
サーバーログでAIクローラーを特定する方法:完全検出ガイド
GPTBot、PerplexityBot、ClaudeBotなどのAIクローラーをサーバーログで特定・監視する方法を解説。ユーザーエージェント文字列やIP検証手法、AIトラフィック追跡のベストプラクティスもご紹介。...
2 分で読める

AIクローラーがウェブサーバーにHTTPヘッダーで送信する識別文字列で、アクセス制御や分析トラッキング、正当なAIボットと悪意のあるスクレイパーを区別するために使用されます。この文字列はクローラーの目的、バージョン、起源を特定します。
AIクローラーがウェブサーバーにHTTPヘッダーで送信する識別文字列で、アクセス制御や分析トラッキング、正当なAIボットと悪意のあるスクレイパーを区別するために使用されます。この文字列はクローラーの目的、バージョン、起源を特定します。
AIクローラーのユーザーエージェントとは、人工知能の学習やインデックス作成、研究目的でウェブコンテンツにアクセスする自動化ボットを識別するためのHTTPヘッダー文字列です。この文字列はクローラーのデジタルIDとして機能し、リクエストの発信元や意図をウェブサーバーに伝えます。ウェブサイト運営者はこのユーザーエージェントを利用して、様々なAIシステムによる自サイトへのアクセス方法を識別・追跡・制御できます。適切なユーザーエージェント識別がなければ、正当なAIクローラーと悪意のあるボットの区別が著しく困難となり、責任あるウェブスクレイピングやデータ収集には不可欠な要素となっています。
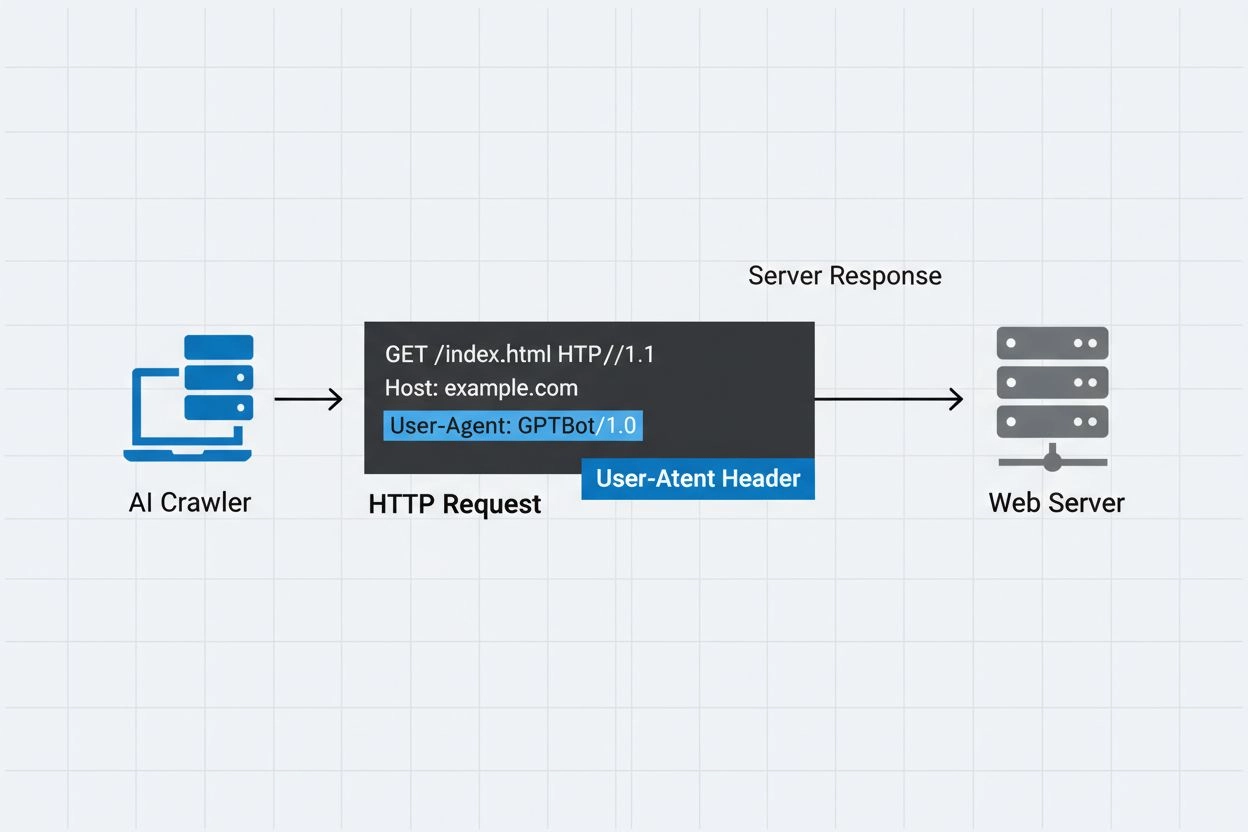
ユーザーエージェントヘッダーはHTTPリクエストの重要な要素で、すべてのブラウザやボットがウェブリソースへアクセスする際にリクエストヘッダー内に送信されます。クローラーがウェブサーバーにリクエストを送る際、自身のメタデータをHTTPヘッダーに含め、その中でもユーザーエージェント文字列は最も重要な識別情報のひとつです。この文字列には通常、クローラー名、バージョン、運営組織、検証用の連絡先URLやメールアドレスなどの情報が含まれます。ユーザーエージェントによってサーバーはリクエスト元を特定し、コンテンツの提供可否、リクエストのレート制限、アクセス遮断などの判断が可能になります。以下は主要なAIクローラーのユーザーエージェント文字列例です。
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36; compatible; OAI-SearchBot/1.3; +https://openai.com/searchbot
| クローラー名 | 目的 | ユーザーエージェント例 | IP検証 |
|---|---|---|---|
| GPTBot | 学習データ収集 | Mozilla/5.0…compatible; GPTBot/1.3 | OpenAI IP範囲 |
| ClaudeBot | モデル学習 | Mozilla/5.0…compatible; ClaudeBot/1.0 | Anthropic IP範囲 |
| OAI-SearchBot | 検索インデックス作成 | Mozilla/5.0…compatible; OAI-SearchBot/1.3 | OpenAI IP範囲 |
| PerplexityBot | 検索インデックス作成 | Mozilla/5.0…compatible; PerplexityBot/1.0 | Perplexity IP範囲 |
