a poskytuje personalizované návrhy šité na míru individuálním potřebám a zájmům. Jádrem tohoto systému je doporučovací engine, který funguje jako inteligentní prostředník mezi rozsáhlými katalogy produktů a jednotlivými uživateli, což umožňuje bezprecedentní úroveň personalizace v masovém měřítku. Globální trh s doporučovacími systémy zažil explozivní růst – v roce 2023 měl hodnotu přibližně 2,8 miliardy dolarů a do roku 2030 se předpokládá nárůst na 8,5 miliardy dolarů, což odráží zásadní význam této technologie v digitální ekonomice. Tato doporučení poháněná AI se stala nepostradatelnými v různých odvětvích, přičemž výrazné uplatnění nacházejí na e-commerce platformách jako Amazon a eBay, streamovacích službách jako Netflix a Spotify, sociálních sítích i obsahových platformách. Základním principem těchto systémů je, že algoritmy strojového učení dokážou odhalit vzorce v chování uživatelů, které lidé snadno nerozeznají, což firmám umožňuje předvídat potřeby zákazníků dříve, než si je sami uživatelé uvědomí. Díky využití rozsáhlých datových souborů a výpočetního výkonu změnily doporučovací systémy způsob, jakým zákazníci objevují produkty, obsah i služby, a zásadně přetvořily strategie zapojení zákazníků napříč odvětvími.

Doporučovací systémy poháněné AI fungují prostřednictvím sofistikovaného pětifázového procesu, který přeměňuje surová uživatelská data na akční personalizované návrhy. První fáze zahrnuje komplexní sběr dat, kdy systémy získávají informace z mnoha kontaktních bodů včetně uživatelských interakcí, historie prohlížení, záznamů o nákupech a mechanismů explicitní zpětné vazby. Ve fázi analýzy systém tato shromážděná data zpracovává s cílem identifikovat smysluplné vzorce a vztahy, přičemž využívá algoritmy strojového učení jako je kolaborativní filtrování, filtrování na základě obsahu nebo neuronové sítě k získání poznatků z komplexních datových souborů. Fáze rozpoznávání vzorců představuje výpočetní jádro systému – algoritmy zde identifikují podobnosti mezi uživateli, položkami nebo obojím a vytvářejí matematické reprezentace preferencí i vlastností položek. Ve fázi predikce systém využívá rozpoznané vzorce k předpovědi, o které položky by mohl mít uživatel největší zájem, a přiřazuje jednotlivým doporučením skóre jistoty. Poslední, doručovací fáze, prezentuje tyto predikce uživatelům prostřednictvím personalizovaného rozhraní, aby se doporučení objevila v optimálních momentech uživatelské cesty. Stále důležitější jsou schopnosti zpracování v reálném čase – moderní systémy aktualizují doporučení okamžitě při příchodu nových dat o chování uživatele, což umožňuje dynamickou personalizaci přizpůsobující se měnícím se preferencím. Pokročilé doporučovací systémy využívají ansámblové metody, které kombinují více algoritmů najednou – každý z nich přispívá svými predikcemi, což vede k robustnějším a přesnějším výsledkům, než by dokázal kterýkoli jednotlivý přístup zvlášť.
Doporučovací systémy se opírají o dva odlišné typy uživatelských dat, z nichž každá poskytuje jedinečný pohled na preference a vzorce chování:
Explicitní data:
Implicitní data:
Explicitní data poskytují přímý a jednoznačný signál o preferencích uživatele, ale trpí řídkostí, protože většina uživatelů hodnotí jen zlomek dostupných položek. Implicitní data jsou naopak bohatá a vznikají nepřetržitě běžnou interakcí, avšak vyžadují sofistikované interpretace – například zobrazení produktu nemusí znamenat preferenci. Nejefektivnější doporučovací systémy integrují oba typy dat – explicitní zpětnou vazbu využívají k ověření a kalibraci implicitních signálů a vytvářejí tak komplexní uživatelské profily zahrnující deklarované i odhalené preference.
