Aprenda como criar dados e pesquisas originais que sistemas de IA citam ativamente. Descubra estratégias para tornar seus dados descobertos pelo ChatGPT, Perplexity, Google Gemini e Claude, enquanto constrói visibilidade sustentável na IA.
Publicado em Jan 3, 2026.Última modificação em Jan 3, 2026 às 3:24 am
Na era da inteligência artificial, dados originais tornaram-se a nova vantagem competitiva para marcas que buscam visibilidade além dos rankings tradicionais de busca. À medida que plataformas de IA como ChatGPT, Perplexity, Google Gemini e Claude mediam cada vez mais como as audiências descobrem informações, as regras de visibilidade mudaram fundamentalmente. Em vez de competir pela posição zero nos resultados do Google, as organizações agora precisam criar dados que os sistemas de IA realmente queiram citar e referenciar. Essa transformação reflete uma mudança mais ampla de um SEO baseado em conteúdo para o que especialistas chamam de “Otimização para Motores Generativos” (GEO), onde a citação pela IA substituiu os rankings tradicionais como principal métrica de visibilidade. As plataformas que sintetizam informações em respostas diretas — seja por geração aumentada por recuperação (RAG) ou síntese nativa do modelo — favorecem fontes que oferecem pesquisas originais claras, extraíveis e autoritativas. Organizações que entendem essa mudança e investem na criação de dados originais, pesquisas proprietárias e insights únicos posicionam-se para conquistar citações em múltiplas plataformas de IA simultaneamente, gerando reconhecimento e credibilidade junto a públicos que talvez nunca vejam os resultados tradicionais de busca.
Como Sistemas de IA Descobrem e Citam Dados
Diferentes plataformas de IA utilizam arquiteturas fundamentalmente distintas para descobrir e citar fontes, o que impacta diretamente como seus dados originais são exibidos e creditados. Entender esses mecanismos é essencial para otimizar a visibilidade do conteúdo no cenário da IA. A distinção entre síntese nativa do modelo (quando a IA gera respostas a partir de padrões de dados de treinamento) e geração aumentada por recuperação (quando a IA busca fontes ao vivo e sintetiza a partir dos resultados encontrados) explica por que algumas plataformas fornecem citações explícitas enquanto outras oferecem respostas sem atribuição. Plataformas que usam sistemas RAG podem rastrear suas respostas até fontes específicas, tornando a citação direta e rastreável. Já os sistemas nativos de modelo dependem de conhecimento probabilístico aprendido no treinamento, tornando a atribuição de fonte difícil ou impossível sem plugins ou integrações adicionais.
Plataforma de IA
Método de Citação
Prioridade da Fonte de Dados
Impacto na Visibilidade
ChatGPT
Nativo do modelo (padrão); citações com plugins/navegação ativada
Dados de treinamento + web ao vivo quando habilitado; prioriza fontes recentes e autoritativas quando a recuperação está ativa
Baixo sem plugins; moderado com busca ativada; citações aparecem no texto da resposta quando disponíveis
Perplexity
Recuperação em primeiro lugar, com citações numeradas inline
Resultados de busca na web ao vivo; prioriza fontes recentes e relevantes; enfatiza destaque da fonte
Alto; citações numeradas com links claros; fontes em primeiro lugar recebem tráfego desproporcional
Google Gemini
Integrado ao Google Search e Knowledge Graph
Páginas indexadas + entidades do Knowledge Graph; prioriza páginas com dados estruturados e sinais E-E-A-T
Alto; citações aparecem como links de fonte nos AI Overviews; dados estruturados aumentam probabilidade de citação
Claude
Nativo do modelo (padrão); busca na web será lançada em 2025
Dados de treinamento + busca seletiva na web ao vivo; prioriza fontes seguras e autoritativas
Moderado; citações aparecem quando busca na web está habilitada; ênfase em precisão e credibilidade da fonte
