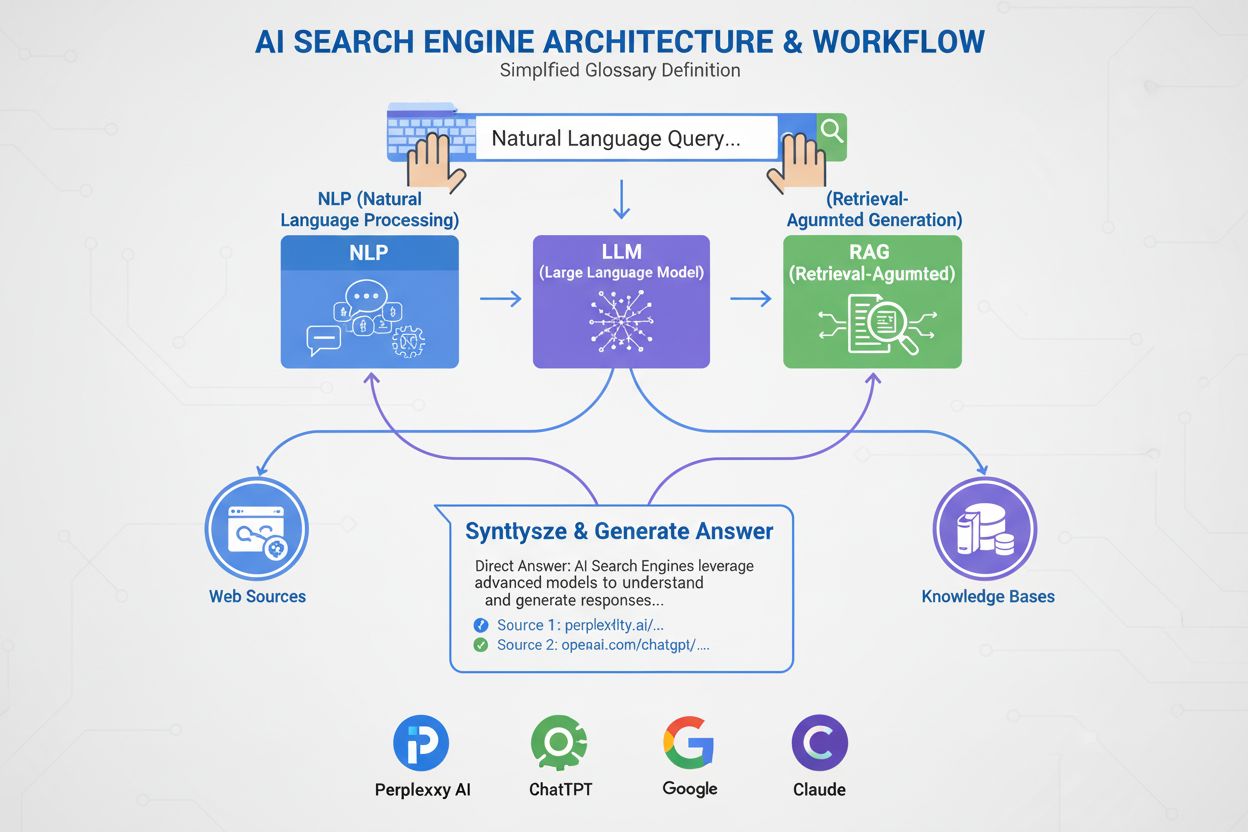
AI vyhledávač
Zjistěte, co jsou AI vyhledávače, jak se liší od tradičního vyhledávání a jak ovlivňují viditelnost značek. Prozkoumejte platformy jako Perplexity, ChatGPT, Goo...
