A prática estratégica de permitir ou bloquear seletivamente crawlers de IA para controlar como o conteúdo é usado para treinamento ou recuperação em tempo real. Isso envolve o uso de arquivos robots.txt, controles em nível de servidor e ferramentas de monitoramento para gerenciar quais sistemas de IA podem acessar seu conteúdo e para quais finalidades.
Gerenciamento de Crawlers de IA
A prática estratégica de permitir ou bloquear seletivamente crawlers de IA para controlar como o conteúdo é usado para treinamento ou recuperação em tempo real. Isso envolve o uso de arquivos robots.txt, controles em nível de servidor e ferramentas de monitoramento para gerenciar quais sistemas de IA podem acessar seu conteúdo e para quais finalidades.
O que é Gerenciamento de Crawlers de IA?
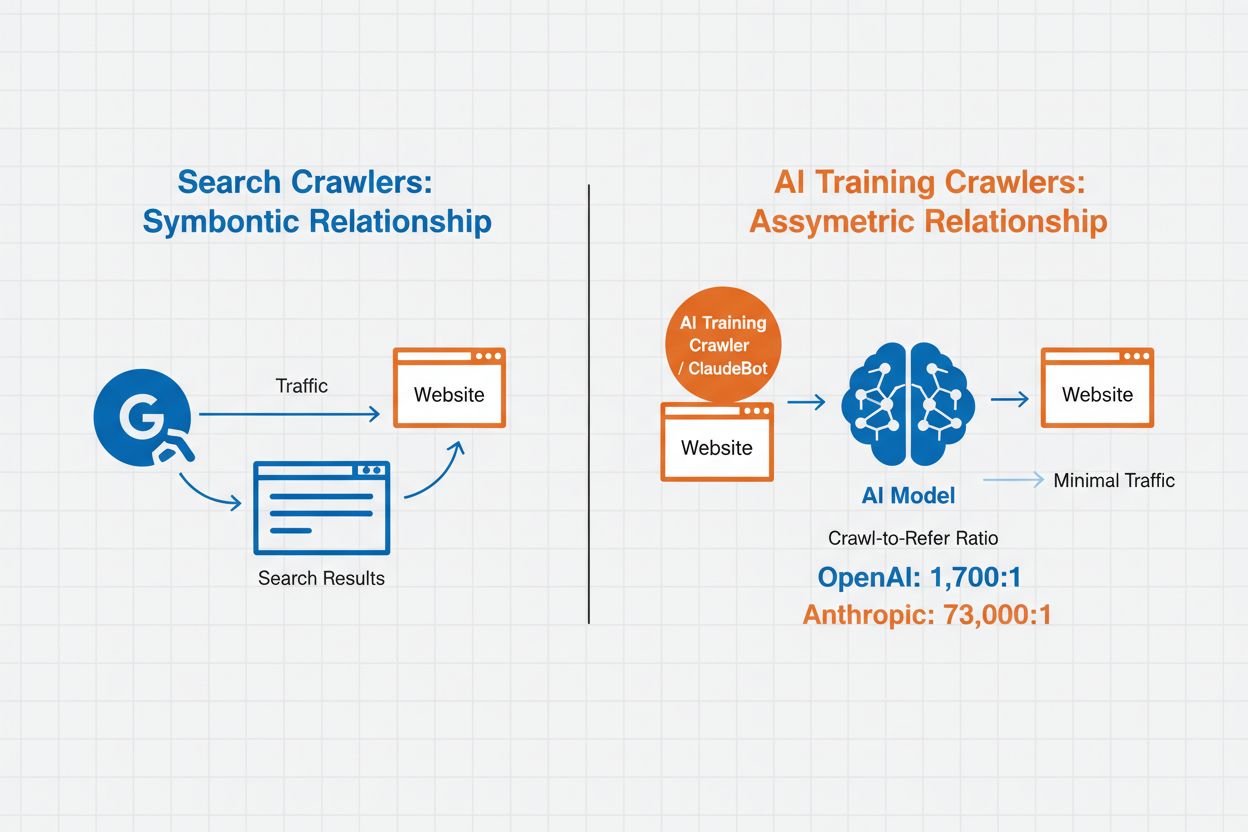
Gerenciamento de Crawlers de IA refere-se à prática de controlar e monitorar como sistemas de inteligência artificial acessam e utilizam o conteúdo de sites para fins de treinamento e busca. Diferentemente dos crawlers tradicionais de motores de busca, que indexam conteúdo para resultados de pesquisa na web, crawlers de IA são projetados especificamente para coletar dados para treinar grandes modelos de linguagem ou alimentar recursos de busca com IA. A escala dessa atividade varia dramaticamente entre organizações—os crawlers da OpenAI operam com uma razão de 1.700:1 entre acesso e referência, ou seja, acessam o conteúdo 1.700 vezes para cada referência que fornecem, enquanto a razão da Anthropic chega a 73.000:1, destacando o enorme consumo de dados necessário para treinar sistemas modernos de IA. Um gerenciamento eficaz de crawlers permite que proprietários de sites decidam se seu conteúdo contribui para o treinamento de IA, aparece em resultados de busca de IA ou permanece protegido contra acesso automatizado.
