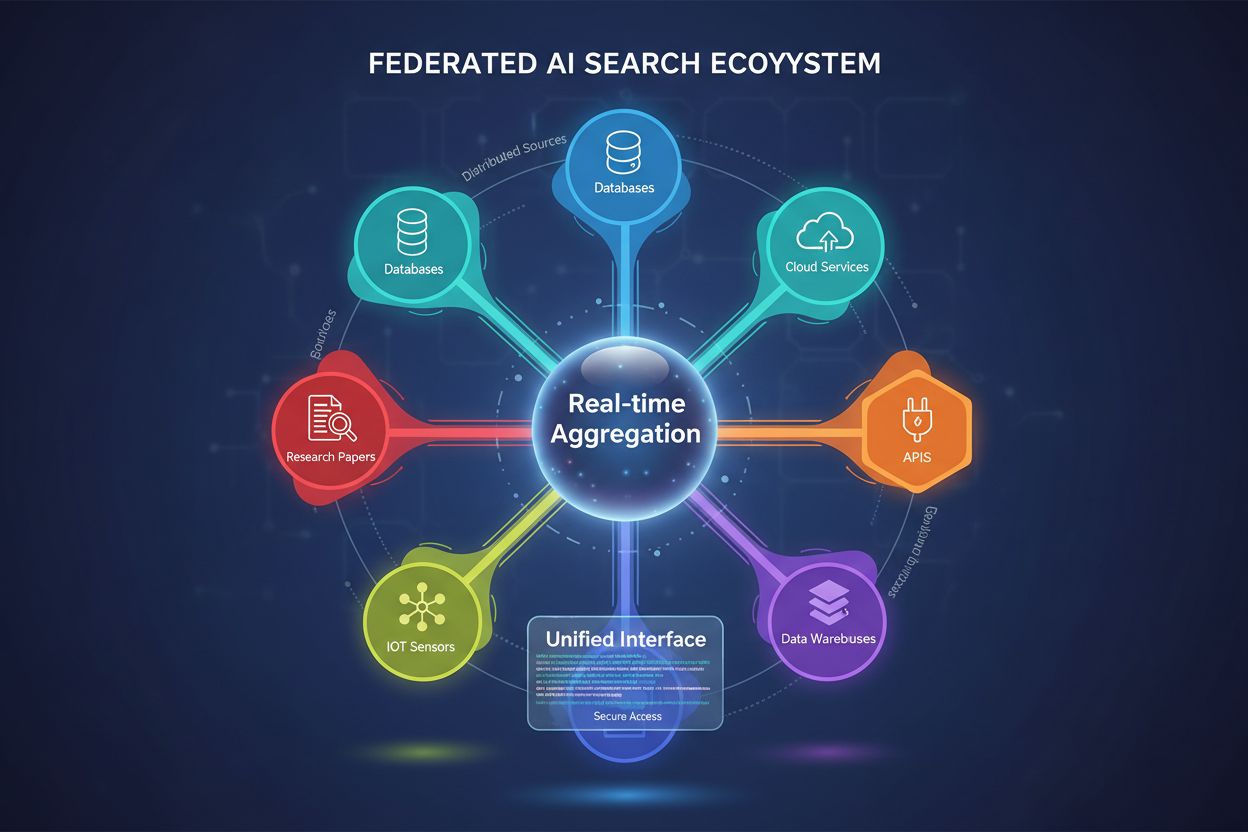
La recherche fédérée par IA est un système qui interroge simultanément plusieurs sources de données indépendantes à l’aide d’une requête unique et agrège les résultats en temps réel sans déplacer ni dupliquer les données. Elle permet aux organisations d’accéder à des informations distribuées à travers des bases de données, API et services cloud tout en maintenant la sécurité et la conformité des données. Contrairement aux moteurs de recherche centralisés traditionnels, les systèmes fédérés préservent l’autonomie des données tout en offrant une découverte unifiée de l’information. Cette approche est particulièrement précieuse pour les entreprises gérant des sources de données variées entre différents départements, zones géographiques ou organisations.
Recherche fédérée par IA
La recherche fédérée par IA est un système qui interroge simultanément plusieurs sources de données indépendantes à l’aide d’une requête unique et agrège les résultats en temps réel sans déplacer ni dupliquer les données. Elle permet aux organisations d’accéder à des informations distribuées à travers des bases de données, API et services cloud tout en maintenant la sécurité et la conformité des données. Contrairement aux moteurs de recherche centralisés traditionnels, les systèmes fédérés préservent l’autonomie des données tout en offrant une découverte unifiée de l’information. Cette approche est particulièrement précieuse pour les entreprises gérant des sources de données variées entre différents départements, zones géographiques ou organisations.