As implicações práticas são significativas: plataformas como Perplexity e Google Gemini, que buscam ativamente na web ao vivo, podem citar seu conteúdo imediatamente após a publicação, se ele atender aos padrões de qualidade e relevância. ChatGPT e Claude, que dependem mais dos dados de treinamento, podem levar mais tempo para incorporar sua pesquisa original, mas oferecem oportunidades de visibilidade diferentes via plugins e integrações. Para criadores de conteúdo, isso significa entender quais plataformas seu público-alvo utiliza e otimizar seus dados conforme necessário — seja garantindo conteúdo extraível e bem estruturado para a recuperação ao vivo da Perplexity, seja construindo sinais de autoridade que influenciem a inclusão nos dados de treinamento de sistemas nativos de modelo.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Dados estruturados evoluíram de uma tática opcional de SEO para uma necessidade estratégica na visibilidade em IA. Ao implementar schema markup usando o vocabulário Schema.org, você não está apenas ajudando o Google a entender seu conteúdo — está criando uma camada legível por máquina na qual os sistemas de IA podem fundamentar suas respostas de forma confiável. Essa camada de dados estruturados, muitas vezes chamada de “grafo de conhecimento de conteúdo”, define explicitamente entidades (pessoas, produtos, serviços, locais, organizações) e os relacionamentos entre elas, tornando muito mais fácil para sistemas de IA entenderem o que é sua marca, o que oferece e como deve ser interpretada. Segundo pesquisa recente da BrightEdge, páginas com schema markup robusto demonstraram taxas de citação mais altas nos AI Overviews do Google, sugerindo que dados estruturados influenciam diretamente a probabilidade de citação. O emergente Model Context Protocol (MCP), adotado tanto pela OpenAI quanto pelo Google DeepMind, representa a próxima evolução — funcionando essencialmente como uma API padronizada para conectar modelos de IA a fontes de dados estruturados. Ao implementar schema markup em escala, empresas criam uma base que reduz alucinações em respostas de IA, melhora o embasamento em conteúdo factual e torna seus dados mais descobertos em sistemas de recuperação. Isso é particularmente importante porque sistemas de IA treinados apenas em texto não estruturado frequentemente têm dificuldade com precisão; dados estruturados fornecem a clareza contextual que permite aos LLMs gerar respostas mais confiáveis e atribuíveis, citando sua pesquisa original com confiança.
Criando Dados Que Sistemas de IA Querem Citar
A estratégia mais eficaz para conquistar citações em IA é criar dados originais que sejam, por natureza, extraíveis, autoritativos e alinhados com a forma como sistemas de IA recuperam e sintetizam informações. Em vez de esperar que seu conteúdo existente seja citado, é preciso projetar deliberadamente produtos de dados que plataformas de IA possam facilmente descobrir, entender e referenciar. Aqui estão as principais estratégias para criar dados originais dignos de citação:
Realize pesquisas originais com metodologia transparente: Sistemas de IA priorizam fontes que demonstram práticas de pesquisa rigorosas. Publique estudos, pesquisas e análises com metodologias claramente documentadas, tamanhos de amostra e limitações. Ao mostrar seu trabalho, as plataformas de IA podem citar suas descobertas com confiança. Exemplos incluem benchmarks de mercado, estudos de comportamento do cliente, pesquisas de mercado e análises proprietárias que concorrentes não podem replicar.
Torne os dados extraíveis por formatos estruturados: Sistemas de IA preferem conteúdo organizado em tabelas, listas, matrizes comparativas e pares de perguntas e respostas em estilo FAQ, em vez de parágrafos densos. Uma tabela comparativa de recursos de concorrentes tem muito mais chance de ser citada do que a mesma informação em texto corrido. Use cabeçalhos, marcadores e hierarquias visuais que tornem os principais insights facilmente escaneáveis e recuperáveis por sistemas de IA.