Tipos de Crawlers de IA
Crawlers de IA se dividem em três categorias distintas com base em seu propósito e padrões de uso de dados. Crawlers de treinamento são projetados para coletar dados para desenvolvimento de modelos de aprendizado de máquina, consumindo grandes volumes de conteúdo para aprimorar as capacidades da IA. Crawlers de busca e citação indexam conteúdo para alimentar recursos de busca com IA e fornecer atribuição em respostas geradas por IA, permitindo que usuários descubram seu conteúdo por meio de interfaces de IA. Crawlers acionados por usuário operam sob demanda quando usuários interagem com ferramentas de IA, como quando um usuário do ChatGPT faz upload de um documento ou solicita a análise de uma página específica. Compreender essas categorias ajuda você a tomar decisões informadas sobre quais crawlers permitir ou bloquear de acordo com sua estratégia de conteúdo e objetivos de negócio.
Tipo de Crawler
Propósito
Exemplos
Usa Dados de Treinamento
Treinamento
Desenvolvimento e aprimoramento de modelos
GPTBot, ClaudeBot
Sim
Busca/Citação
Resultados de busca com IA e atribuição
Google-Extended, OAI-SearchBot, PerplexityBot
Variável
Acionado por Usuário
Análise de conteúdo sob demanda
ChatGPT-User, Meta-ExternalAgent, Amazonbot
Específico ao contexto
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
O gerenciamento de crawlers de IA impacta diretamente o tráfego, a receita e o valor do seu conteúdo. Quando crawlers consomem seu conteúdo sem compensação, você perde a oportunidade de se beneficiar desse tráfego por meio de referências, impressões de anúncios ou engajamento de usuários. Sites já relataram reduções significativas de tráfego, pois usuários encontram respostas diretamente em respostas geradas por IA, em vez de clicar no link para a fonte original, cortando efetivamente o tráfego de referência e a receita publicitária associada. Além das implicações financeiras, há considerações legais e éticas importantes—seu conteúdo representa propriedade intelectual e você tem o direito de controlar como ele é utilizado e se recebe atribuição ou compensação. Adicionalmente, permitir acesso irrestrito de crawlers pode aumentar a carga do servidor e custos de banda, especialmente devido a crawlers com taxas de acesso agressivas que não respeitam diretivas de limitação de taxa.
Robots.txt e Controles Técnicos
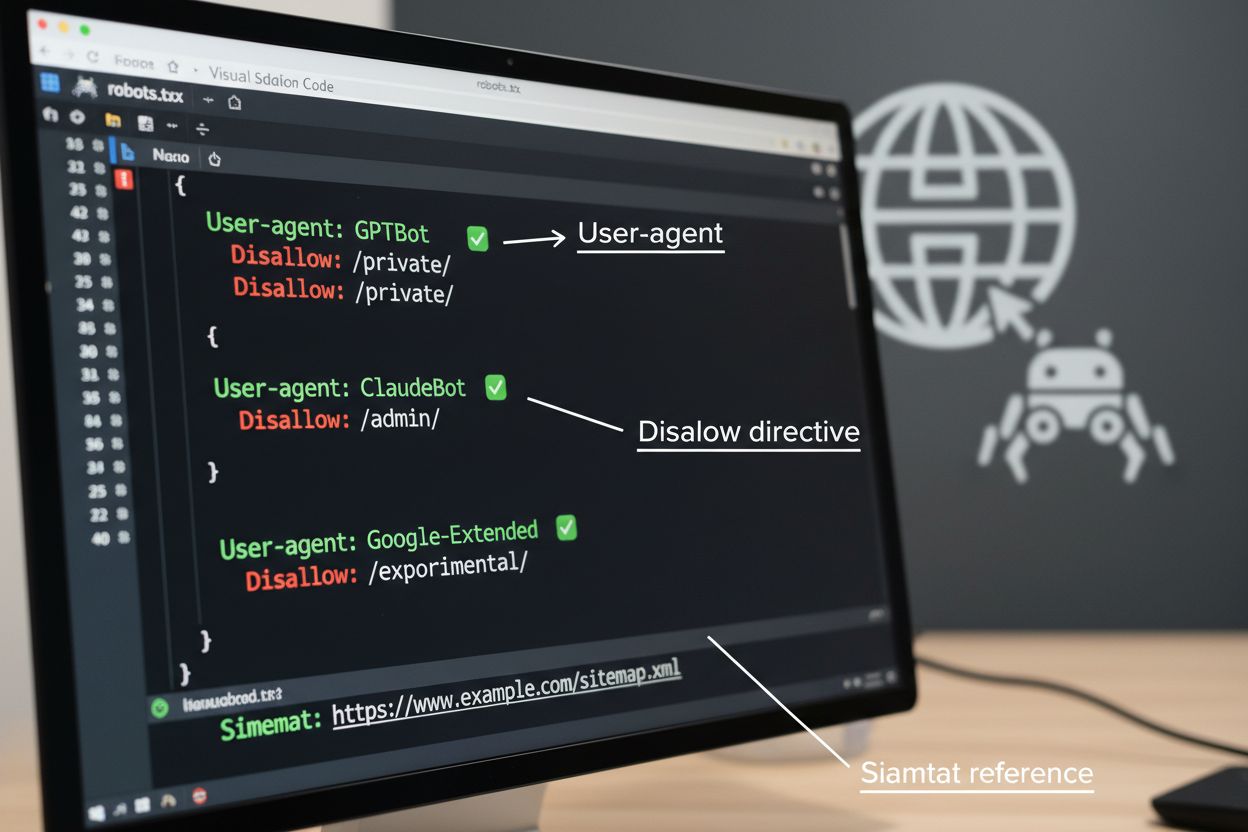
O robots.txt é a ferramenta fundamental para gerenciar o acesso de crawlers, posicionado no diretório raiz do seu site para comunicar preferências de rastreamento a agentes automatizados. Esse arquivo utiliza diretivas User-agent para direcionar crawlers específicos e regras Disallow ou Allow para permitir ou restringir o acesso a determinados caminhos e recursos. Entretanto, o robots.txt possui limitações importantes—é um padrão voluntário que depende da conformidade do crawler, e bots maliciosos ou mal projetados podem ignorá-lo totalmente. Além disso, o robots.txt não impede crawlers de acessar conteúdo público; ele apenas solicita que respeitem suas preferências. Por essas razões, o robots.txt deve fazer parte de uma abordagem em camadas ao gerenciamento de crawlers, e não ser sua única defesa.