Kolaborativní filtrování je jedním ze základních přístupů v doporučovacích systémech a funguje na principu, že uživatelé s podobnými preferencemi v minulosti budou pravděpodobně mít rádi podobné položky i v budoucnu. Tato metodika analyzuje vzorce napříč celou populací uživatelů a hledá podobnosti, na rozdíl od přístupů, které zkoumají vlastnosti jednotlivých položek. Kolaborativní filtrování založené na uživatelích identifikuje uživatele s podobnou historií preferencí jako má cílový uživatel a doporučuje položky, které se líbily těmto podobným uživatelům, ale cílový uživatel je zatím nezná – tedy využívá „moudrost podobných uživatelů“. Kolaborativní filtrování založené na položkách se naopak zaměřuje na podobnost položek a doporučuje produkty podobné těm, které uživatel dříve dobře hodnotil, na základě toho, jak ostatní uživatelé hodnotili tyto položky navzájem. Oba přístupy využívají sofistikované míry podobnosti, například kosinovou podobnost, Pearsonovu korelaci nebo eukleidovskou vzdálenost, aby kvantifikovaly, jak blízko si uživatelé či položky jsou v prostoru preferencí. Kolaborativní filtrování nabízí významné výhody, například možnost doporučovat položky bez obsahových metadat a schopnost objevovat překvapivá doporučení, která by uživatel nečekal. Tento přístup však čelí i zásadním omezením, zejména „problému studeného startu“, kdy noví uživatelé nebo položky postrádají dostatek historických dat pro přesné výpočty podobnosti, a problémům s řídkostí dat v oblastech s miliony položek, kde většina interakcí zůstává nepozorována.
Filtrování na základě obsahu doporučuje položky na základě analýzy jejich vlastních charakteristik a vlastností; doporučuje produkty podobné těm, které uživatel v minulosti preferoval, a to na základě měřitelných atributů. Místo spoléhání na kolektivní chování uživatelů vytvářejí obsahové systémy detailní profily položek zahrnující relevantní rysy, například žánr, režiséra a herecké obsazení u filmů; autora, téma a datum vydání u knih; nebo kategorii, značku a specifikace u e-commerce položek. Systém počítá podobnost mezi položkami porovnáváním jejich vektorů vlastností matematickými metodami, jako je kosinová podobnost nebo eukleidovská vzdálenost, a vytváří tak kvantitativní měřítko podobnosti v prostoru vlastností. Když uživatel ohodnotí nebo se zapojí do položky, systém identifikuje další položky s podobným profilem a doporučuje tyto alternativy – efektivně personalizuje návrhy podle projevovaných preferencí ke konkrétním vlastnostem. Obsahové filtrování vyniká v situacích, kde jsou metadata položek bohatá a dobře strukturovaná, a přirozeně si poradí s „problémem studeného startu“ u nových položek, protože doporučení závisejí na vlastnostech položek, nikoli na historii uživatelů. Tento přístup však má i omezení v oblasti překvapivosti a objevování, protože má tendenci doporučovat velmi podobné položky jako v minulosti, což může vytvářet „filtrační bubliny“, které uživatele omezují na úzké kategorie. Ve srovnání s kolaborativním filtrováním vyžadují obsahové systémy náročnější práci s vlastnostmi a mají potíže s položkami, které nemají jasné kategorie, nabízejí však lepší transparentnost, protože doporučení lze vysvětlit konkrétními atributy položek.
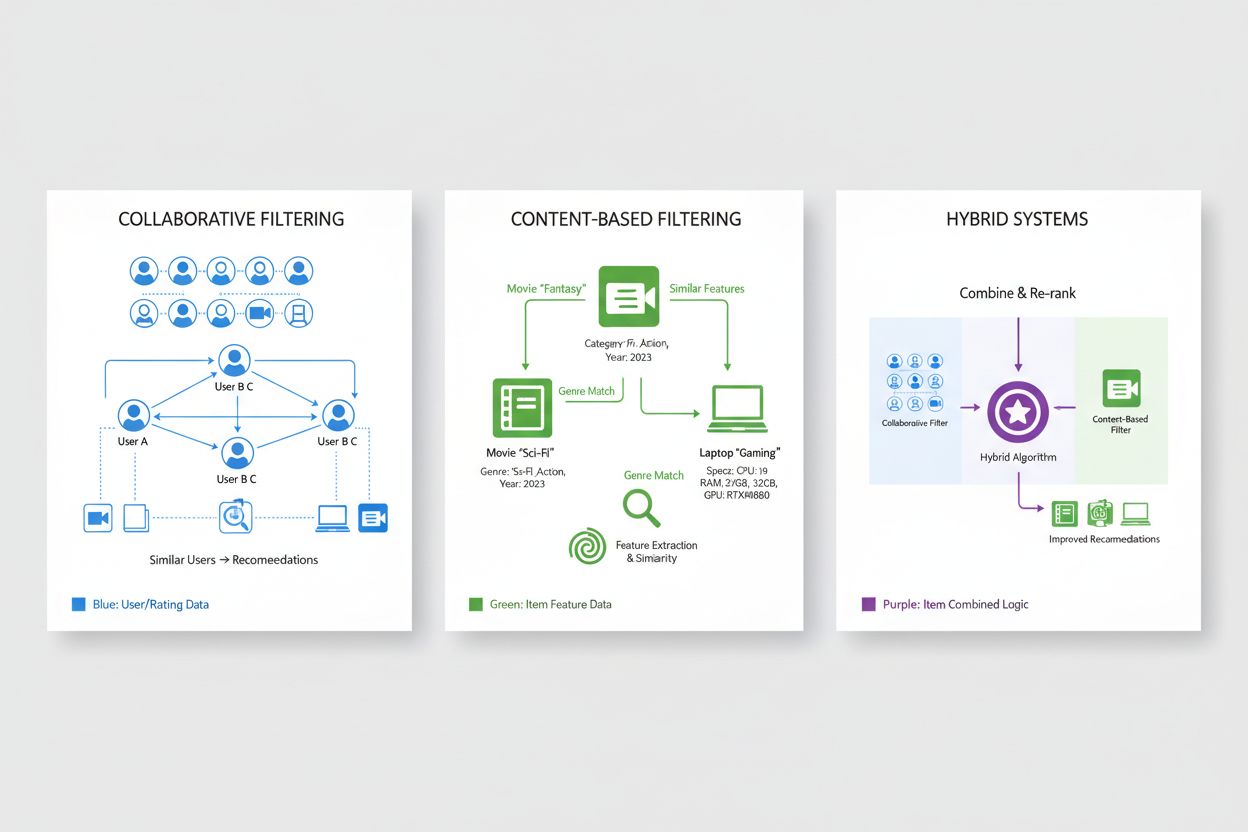