11 min čtení
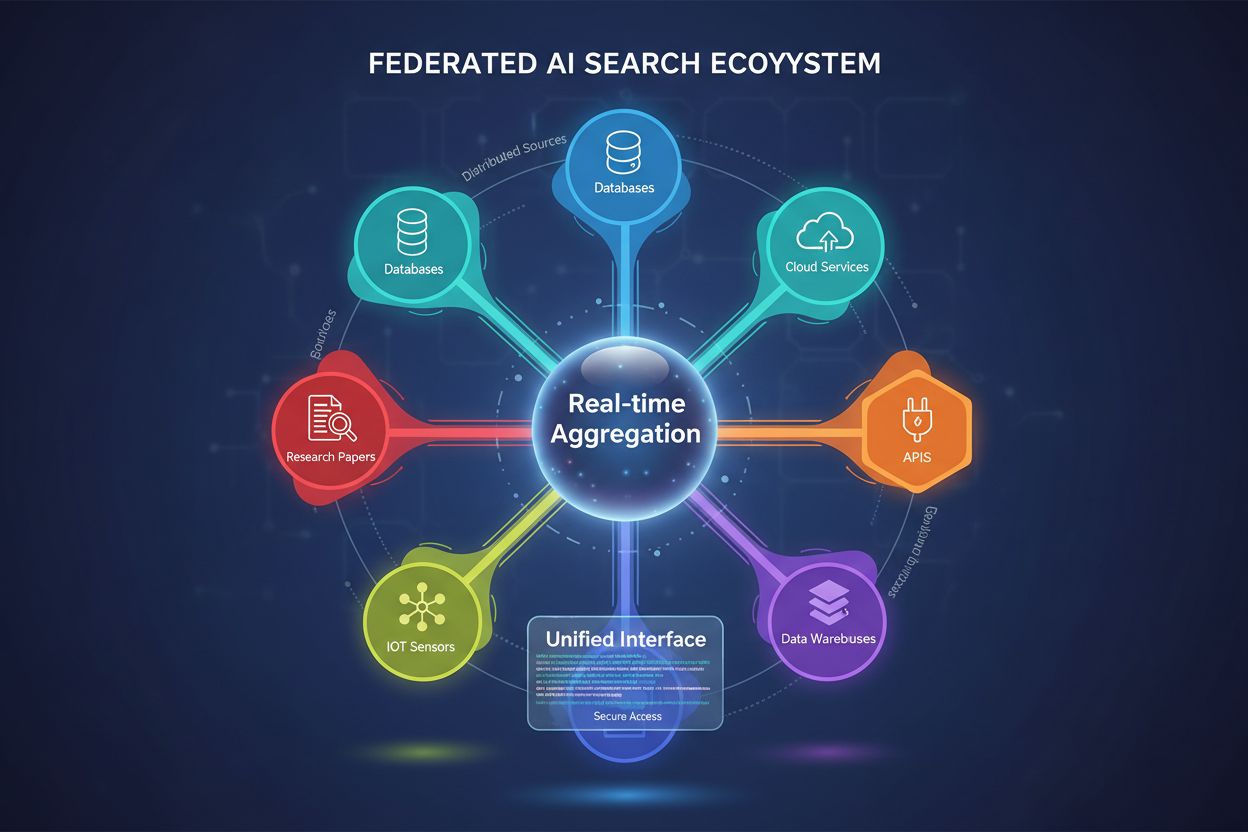
Federovaný AI vyhledávač je systém, který pomocí jednoho dotazu současně prohledává více nezávislých datových zdrojů a v reálném čase agreguje výsledky bez přesunu nebo duplikace dat. Umožňuje organizacím přistupovat k distribuovaným informacím napříč databázemi, API a cloudovými službami při zachování bezpečnosti a souladu s předpisy. Na rozdíl od tradičních centralizovaných vyhledávačů federované systémy zachovávají autonomii datových zdrojů a zároveň poskytují jednotné vyhledávání informací. Tento přístup je obzvlášť cenný pro podniky, které spravují rozmanité datové zdroje napříč různými odděleními, geografickými oblastmi nebo organizacemi.
Federovaný AI vyhledávač je systém, který pomocí jednoho dotazu současně prohledává více nezávislých datových zdrojů a v reálném čase agreguje výsledky bez přesunu nebo duplikace dat. Umožňuje organizacím přistupovat k distribuovaným informacím napříč databázemi, API a cloudovými službami při zachování bezpečnosti a souladu s předpisy. Na rozdíl od tradičních centralizovaných vyhledávačů federované systémy zachovávají autonomii datových zdrojů a zároveň poskytují jednotné vyhledávání informací. Tento přístup je obzvlášť cenný pro podniky, které spravují rozmanité datové zdroje napříč různými odděleními, geografickými oblastmi nebo organizacemi.
Federovaný AI vyhledávač je distribuovaný systém pro vyhledávání informací, který současně dotazuje více různorodých datových zdrojů a inteligentně agreguje výsledky pomocí technik umělé inteligence. Na rozdíl od tradičních centralizovaných vyhledávačů, které udržují jeden indexovaný repozitář, funguje federovaný AI vyhledávač napříč decentralizovanými sítěmi nezávislých databází, znalostních bází a informačních systémů bez nutnosti konsolidace dat nebo centralizovaného indexování.
