
Bør du blokkere eller tillate AI-crawlere? Beslutningsrammeverk
Lær hvordan du tar strategiske beslutninger om blokkering av AI-crawlere. Vurder innholdstype, trafikkilder, inntektsmodeller og konkurranseposisjon med vårt om...
11 min lesing

Den strategiske praksisen med selektivt å tillate eller blokkere AI-crawlere for å kontrollere hvordan innhold brukes til trening versus sanntidsinnhenting. Dette innebærer bruk av robots.txt-filer, servernivåkontroller og overvåkingsverktøy for å styre hvilke AI-systemer som får tilgang til innholdet ditt og til hvilke formål.
Den strategiske praksisen med selektivt å tillate eller blokkere AI-crawlere for å kontrollere hvordan innhold brukes til trening versus sanntidsinnhenting. Dette innebærer bruk av robots.txt-filer, servernivåkontroller og overvåkingsverktøy for å styre hvilke AI-systemer som får tilgang til innholdet ditt og til hvilke formål.
AI-crawleradministrasjon refererer til praksisen med å kontrollere og overvåke hvordan kunstig intelligens-systemer får tilgang til og bruker nettsideinnhold for trenings- og søkeformål. I motsetning til tradisjonelle søkemotorcrawlere som indekserer innhold for nettsøkeresultater, er AI-crawlere spesielt utviklet for å samle data til trening av store språkmodeller eller for å drive AI-drevne søkefunksjoner. Omfanget av denne aktiviteten varierer dramatisk mellom organisasjoner—OpenAIs crawlere opererer med et crawl-to-refer-forhold på 1 700:1, noe som betyr at de besøker innhold 1 700 ganger for hver referanse de gir, mens Anthropics forhold når 73 000:1, noe som illustrerer det enorme datakonsumet som kreves for å trene moderne AI-systemer. Effektiv crawleradministrasjon lar nettsideeieren avgjøre om innholdet deres skal bidra til AI-trening, vises i AI-søkeresultater eller forbli beskyttet mot automatisert tilgang.
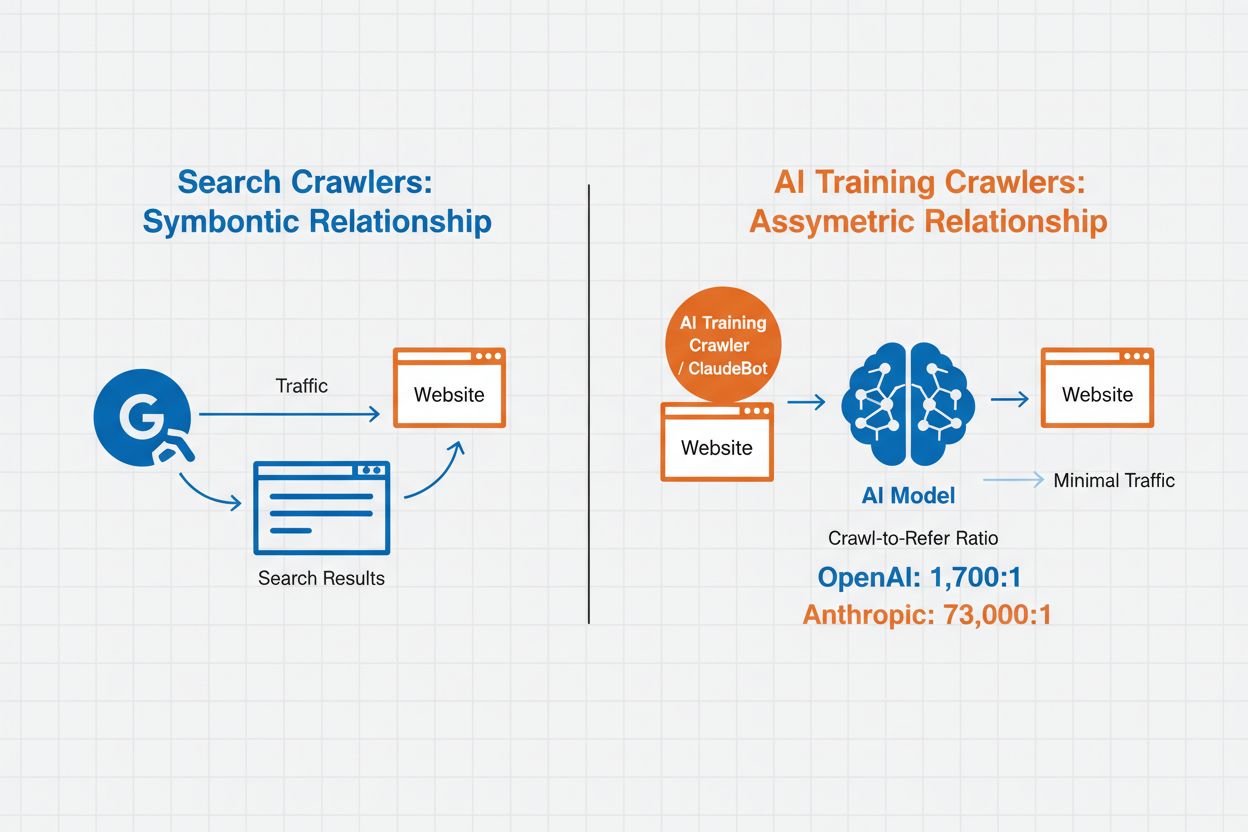