Hybridní doporučovací systémy strategicky kombinují kolaborativní filtrování a filtrování na základě obsahu, využívají komplementární silné stránky obou metodik k překonání jejich individuálních omezení a poskytují vyšší přesnost doporučení. Tyto systémy využívají různé integrační strategie, například vážené kombinace, kdy jsou predikce z více algoritmů sloučeny s předem danými nebo naučenými váhami, přepínací mechanismy, které vybírají nejvhodnější algoritmus podle kontextových faktorů, nebo kaskádové přístupy, kde výstup jednoho algoritmu slouží jako vstup pro další. Integrací schopnosti kolaborativního filtrování objevit překvapivá doporučení a zachytit složité vzorce preferencí s možnostmi obsahového filtrování zvládat nové položky a poskytovat vysvětlitelná doporučení dosahují hybridní systémy robustnějšího výkonu v rozmanitých scénářích. Přední technologické firmy přijaly hybridní přístupy jako průmyslový standard – například Netflix kombinuje kolaborativní a obsahové metody i kontextové informace, aby poskytoval doporučení, která vyvažují popularitu, personalizaci a novost. Doporučovací engine Spotify také využívá hybridní techniky, integruje kolaborativní filtrování na základě poslechových vzorců s obsahovou analýzou zvukových vlastností a metadat, doplněnou o zpracování přirozeného jazyka uživatelsky vytvářených playlistů a recenzí. Výhody hybridních systémů přesahují jen zlepšení přesnosti – zahrnují lepší pokrytí katalogu položek, efektivnější práci s řídkými daty i vyšší odolnost vůči běžným problémům doporučování. Tyto systémy představují současný stav techniky v personalizaci a většina podnikových doporučovacích platforem využívá hybridní architektury, které se neustále vyvíjejí s příchodem nových algoritmických inovací.
Doporučení poháněná AI se stala ústřední součástí obchodních modelů hlavních technologických i maloobchodních společností a zásadně proměnila způsob, jakým zákazníci objevují a nakupují produkty. Amazon, průkopník v e-commerce, generuje přibližně 35 % svého celkového obratu prostřednictvím nákupů podpořených doporučením – jeho sofistikovaný systém analyzuje historii prohlížení, nákupní vzorce, hodnocení produktů i chování podobných zákazníků a navrhuje položky v klíčových momentech nákupní cesty. Netflix zpracovává historii sledování, hodnocení, vyhledávání a časové vzorce pro návrhy obsahu – společnost uvádí, že personalizovaná doporučení tvoří asi 80 % hodin sledování na platformě, což dokládá zásadní vliv efektivní personalizace na zapojení a udržení uživatelů. Spotify využívá doporučení poháněná AI na řadě míst, včetně funkce „Discover Weekly“, která kombinuje kolaborativní filtrování s analýzou zvukových vlastností a kontextu, a generuje tak vysoce personalizovaná hudební doporučení, která jsou klíčová pro zapojení i loajalitu uživatelů. Temu, rychle rostoucí e-commerce platforma, nasazuje pokročilé doporučovací systémy analyzující vzorce chování uživatelů, vyhledávací dotazy i historii nákupů a nabízí produkty odpovídající individuálním preferencím, čímž výrazně přispívá ke svému dynamickému růstu a metrikám zapojení uživatelů. Tyto implementace ukazují, že doporučovací systémy přímo ovlivňují klíčové obchodní metriky – hodnotu zákazníka v čase, opakované nákupy i délku zapojení – a firmy proto do doporučovacích technologií investují jako do klíčového konkurenčního odlišení na stále přeplněnějších digitálních trzích.