Définition de base & caractéristiques clés
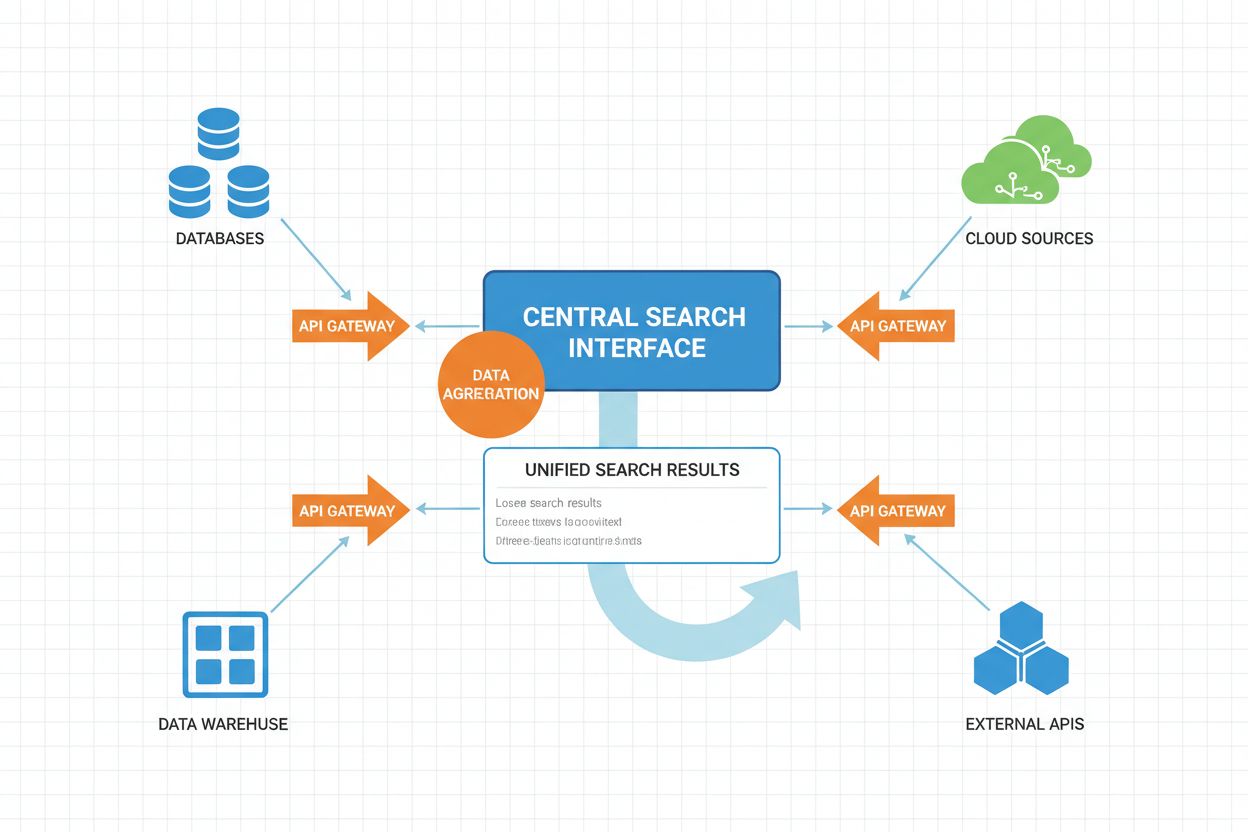
La recherche fédérée par IA est un système de recherche d’information distribué qui interroge simultanément plusieurs sources de données hétérogènes et agrège intelligemment les résultats à l’aide de techniques d’intelligence artificielle. Contrairement aux moteurs de recherche centralisés traditionnels qui maintiennent un référentiel indexé unique, la recherche fédérée par IA opère sur des réseaux décentralisés de bases de données, bases de connaissances et systèmes d’information indépendants, sans nécessiter de consolidation ou d’indexation centralisée des données.
Le principe fondamental de la recherche fédérée par IA est l’interrogation indépendante des sources, où une requête utilisateur unique est intelligemment routée vers les sources pertinentes, traitée indépendamment par chaque source, puis synthétisée en un ensemble de résultats unifié. Cette approche préserve l’autonomie des données tout en permettant une découverte complète de l’information à travers des frontières organisationnelles et techniques.
Les caractéristiques clés des systèmes de recherche fédérée par IA incluent :
Architecture distribuée : Les données restent à leur emplacement d’origine sur plusieurs référentiels, éliminant le besoin de migration ou de stockage centralisé. Chaque source maintient son propre index, ses contrôles d’accès et ses mécanismes de mise à jour de façon indépendante.
Routage intelligent des requêtes : Les algorithmes d’IA analysent les requêtes entrantes pour déterminer quelles sources sont les plus susceptibles de contenir des informations pertinentes, optimisant ainsi l’efficacité de la recherche et réduisant les requêtes inutiles vers des bases non pertinentes.
Agrégation et classement des résultats : Les modèles d’apprentissage automatique synthétisent les résultats de multiples sources, appliquant des algorithmes de classement sophistiqués qui prennent en compte la crédibilité de la source, la pertinence des résultats, leur fraîcheur et le contexte utilisateur.
Prise en charge de sources hétérogènes : Les systèmes fédérés gèrent divers formats de données, schémas, langages de requête et protocoles d’accès, notamment bases de données relationnelles, magasins de documents, graphes de connaissances, APIs et référentiels de textes non structurés.
Intégration en temps réel : Contrairement aux approches d’entreposage de données par lots, la recherche fédérée offre un accès quasi temps réel à l’information actuelle sur l’ensemble des sources connectées, garantissant la fraîcheur et l’exactitude des résultats.