Garanta atualidade dos dados e sinais de recência: Plataformas de IA, especialmente as que usam recuperação ao vivo, priorizam informações atuais. Inclua datas de publicação visíveis, registros de atualização e renovações regulares de conteúdo. Ao demonstrar que seus dados são atuais e mantidos, os sistemas de IA os consideram mais confiáveis do que fontes desatualizadas. Isso é especialmente crítico para dados sensíveis ao tempo, como preços, estatísticas e tendências de mercado.
Estabeleça autoridade do autor e da marca: Sistemas de IA avaliam a credibilidade da fonte antes de citar. Construa credenciais claras para os autores (inclua bios com expertise relevante), autoridade organizacional (backlinks, menções na mídia, reconhecimento no setor) e sinais de especialização no domínio. Quando sua marca é reconhecida como autoridade na categoria, sistemas de IA citam você com mais frequência e destaque.
Use definições claras de entidades e relacionamentos: Defina explicitamente as entidades-chave — sua empresa, produtos, serviços, membros da equipe e conceitos do setor. Utilize dados estruturados para estabelecer relacionamentos entre essas entidades. Quando um sistema de IA entende exatamente quem você é e como se relaciona com conceitos do setor, pode citá-lo com mais precisão e contexto.
Implemente atribuição e fontes adequadas: Se seus dados originais se baseiam em outras fontes, cite-as de forma transparente. Sistemas de IA reconhecem e recompensam fontes que reconhecem suas próprias fontes. Isso cria uma cadeia de atribuição que aumenta a confiança e a probabilidade de citação em todo o ecossistema.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Medindo e Otimizando para Citação em IA
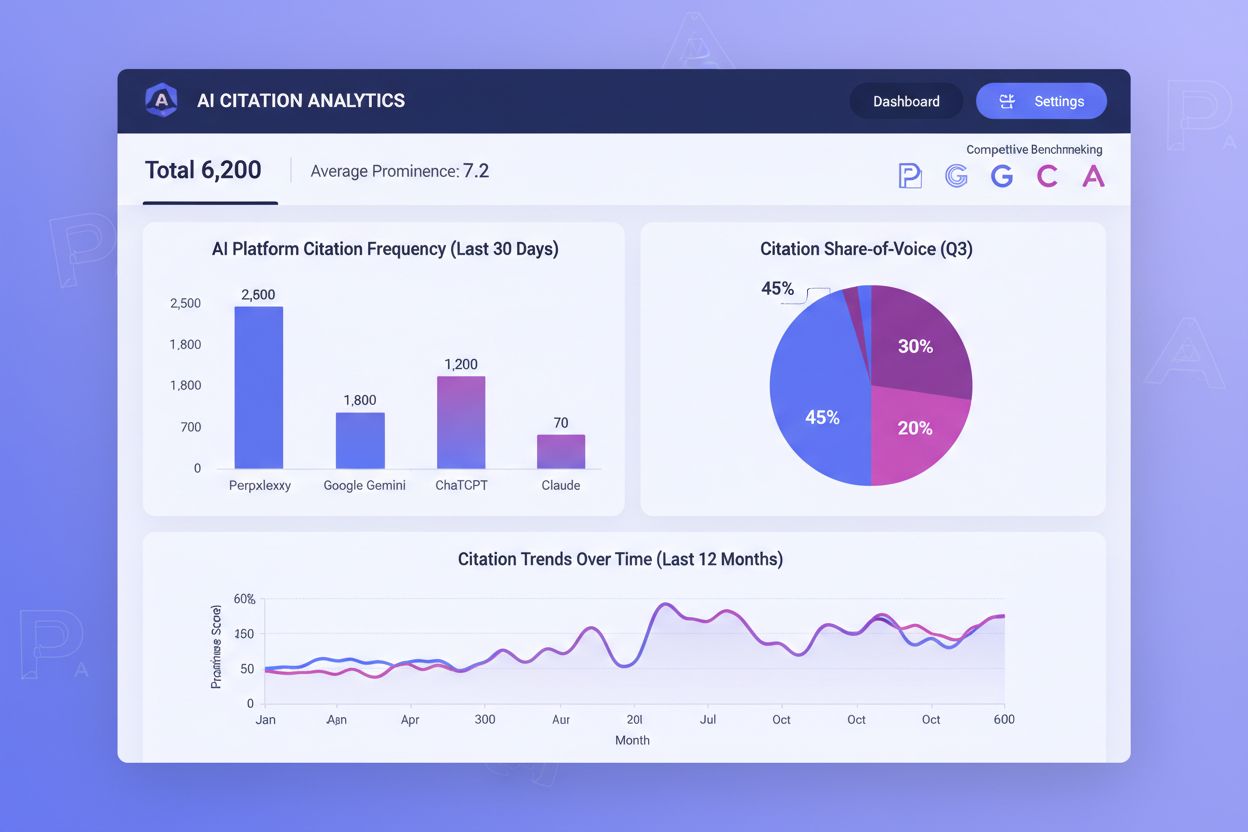
Acompanhar citações em IA tornou-se tão importante quanto monitorar rankings tradicionais de busca, mas a maioria das organizações carece de visibilidade sobre a frequência com que seu conteúdo é citado em plataformas de IA. Frequência de citação, destaque da citação e share-of-voice são as três principais métricas que determinam seu sucesso na descoberta mediada por IA. Frequência de citação mede quantas vezes seu conteúdo aparece em respostas de IA para suas consultas-alvo — se você é citado em 40% dos prompts relevantes enquanto concorrentes aparecem em 60%, há uma lacuna clara de otimização. O destaque da citação é ainda mais importante: uma citação em primeiro lugar na lista numerada da Perplexity gera visibilidade desproporcional em relação à quinta posição. Share-of-voice revela sua posição competitiva — se sua marca recebe citações em 25% das consultas que definem a categoria e seu principal concorrente em 50%, você está perdendo visibilidade significativa.