AI-crawlere faller inn i tre distinkte kategorier basert på formål og databruksmønstre. Treningscrawlere er utformet for å samle data til utvikling av maskinlæringsmodeller, og forbruker store mengder innhold for å forbedre AI-evner. Søke- og siteringscrawlere indekserer innhold for å drive AI-drevne søkefunksjoner og gi attribusjon i AI-genererte svar, slik at brukere kan oppdage innholdet ditt gjennom AI-grensesnitt. Brukerutløste crawlere opererer på forespørsel når brukere interagerer med AI-verktøy, for eksempel når en ChatGPT-bruker laster opp et dokument eller ber om analyse av en bestemt nettside. Å forstå disse kategoriene hjelper deg å ta informerte valg om hvilke crawlere som skal tillates eller blokkeres basert på innholdsstrategi og forretningsmål.
| Crawler-type | Formål | Eksempler | Brukes til trening? |
|---|---|---|---|
| Trening | Modellutvikling og forbedring | GPTBot, ClaudeBot | Ja |
| Søk/Sitering | AI-søkeresultater og attribusjon | Google-Extended, OAI-SearchBot, PerplexityBot | Varierer |
| Brukerutløst | Innholdsanalyse på forespørsel | ChatGPT-User, Meta-ExternalAgent, Amazonbot | Kontekstavhengig |
AI-crawleradministrasjon påvirker direkte nettstedets trafikk, inntekter og innholdsverdi. Når crawlere bruker innholdet ditt uten kompensasjon, mister du muligheten til å dra nytte av denne trafikken gjennom henvisninger, annonsevisninger eller brukerengasjement. Nettsteder har rapportert betydelige trafikkreduksjoner ettersom brukere finner svar direkte i AI-genererte svar i stedet for å klikke seg videre til den opprinnelige kilden, noe som i praksis kutter henvisningstrafikk og tilhørende annonseinntekter. Utover de økonomiske konsekvensene finnes det viktige juridiske og etiske betraktninger—innholdet ditt representerer immaterielle rettigheter, og du har rett til å bestemme hvordan det brukes og om du mottar attribusjon eller kompensasjon. I tillegg kan ubegrenset crawler-tilgang øke serverbelastning og båndbreddekostnader, særlig fra crawlere med aggressive besøkshyppigheter som ikke respekterer begrensningsdirektiver.