Základním principem federovaného AI vyhledávání je zdrojově agnostické dotazování, kdy je jeden uživatelský dotaz inteligentně směrován na relevantní datové zdroje, každý zdroj jej zpracuje nezávisle a výstupy jsou syntetizovány do jednotného výsledku. Tento přístup zachovává autonomii dat při umožnění komplexního vyhledávání informací napříč organizačními a technickými hranicemi.
Mezi klíčové vlastnosti federovaných AI vyhledávacích systémů patří:
Distribuovaná architektura: Data zůstávají na svých původních místech napříč různými repozitáři, což eliminuje potřebu migrace dat nebo centralizovaného úložiště. Každý zdroj si zachovává vlastní indexování, přístupová práva a mechanismy aktualizace.
Inteligentní směrování dotazů: AI algoritmy analyzují příchozí dotazy a určují, které zdroje s největší pravděpodobností obsahují relevantní informace, čímž optimalizují efektivitu vyhledávání a minimalizují zbytečné dotazy do nerelevantních databází.
Agregace a řazení výsledků: Modely strojového učení syntetizují výsledky z více zdrojů a aplikují sofistikované algoritmy řazení, které zohledňují důvěryhodnost zdroje, relevanci výsledku, aktuálnost i uživatelský kontext.
Podpora heterogenních zdrojů: Federované systémy zvládají rozmanité datové formáty, schémata, dotazovací jazyky a přístupové protokoly, včetně relačních databází, dokumentových úložišť, znalostních grafů, API a nestrukturovaných textových repozitářů.
Integrace v reálném čase: Na rozdíl od dávkových datových skladů poskytuje federované vyhledávání téměř okamžitý přístup k aktuálním informacím ze všech zapojených zdrojů a zajišťuje čerstvost i přesnost výsledků.
Sémantické porozumění: Moderní federované AI vyhledávání využívá zpracování přirozeného jazyka a sémantickou analýzu k pochopení záměru dotazu nad rámec klíčových slov, což umožňuje přesnější výběr zdrojů i interpretaci výsledků.
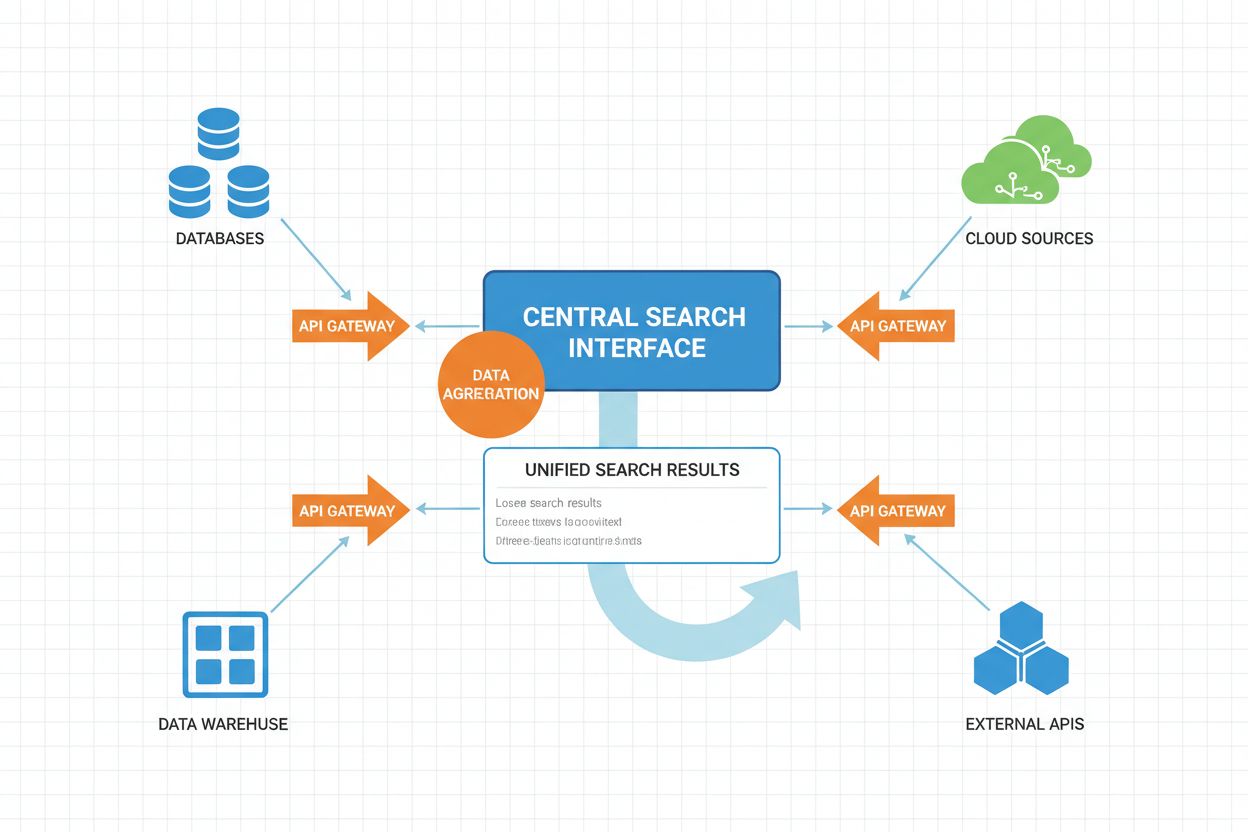
Provozní pracovní tok federovaného AI vyhledávání zahrnuje více koordinovaných fází, z nichž každá je vylepšena umělou inteligencí pro optimalizaci výkonu i kvality výsledků.
| Fáze | Proces | AI komponenta | Výstup |
|---|---|---|---|
| Analýza dotazu | Uživatelův dotaz je parsován a analyzován na záměr, entity a kontext | NLP, rozpoznávání entit, klasifikace záměru | Strukturovaná reprezentace dotazu, identifikované entity, signály záměru |