# Bloquear crawlers de treinamento de IA
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
# Permitir motores de busca
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Regra padrão para outros crawlers
User-agent: *
Allow: /
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Métodos Avançados de Controle
Além do robots.txt, diversas técnicas avançadas oferecem reforço e controle mais granular sobre o acesso de crawlers. Esses métodos atuam em diferentes camadas da sua infraestrutura e podem ser combinados para proteção abrangente:
Regras de .htaccess: Diretivas em nível de servidor que podem bloquear user agents ou faixas de IP específicas antes do conteúdo ser servido
Lista branca/negra de IPs: Restringe o acesso com base nos endereços IP associados a crawlers de IA conhecidos, embora exija manter listas de IPs atualizadas
Soluções WAF da Cloudflare: Use regras do Web Application Firewall para identificar e bloquear tráfego de crawlers com base em padrões de comportamento e assinaturas
Cabeçalhos HTTP (X-Robots-Tag): Envie diretivas de crawler diretamente em headers de resposta, fornecendo controle por página ou recurso que é mais difícil de ser ignorado que robots.txt
Limitação de taxa: Implemente limites agressivos de taxa para tornar a coleta de dados em grande escala economicamente inviável
Fingerprinting de bots: Analise padrões de requisição, cabeçalhos e comportamento para identificar crawlers sofisticados que mascaram sua identidade
Equilibrando Proteção e Visibilidade
A decisão de bloquear crawlers de IA envolve importantes compensações entre proteção de conteúdo e visibilidade. Bloquear todos os crawlers de IA elimina a possibilidade de seu conteúdo aparecer em resultados de busca de IA, resumos baseados em IA ou ser citado por ferramentas de IA—o que pode reduzir a visibilidade para usuários que descobrem conteúdo por esses canais emergentes. Por outro lado, permitir acesso irrestrito significa que seu conteúdo alimenta o treinamento de IA sem compensação e pode reduzir o tráfego de referência, já que usuários obtêm respostas diretamente por sistemas de IA. Uma abordagem estratégica envolve o bloqueio seletivo: permitir crawlers de citação como OAI-SearchBot e PerplexityBot, que geram tráfego de referência, enquanto bloqueia crawlers de treinamento como GPTBot e ClaudeBot, que consomem dados sem atribuição. Você também pode considerar permitir o Google-Extended para manter visibilidade no Google AI Overviews, que pode gerar tráfego significativo, enquanto bloqueia crawlers de treinamento de concorrentes. A estratégia ideal depende do tipo de conteúdo, modelo de negócio e público—sites de notícias e publishers podem priorizar bloqueio, enquanto criadores de conteúdo educacional podem se beneficiar de maior visibilidade em IA.