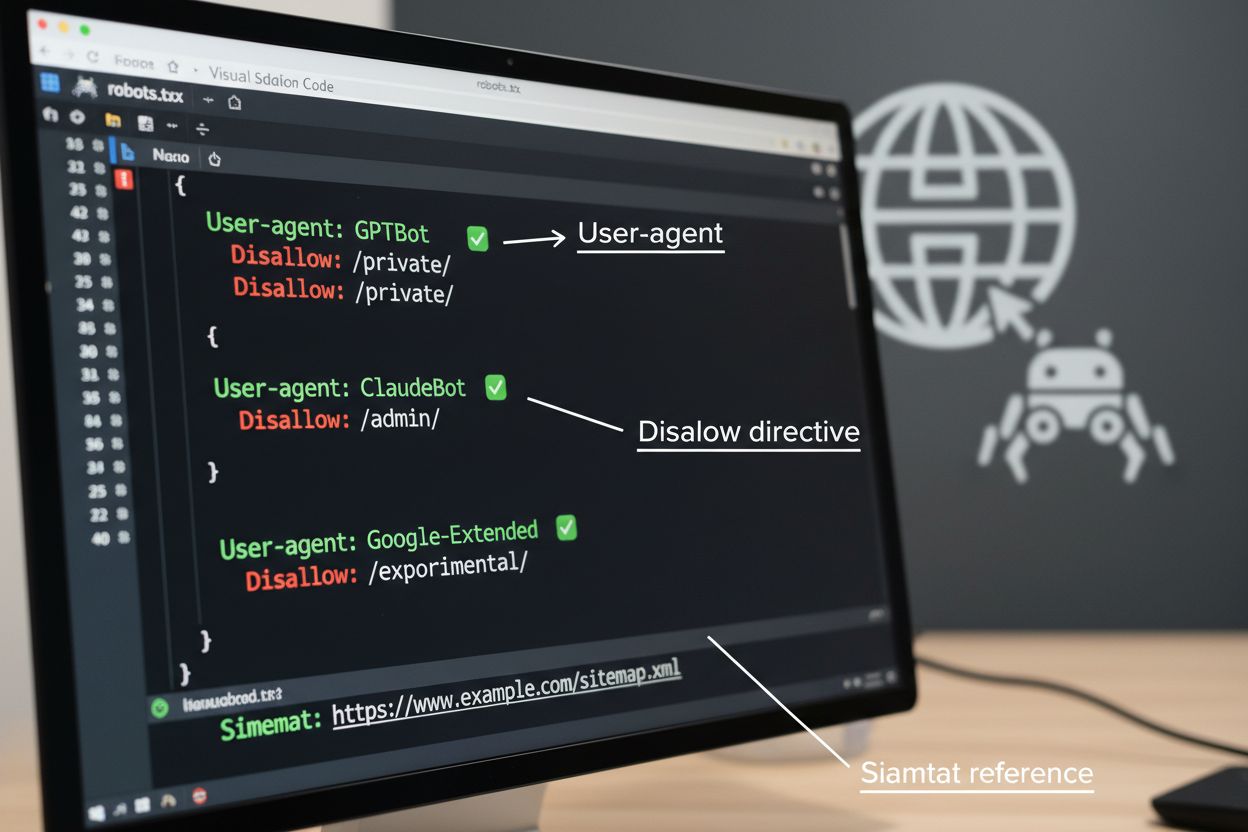
robots.txt-filen er det grunnleggende verktøyet for å styre crawler-tilgang, plassert i rotmappen på nettstedet ditt for å kommunisere krav til automatiserte agenter. Denne filen bruker User-agent-direktiver for å rette seg mot spesifikke crawlere og Disallow- eller Allow-regler for å tillate eller begrense tilgang til bestemte stier og ressurser. Robots.txt har imidlertid viktige begrensninger—det er en frivillig standard som er avhengig av at crawlere følger reglene, og ondsinnede eller dårlig utformede botter kan ignorere den fullstendig. I tillegg forhindrer ikke robots.txt crawlere i å få tilgang til offentlig tilgjengelig innhold; den ber bare om at de respekterer dine preferanser. Av disse grunnene bør robots.txt være en del av en lagdelt tilnærming til crawleradministrasjon fremfor din eneste forsvarslinje.