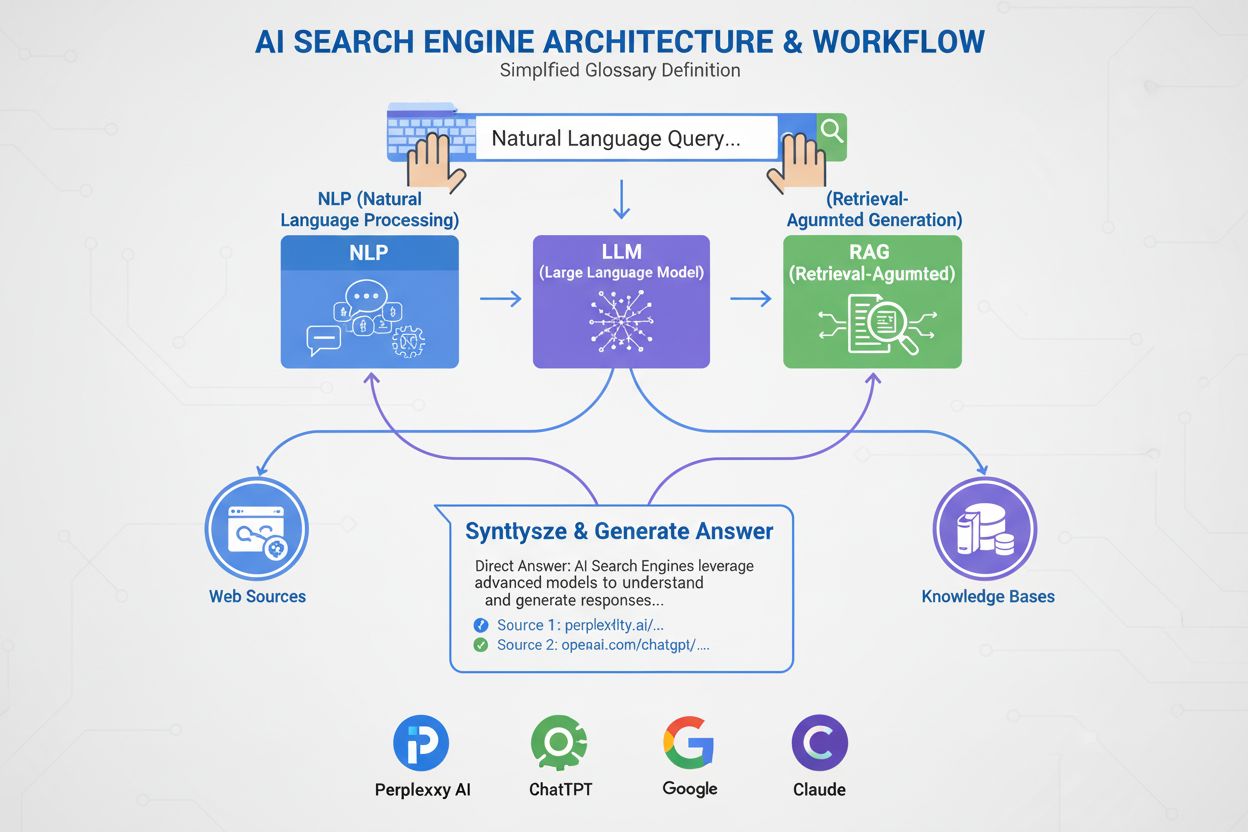
Compréhension sémantique : La recherche fédérée par IA moderne exploite le traitement du langage naturel et l’analyse sémantique pour comprendre l’intention des requêtes au-delà de la simple correspondance de mots-clés, permettant ainsi une sélection de sources et une interprétation des résultats plus précises.
Fonctionnement de la recherche fédérée par IA
Le flux opérationnel de la recherche fédérée par IA comprend plusieurs étapes coordonnées, chacune étant améliorée par l’intelligence artificielle pour optimiser la performance et la qualité des résultats.
Étape
Processus
Composant IA
Sortie
Analyse de la requête
La requête utilisateur est analysée pour détecter l’intention, les entités et le contexte
Représentation structurée de la requête, entités identifiées, signaux d’intention
Sélection des sources
Le système détermine quelles sources sont les plus pertinentes pour la requête
Modèles de classement par apprentissage automatique, Classifieurs de pertinence de sources
Liste priorisée des sources cibles, scores de confiance
Traduction de la requête
La requête est traduite dans les formats et langages propres à chaque source
Mappage de schéma, Modèles de traduction de requêtes, Appariement sémantique
Requêtes spécifiques aux sources (SQL, SPARQL, appels API, etc.)
Exécution distribuée
Les requêtes sont exécutées en parallèle sur les sources sélectionnées
Répartition de charge, Gestion des délais, Traitement parallèle
Résultats bruts de chaque source, métadonnées d’exécution
Normalisation des résultats
Les résultats de différentes sources sont convertis dans un format commun
Alignement de schéma, Conversion de types de données, Standardisation de format
Ensemble de résultats normalisés à structure cohérente
Enrichissement sémantique
Les résultats sont améliorés avec du contexte et des métadonnées supplémentaires
Liage d’entités, Tagging sémantique, Intégration de graphes de connaissances
Résultats enrichis avec annotations sémantiques
Classement et déduplication
Les résultats sont classés par pertinence et les doublons éliminés
Modèles de classement, Détection de similarité, Scoring de pertinence
Liste de résultats classée et dédupliquée
Personnalisation
Les résultats sont adaptés selon le profil utilisateur et ses préférences
Filtrage collaboratif, Modélisation utilisateur, Prise en compte du contexte
Ordonnancement personnalisé des résultats
Présentation
Les résultats sont formatés pour la restitution utilisateur
Génération de langage naturel, Résumé de résultats
Affichage des résultats côté utilisateur
Le processus repose sur l’exécution parallèle en son cœur, où plusieurs sources sont interrogées simultanément plutôt que séquentiellement. Cette parallélisation réduit considérablement la latence globale malgré la coordination de multiples sources. Les systèmes fédérés avancés mettent en œuvre une planification adaptative des requêtes, où le système apprend des schémas de requêtes passées pour optimiser la sélection des sources et les stratégies d’exécution.
