
ClaudeBot expliqué : le crawler d’Anthropic et votre contenu
Découvrez comment fonctionne ClaudeBot, en quoi il diffère de Claude-Web et Claude-SearchBot, et comment gérer les crawlers web d’Anthropic sur votre site à l’a...
9 min de lecture

ClaudeBot est le robot d’indexation d’Anthropic utilisé pour collecter des données d’entraînement pour les modèles d’IA Claude. Il explore systématiquement les sites web accessibles au public afin de rassembler du contenu pour l’entraînement des modèles d’apprentissage automatique. Les propriétaires de sites peuvent contrôler l’accès de ClaudeBot via la configuration du fichier robots.txt. Le robot respecte les directives standards du robots.txt, permettant aux sites de bloquer ou d’autoriser ses visites.
ClaudeBot est le robot d’indexation d’Anthropic utilisé pour collecter des données d’entraînement pour les modèles d’IA Claude. Il explore systématiquement les sites web accessibles au public afin de rassembler du contenu pour l’entraînement des modèles d’apprentissage automatique. Les propriétaires de sites peuvent contrôler l’accès de ClaudeBot via la configuration du fichier robots.txt. Le robot respecte les directives standards du robots.txt, permettant aux sites de bloquer ou d’autoriser ses visites.
ClaudeBot est un robot d’indexation web exploité par Anthropic pour télécharger des données d’entraînement destinées à ses grands modèles de langage (LLMs) qui alimentent des produits d’IA comme Claude. Ce robot extracteur de données IA parcourt systématiquement les sites web afin de collecter du contenu spécifiquement pour l’entraînement des modèles d’apprentissage automatique, ce qui le distingue des robots d’indexation des moteurs de recherche traditionnels qui indexent le contenu à des fins de récupération. ClaudeBot peut être identifié par sa chaîne user agent et peut être bloqué ou autorisé via la configuration du fichier robots.txt, donnant ainsi aux propriétaires de sites le contrôle sur l’utilisation de leur contenu dans l’entraînement des modèles IA d’Anthropic.

ClaudeBot fonctionne avec des méthodes systématiques de découverte web, incluant le suivi de liens à partir de sites indexés, le traitement des sitemaps et l’utilisation d’URLs de départ issues de listes de sites disponibles publiquement. Le robot télécharge le contenu des sites pour constituer les jeux de données servant à entraîner les modèles de langage de Claude, collectant ainsi les pages accessibles au public sans requérir d’authentification. À la différence des robots d’indexation de moteurs de recherche qui privilégient l’indexation pour la restitution, les schémas de crawl de ClaudeBot sont généralement opaques : Anthropic dévoile rarement les critères de sélection des sites, la fréquence d’exploration ou les priorités selon les types de contenu.
Le tableau ci-dessous compare ClaudeBot aux autres robots d’Anthropic :
| Nom du robot | Objectif | User Agent | Portée |
|---|---|---|---|
| ClaudeBot | Récupération de citations chat et données d’entraînement | ClaudeBot/1.0 | Crawl web général pour l’entraînement des modèles |
| anthropic-ai | Collecte de données d’entraînement à grande échelle | anthropic-ai | Compilation massive de jeux de données |
| Claude-Web | Crawl web focalisé pour les fonctionnalités Claude | Claude-Web | Recherche web et informations en temps réel |
ClaudeBot fonctionne de manière similaire aux autres grands robots d’entraînement IA comme GPTBot (OpenAI) et PerplexityBot (Perplexity), mais présente des différences notables en termes de portée et de méthodologie. Alors que GPTBot se concentre sur les besoins d’entraînement d’OpenAI et que PerplexityBot sert à la fois la recherche et l’entraînement, ClaudeBot cible spécifiquement le contenu destiné à l’entraînement du modèle de Claude. D’après les données de Dark Visitors, environ 18 % des 1 000 plus grands sites mondiaux bloquent activement ClaudeBot, ce qui montre la préoccupation des éditeurs vis-à-vis de ses pratiques de collecte de données. La principale différence réside dans la façon dont chaque société priorise la collecte : la démarche d’Anthropic privilégie un crawl systématique et large pour l’entraînement, tandis que les robots axés recherche équilibrent indexation et génération de trafic référent.
Les propriétaires de site peuvent identifier les visites de ClaudeBot en surveillant les logs serveur à la recherche de la chaîne user agent : Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com). ClaudeBot provient généralement de plages IP des États-Unis, et ses visites peuvent être suivies par analyse des logs ou via des outils de monitoring dédiés. La mise en place de solutions d’analytics en temps réel permet de visualiser la fréquence et les schémas de crawl de ClaudeBot.