# Blokker AI-treningscrawlere
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
# Tillat søkemotorer
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Standardregel for andre crawlere
User-agent: *
Allow: /
I tillegg til robots.txt finnes det flere avanserte teknikker som gir sterkere håndhevelse og mer granulær kontroll over crawler-tilgang. Disse metodene fungerer på ulike lag i infrastrukturen din og kan kombineres for helhetlig beskyttelse:
Valget om å blokkere AI-crawlere innebærer viktige avveininger mellom innholdsbeskyttelse og synlighet. Å blokkere alle AI-crawlere fjerner muligheten for at innholdet ditt vises i AI-søkeresultater, AI-drevne sammendrag eller blir sitert av AI-verktøy—noe som potensielt reduserer synlighet overfor brukere som oppdager innhold gjennom disse kanalene. På den annen side betyr ubegrenset tilgang at innholdet ditt brukes til AI-trening uten kompensasjon og kan redusere henvisningstrafikk når brukere får svar direkte fra AI-systemer. En strategisk tilnærming innebærer selektiv blokkering: tillate siteringscrawlere som OAI-SearchBot og PerplexityBot som gir henvisningstrafikk, samtidig som treningscrawlere som GPTBot og ClaudeBot som bruker data uten attribusjon blokkeres. Du kan også vurdere å tillate Google-Extended for å opprettholde synlighet i Google AI Overviews, som kan gi betydelig trafikk, samtidig som du blokkerer konkurrenters treningscrawlere. Den optimale strategien avhenger av innholdstype, forretningsmodell og målgruppe—nyhets- og publiseringsnettsteder kan prioritere blokkering, mens utdanningsinnhold kan ha fordeler av bredere AI-synlighet.
Å implementere crawler-kontroller er bare effektivt dersom du verifiserer at crawlere faktisk følger direktivene dine. Serverlogganalyse er den primære metoden for å overvåke crawler-aktivitet—undersøk tilgangsloggene dine for User-Agent-strenger og forespørselsmønstre for å identifisere hvilke crawlere som besøker siden din og om de respekterer robots.txt-reglene dine. Mange crawlere påstår at de følger reglene, men fortsetter å besøke blokkerte stier, noe som gjør kontinuerlig overvåking essensielt. Verktøy som Cloudflare Radar gir sanntidsinnsyn i trafikkmønstre og kan hjelpe med å identifisere mistenkelig eller ikke-kompatibel crawleratferd. Sett opp automatiske varsler for forsøk på å få tilgang til blokkerte ressurser, og revider loggene dine jevnlig for å fange opp nye crawlere eller endrede mønstre som kan indikere omgåelsesforsøk.
Effektiv AI-crawleradministrasjon krever en systematisk tilnærming som balanserer beskyttelse med strategisk synlighet. Følg disse åtte stegene for å etablere en helhetlig crawleradministrasjonsstrategi:
AmICited.com tilbyr en spesialisert plattform for å overvåke hvordan AI-systemer refererer til og bruker innholdet ditt på tvers av ulike modeller og applikasjoner. Tjenesten gir sanntidssporing av siteringene dine i AI-genererte svar, slik at du kan forstå hvilke crawlere som mest aktivt bruker innholdet ditt og hvor ofte arbeidet ditt dukker opp i AI-resultater. Ved å analysere crawlermønstre og siteringsdata gir AmICited.com deg mulighet til å ta datadrevne beslutninger om crawleradministrasjonsstrategien—du kan se nøyaktig hvilke crawlere som gir verdi gjennom siteringer og henvisninger versus de som forbruker innhold uten attribusjon. Denne innsikten gjør at crawleradministrasjon går fra å være en defensiv praksis til et strategisk verktøy for å optimalisere innholdets synlighet og gjennomslagskraft på det AI-drevne nettet.
Treningscrawlere som GPTBot og ClaudeBot samler innhold for å bygge datasett til utvikling av store språkmodeller, og bruker innholdet ditt uten å gi henvisningstrafikk. Søkecrawlere som OAI-SearchBot og PerplexityBot indekserer innhold for AI-drevne søkeresultater og kan sende besøkende tilbake til siden din via siteringer. Å blokkere treningscrawlere beskytter innholdet ditt mot å bli innlemmet i AI-modeller, mens blokkering av søkecrawlere kan redusere synligheten din på AI-drevne oppdagelsesplattformer.