Les mécanismes de délai et de repli sont des composants critiques assurant la fiabilité du système. Lorsqu’une source répond lentement ou échoue, le système peut soit attendre grâce à des délais adaptatifs, soit poursuivre avec les résultats des sources disponibles, dégradant gracieusement la complétude des résultats plutôt que d’échouer complètement.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Les systèmes de recherche fédérée par IA peuvent être catégorisés selon plusieurs axes :
Selon le modèle d’architecture :
Recherche fédérée centralisée : Un coordinateur central gère le routage des requêtes et l’agrégation des résultats, maintenant des métadonnées sur toutes les sources. Cette approche simplifie la coordination mais constitue un point de défaillance unique.
Recherche fédérée décentralisée : Architecture pair-à-pair où chaque nœud peut initier des recherches et coordonner les résultats sans autorité centrale. Cela apporte de la résilience mais augmente la complexité de la coordination.
Recherche fédérée hybride : Combine une coordination centralisée pour les fonctions clés avec des capacités décentralisées pour la redondance et la montée en charge.
Selon le type de source de données :
Fédération de données structurées : Intègre des bases de données relationnelles, entrepôts de données et référentiels structurés aux schémas bien définis.
Fédération de données non structurées : Recherche dans des dépôts de documents, collections textuelles et systèmes de gestion de contenu sans contrainte de schéma rigide.
Fédération de graphes de connaissances : Interroge des graphes de connaissances et réseaux sémantiques distribués, exploitant les ontologies pour une intégration intelligente.
Fédération basée sur les API : Agrège les résultats de plusieurs web services et APIs REST, gérant la diversité des formats de réponse et protocoles.
Fédération de contenus hybrides : Combine plusieurs types de données au sein d’un système fédéré unique.
Selon la portée et l’échelle :
Recherche fédérée d’entreprise : Intègre les sources de données à l’intérieur des frontières organisationnelles, généralement avec des accès contrôlés et des sources connues.
Recherche fédérée à l’échelle du web : Opère sur des sources accessibles via Internet aux caractéristiques inconnues ou variables, nécessitant une gestion robuste des sources peu fiables.
Fédération sectorielle : Ciblée sur des secteurs ou domaines de connaissance spécifiques, avec des types de sources spécialisés et des critères de classement adaptés au domaine.
Selon le niveau d’intelligence :
Fédération basique : Routage simple des requêtes et fusion des résultats sans composant IA sophistiqué.
Fédération intelligente : Intègre l’apprentissage automatique pour la sélection des sources, le classement et l’optimisation de la qualité des résultats.
Fédération sémantique : Exploite graphes de connaissances, ontologies et compréhension sémantique pour une intégration en profondeur de sources hétérogènes.
Fédération autonome : Systèmes auto-optimisants qui apprennent et adaptent en continu la sélection des sources et les stratégies de classement.
Principaux bénéfices & avantages
Autonomie et gouvernance des données : Les organisations conservent le contrôle sur leurs données, éliminant la nécessité de transférer des informations sensibles vers des référentiels centralisés. Cela préserve les politiques de gouvernance, les exigences de conformité et les contrôles de sécurité au niveau de la source.
Scalabilité sans consolidation : Les systèmes fédérés montent en charge en ajoutant de nouvelles sources sans migration de données ni restructuration d’entrepôt, permettant une intégration incrémentielle selon l’évolution des besoins métier.
Accès en temps réel à l’information : En interrogeant directement les sources, la recherche fédérée offre un accès à l’information actuelle sans la latence des entreposages de données par lots, ce qui est crucial pour les applications sensibles au temps.
Efficacité des coûts : Élimine les coûts d’infrastructure et d’opération importants liés à la création et la maintenance d’entrepôts de données centralisés. Les organisations évitent la duplication des données, le stockage redondant et les processus ETL complexes.
Réduction de la redondance des données : Contrairement aux entrepôts de données qui dupliquent l’information, la recherche fédérée maintient une source unique de vérité, réduisant la charge de stockage et assurant la cohérence.
Flexibilité et adaptabilité : De nouvelles sources peuvent être intégrées sans modifier l’infrastructure existante ni réindexer les référentiels centralisés, permettant une adaptation rapide aux évolutions métier.
Amélioration de la qualité des données : En interrogeant directement les sources d’autorité, la recherche fédérée limite la désuétude et les incohérences liées à la synchronisation périodique des données dans les entrepôts.
Sécurité renforcée : Les données sensibles ne quittent jamais leur emplacement d’origine, réduisant le risque d’accès non autorisé ou de brèche. Les contrôles d’accès restent gérés au niveau source plutôt que par un système centralisé.
Prise en charge de sources hétérogènes : Les systèmes fédérés acceptent la diversité des technologies, formats et protocoles sans exiger de standardisation ou de migration vers des plateformes communes.