| Výběr zdrojů | Systém určí, které datové zdroje jsou pro dotaz nejrelevantnější | Modely strojového učení pro řazení, klasifikátory relevance zdrojů | Prioritizovaný seznam cílových zdrojů, skóre důvěry |
| Překlad dotazu | Dotaz je převeden do formátů a jazyků specifických pro daný zdroj | Mapování schémat, modely překladu dotazů, sémantické párování | Dotazy specifické pro zdroj (SQL, SPARQL, API volání, atd.) |
| Distribuované provedení | Dotazy jsou spuštěny paralelně napříč vybranými zdroji | Vyvažování zátěže, správa timeoutů, paralelní zpracování | Surové výsledky z každého zdroje, metadata provedení |
| Normalizace výsledků | Výsledky z různých zdrojů jsou převedeny do jednotného formátu | Zarovnání schémat, převod datových typů, standardizace formátů | Normalizovaná sada výsledků s konzistentní strukturou |
| Sémantické obohacení | Výsledky jsou doplněny o další kontext a metadata | Propojování entit, sémantické označkování, integrace znalostních grafů | Obohacení výsledků sémantickými anotacemi |
| Řazení a deduplikace | Výsledky jsou seřazeny podle relevance a duplicity odstraněny | Modely pro řazení, detekce podobnosti, skórování relevance | Deduplicitní, seřazený seznam výsledků |
| Personalizace | Výsledky jsou přizpůsobeny dle profilu a preferencí uživatele | Kolaborativní filtrování, modelování uživatele, vnímání kontextu | Personalizované pořadí výsledků |
| Prezentace | Výsledky jsou naformátovány pro uživatelskou spotřebu | Generování přirozeného jazyka, sumarizace výsledků | Uživatelsky přívětivé zobrazení výsledků |
Workflow je založen na paralelním provedení, kdy je více zdrojů dotazováno současně místo sekvenčního zpracování. Tato paralelizace výrazně snižuje celkovou latenci dotazu i přes režii koordinace více zdrojů. Pokročilé federované systémy implementují adaptivní plánování dotazů, kdy se systém učí z historických vzorců dotazů a průběžně optimalizuje výběr zdrojů i strategie provedení.
Timeouty a záložní mechanismy jsou klíčové pro spolehlivost systému. Pokud zdroj reaguje pomalu nebo selže, systém může čekat s adaptivními timeouty, nebo pokračovat s dostupnými výsledky, čímž elegantně snižuje úplnost výsledku místo úplného selhání.