Voici un exemple de log serveur montrant ClaudeBot :
203.0.113.45 - - [03/Jan/2025:09:15:32 +0000] "GET /blog/article-title HTTP/1.1" 200 5432 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)"
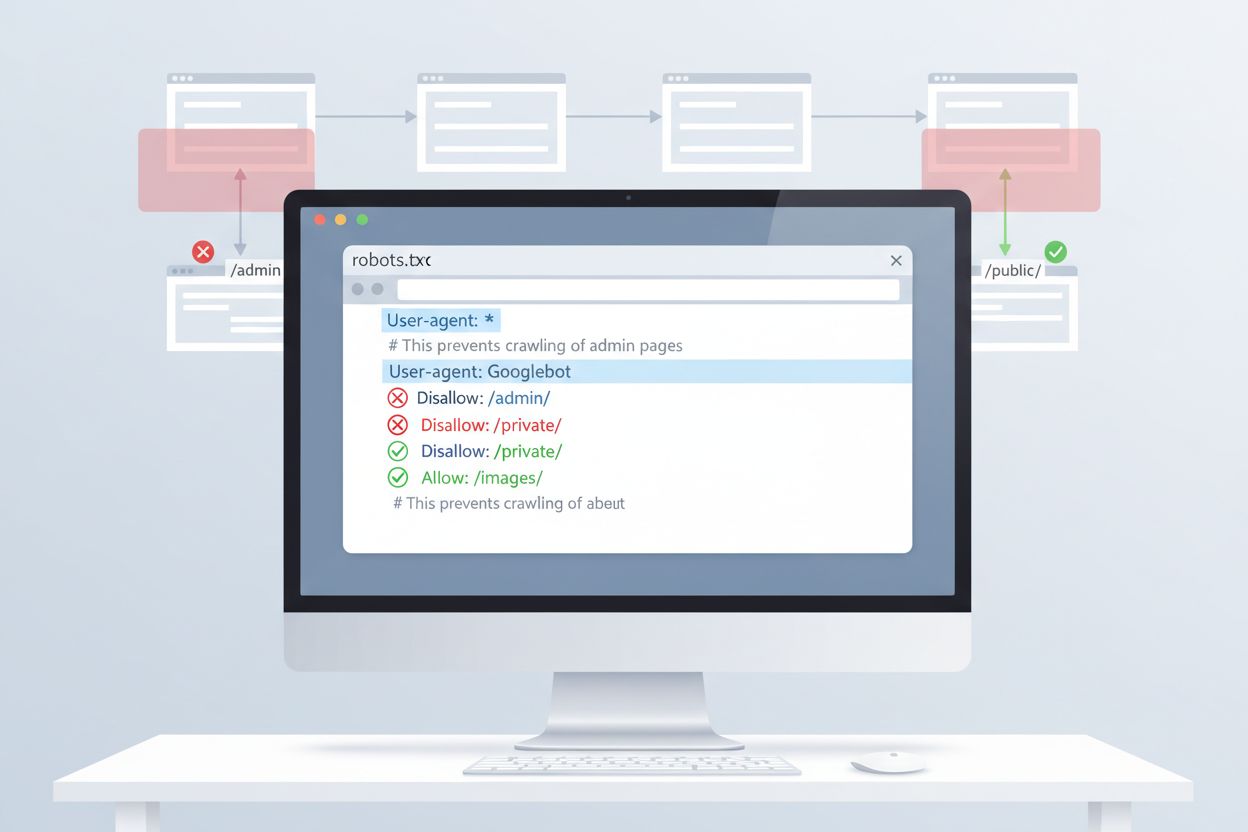
La méthode la plus simple pour contrôler l’accès de ClaudeBot est la configuration du fichier robots.txt à la racine de votre site. Ce fichier indique aux robots les parties de votre site auxquelles ils peuvent accéder, et ClaudeBot d’Anthropic respecte ces directives. Pour bloquer toute l’activité de ClaudeBot, ajoutez les règles suivantes à votre robots.txt :
User-agent: ClaudeBot
Disallow: /
Pour un blocage sélectif empêchant ClaudeBot d’accéder à certains répertoires tout en autorisant l’exploration d’autres contenus, utilisez :
User-agent: ClaudeBot
Disallow: /private/
Disallow: /admin/
Allow: /public/
Si vous souhaitez bloquer tous les robots d’Anthropic (y compris anthropic-ai et Claude-Web), ajoutez une règle distincte pour chacun :
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Claude-Web
Disallow: /
Le robots.txt constitue une première ligne de défense, mais son application demeure volontaire. Pour les éditeurs nécessitant un contrôle renforcé, plusieurs méthodes complémentaires existent :
Ces méthodes requièrent davantage de compétences techniques que la configuration robots.txt mais assurent un blocage plus strict en cas de non-respect des directives.