Synthèse intelligente des résultats : Le classement et l’agrégation assistés par IA produisent des résultats de meilleure qualité qu’une simple fusion, intégrant crédibilité des sources, pertinence et contexte utilisateur.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Architecture technique & composants
Les systèmes modernes de recherche fédérée par IA regroupent divers composants techniques interconnectés collaborant pour offrir une capacité de recherche intégrée.
Moteur de traitement des requêtes : Composant central recevant les requêtes utilisateur et orchestrant le flux fédéré de recherche. Il inclut l’analyse de requête, l’analyse sémantique et la reconnaissance d’intention. Les implémentations avancées exploitent des modèles de langage de type transformeur pour comprendre la sémantique complexe des requêtes et l’intention implicite de l’utilisateur.
Registre des sources et gestion des métadonnées : Maintient des métadonnées complètes sur les sources disponibles : schémas, caractéristiques, fréquence de mise à jour, disponibilité, métriques de performance. Ce registre facilite la sélection intelligente des sources et l’optimisation des requêtes. Les modèles d’IA analysent l’historique des requêtes pour prédire la pertinence des sources pour de nouvelles recherches.
Module intelligent de sélection des sources : Utilise des classifieurs d’apprentissage automatique pour déterminer quelles sources ont le plus de chances de contenir de l’information pertinente pour une requête donnée. Il prend en compte couverture, taux de succès historique, disponibilité, temps de réponse estimé. Les systèmes avancés emploient l’apprentissage par renforcement pour optimiser en continu les stratégies de sélection.
Couche de traduction et adaptation des requêtes : Convertit les requêtes utilisateur dans les formats et langages propres à chaque source. Cela inclut la génération SQL pour les bases relationnelles, SPARQL pour les graphes de connaissances, appels API REST pour les web services, et requêtes en langage naturel pour les systèmes textuels. Le mappage sémantique veille à préserver l’intention de la requête.
Coordinateur d’exécution distribuée : Gère l’exécution parallèle des requêtes, incluant la gestion des délais, l’équilibrage de charge et la reprise après échec. Il applique des stratégies de délai adaptatif selon les réponses et la charge système.
Moteur de normalisation des résultats : Convertit les résultats hétérogènes en un format commun pour l’agrégation et le classement. Cela comprend l’alignement de schémas, la conversion de types de données et la standardisation des formats, gérant les champs manquants, les conflits de types, et les différences structurelles.
Module d’enrichissement sémantique : Ajoute du contexte et des informations sémantiques aux résultats : liage d’entités à des bases de connaissances, tagging sémantique via des ontologies, extraction de relations à partir de textes non structurés. Ces enrichissements améliorent la pertinence du classement et la compréhension des résultats.
Modèle de classement par apprentissage : Modèle IA entraîné sur des couples requête-résultat historiques pour prédire la pertinence. Il prend en compte des centaines de critères : crédibilité de la source, fraîcheur, alignement avec le profil utilisateur, similarité sémantique. Les implémentations modernes utilisent le boosting de gradient ou des réseaux neuronaux.
Moteur de déduplication : Identifie et supprime les doublons ou quasi-doublons issus de différentes sources, via des métriques de similarité : correspondance exacte, fuzzy matching, similarité sémantique par embeddings.
Moteur de personnalisation : Personnalise l’ordre des résultats selon le profil utilisateur, les préférences et le contexte, à l’aide du filtrage collaboratif et de la recommandation basée sur le contenu.
Couche de mise en cache et optimisation : Implémente des stratégies de cache intelligentes pour éviter les requêtes redondantes : cache de résultats, des métadonnées sources, et modèles de requêtes apprises.
Module de monitoring et analytique : Suit la performance système, la fiabilité des sources, les schémas de requêtes et la qualité des résultats. Ces données alimentent l’optimisation continue du système.
Cas d’usage sectoriels
Santé et recherche médicale : La recherche fédérée intègre les dossiers patients entre hôpitaux, bases de recherche, registres d’essais cliniques et publications médicales. Les médecins accèdent à l’historique patient complet sans centraliser les données sensibles. Les chercheurs consultent des données cliniques réparties tout en respectant la conformité HIPAA et la vie privée.
Services financiers : Les banques et sociétés d’investissement utilisent la recherche fédérée pour interroger simultanément données de marché, bases réglementaires, transactions internes. Cela permet évaluation des risques en temps réel, monitoring de conformité et analyse de marché sans centraliser les données sensibles.
Juridique et conformité : Cabinets et départements juridiques recherchent dans jurisprudence, bases réglementaires, GED internes et contrats. La recherche fédérée permet une recherche exhaustive tout en préservant la confidentialité et le secret professionnel.
E-commerce & retail : Les e-commerçants intègrent catalogues produits de plusieurs entrepôts, fournisseurs, marketplace. La recherche fédérée offre une découverte unifiée tout en laissant chaque fournisseur gérer indépendamment ses stocks et tarifs.
Secteur public : Les administrations cherchent dans bases de données réparties : recensements, impôts, permis, registres publics sans centraliser les informations citoyennes sensibles, assurant des services complets tout en protégeant la vie privée.
Industrie & chaîne logistique : Les industriels intègrent bases fournisseurs, stocks, production et plateformes logistiques. La recherche fédérée offre une visibilité chaîne d’approvisionnement tout en préservant l’indépendance des partenaires.