著名なAI企業は、それぞれ独自のユーザーエージェント識別子と目的を持つクローラーを運用しています。これらのクローラーはAIエコシステム内での異なる利用ケースを代表しています。
各クローラーには特定のIP範囲や公式ドキュメントがあり、ウェブサイト運営者はそれを参照して正当性を検証し、適切なアクセス制御を実施できます。
ユーザーエージェント文字列は、HTTPリクエストを行うどんなクライアントでも簡単に偽装できるため、正当なAIクローラーの識別手段としては単独では不十分です。悪意のあるボットは、よく使われるユーザーエージェント文字列を頻繁に偽装し、実際の正体を隠したりウェブサイトのセキュリティ対策やrobots.txtの制限を回避したりします。この脆弱性への対策として、セキュリティ専門家はIP検証を追加の認証層として推奨し、AI企業が公開する公式IP範囲からのリクエストであることを確認します。また、新たな標準であるRFC 9421 HTTPメッセージ署名は、クローラーがリクエストにデジタル署名し、サーバー側で暗号学的に真正性を検証できる仕組みを提供します。しかし、ユーザーエージェント文字列やIPアドレスをプロキシや侵害されたインフラ経由で同時に偽装する高度な攻撃者も存在するため、本物と偽物のクローラーの識別は依然として困難です。クローラー運営者とセキュリティ意識の高いウェブサイト運営者の間では、こうした検証技術の進化に応じたいたちごっこが続いています。
ウェブサイト運営者はrobots.txtファイルでユーザーエージェント指令を指定することで、どのクローラーがどのサイト部分へアクセスできるかを細かく制御できます。robots.txtではユーザーエージェント識別子ごとに独自ルールを適用できるため、特定のクローラーは許可し、他はブロックするなど柔軟な管理が可能です。以下はrobots.txtの設定例です。
User-agent: GPTBot
Disallow: /private
Allow: /
User-agent: ClaudeBot
Disallow: /
ただしrobots.txtには重要な制約があります。
ウェブサイト運営者はサーバーログを活用することで、どのAIクローラーがどの頻度でコンテンツへアクセスしているかを可視化できます。HTTPリクエストログを確認し、既知のAIクローラーのユーザーエージェントをフィルタリングすることで、各AI企業による帯域幅への影響やデータ収集パターンを把握可能です。ログ分析プラットフォームやウェブ解析サービス、カスタムスクリプトなどを利用してサーバーログを解析し、クローラーのトラフィック特定、リクエスト頻度の計測、データ転送量の算出などができます。これは自身のコンテンツがAI学習にどう使われているかを知り、アクセス制限の要否を判断したい制作者や出版社にとって特に重要です。AmICited.comのようなサービスは、AIシステムがウェブ上のコンテンツをどのように引用・参照しているかをモニタリングし、クリエイターにAI学習での利用実態の透明性を提供します。クローラー活動の理解は、ウェブサイト運営者がコンテンツポリシーやAI企業とのデータ利用交渉を行ううえでの意思決定に役立ちます。
AIクローラーのアクセスを効果的に管理するには、複数の検証・監視技術を組み合わせた多層的アプローチが求められます。
これらの実践により、ウェブサイト運営者は自らのコンテンツを管理しつつ、責任あるAI開発をサポートできます。
