
ClaudeBot uitgelegd: Antropic's crawler en jouw content
Ontdek hoe ClaudeBot werkt, hoe het verschilt van Claude-Web en Claude-SearchBot, en hoe je Antropic's webcrawlers op je website beheert met robots.txt-configur...
7 min lezen

ClaudeBot is de webcrawler van Anthropic die wordt gebruikt voor het verzamelen van trainingsdata voor Claude AI-modellen. Het crawlt systematisch publiek toegankelijke websites om content te verzamelen voor het trainen van machine learning-modellen. Website-eigenaren kunnen de toegang van ClaudeBot beheren via robots.txt-configuratie. De crawler respecteert standaard robots.txt-richtlijnen, waardoor sites het bezoek kunnen blokkeren of toestaan.
ClaudeBot is de webcrawler van Anthropic die wordt gebruikt voor het verzamelen van trainingsdata voor Claude AI-modellen. Het crawlt systematisch publiek toegankelijke websites om content te verzamelen voor het trainen van machine learning-modellen. Website-eigenaren kunnen de toegang van ClaudeBot beheren via robots.txt-configuratie. De crawler respecteert standaard robots.txt-richtlijnen, waardoor sites het bezoek kunnen blokkeren of toestaan.
ClaudeBot is een webcrawler die wordt beheerd door Anthropic om trainingsdata te downloaden voor hun grote taalmodellen (LLM’s) die AI-producten zoals Claude aandrijven. Deze AI-datascraper crawlt systematisch websites om content te verzamelen speciaal voor het trainen van machine learning-modellen, wat het onderscheidt van traditionele zoekmachine-crawlers die content indexeren voor opvraagdoeleinden. ClaudeBot is te herkennen aan zijn user agent-string en kan worden geblokkeerd of toegestaan via een robots.txt-configuratie, waardoor website-eigenaren controle krijgen over het gebruik van hun content voor de training van de AI-modellen van Anthropic.

ClaudeBot werkt via systematische webontdekkingsmethoden, waaronder het volgen van links van geïndexeerde sites, het verwerken van sitemaps en het gebruiken van seed-URL’s uit openbaar beschikbare website-lijsten. De crawler downloadt website-inhoud om op te nemen in datasets die worden gebruikt voor de training van Claude’s taalmodellen en verzamelt data van publiek toegankelijke pagina’s zonder authenticatie te vereisen. In tegenstelling tot zoekmachine-crawlers die prioriteit geven aan indexering voor opvraging, zijn de crawlfrequentie en patronen van ClaudeBot doorgaans ondoorzichtig, waarbij Anthropic zelden specifieke criteria voor sitekeuze, crawlfrequentie of prioriteiten voor verschillende contenttypes bekendmaakt.
De volgende tabel vergelijkt ClaudeBot met andere crawlers van Anthropic:
| Botnaam | Doel | User Agent | Scope |
|---|---|---|---|
| ClaudeBot | Chatvermelding ophalen en trainingsdata | ClaudeBot/1.0 | Algemene webcrawling voor modeltraining |
| anthropic-ai | Bulkverzameling trainingsdata voor modellen | anthropic-ai | Grootchalige samenstelling van trainingsdatasets |
| Claude-Web | Webgerichte crawling voor Claude-functies | Claude-Web | Webzoek en realtime informatie |
ClaudeBot werkt vergelijkbaar met andere grote AI-trainingscrawlers zoals GPTBot (OpenAI) en PerplexityBot (Perplexity), maar met duidelijke verschillen in scope en methodologie. Terwijl GPTBot zich richt op de trainingsbehoeften van OpenAI en PerplexityBot zowel zoek- als trainingsdoeleinden dient, richt ClaudeBot zich specifiek op content voor de modeltraining van Claude. Volgens data van Dark Visitors blokkeert ongeveer 18% van de 1.000 grootste websites ter wereld actief ClaudeBot, wat duidt op aanzienlijke zorgen onder uitgevers over de dataverzamelingspraktijken. Het belangrijkste verschil is de manier waarop elk bedrijf prioriteit geeft aan contentverzameling—Anthropic kiest voor systematische, brede crawling voor trainingsdata, terwijl zoekgerichte crawlers indexering combineren met het genereren van referralverkeer.
Website-eigenaren kunnen ClaudeBot-bezoeken identificeren door serverlogs te monitoren op de kenmerkende user agent-string: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com). ClaudeBot komt meestal uit IP-reeksen uit de Verenigde Staten en bezoeken kunnen gevolgd worden via serverlog-analyse of speciale monitoringtools. Het instellen van agent-analytics-platforms biedt realtime inzicht in ClaudeBot-bezoeken, zodat website-eigenaren de crawlfrequentie en patronen kunnen meten.