Éducation & recherche : Les universités interrogent référentiels institutionnels, bibliothèques, bases de recherche et publications. La recherche fédérée permet une exploration académique exhaustive tout en respectant l’autonomie institutionnelle.
Télécommunications : Les opérateurs consultent bases clients, réseaux, facturation, catalogues de services. La recherche fédérée permet un service client unifié tout en préservant les systèmes distincts par ligne de service ou région.
Énergie et services publics : Les énergéticiens interrogent centrales, réseaux de distribution, bases clients, systèmes de conformité réglementaire. La recherche fédérée assure une visibilité opérationnelle tout en maintenant l’indépendance des opérateurs régionaux.
Médias & édition : Les groupes médias recherchent dans archives, référentiels, systèmes de gestion des droits et plateformes de diffusion. La recherche fédérée permet une découverte exhaustive du contenu tout en préservant la propriété et les droits.
Défis & limitations
Hétérogénéité des sources et complexité d’intégration : L’intégration de sources diverses (schémas, langages, protocoles différents) requiert un effort d’ingénierie important. Le mappage de schémas et l’alignement sémantique restent difficiles, surtout en cas de représentations divergentes d’un même concept.
Latence et performance : La recherche fédérée implique de multiples sources, introduisant de la latence par rapport à un système centralisé. Des sources lentes ou non réactives dégradent la performance. La gestion fine des délais est essentielle pour équilibrer exhaustivité et réactivité.
Fiabilité et disponibilité des sources : Les systèmes fédérés dépendent de la disponibilité des sources externes. Les pannes ou dégradations impactent directement la qualité de recherche. Une dégradation progressive doit être prévue en cas d’échec.
Qualité des résultats et précision du classement : Agréger des résultats de sources aux qualités, couvertures et critères de pertinence variés est complexe. Les modèles de classement doivent éviter d’avantager certains fournisseurs.
Fraîcheur et cohérence des données : Les systèmes fédérés accèdent aux données à jour, mais la fréquence de mise à jour et la cohérence varient selon les sources. La résolution intelligente des conflits est nécessaire.
Limites de scalabilité : L’augmentation du nombre de sources accroît la complexité de coordination. La sélection pertinente parmi des milliers de sources devient coûteuse. L’exécution parallèle exige une infrastructure robuste.
Sécurité et contrôle d’accès : Les systèmes fédérés doivent faire respecter les droits d’accès propres à chaque source tout en offrant une interface unifiée. Garantir que chaque utilisateur voit uniquement ce à quoi il a droit est complexe, surtout en mode multi-tenant.
Vie privée et protection des données : La recherche fédérée doit respecter RGPD, CCPA et exigences sectorielles. Il faut éviter toute fuite de données sensibles via l’agrégation des résultats ou l’analyse des métadonnées.
Découverte et gestion des sources : Identifier, cataloguer, maintenir les sources disponibles et gérer leur cycle de vie (ajout, retrait, mise à jour) requiert un suivi opérationnel continu.
Interopérabilité sémantique : Atteindre une interopérabilité sémantique réelle entre sources aux ontologies et modèles variés reste difficile. Les techniques automatiques de mappage et résolution d’entités ont leurs limites.
Coût de la coordination : Si la recherche fédérée supprime les coûts de consolidation, elle introduit un surcoût de coordination : gestion de l’exécution distribuée, des échecs, optimisation du routage des requêtes.
Manque de standardisation : L’absence de standards universels pour les protocoles et interfaces de recherche fédérée complique l’intégration et favorise le verrouillage fournisseur.
Recherche fédérée par IA vs. technologies apparentées
Recherche fédérée par IA vs. entreposage de données : L’entreposage consolide les données dans un référentiel centralisé, permettant des requêtes rapides mais nécessitant un effort ETL et introduisant de la latence. La recherche fédérée interroge directement les sources, offrant un accès en temps réel mais avec une latence plus élevée. L’entreposage convient à l’analyse historique, la fédération à la découverte d’informations actuelles.
Recherche fédérée par IA vs. data lakes : Les data lakes stockent les données brutes de plusieurs sources dans un emplacement central, avec peu de transformation. Ils sont flexibles mais impliquent des coûts de stockage et de gouvernance. La fédération évite toute consolidation, préservant l’autonomie des sources au prix d’une gestion des requêtes plus complexe.
Recherche fédérée par IA vs. APIs et microservices : Les APIs offrent un accès programmatique à chaque service, mais nécessitent la connaissance de chaque interface. La fédération masque ces détails, permettant des requêtes unifiées. Les APIs servent l’intégration applicative, la fédération la découverte d’information transversale.
Recherche fédérée par IA vs. graphes de connaissances : Les graphes de connaissances représentent l’information sous forme d’entités et de relations pour le raisonnement sémantique. La recherche fédérée peut exploiter des graphes distribués mais sans construction centralisée. Les graphes offrent une compréhension sémantique, la fédération privilégie l’autonomie des sources.
Recherche fédérée par IA vs. moteurs de recherche : Les moteurs traditionnels maintiennent des index centralisés du contenu crawlé. La fédération interroge directement les sources sans pré-indexation. Les moteurs couvrent le contenu public, la fédération excelle pour l’intégration de sources privées ou spécialisées.