Doporučení poháněná AI přinášejí výraznou hodnotu jak podnikům, tak uživatelům a vytvářejí oboustranně výhodný ekosystém podporující zapojení i spokojenost:
Přínosy pro firmy:
Přínosy pro uživatele:
Kumulativní dopad těchto přínosů učinil z doporučovacích systémů klíčovou infrastrukturu digitálního obchodu a obsahových platforem – uživatelé stále více očekávají personalizované zážitky jako základní standard, nikoli jako prémiovou službu.
Navzdory rozšířenému úspěchu čelí doporučovací systémy poháněné AI významným výzvám, kterými se vědci i praktici stále zabývají. Obavy o ochranu soukromí zesílily s příchodem regulací jako GDPR a CCPA, které kladou přísné požadavky na sběr a využití dat a nutí firmy balancovat efektivitu personalizace s právem uživatelů na soukromí a povinností chránit data. Problém studeného startu je stále aktuální zejména pro nové uživatele a položky – nedostatek historických dat znemožňuje přesná doporučení a vyžaduje hybridní přístupy nebo alternativní strategie pro nastartování personalizace. Algoritmická zaujatost je kritickou výzvou, protože doporučovací systémy mohou posilovat a zesilovat existující předsudky v trénovacích datech, což může vést k diskriminaci určitých skupin uživatelů nebo k „filtračním bublinám“, které omezují pestrost perspektiv i obsahu.
Nově se prosazující trendy mění podobu doporučovacích systémů – personalizace v reálném čase je stále sofistikovanější díky edge computingu a zpracování dat ve streamu, které umožňuje okamžité přizpůsobení chování uživatele. Integrace multimodálních dat přesahuje tradiční behaviorální signály a zahrnuje vizuální vlastnosti, zvukové rysy, textový obsah i kontextové informace, což umožňuje bohatší a nuancovanější porozumění preferencím. Doporučení řízená emocemi jsou novou hranicí personalizace – systémy začínají zohledňovat emoční kontext a analýzu sentimentu, aby poskytovala doporučení nejen podle historických preferencí, ale i aktuálního rozpoložení a potřeb. Budoucí vývoj bude pravděpodobně klást důraz na vysvětlitelnost a transparentnost, což uživatelům umožní pochopit, proč se jim konkrétní doporučení zobrazují, a poskytne nástroje ke správě vlastního doporučovacího profilu. Sbližování těchto trendů naznačuje, že příští generace doporučovacích systémů bude více dbát na soukromí, transparentnost, emoční inteligenci a schopnost poskytovat skutečně transformační personalizaci při respektování autonomie i práv uživatelů k jejich datům.
Doporučení poháněná AI proaktivně navrhují položky na základě chování a preferencí uživatele bez nutnosti explicitního vyhledávání, zatímco tradiční vyhledávání vyžaduje, aby uživatelé aktivně zadávali dotazy na produkty. Doporučení využívají strojové učení k předpovídání zájmů, zatímco vyhledávání spoléhá na shodu klíčových slov. Doporučení jsou personalizovaná pro jednotlivé uživatele, zatímco výsledky vyhledávání jsou obvykle obecnější. Moderní systémy často kombinují oba přístupy pro optimální uživatelský zážitek.
Noví uživatelé čelí tzv. 'problému studeného startu', kdy systémy postrádají historická data pro přesná doporučení. Řešení zahrnují využití demografických údajů, zobrazení populárních položek, použití filtrování na základě obsahu (dle vlastností položek) nebo vyžádání explicitních preferencí. Hybridní systémy kombinují více přístupů k nastartování doporučení pro nové uživatele. Některé platformy využívají kolaborativní filtrování s podobnými uživatelskými profily nebo kontextové informace, jako je typ zařízení a poloha, pro počáteční návrhy.