Monitoramento e Aplicação
Implementar controles de crawlers só é eficaz se você verificar se realmente seguem suas diretivas. Análise de logs de servidor é o principal método para monitorar a atividade de crawlers—examine seus logs de acesso em busca de strings de User-Agent e padrões de requisição para identificar quais crawlers estão acessando seu site e se respeitam as regras do robots.txt. Muitos crawlers afirmam conformidade mas continuam acessando caminhos bloqueados, tornando o monitoramento contínuo essencial. Ferramentas como o Cloudflare Radar oferecem visibilidade em tempo real sobre padrões de tráfego e ajudam a identificar comportamentos suspeitos ou não conformes. Configure alertas automáticos para tentativas de acesso a recursos bloqueados e audite periodicamente seus logs para detectar novos crawlers ou padrões que possam indicar tentativas de evasão.
Boas Práticas e Implementação
Implementar um gerenciamento eficaz de crawlers de IA exige uma abordagem sistemática que equilibre proteção e visibilidade estratégica. Siga estes oito passos para estabelecer uma estratégia abrangente de gerenciamento de crawlers:
Audite o acesso atual: Analise os logs do servidor para identificar quais crawlers de IA acessam seu site, a frequência e os recursos mais visados
Defina sua política: Decida quais crawlers estão alinhados com os objetivos do seu negócio—considere crawlers de treinamento vs. busca, impacto no tráfego e valor do conteúdo
Documente suas decisões: Crie documentação clara da sua política de crawlers e do racional para cada decisão para referência futura e alinhamento da equipe
Implemente controles: Aplique regras no robots.txt, cabeçalhos HTTP e controles avançados como limitação de taxa ou bloqueio de IP conforme sua política
Monitore a conformidade: Revise regularmente os logs do servidor e use ferramentas de monitoramento para verificar se os crawlers cumprem suas diretivas
Configure alertas: Programe alertas automáticos para acessos de crawlers não conformes ou tentativas de burlar seus controles
Revise trimestralmente: Reavalie sua estratégia de gerenciamento de crawlers a cada trimestre, à medida que surgem novos crawlers e suas necessidades de negócio mudam
Atualize conforme surgem novos crawlers: Mantenha-se informado sobre novos crawlers de IA e atualize seus controles de forma proativa, não reativa
AmICited.com: Monitore Suas Referências em IA
O AmICited.com oferece uma plataforma especializada para monitorar como sistemas de IA referenciam e utilizam seu conteúdo em diferentes modelos e aplicações. O serviço proporciona rastreamento em tempo real de suas citações em respostas geradas por IA, ajudando você a entender quais crawlers usam seu conteúdo ativamente e com que frequência seu trabalho aparece em respostas de IA. Ao analisar padrões de crawlers e dados de citação, o AmICited.com permite decisões baseadas em dados para sua estratégia de gerenciamento de crawlers—você pode ver exatamente quais crawlers geram valor por meio de citações e referências versus aqueles que consomem conteúdo sem atribuição. Essa inteligência transforma o gerenciamento de crawlers de uma prática defensiva em uma ferramenta estratégica para otimizar a visibilidade e o impacto do seu conteúdo na web movida por IA.
Perguntas frequentes
Qual é a diferença entre bloquear crawlers de treinamento de IA e crawlers de busca?
Crawlers de treinamento como GPTBot e ClaudeBot coletam conteúdo para construir conjuntos de dados para o desenvolvimento de grandes modelos de linguagem, consumindo seu conteúdo sem fornecer tráfego de referência. Crawlers de busca como OAI-SearchBot e PerplexityBot indexam conteúdo para resultados de busca com IA e podem enviar visitantes de volta ao seu site por meio de citações. Bloquear crawlers de treinamento protege seu conteúdo de ser incorporado em modelos de IA, enquanto bloquear crawlers de busca pode reduzir sua visibilidade em plataformas de descoberta baseadas em IA.
Bloquear crawlers de IA prejudica meu ranqueamento de SEO?