ユーザーエージェントとは、ウェブリクエストを行うクライアントを識別するHTTPヘッダー文字列です。これは、リクエストを行うアプリケーションがブラウザ、クローラー、ボットのいずれであっても、そのソフトウェア、オペレーティングシステム、バージョンに関する情報を含みます。この文字列により、ウェブサーバーは異なる種類のクライアントを識別・追跡できます。
ユーザーエージェント文字列によって、ウェブサーバーはどのクローラーがコンテンツへアクセスしているかを識別でき、ウェブサイト所有者はアクセス制御、クローラー活動の追跡、さまざまな種類のボットの区別が可能になります。これは帯域幅の管理、コンテンツの保護、AIシステムがどのようにデータを利用しているかを把握するために不可欠です。
はい、ユーザーエージェント文字列は単なるHTTPヘッダー内のテキスト値なので簡単に偽装できます。そのため、IP検証やHTTPメッセージ署名などの追加の検証方法が、クローラーの正当な身元確認と悪意のあるボットによる偽装防止のために重要です。
robots.txtでユーザーエージェント指令を使ってクローラーにサイトへのアクセスを控えるよう依頼できますが、これは強制力がありません。より強力な制御には、サーバーサイドの検証やIP許可/ブロックリスト、ユーザーエージェントとIPアドレスの両方を同時に確認するWAFルールを利用してください。
GPTBotはChatGPTなどのAIモデル向けに学習データを収集するOpenAIのクローラーで、OAI-SearchBotはChatGPT内の検索機能やインデックス作成を目的としたクローラーです。目的、クロール速度、IP範囲が異なるため、それぞれ異なるアクセス制御戦略が必要です。
クローラーのIPアドレスを、クローラー運営元が公開している公式IPリスト(例:GPTBotの場合はopenai.com/gptbot.json)と照合してください。正当なクローラーはIP範囲を公開しており、ファイアウォールやWAF設定でリクエストがその範囲から来ているか検証できます。
HTTPメッセージ署名(RFC 9421)は、クローラーがリクエストに秘密鍵で署名する暗号技術です。サーバーは、クローラーの.well-knownディレクトリから公開鍵を取得し、署名を検証することでリクエストの真正性や改ざんの有無を確認できます。
AmICited.comは、GPTs、Perplexity、Google AI OverviewsなどのAIプラットフォーム全体で、AIシステムがあなたのブランドをどのように参照・引用しているかを監視します。クローラー活動やAIによる言及を追跡し、AI生成回答での可視性やコンテンツの利用状況を把握できます。
AmICitedを使って、ChatGPT、Perplexity、Google AI Overviews、その他AIプラットフォームでAIクローラーがあなたのコンテンツをどのように参照・引用しているかを追跡しましょう。
GPTBot、PerplexityBot、ClaudeBotなどのAIクローラーをサーバーログで特定・監視する方法を解説。ユーザーエージェント文字列やIP検証手法、AIトラフィック追跡のベストプラクティスもご紹介。...
どのAIクローラーをrobots.txtで許可またはブロックすべきかを解説。GPTBot、ClaudeBot、PerplexityBotなど25種類以上のAIクローラーと設定例を網羅した総合ガイド。...

GPTBot、ClaudeBot、PerplexityBotなどのAIクローラーをサーバーログで特定・監視する方法を解説。ユーザーエージェント文字列、IP検証、実践的な監視戦略を網羅した完全ガイド。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.