Bloquer ClaudeBot a un impact direct minimal sur le référencement SEO classique, car les robots d’entraînement ne participent pas à l’indexation des moteurs de recherche : Google, Bing et autres utilisent leurs propres robots (Googlebot, Bingbot) qui fonctionnent indépendamment. Toutefois, bloquer ClaudeBot peut réduire la représentation de votre contenu dans les réponses générées par Claude, ce qui peut impacter sa découverte via les interfaces de recherche et de chat IA à l’avenir. La décision stratégique de bloquer ou d’autoriser ClaudeBot dépend de votre modèle de monétisation du contenu : si vos revenus reposent sur le trafic direct et les impressions publicitaires, le blocage évite d’intégrer votre contenu dans des jeux d’entraînement pouvant réduire le nombre de visiteurs. À l’inverse, autoriser ClaudeBot peut accroître votre visibilité dans les réponses de Claude, générant potentiellement du trafic référent via les utilisateurs du chat IA.
Une gestion efficace de ClaudeBot nécessite une surveillance continue et des tests de configuration. Utilisez des outils comme le testeur robots.txt de Google Search Console, l’outil de test robots.txt de Merkle, ou des plateformes spécialisées comme Dark Visitors pour vérifier que vos règles de blocage fonctionnent comme prévu. Contrôlez régulièrement vos logs serveur afin de confirmer que ClaudeBot respecte vos directives et surveillez tout changement de comportement d’exploration. Comme l’écosystème des robots IA évolue rapidement, avec de nouveaux robots détectés régulièrement, un audit trimestriel de votre configuration robots.txt garantit la prise en compte des robots émergents et le maintien d’une stratégie de protection efficace. Tester votre configuration avant déploiement permet d’éviter de bloquer accidentellement les moteurs de recherche légitimes ou d’autres robots importants.
ClaudeBot est le robot d’indexation d’Anthropic qui visite systématiquement les sites web afin de collecter des données d’entraînement pour les modèles d’IA Claude. Il découvre votre site en suivant des liens, en traitant les sitemaps ou via des listes publiques de sites web. Le robot collecte le contenu accessible au public pour améliorer les capacités du modèle de langage Claude.
Vous pouvez bloquer ClaudeBot en ajoutant une règle robots.txt à la racine de votre site. Il suffit d’ajouter 'User-agent: ClaudeBot' suivi de 'Disallow: /' pour empêcher tout accès, ou de spécifier certains chemins à bloquer de façon sélective. ClaudeBot d’Anthropic respecte les directives du fichier robots.txt.
Non, bloquer ClaudeBot n’aura pas d’impact sur votre classement Google ou Bing. Les robots d’entraînement comme ClaudeBot opèrent indépendamment des moteurs de recherche traditionnels. Seul le blocage de Googlebot ou Bingbot affecterait votre performance SEO.
Anthropic exploite trois robots principaux : ClaudeBot (pour la récupération de citations et l’entraînement général), anthropic-ai (collecte massive de données d’entraînement), et Claude-Web (robot focalisé sur le web pour des fonctionnalités temps réel). Chacun a un rôle distinct dans l’infrastructure IA d’Anthropic.
Vérifiez les logs de votre serveur pour la chaîne user agent de ClaudeBot : 'Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)'. Vous pouvez aussi utiliser des outils de monitoring comme Dark Visitors ou mettre en place de l’analytics pour suivre en temps réel les visites de ClaudeBot.
Oui, ClaudeBot respecte les directives du fichier robots.txt selon la documentation officielle d’Anthropic. Cependant, comme toutes les règles robots.txt, le respect est volontaire. Pour un blocage renforcé, vous pouvez appliquer des restrictions au niveau du serveur, du filtrage IP ou via un WAF.
ClaudeBot peut consommer une bande passante significative selon la taille et le volume de contenu de votre site. Les robots d’IA peuvent crawler plus intensivement que les moteurs de recherche classiques. Surveillez vos logs pour évaluer l’impact et décider de bloquer ou non le robot.
La décision dépend de votre modèle économique. Bloquez ClaudeBot si vous êtes préoccupé par l’attribution du contenu, la rémunération ou l’utilisation de votre travail dans des systèmes d’IA. Autorisez-le si vous souhaitez que votre contenu apparaisse dans les réponses et résultats de recherche IA de Claude. Prenez en compte votre stratégie de monétisation du trafic pour décider.
Suivez ClaudeBot et d’autres robots IA qui accèdent à votre contenu. Obtenez des informations sur les systèmes d’IA qui mentionnent votre marque et sur l’utilisation de votre contenu dans les réponses générées par l’IA.
Découvrez comment fonctionne ClaudeBot, en quoi il diffère de Claude-Web et Claude-SearchBot, et comment gérer les crawlers web d’Anthropic sur votre site à l’a...
Claude est l’assistant IA avancé d’Anthropic, propulsé par l’IA constitutionnelle. Découvrez le fonctionnement de Claude, ses principales fonctionnalités, ses m...

Découvrez ce qu'est CCBot, son fonctionnement et comment le bloquer. Comprenez son rôle dans l'entraînement de l'IA, les outils de surveillance et les bonnes pr...
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.