Doporučovací systémy sbírají explicitní data jako hodnocení, recenze a zpětnou vazbu uživatelů, dále implicitní data zahrnující historii prohlížení, záznamy o nákupech, dobu strávenou u položek, vyhledávací dotazy a vzorce klikání. Mohou také shromažďovat kontextové informace, jako je typ zařízení, poloha, denní doba a sezónní faktory. Pokročilé systémy integrují demografická data, sociální vazby a behaviorální signály. Veškerý sběr dat musí být v souladu s předpisy o ochraně soukromí, jako je GDPR a CCPA, což vyžaduje souhlas uživatele a transparentní zásady nakládání s daty.
Ano, doporučovací systémy mohou upevňovat a zesilovat předsudky přítomné ve trénovacích datech, což může vést k diskriminaci určitých skupin uživatelů nebo omezení přístupu k rozmanitému obsahu. Algoritmická zaujatost může vzniknout ze zkreslených historických dat, nedostatečného zastoupení menšinových skupin nebo zpětných vazeb, které posilují stávající vzorce. Řešení zaujatosti vyžaduje různorodá trénovací data, pravidelné audity, metriky spravedlnosti a transparentní návrh algoritmů. Firmy musí aktivně sledovat výskyt zaujatosti a zavádět opatření, která zajistí rovné doporučování napříč všemi segmenty uživatelů.
Hybridní systémy kombinují schopnost kolaborativního filtrování objevovat nečekaná doporučení se schopností filtrování na základě obsahu zpracovávat nové položky a poskytovat vysvětlitelná doporučení. Toto spojení překonává dílčí omezení: kolaborativní filtrování má problém s novými položkami, zatímco obsahové filtrování postrádá prvek překvapení. Hybridní přístupy využívají vážené kombinace, přepínací mechanismy nebo kaskádové metody k využití silných stránek jednotlivých algoritmů. Výsledkem je vyšší přesnost, lepší pokrytí katalogu položek, lepší práce s řídkými daty a robustnější výkon v různých scénářích.
Obavy o soukromí zahrnují rozsáhlý sběr dat potřebný pro přesná doporučení, potenciální neoprávněné použití dat, rizika úniku dat a obtíže s dodržováním předpisů, jako jsou GDPR, CCPA a podobné zákony. Uživatelé se mohou cítit nepříjemně s mírou sledování chování potřebnou pro personalizaci. Firmy musí zavést silné zabezpečení dat, získat explicitní souhlas, zajistit transparentnost ohledně využití dat a umožnit uživatelům kontrolu nad jejich daty. Vyvážení efektivity personalizace s ochranou soukromí zůstává v oboru trvalou výzvou.
Doporučení v reálném čase zpracovávají data o chování uživatelů okamžitě při jejich vzniku a ihned aktualizují návrhy na základě aktuální interakce. Systémy využívají zpracování dat ve streamu a edge computing pro analýzu akcí, jako jsou kliknutí, zhlédnutí nebo nákupy během milisekund. To umožňuje dynamickou personalizaci, která se přizpůsobuje měnícím se preferencím během uživatelské relace. Systémy v reálném čase vyžadují robustní infrastrukturu, efektivní algoritmy a nízkolatenční datové toky. Příklady zahrnují aktualizaci doporučení na Netflixu při procházení, nebo nové návrhy na Amazonu při přidávání položek do košíku.
Budoucí trendy zahrnují doporučení řízená emocemi, která zohledňují emoční stav uživatele, integraci multimodálních dat kombinujících vizuální, zvukové a textové informace, pokročilé techniky ochrany soukromí, lepší vysvětlitelnost a transparentnost a personalizaci v reálném čase ve velkém rozsahu. Nové technologie, jako je federativní učení, umožňují doporučení bez centralizace uživatelských dat. Systémy budou kontextově citlivější a zohlední časové i situační informace. Sbližování těchto trendů přinese sofistikovanější, transparentní a na soukromí zaměřenou personalizaci při respektování autonomie a práv uživatelů k datům.
AmICited sleduje, jak systémy AI jako ChatGPT, Perplexity a Google AI Overviews zmiňují vaši značku v personalizovaných doporučeních a obsahu generovaném AI. Zůstaňte informováni o viditelnosti vaší značky v systémech poháněných AI.
Zjistěte, jak fungují doporučení produktů pomocí umělé inteligence, jaké algoritmy je pohánějí a jak optimalizovat svou viditelnost v systémech doporučování vyu...

Zjistěte, jak AI product discovery využívá konverzační AI a strojové učení k poskytování personalizovaných produktových doporučení a zlepšuje konverze v e-comme...
Zjistěte, jak zákaznické recenze ovlivňují algoritmy AI doporučování, zvyšují přesnost doporučení a zlepšují personalizaci v AI systémech jako ChatGPT, Perplexi...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.