Hier is een voorbeeld van hoe ClaudeBot zichtbaar is in serverlogs:
203.0.113.45 - - [03/Jan/2025:09:15:32 +0000] "GET /blog/article-title HTTP/1.1" 200 5432 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)"
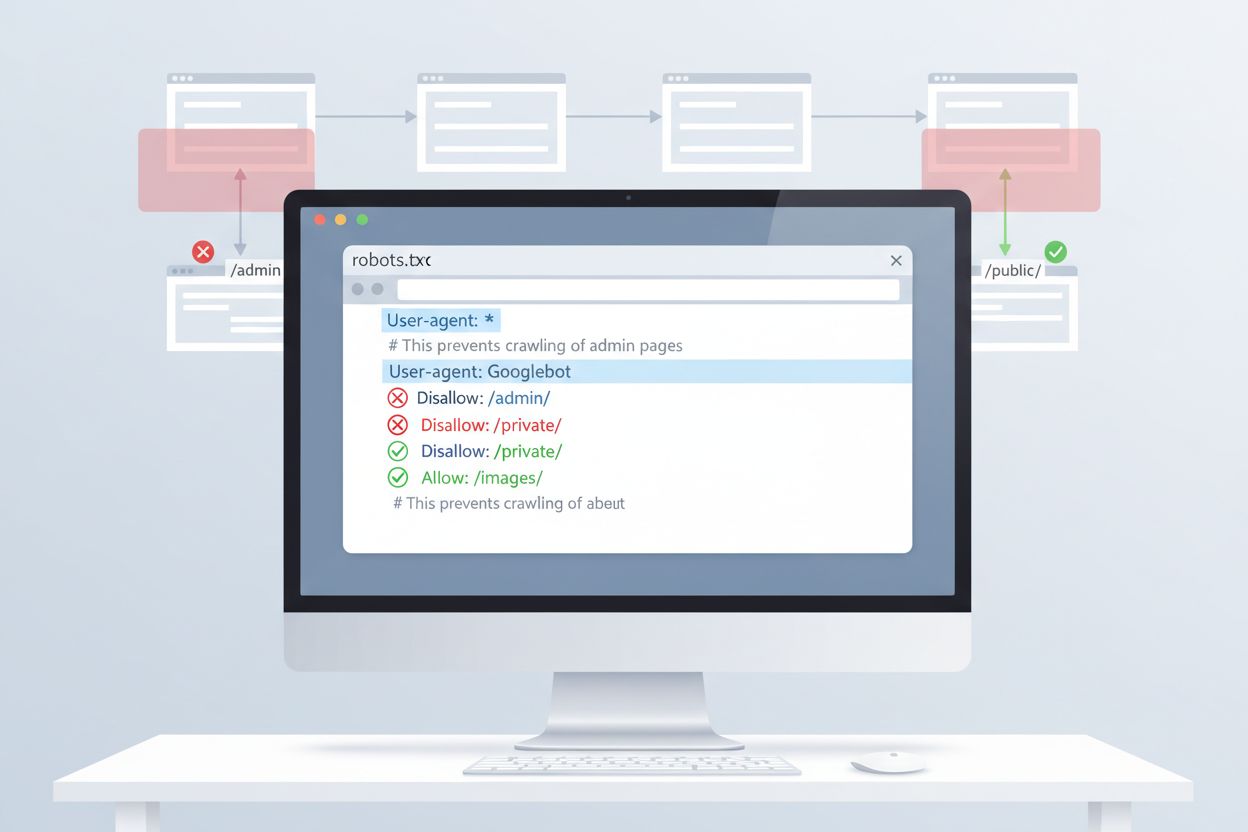
De eenvoudigste manier om toegang van ClaudeBot te beheren is via een robots.txt-configuratie in de hoofdmap van je website. Dit bestand vertelt crawlers welke delen van je site ze mogen bezoeken, en ClaudeBot van Anthropic respecteert deze richtlijnen. Om alle ClaudeBot-activiteit te blokkeren, voeg je de volgende regels toe aan je robots.txt-bestand:
User-agent: ClaudeBot
Disallow: /
Voor selectiever blokkeren waarbij ClaudeBot bepaalde mappen niet mag benaderen maar andere content wel mag crawlen, gebruik je:
User-agent: ClaudeBot
Disallow: /private/
Disallow: /admin/
Allow: /public/
Als je alle Anthropic-crawlers wilt blokkeren (inclusief anthropic-ai en Claude-Web), voeg dan voor elke crawler aparte regels toe:
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Claude-Web
Disallow: /
Hoewel robots.txt de eerste verdedigingslinie biedt, is naleving vrijwillig. Voor uitgevers die sterkere handhaving vereisen, bestaan er aanvullende blokkeringstechnieken:
Deze methoden vereisen meer technische kennis dan een robots.txt-configuratie, maar bieden sterkere handhaving tegen niet-nalevende crawlers.