Federované AI vyhledávací systémy lze kategorizovat podle několika hledisek:
Podle architektonického modelu:
Podle typu datových zdrojů:
Podle rozsahu a škály:
Podle úrovně inteligence:
Autonomie a správa dat: Organizace si zachovávají kontrolu nad svými daty a nemusí přesouvat citlivé informace do centrálních úložišť. To zachovává politiky správy dat, požadavky na soulad a bezpečnostní opatření přímo na úrovni zdrojů.
Škálovatelnost bez konsolidace: Federované systémy lze škálovat přidáváním nových zdrojů bez migrace dat nebo restrukturalizace skladů. Organizace tak mohou postupně integrovat nové datové zdroje podle vývoje podnikových potřeb.
Přístup k informacím v reálném čase: Přímým dotazováním zdrojů poskytuje federované vyhledávání aktuální informace bez zpoždění typického pro dávkové sklady dat. To má zásadní význam pro časově citlivé aplikace vyžadující nejnovější data.
Úspora nákladů: Odpadá nutnost budovat a udržovat rozsáhlé centralizované datové sklady, což snižuje infrastrukturní i provozní náklady. Organizace se vyhnou duplikaci dat, nadbytečnému úložišti i složitým ETL procesům.
Snížení redundance dat: Na rozdíl od skladování dat, kdy dochází k duplikaci napříč systémy, federované vyhledávání zachovává jednotné zdroje pravdy a snižuje tak nároky na úložiště i riziko nekonzistence.
Flexibilita a přizpůsobivost: Nové zdroje lze integrovat bez úprav stávající infrastruktury nebo reindexace. Tato flexibilita umožňuje rychle reagovat na změny v požadavcích podnikání.
Vyšší kvalita dat: Přímým dotazováním autoritativních zdrojů snižuje federované vyhledávání zastaralost dat a problémy s nekonzistencí, které vznikají při periodické synchronizaci ve skladech.
Zvýšená bezpečnost: Citlivá data nikdy neopouštějí původní umístění, což snižuje riziko neautorizovaného přístupu či úniku. Přístupová práva zůstávají pod správou zdroje, nikoli centrálního systému.
Podpora heterogenních zdrojů: Federované systémy zvládají různé technologie, formáty a protokoly bez nutnosti standardizace nebo migrace na jednotné platformy.
Inteligentní syntéza výsledků: AI poháněné řazení a agregace produkují kvalitnější výsledky než pouhé sloučení, neboť zohledňují důvěryhodnost zdroje, relevanci výsledků i kontext uživatele.
Moderní federované AI vyhledávače se skládají z několika propojených technických komponent, které společně zajišťují integrované vyhledávání.
Engine pro zpracování dotazů: Centrální komponenta přijímající uživatelské dotazy a řídící pracovní tok federovaného vyhledávání. Zahrnuje parsování dotazů, sémantickou analýzu a rozpoznávání záměru. Pokročilé implementace využívají jazykové modely typu transformer pro pochopení složitých dotazů a implicitního záměru uživatele.
Registr zdrojů a správa metadat: Udržuje metadata o dostupných zdrojích včetně informací o schématu, charakteristice obsahu, frekvenci aktualizací, dostupnosti a výkonnostních metrikách. Tento registr umožňuje inteligentní výběr zdrojů a optimalizaci dotazů. Modely strojového učení analyzují historické vzory dotazů a předpovídají relevanci zdrojů pro nové dotazy.
Modul pro inteligentní výběr zdrojů: Používá klasifikátory strojového učení k určení, které zdroje s nejvyšší pravděpodobností obsahují relevantní informace pro daný dotaz. Zohledňuje pokrytí obsahu, úspěšnost minulých dotazů, dostupnost zdrojů i odhadovanou dobu odezvy. Pokročilé systémy využívají reinforcement learning pro průběžnou optimalizaci strategie výběru zdrojů.
Vrstva pro překlad a adaptaci dotazů: Převádí uživatelské dotazy do formátů a jazyků specifických pro jednotlivé zdroje – včetně generování SQL pro relační databáze, SPARQL pro znalostní grafy, REST API volání pro webové služby a přirozených jazykových dotazů pro nestrukturované texty. Sémantické mapování zajišťuje zachování záměru dotazu napříč různými jazyky a datovými modely.