Não. Bloquear crawlers de treinamento de IA como GPTBot, ClaudeBot e CCBot não afeta seus ranqueamentos no Google ou Bing. Motores de busca tradicionais usam crawlers diferentes (Googlebot, Bingbot) que operam independentemente dos bots de treinamento de IA. Só bloqueie crawlers de busca tradicionais se quiser desaparecer completamente dos resultados de busca, o que prejudicaria seu SEO.
Como saber quais crawlers estão acessando meu site?
Examine os logs de acesso do seu servidor para identificar as strings de User-Agent dos crawlers. Procure por entradas contendo 'bot', 'crawler' ou 'spider' no campo User-Agent. Ferramentas como o Cloudflare Radar fornecem visibilidade em tempo real sobre quais crawlers de IA estão acessando seu site e seus padrões de tráfego. Você também pode usar plataformas de análise que diferenciam tráfego de bots de visitantes humanos.
Crawlers de IA podem ignorar diretivas do robots.txt?
Sim. robots.txt é um padrão de orientação que depende da conformidade do crawler—não é obrigatório. Crawlers bem-comportados de grandes empresas como OpenAI, Anthropic e Google geralmente respeitam as diretivas do robots.txt, mas alguns crawlers as ignoram completamente. Para proteção mais forte, implemente bloqueio em nível de servidor via .htaccess, regras de firewall ou restrições baseadas em IP.
Devo bloquear todos os crawlers de IA ou usar bloqueio seletivo?
Isso depende das prioridades do seu negócio. Bloquear todos os crawlers de treinamento protege seu conteúdo de ser incorporado em modelos de IA enquanto potencialmente permite crawlers de busca que podem gerar tráfego de referência. Muitos publishers usam bloqueio seletivo que mira crawlers de treinamento enquanto permite crawlers de busca e de citação. Considere o tipo de conteúdo, fontes de tráfego e modelo de monetização ao decidir sua estratégia.
Com que frequência devo atualizar minha política de gerenciamento de crawlers?
Revise e atualize sua política de gerenciamento de crawlers ao menos trimestralmente. Novos crawlers de IA surgem regularmente e crawlers existentes atualizam seus user agents sem aviso. Acompanhe recursos como o projeto ai.robots.txt no GitHub para listas mantidas pela comunidade e verifique seus logs de servidor mensalmente para identificar novos crawlers acessando seu site.
Qual é o impacto dos crawlers de IA no tráfego e receita do meu site?
Crawlers de IA podem impactar significativamente seu tráfego e receita. Quando usuários obtêm respostas diretamente de sistemas de IA ao invés de visitar seu site, você perde tráfego de referência e impressões de anúncios associadas. Pesquisas mostram razões de crawl para referência tão altas quanto 73.000:1 para algumas plataformas de IA, o que significa que elas acessam seu conteúdo milhares de vezes para cada visitante enviado de volta. Bloquear crawlers de treinamento pode proteger seu tráfego, enquanto permitir crawlers de busca pode fornecer alguns benefícios de referência.
Como posso verificar se minha configuração do robots.txt está funcionando?
Verifique os logs do seu servidor para ver se crawlers bloqueados ainda aparecem nos logs de acesso. Use ferramentas de teste como o validador de robots.txt do Google Search Console ou o Robots.txt Tester da Merkle para validar sua configuração. Acesse seu arquivo robots.txt diretamente em seusite.com/robots.txt para verificar se o conteúdo está correto. Monitore seus logs regularmente para identificar crawlers que deveriam ser bloqueados, mas ainda aparecem.
Monitore Como Sistemas de IA Referenciam Seu Conteúdo
O AmICited.com rastreia em tempo real referências de IA à sua marca em ChatGPT, Perplexity, Google AI Overviews e outros sistemas de IA. Tome decisões baseadas em dados sobre sua estratégia de gerenciamento de crawlers.
Impacto dos Crawlers de IA nos Recursos do Servidor: O Que Esperar
Saiba como crawlers de IA impactam recursos do servidor, banda e desempenho. Descubra estatísticas reais, estratégias de mitigação e soluções de infraestrutura ...
Você Deve Bloquear ou Permitir Crawlers de IA? Estrutura para Tomada de Decisão
Aprenda como tomar decisões estratégicas sobre o bloqueio de crawlers de IA. Avalie tipo de conteúdo, fontes de tráfego, modelos de receita e posição competitiv...
Como Identificar Crawlers de IA em Logs de Servidor: Guia Completo de Detecção
Aprenda como identificar e monitorar crawlers de IA como GPTBot, PerplexityBot e ClaudeBot em seus logs de servidor. Descubra strings de user-agent, métodos de ...
9 min de leitura
Consentimento de Cookies Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.