Ferramentas como AmICited.com surgiram como soluções essenciais para monitorar citações em IA em diferentes plataformas. Essas plataformas rastreiam quais de suas páginas ganham citações na Perplexity, Google AI Overviews, ChatGPT com busca e outros sistemas de IA, revelando qual conteúdo realmente impulsiona visibilidade mediada por IA. Ao monitorar padrões de citação ao longo do tempo, é possível identificar quais tipos, tópicos e formatos de conteúdo geram mais citações, replicando essas estratégias vencedoras. O benchmarking competitivo por meio dessas ferramentas mostra exatamente onde você está perdendo citações para concorrentes, possibilitando otimização direcionada. Os dados revelam se seus desafios de citação são universais entre todas as plataformas de IA ou específicos de certos sistemas — se você é citado frequentemente na Perplexity mas raramente no Google AI Overviews, sua estratégia de otimização deve ser diferente. Métricas ponderadas por posição reconhecem que citações em posição inicial entregam valor desproporcional; uma ferramenta que pondera citações em primeiro lugar mais do que posições inferiores oferece insights mais práticos do que contagens brutas. Ao tratar o acompanhamento de citações em IA como um componente central de sua estratégia de conteúdo, você pode otimizar continuamente seus dados originais para aumentar tanto a frequência quanto o destaque das citações, melhorando diretamente sua visibilidade em um cenário de busca orientado por IA.
Construindo uma Estratégia Sustentável de Dados para Visibilidade em IA
Criar dados originais que conquistam citações em IA não pode ser um projeto pontual — exige construir uma estratégia de dados sustentável e multifuncional que trate dados como um ativo estratégico que merece investimento e governança contínuos. Organizações bem-sucedidas em visibilidade em IA implementam processos estruturados para atualizações contínuas de dados, garantindo que pesquisas originais permaneçam atuais e relevantes. Isso significa estabelecer ciclos regulares de atualização para conjuntos de dados-chave, atualizar estatísticas conforme surgem novas informações e manter os sinais de recência que sistemas de IA usam para avaliar credibilidade da fonte. Além das atualizações de conteúdo, organizações de sucesso alinham sua estratégia de dados entre marketing, SEO, conteúdo, produto e equipes de dados por meio de governança de entidades — definições e taxonomias compartilhadas que asseguram representação consistente e precisa de sua marca, produtos e conceitos do setor em todos os pontos de contato.