Recherche fédérée par IA vs. MDM : Le MDM (gestion des données de référence) crée des enregistrements maîtres à partir de sources multiples. La fédération interroge chaque source indépendamment, sans créer de master. Le MDM vise la gouvernance et la cohérence, la fédération l’autonomie et l’accès en temps réel.
Recherche fédérée par IA vs. recherche d’entreprise : La recherche d’entreprise indexe en central documents et bases internes. La fédération interroge les sources en direct sans index central. L’entreprise offre une recherche texte rapide, la fédération gère la diversité et les mises à jour temps réel.
Recherche fédérée par IA vs. blockchain et registres distribués : La blockchain assure l’intégrité et l’immutabilité via consensus entre nœuds. La fédération coordonne les requêtes sans consensus, pour la découverte d’information. La blockchain vise la confiance, la fédération la découverte.
Bonnes pratiques de mise en œuvre
Évaluation complète des sources : Avant intégration, évaluer qualité, fréquence de mise à jour, disponibilité, complexité des schémas et protocoles d’accès. Ceci oriente la sélection des sources et fixe des attentes réalistes.
Intégration incrémentale : Commencer par quelques sources bien maîtrisées puis élargir progressivement, pour acquérir de l’expertise, identifier les défis et affiner les processus.
Gestion robuste des métadonnées : Maintenir des métadonnées complètes sur les sources (schéma, couverture, qualité, performance). Garantir leur actualité par du monitoring et des validations périodiques.
Sélection intelligente des sources : Utiliser l’apprentissage automatique pour affiner la sélection selon les résultats passés. Suivre la pertinence des sources par type de requête et optimiser en continu.
Gestion adaptative des délais : Adapter dynamiquement les délais selon la charge et la réactivité des sources, éviter les délais fixes trop longs ou trop courts.
Garantie de la qualité des résultats : Définir des métriques de qualité (pertinence, fraîcheur, exhaustivité). Mettre en place des retours utilisateur pour entraîner les modèles de classement.
Monitoring exhaustif : Surveiller disponibilité, temps de réponse, qualité des résultats, satisfaction utilisateur. Exploiter ces données pour optimiser le routage et la performance.
Sécurité et contrôle d’accès : Appliquer les contrôles au niveau source pour garantir l’autorisation sur l’ensemble du système fédéré. S’assurer que chaque utilisateur n’accède qu’aux informations autorisées.
Stratégies de cache : Implémenter le cache à plusieurs niveaux (résultats, métadonnées, modèles de requêtes), en équilibrant fraîcheur et performance.
Optimisation de l’expérience utilisateur : Concevoir des interfaces explicitant les sources, niveaux de confiance, fraîcheur. Rendre transparentes les sources interrogées et les raisons du classement.
Optimisation des performances : Profiler l’exécution pour détecter les goulets. Optimiser la sélection des sources, la traduction des requêtes, l’agrégation. Anticiper les requêtes fréquentes.
Apprentissage continu : Capturer l’interaction utilisateur pour améliorer la sélection, le classement et la présentation.
Documentation et gouvernance : Documenter caractéristiques des sources, méthodes d’intégration, architecture du système, et mettre en place des politiques de gouvernance pour la gestion du cycle de vie des sources.
Tests et validation : Mettre en place des tests unitaires, d’intégration et de bout en bout sur tout le workflow, valider la qualité des résultats sur des jeux de vérité.
Tendances futures & intégration de l’IA
Compréhension avancée du langage naturel : Les futurs systèmes fédérés exploiteront de grands modèles de langage et des techniques NLP avancées pour comprendre des requêtes complexes et nuancées, permettant une sélection de source et une interprétation plus précises.
Découverte autonome des sources : L’IA automatisera la découverte, l’évaluation et l’intégration de nouvelles sources, réduisant la gestion manuelle.
Intégration du web sémantique : Avec la maturité des technologies du web sémantique, la fédération exploitera ontologies et normes de data linking pour une interopérabilité sémantique profonde.
IA explicable et transparence : Les futurs systèmes fourniront des explications détaillées sur le classement, la sélection et l’agrégation, renforçant la confiance utilisateur et la compréhension du fonctionnement.
Intégration de l’apprentissage fédéré : L’apprentissage fédéré permettra d’entraîner des modèles sur des sources distribuées sans centraliser les données, combinant autonomie et puissance prédictive.
Intégration des flux en temps réel : Les systèmes fédérés s’ouvriront aux flux temps réel, permettant la recherche sur des données en continu.
Recherche multimodale : L’IA permettra la recherche sur des contenus variés : texte, image, vidéo, audio. Les modèles multimodaux offriront une synthèse transversale.
Personnalisation et sensibilité au contexte : Une modélisation utilisateur avancée permettra une expérience de recherche fédérée hautement personnalisée, tenant compte du niveau d’expertise, des besoins et préférences.
Applications du calcul quantique : Avec la maturation du quantique, les algorithmes fédérés exploiteront ces techniques pour l’optimisation de la sélection des sources et du classement, accélérant le traitement.
Intégration de la blockchain : La blockchain apportera la vérification des sources, la traçabilité des résultats et la coordination décentralisée, en particulier pour les applications nécessitant la confiance.
Edge computing & traitement distribué : La recherche fédérée s’appuiera sur l’edge pour traiter les requêtes au plus près des sources, réduisant latence et trafic, améliorant la vie privée.
Optimisation autonome : Les systèmes fédérés s’auto-optimiseront en continu selon les schémas de requêtes, les caractéristiques des sources et les retours utilisateurs, sans intervention humaine.