Koordinátor distribuovaného provedení: Řídí paralelní provádění dotazů napříč zdroji, spravuje timeouty, vyvažuje zátěž a obnovuje stav po selhání. Implementuje adaptivní strategie timeoutů podle vzorců odezvy zdrojů a zatížení systému.
Engine pro normalizaci výsledků: Převádí výsledky z heterogenních zdrojů do jednotného formátu pro agregaci a řazení. Zahrnuje zarovnání schémat, převod datových typů a standardizaci formátů. Řeší chybějící pole, konfliktní datové typy i strukturální rozdíly mezi zdroji.
Modul pro sémantické obohacení: Obohacuje výsledky o další kontext a sémantické informace – včetně propojování entit se znalostními bázemi, označkování na základě ontologií a extrakce vztahů z nestrukturovaných textů. Tato obohacení zlepšují přesnost řazení a srozumitelnost výsledků.
Model pro učení řazení (Learning-to-Rank): Model strojového učení trénovaný na historických dvojicích dotaz-výsledek pro predikci relevance. Zohledňuje stovky atributů včetně důvěryhodnosti zdroje, aktuálnosti obsahu, souladu s uživatelským profilem a sémantické podobnosti mezi dotazem a výsledkem. Moderní implementace využívají gradient boosting nebo neuronové sítě.
Engine pro deduplikaci: Identifikuje a odstraňuje duplicitní nebo téměř duplicitní výsledky z různých zdrojů. Používá metriky podobnosti – od přesné shody až po fuzzy string matching a sémantickou podobnost založenou na embeddingu.
Engine pro personalizaci: Přizpůsobuje pořadí výsledků na základě uživatelských profilů, historických preferencí a kontextových informací. Implementuje kolaborativní filtrování a doporučovací techniky pro zvýšení relevance pro jednotlivé uživatele.
Vrstva pro ukládání do mezipaměti a optimalizaci: Implementuje inteligentní caching pro snížení zbytečných dotazů na zdroje – včetně ukládání výsledků dotazů, metadat o zdrojích i naučených vzorců dotazů pro predikci budoucích potřeb.
Modul pro monitoring a analytiku: Sleduje výkonnost systému, spolehlivost zdrojů, vzorce dotazů a metriky kvality výsledků. Tato data slouží k optimalizaci a průběžnému zlepšování systému.
Zdravotnictví a lékařský výzkum: Federované vyhledávání integruje záznamy pacientů napříč nemocnicemi, výzkumnými databázemi, registry klinických studií i repozitáři lékařské literatury. Lékaři mohou vyhledávat kompletní zdravotní historii napříč poskytovateli bez centralizace citlivých dat. Výzkumníci přistupují k distribuovaným klinickým datům pro epidemiologické studie při zachování souladu s HIPAA a ochranou soukromí pacientů.
Finanční služby: Banky a investiční firmy používají federované vyhledávání pro dotazování na obchodní data, tržní informace, regulatorní databáze i interní záznamy transakcí zároveň. To umožňuje analýzu rizik, monitoring souladu a tržní analýzy v reálném čase bez konsolidace citlivých finančních dat.
Právo a compliance: Advokátní kanceláře a právní oddělení firem hledají napříč databázemi judikatury, regulatorními repozitáři, interními systémy správy dokumentů a databázemi smluv. Federované vyhledávání umožňuje komplexní právní rešerši při zachování mlčenlivosti a důvěrnosti dokumentů.
E-commerce a maloobchod: Online prodejci integrují katalogy produktů napříč sklady, systémy dodavatelů a tržišti. Federované vyhledávání umožňuje jednotné objevování produktů a zároveň ponechává dodavatelům nezávislost v řízení zásob i cenové politiky.
Státní správa a veřejná správa: Úřady vyhledávají napříč distribuovanými databázemi, jako jsou sčítací data, daňové záznamy, systémy povolení a veřejné registry bez centralizace citlivých informací o občanech. To umožňuje komplexní veřejné služby při zachování bezpečnosti a soukromí dat.
Výroba a dodavatelské řetězce: Výrobci integrují databáze dodavatelů, skladové systémy, záznamy o výrobě a logistické platformy. Federované vyhledávání zajišťuje přehled o celém dodavatelském řetězci při zachování nezávislosti systémů i proprietárních informací partnerů.
Vzdělávání a výzkum: Univerzity vyhledávají napříč institucionálními repozitáři, knihovními systémy, výzkumnými databázemi a open-access publikacemi. Federované vyhledávání umožňuje komplexní akademické rešerše při respektování autonomie institucí a práv k duševnímu vlastnictví.