A abordagem mais sofisticada trata dados estruturados e grafos de conhecimento de conteúdo como infraestrutura corporativa. Em vez de implementar schema markup página a página, empresas líderes constroem grafos de conhecimento de conteúdo abrangentes que conectam todas as entidades, tópicos e relacionamentos em suas propriedades digitais. Isso demanda capacidade técnica — ferramentas e processos para gerenciar schema markup em escala — e alinhamento organizacional em torno de padrões de qualidade de dados. Quando estruturada corretamente, essa infraestrutura serve a dois propósitos: melhora a visibilidade externa em IA e viabiliza iniciativas internas de IA. Segundo o AI Mandates for the Enterprise Survey da Gartner de 2024, disponibilidade e qualidade dos dados são a principal barreira para o sucesso em IA; ao investir em dados estruturados e governança de entidades, você resolve simultaneamente desafios de visibilidade externa e capacitação interna em IA. As organizações que lideram em visibilidade em IA tratam a criação de dados originais não como uma tática de marketing, mas como uma capacidade fundamental do negócio, com recursos dedicados, responsabilidade clara e otimização contínua baseada em acompanhamento de citações e benchmarking competitivo.
Perguntas frequentes
Qual é a diferença entre dados originais e conteúdo comum para citação por IA?
Dados originais referem-se a pesquisas proprietárias, conjuntos de dados únicos e descobertas primárias que você mesmo criou ou descobriu. Os sistemas de IA priorizam dados originais porque oferecem informações autoritativas e extraíveis que podem citar com confiança. Conteúdo comum geralmente sintetiza informações existentes, tornando-se menos valioso para citação por IA. Dados originais tornam-se a base para a visibilidade em IA porque plataformas como Perplexity e Google Gemini buscam ativamente e citam fontes que oferecem insights e pesquisas únicas.
Como diferentes plataformas de IA descobrem e citam meus dados originais?
Diferentes plataformas de IA usam mecanismos de descoberta distintos. Perplexity e Google Gemini utilizam geração aumentada por recuperação (RAG), o que significa que pesquisam a web ao vivo e podem citar seu conteúdo imediatamente após a publicação. ChatGPT e Claude dependem mais de dados de treinamento, então seu conteúdo pode demorar mais para ser incorporado, mas oferece oportunidades de visibilidade diferentes. Todas as plataformas se beneficiam de dados estruturados (schema markup) que tornam seus dados legíveis por máquina e mais fáceis de entender, aumentando a probabilidade de citação em todos os sistemas.
Qual o papel dos dados estruturados na citação por IA?
Dados estruturados usando o vocabulário Schema.org criam uma camada legível por máquina na qual os sistemas de IA podem fundamentar suas respostas de forma confiável. Ao implementar schema markup, você está definindo explicitamente entidades (sua empresa, produtos, serviços) e seus relacionamentos, tornando muito mais fácil para sistemas de IA entenderem e citarem seu conteúdo com precisão. Pesquisas mostram que páginas com schema markup robusto recebem taxas de citação mais altas nos AI Overviews. Dados estruturados também reduzem alucinações ao fornecer informações claras e factuais para referência dos sistemas de IA.
Quais tipos de dados originais têm maior probabilidade de serem citados pela IA?
Sistemas de IA citam com mais frequência pesquisas originais com metodologia transparente, conjuntos de dados proprietários, benchmarks de mercado, estudos de comportamento do cliente, análises de mercado e insights únicos que concorrentes não conseguem replicar. Dados apresentados em formatos extraíveis — tabelas, matrizes comparativas, listas e perguntas e respostas em estilo FAQ — recebem mais citações do que as mesmas informações em parágrafos densos. Dados atuais, com datas de publicação visíveis e atualizações regulares, têm prioridade sobre informações desatualizadas. Sinais de autoridade como credenciais de autores e reconhecimento organizacional também aumentam a probabilidade de citação.