Intégration de connaissances inter-domaines : Les systèmes futurs relieront des connaissances issues de domaines distincts, permettant de découvrir des liens et insights inédits issus de la combinaison de sources variées.
Questions fréquemment posées
Quelle est la principale différence entre la recherche fédérée par IA et la recherche centralisée traditionnelle ?
La recherche centralisée traditionnelle consolide toutes les données dans un référentiel indexé unique, nécessitant la migration des données et introduisant de la latence. La recherche fédérée par IA interroge directement plusieurs sources indépendantes en temps réel sans déplacer ni dupliquer les données, préservant l’autonomie des sources tout en offrant un accès unifié. Cela rend la recherche fédérée idéale pour les organisations avec des sources de données distribuées et des exigences strictes en matière de gouvernance des données.
Comment la recherche fédérée par IA assure-t-elle la sécurité et la conformité ?
La recherche fédérée par IA conserve les données à leur emplacement d’origine et respecte les contrôles d’accès et politiques de sécurité de chaque source. Les utilisateurs n’accèdent qu’aux informations auxquelles ils sont autorisés, et les données sensibles ne quittent jamais leur système source. Cette approche simplifie la conformité à des réglementations telles que le RGPD et la HIPAA en éliminant les risques liés à la centralisation des informations sensibles.
Quels sont les principaux défis de la mise en œuvre de la recherche fédérée par IA ?
Les principaux défis incluent la gestion de sources de données hétérogènes avec des schémas et formats différents, la gestion de la latence des requêtes provenant de multiples sources, l’assurance d’un classement cohérent des résultats entre sources, et le maintien de la fiabilité du système lorsque des sources ne sont pas disponibles. Les organisations doivent également investir dans une gestion robuste des métadonnées et des algorithmes intelligents de sélection des sources pour optimiser la performance.
La recherche fédérée par IA est-elle évolutive à mesure que les sources augmentent ?
Oui, la recherche fédérée par IA est évolutive en ajoutant de nouvelles sources sans exiger de migration des données ou de restructuration d’entrepôt. Cependant, à mesure que le nombre de sources augmente, la coordination des requêtes devient plus lourde. Les systèmes modernes utilisent l’apprentissage automatique pour la sélection intelligente des sources et mettent en œuvre des stratégies de mise en cache afin de maintenir la performance à grande échelle.
En quoi la recherche fédérée par IA diffère-t-elle de l’entreposage de données ?
L’entreposage de données consolide les données dans un référentiel centralisé, permettant des requêtes rapides mais nécessitant un effort ETL important et introduisant de la latence. La recherche fédérée interroge les sources directement, offrant un accès en temps réel mais avec une latence de requête plus élevée. L’entreposage convient à l’analyse historique et au reporting, tandis que la recherche fédérée excelle dans la découverte d’informations actuelles sur des sources distribuées.
Quels secteurs bénéficient le plus de la recherche fédérée par IA ?
La santé, la finance, le e-commerce, le secteur public et les organisations de recherche bénéficient fortement de la recherche fédérée. La santé l’utilise pour intégrer les dossiers patients entre prestataires, la finance pour la conformité et l’évaluation des risques, le e-commerce pour une découverte unifiée des produits, et la recherche pour explorer des bases de données académiques distribuées.
Comment l’IA améliore-t-elle les capacités de recherche fédérée ?
L’IA améliore la recherche fédérée grâce au traitement du langage naturel pour la compréhension des requêtes, à l’apprentissage automatique pour la sélection intelligente des sources, à l’analyse sémantique pour un meilleur classement des résultats, et à la déduplication automatisée. Les modèles d’IA apprennent des schémas de requêtes afin d’optimiser continuellement la sélection des sources et l’agrégation des résultats, améliorant ainsi la performance du système au fil du temps.
Quel est le rôle de la compréhension sémantique dans la recherche fédérée par IA ?
La compréhension sémantique permet aux systèmes fédérés de saisir l’intention d’une requête au-delà de la simple correspondance de mots-clés, d’identifier plus précisément les sources pertinentes et de classer les résultats selon la signification plutôt que le simple recoupement de mots-clés. Cela inclut la reconnaissance d’entités, l’extraction de relations, et l’intégration de graphes de connaissances, produisant des résultats de recherche plus pertinents et adaptés au contexte.
Surveillez comment l’IA référence votre marque
AmICited suit la façon dont les systèmes d’IA comme ChatGPT, Perplexity et Google AI Overviews citent et référencent votre marque. Comprenez la visibilité de votre marque auprès de l’IA et optimisez votre présence dans les réponses générées par l’IA.
Comment les entreprises technologiques optimisent pour les moteurs de recherche par IA
Découvrez comment les entreprises technologiques optimisent leur contenu pour les moteurs de recherche par IA comme ChatGPT, Perplexity et Gemini. Découvrez des...
Découvrez ce que sont les moteurs de recherche IA, en quoi ils diffèrent de la recherche traditionnelle et leur impact sur la visibilité des marques. Explorez d...
Qu'est-ce que la recherche en temps réel dans l'IA ?
Découvrez comment fonctionne la recherche en temps réel dans l'IA, ses avantages pour les utilisateurs et les entreprises, et en quoi elle diffère des moteurs d...
15 min de lecture
Consentement aux Cookies Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.