Telekomunikace: Poskytovatelé telekomunikačních služeb vyhledávají napříč zákaznickými databázemi, záznamy o síťové infrastruktuře, fakturačními systémy a katalogy služeb. Federované vyhledávání umožňuje sjednocenou zákaznickou podporu při zachování oddělených systémů pro různé služby a regiony.
Energetika a utility: Energetické společnosti vyhledávají napříč zařízeními na výrobu energie, distribučními sítěmi, zákaznickými databázemi a systémy pro compliance. Federované vyhledávání poskytuje provozní přehled při zachování nezávislosti regionálních operátorů.
Média a vydavatelství: Mediální organizace vyhledávají napříč repozitáři obsahu, archivy, systémy správy práv a distribučními platformami. Federované vyhledávání umožňuje komplexní objevování obsahu při zachování vlastnictví a licenčních omezení.
Heterogenita zdrojů a složitost integrace: Integrace rozmanitých zdrojů s různými schématy, dotazovacími jazyky a přístupovými protokoly je náročná z hlediska inženýrství. Mapování schémat a sémantické zarovnání jsou obtížné, zvlášť pokud různé zdroje reprezentují stejné koncepty odlišně.
Latence dotazů a výkon: Federované vyhledávání zahrnuje dotazování na více zdrojů, což zvyšuje latenci oproti centralizovaným systémům. Pomalé nebo nereagující zdroje mohou zhoršit celkový výkon dotazů. Správu timeoutů je třeba pečlivě ladit pro rovnováhu mezi úplností a rychlostí.
Spolehlivost a dostupnost zdrojů: Federované systémy závisejí na externích zdrojích, že budou dostupné a reagující. Síťové chyby, výpadky zdrojů či zhoršený výkon mají přímý dopad na kvalitu vyhledávání. Je nutné zajistit elegantní degradaci při selhání zdrojů.
Kvalita výsledků a přesnost řazení: Agregace výsledků ze zdrojů s různou kvalitou, pokrytím a kritérii relevance je náročná. Modely řazení musí zohledňovat rozdílnou důvěryhodnost zdrojů a vyvarovat se upřednostňování konkrétních zdrojů.
Aktuálnost a konzistence dat: Federované systémy mají přístup k aktuálním datům zdrojů, ale jednotlivé zdroje se mohou lišit frekvencí aktualizací i garancemi konzistence. Řešení rozporů mezi zdroji vyžaduje pokročilé strategie.
Škálovatelnost: S rostoucím počtem zdrojů narůstá režie koordinace dotazů. Výběr relevantních zdrojů z tisíců možností je výpočetně náročný. Paralelní provádění napříč mnoha zdroji vyžaduje robustní infrastrukturu.
Bezpečnost a řízení přístupu: Federované systémy musí prosazovat přístupová práva na úrovni zdrojů při poskytování jednotného rozhraní vyhledávání. Zajištění, že uživatelé uvidí pouze autorizované informace napříč více zdroji, je složité, zvlášť v prostředí s více nájemci.
Ochrana soukromí a dat: Federované vyhledávání musí být v souladu s nařízeními o ochraně osobních údajů (GDPR, CCPA atd.). Je nutné zabránit úniku citlivých dat prostřednictvím agregace výsledků nebo analýzy metadat.
Objevování a správa zdrojů: Identifikace a katalogizace dostupných zdrojů, udržování přesných metadat a správa životního cyklu zdrojů (přidávání, odebrání, aktualizace) vyžaduje průběžnou operativní péči.
Sémantická interoperabilita: Skutečně sémantická interoperabilita napříč zdroji s různými ontologiemi a datovými modely je stále výzvou. Automatizované mapování schémat a rozpoznávání entit má své limity.
Náklady na koordinaci: I když federované vyhledávání eliminuje náklady na konsolidaci dat, přináší režii koordinace. Správa distribuovaného provádění, řešení selhání a optimalizace směrování dotazů vyžaduje sofistikovanou infrastrukturu.
Omezená standardizace: Nedostatek univerzálních standardů pro federované vyhledávací protokoly a rozhraní ztěžuje integraci a zvyšuje riziko závislosti na dodavateli.