Como posso medir se meus dados originais estão sendo citados por sistemas de IA?
Ferramentas como AmICited.com rastreiam citações em IA em várias plataformas, mostrando com que frequência seu conteúdo aparece em respostas do ChatGPT, Perplexity, Google AI Overviews e Claude. Essas ferramentas medem frequência de citação (quantas vezes você é citado), destaque da citação (posição na resposta) e share-of-voice (suas citações em comparação com concorrentes). Ao acompanhar essas métricas, você pode identificar quais tipos de conteúdo e tópicos geram mais citações, otimizando sua estratégia de dados de acordo. Métricas ponderadas por posição reconhecem que citações em primeiro lugar entregam mais valor do que posições inferiores.
Qual a diferença entre frequência de citação e destaque da citação?
Frequência de citação mede com que frequência seu conteúdo é citado em respostas de IA para suas consultas-alvo — se você é citado em 40% dos prompts relevantes, essa é sua frequência de citação. Destaque da citação mede onde sua citação aparece na resposta — uma citação em primeiro lugar na lista numerada da Perplexity gera muito mais visibilidade do que uma citação na quinta posição. Ambas as métricas importam para visibilidade em IA, mas o destaque geralmente importa mais porque os usuários tendem a clicar ou interagir mais com as primeiras citações. Uma otimização eficaz requer melhorar ambas as métricas simultaneamente.
Com que frequência devo atualizar meus dados originais para manter valor de citação em IA?
Dados originais devem ser atualizados em um cronograma regular compatível com o ritmo de mudanças do seu setor. Para áreas de rápida evolução como tecnologia ou finanças, atualizações mensais ou trimestrais podem ser necessárias. Para setores mais lentos, atualizações anuais podem ser suficientes. O essencial é manter sinais de atualidade visíveis — datas de publicação, registros de atualização e indicadores de renovação — que mostrem aos sistemas de IA que seus dados são atuais e confiáveis. Atualizações regulares também aumentam suas chances de ser citado por sistemas baseados em recuperação, como Perplexity, que priorizam informações recentes. Trate a manutenção de dados como uma responsabilidade operacional contínua, não um projeto pontual.
Posso usar o AmICited.com para rastrear citações de concorrentes?
Sim, o AmICited.com inclui recursos de benchmarking competitivo que mostram seu desempenho de citação em relação a concorrentes definidos. Você pode ver quais concorrentes são citados com mais frequência, em posições mais destacadas e em quais plataformas de IA. Essa inteligência competitiva revela exatamente onde você está perdendo citações e quais estratégias de otimização podem ajudá-lo a ganhar espaço. Entendendo o cenário competitivo de citações, você pode priorizar a criação e otimização de dados para as oportunidades de maior impacto, garantindo que seus dados originais recebam a visibilidade que merecem.
Monitore Suas Citações em IA Hoje
Acompanhe com que frequência seus dados originais são citados no ChatGPT, Perplexity, Google AI Overviews e outras plataformas de IA. Obtenha insights práticos para otimizar seu conteúdo visando máxima visibilidade em IA.
Por Que Pesquisa Original É Importante para Visibilidade e Citações em IA
Descubra por que criar pesquisa original é fundamental para visibilidade em IA. Saiba como a pesquisa original ajuda sua marca a ser citada em respostas geradas...
PR Orientado por Dados: Criando Pesquisas Que a IA Quer Citar
Aprenda como criar pesquisas originais e conteúdos de PR orientados por dados que sistemas de IA citam ativamente. Descubra os 5 atributos de conteúdos dignos d...
Pesquisa Original: O Impulso de 30-40% na Visibilidade para Citações em IA
Descubra como pesquisas originais e dados de primeira mão impulsionam um aumento de 30-40% na visibilidade em citações de IA em ChatGPT, Perplexity e Google AI ...
14 min de leitura
Consentimento de Cookies Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.