Nei. Å blokkere AI-treningscrawlere som GPTBot, ClaudeBot og CCBot påvirker ikke Google- eller Bing-rangeringen din. Tradisjonelle søkemotorer bruker andre crawlere (Googlebot, Bingbot) som opererer uavhengig av AI-treningsboter. Blokker kun tradisjonelle søkecrawlere hvis du ønsker å forsvinne helt fra søkeresultatene, noe som vil skade SEO-en din.
Undersøk serverens tilgangslogger for å identifisere User-Agent-strenger fra crawlere. Se etter oppføringer som inneholder 'bot', 'crawler' eller 'spider' i User-Agent-feltet. Verktøy som Cloudflare Radar gir sanntidsinnsyn i hvilke AI-crawlere som besøker siden din og deres trafikkmønstre. Du kan også bruke analyseplattformer som skiller mellom bottrafikk og menneskelige besøkende.
Ja. robots.txt er en rådgivende standard som er avhengig av at crawlere følger reglene—den kan ikke håndheves. Velfungerende crawlere fra store selskaper som OpenAI, Anthropic og Google respekterer stort sett robots.txt, men enkelte crawlere ignorerer den helt. For sterkere beskyttelse, implementer blokkering på servernivå via .htaccess, brannmurregler eller IP-baserte restriksjoner.
Dette avhenger av dine forretningsprioriteringer. Å blokkere alle treningscrawlere beskytter innholdet ditt mot bruk i AI-modeller, mens det potensielt tillater søkecrawlere som kan gi henvisningstrafikk. Mange utgivere bruker selektiv blokkering som retter seg mot treningscrawlere, men tillater søke- og siteringscrawlere. Ta hensyn til innholdstype, trafikkilder og inntektsmodell når du bestemmer strategien.
Gå gjennom og oppdater crawleradministrasjonspolicyen minst kvartalsvis. Nye AI-crawlere dukker opp jevnlig, og eksisterende crawlere endrer User-Agent uten varsel. Følg ressurser som ai.robots.txt-prosjektet på GitHub for fellesskapsvedlikeholdte lister, og sjekk serverloggene dine månedlig for å finne nye crawlere som besøker siden din.
AI-crawlere kan ha betydelig innvirkning på trafikk og inntekter. Når brukere får svar direkte fra AI-systemer i stedet for å besøke siden din, mister du henvisningstrafikk og relaterte annonsevisninger. Forskning viser crawl-to-refer-forhold på opptil 73 000:1 for noen AI-plattformer, noe som betyr at de besøker innholdet ditt tusenvis av ganger for hver besøkende de sender tilbake. Å blokkere treningscrawlere kan beskytte trafikken din, mens tillatelse av søkecrawlere kan gi noen henvisningsfordeler.
Sjekk serverloggene dine for å se om blokkerte crawlere fortsatt dukker opp i tilgangsloggene. Bruk testverktøy som Google Search Console sin robots.txt-tester eller Merkle sin Robots.txt Tester for å validere oppsettet ditt. Gå direkte til robots.txt-filen på dittdomene.com/robots.txt for å verifisere at innholdet er riktig. Overvåk loggene dine regelmessig for å oppdage crawlere som burde vært blokkert men fortsatt vises.
AmICited.com sporer i sanntid AI-henvisninger til merkevaren din på tvers av ChatGPT, Perplexity, Google AI Overviews og andre AI-systemer. Ta datadrevne beslutninger om din crawleradministrasjonsstrategi.
Lær hvordan du tar strategiske beslutninger om blokkering av AI-crawlere. Vurder innholdstype, trafikkilder, inntektsmodeller og konkurranseposisjon med vårt om...

Lær hvilke AI-crawlere du bør tillate eller blokkere i robots.txt-filen din. Omfattende guide som dekker GPTBot, ClaudeBot, PerplexityBot og 25+ AI-crawlere med...

Lær hvordan du blokkerer eller tillater AI-crawlere som GPTBot og ClaudeBot ved hjelp av robots.txt, blokkering på servernivå og avanserte beskyttelsesmetoder. ...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.