Federovaný AI vyhledávač vs. datové sklady: Datové sklady konsolidují data z více zdrojů do centraliz
Tradiční centralizované vyhledávání konsoliduje všechna data do jednoho indexovaného úložiště, což vyžaduje migraci dat a zavádí zpoždění. Federované AI vyhledávání se v reálném čase dotazuje přímo na více nezávislých zdrojů bez přesunu či duplikace dat, čímž zachovává autonomii zdrojů a zároveň poskytuje jednotný přístup. Díky tomu je federované vyhledávání ideální pro organizace s distribuovanými datovými zdroji a přísnými požadavky na správu dat.
Federované AI vyhledávání ponechává data na jejich původním místě a respektuje přístupová oprávnění i bezpečnostní politiky jednotlivých zdrojů. Uživatelé mají přístup pouze k informacím, ke kterým jsou oprávněni, a citlivá data nikdy neopouštějí svůj původní systém. Tento přístup zjednodušuje soulad s předpisy, jako je GDPR a HIPAA, tím, že eliminuje rizika spojená s centralizací citlivých informací.
Mezi klíčové výzvy patří správa heterogenních datových zdrojů s různými schématy a formáty, řešení latence dotazů z více zdrojů, zajištění konzistentního řazení výsledků napříč zdroji a udržení spolehlivosti systému v případě nedostupnosti zdrojů. Organizace musí také investovat do robustní správy metadat a inteligentních algoritmů pro výběr zdrojů, aby optimalizovaly výkon.
Ano, federované AI vyhledávání lze škálovat přidáváním nových zdrojů bez nutnosti migrace dat nebo restrukturalizace datových skladů. S rostoucím počtem zdrojů však narůstá režie koordinace dotazů. Moderní systémy používají strojové učení pro inteligentní výběr zdrojů a implementují strategie ukládání do mezipaměti, aby udržely výkon i ve velkém měřítku.
Datový sklad konsoliduje data do centralizovaného úložiště, což umožňuje rychlé dotazy, ale vyžaduje značné úsilí na ETL a zavádí zpoždění dat. Federované vyhledávání dotazuje zdroje přímo, poskytuje přístup v reálném čase, ale s vyšší latencí dotazů. Skladování je vhodné pro historickou analýzu a reportování, zatímco federované vyhledávání vyniká při vyhledávání aktuálních informací v distribuovaných zdrojích.
Z federovaného vyhledávání výrazně těží zdravotnictví, finance, e-commerce, státní správa a výzkumné organizace. Zdravotnictví jej využívá ke sjednocení záznamů pacientů napříč poskytovateli, finance pro soulad s předpisy a řízení rizik, e-commerce pro jednotné vyhledávání produktů a výzkumné organizace pro vyhledávání v distribuovaných akademických databázích.
AI zlepšuje federované vyhledávání díky zpracování přirozeného jazyka pro pochopení dotazů, strojovému učení pro inteligentní výběr zdrojů, sémantické analýze pro lepší řazení výsledků a automatické deduplikaci. AI modely se učí ze vzorců dotazů a průběžně optimalizují výběr zdrojů i agregaci výsledků, čímž zlepšují výkon systému v čase.
Sémantické porozumění umožňuje federovaným systémům chápat záměr dotazu nad rámec prostého shody klíčových slov, přesněji identifikovat relevantní zdroje a řadit výsledky na základě významu a nikoli jen překryvu klíčových slov. Zahrnuje to rozpoznávání entit, extrakci vztahů a integraci znalostních grafů, což vede k relevantnějším a kontextově vhodným výsledkům vyhledávání.
AmICited sleduje, jak AI systémy jako ChatGPT, Perplexity a Google AI Overviews citují a zmiňují vaši značku. Získejte přehled o vaší viditelnosti v AI a optimalizujte svou přítomnost v AI-generovaných odpovědích.
Zjistěte, co jsou AI vyhledávače, jak se liší od tradičního vyhledávání a jak ovlivňují viditelnost značek. Prozkoumejte platformy jako Perplexity, ChatGPT, Goo...

Zjistěte, jak fungují AI vyhledávače jako ChatGPT, Perplexity a Google AI Overviews. Objevte LLM, RAG, sémantické vyhledávání a mechanismy pro vyhledávání v reá...
Zjistěte, jak implementovat FAQ schéma pro AI vyhledávače. Postupný průvodce pokrývající formát JSON-LD, osvědčené postupy, validaci a optimalizaci pro AI platf...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.