Het blokkeren van ClaudeBot heeft minimale directe invloed op traditionele SEO-rankings omdat trainingscrawlers niet bijdragen aan zoekmachine-indexering—Google, Bing en andere zoekmachines gebruiken aparte crawlers (Googlebot, Bingbot) die onafhankelijk werken. Het blokkeren van ClaudeBot kan er echter voor zorgen dat je content minder wordt weergegeven in AI-gegenereerde antwoorden van Claude, wat toekomstige vindbaarheid via AI-zoek- en chatinterfaces kan beïnvloeden. De strategische keuze om ClaudeBot te blokkeren of toe te staan, hangt af van je model voor content-monetisatie: als je inkomsten afhankelijk zijn van direct websiteverkeer en advertentie-impressies, voorkom je met blokkeren dat je content wordt opgenomen in trainingsdatasets die mogelijk het bezoekersaantal verminderen. Omgekeerd kan toestaan van ClaudeBot je zichtbaarheid in Claude’s antwoorden vergroten, wat mogelijk referralverkeer van AI-chatgebruikers oplevert.
Effectief beheer van ClaudeBot vereist voortdurende monitoring en testen van je configuratie. Gebruik tools zoals de robots.txt-tester van Google Search Console, de robots.txt-testtool van Merkle of gespecialiseerde platforms zoals Dark Visitors om te controleren of je blokkaderegels goed werken. Controleer regelmatig je serverlogs om te bevestigen of ClaudeBot je robots.txt respecteert en om eventuele veranderingen in crawlpatronen te monitoren. Omdat het AI-crawlerlandschap zich snel ontwikkelt en er regelmatig nieuwe bots verschijnen, zorgen kwartaalcontroles van je robots.txt-configuratie ervoor dat je nieuwe crawlers adresseert en je contentbeschermingsstrategie up-to-date blijft. Test je configuratie altijd voordat je deze live zet om te voorkomen dat je per ongeluk legitieme zoekmachines of andere belangrijke crawlers blokkeert.
ClaudeBot is de webcrawler van Anthropic die systematisch websites bezoekt om trainingsdata te verzamelen voor Claude AI-modellen. Het ontdekt je site door links te volgen, sitemaps te verwerken of via openbare website-lijsten. De crawler verzamelt publiek toegankelijke content om de taalmodelcapaciteiten van Claude te verbeteren.
Je kunt ClaudeBot blokkeren door een robots.txt-regel toe te voegen in de hoofdmap van je website. Voeg simpelweg 'User-agent: ClaudeBot' gevolgd door 'Disallow: /' toe om alle toegang te voorkomen, of specificeer bepaalde paden om selectief te blokkeren. ClaudeBot van Anthropic respecteert robots.txt-richtlijnen.
Nee, het blokkeren van ClaudeBot heeft geen invloed op je Google- of Bing-rankings. Trainingscrawlers zoals ClaudeBot werken onafhankelijk van traditionele zoekmachines. Alleen het blokkeren van Googlebot of Bingbot zou je SEO-prestaties beïnvloeden.
Anthropic beheert drie hoofd-crawlers: ClaudeBot (voor chatvermelding en algemene training), anthropic-ai (verzamelen van bulk trainingsdata), en Claude-Web (webgerichte crawling voor real-time functies). Elk heeft een ander doel binnen de AI-infrastructuur van Anthropic.
Controleer je serverlogs op de ClaudeBot user-agent string: 'Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)'. Je kunt ook monitoringtools zoals Dark Visitors gebruiken of agent-analytics instellen om ClaudeBot-bezoeken in realtime te volgen.
Ja, ClaudeBot respecteert robots.txt-richtlijnen volgens de officiële documentatie van Anthropic. Net als bij alle robots.txt-regels is naleving echter vrijwillig. Voor sterkere handhaving kun je server-niveau blokkering, IP-filtering of WAF-regels implementeren.
ClaudeBot kan aanzienlijke bandbreedte verbruiken, afhankelijk van de grootte van je site en het volume aan content. AI-datascrapers kunnen agressiever crawlen dan traditionele zoekmachines. Door je serverlogs te monitoren kun je het effect inschatten en beslissen of je de crawler wilt blokkeren of toestaan.
De keuze hangt af van je bedrijfsmodel. Blokkeer ClaudeBot als je je zorgen maakt over bronvermelding, compensatie of hoe je werk wordt gebruikt in AI-systemen. Sta het toe als je wilt dat je content verschijnt in Claude's antwoorden en AI-zoekresultaten. Overweeg je strategie voor traffic-monetisatie bij het maken van je keuze.
Volg ClaudeBot en andere AI-crawlers die jouw content benaderen. Krijg inzicht in welke AI-systemen jouw merk citeren en hoe jouw content wordt gebruikt in AI-gegenereerde antwoorden.
Ontdek hoe ClaudeBot werkt, hoe het verschilt van Claude-Web en Claude-SearchBot, en hoe je Antropic's webcrawlers op je website beheert met robots.txt-configur...

Ontdek wat CCBot is, hoe het werkt en hoe je het kunt blokkeren. Begrijp de rol in AI-training, monitoringtools en best practices om je content te beschermen te...
Claude is Anthropic's geavanceerde AI-assistent aangedreven door Constitutionele AI. Ontdek hoe Claude werkt, de belangrijkste kenmerken, veiligheidsmechanismen...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.