
Kanonické URL adresy a AI: Prevencia problémov s duplicitným obsahom
Zistite, ako kanonické URL adresy predchádzajú problémom s duplicitným obsahom v AI vyhľadávacích systémoch. Objavte najlepšie postupy implementácie kanoník na ...
6 min čítania
Logika deduplikácie AI označuje automatizované procesy a algoritmy, ktoré systémy umelej inteligencie využívajú na identifikáciu, analýzu a odstránenie redundantných alebo duplicitných informácií z viacerých zdrojov. Tieto systémy používajú strojové učenie, spracovanie prirodzeného jazyka a techniky porovnávania podobnosti na rozpoznávanie identického alebo vysoko podobného obsahu naprieč rozličnými dátovými úložiskami, čím zabezpečujú kvalitu údajov, znižujú náklady na ukladanie a zlepšujú presnosť rozhodovania.
Logika deduplikácie AI označuje automatizované procesy a algoritmy, ktoré systémy umelej inteligencie využívajú na identifikáciu, analýzu a odstránenie redundantných alebo duplicitných informácií z viacerých zdrojov. Tieto systémy používajú strojové učenie, spracovanie prirodzeného jazyka a techniky porovnávania podobnosti na rozpoznávanie identického alebo vysoko podobného obsahu naprieč rozličnými dátovými úložiskami, čím zabezpečujú kvalitu údajov, znižujú náklady na ukladanie a zlepšujú presnosť rozhodovania.
Logika deduplikácie AI je sofistikovaný algoritmický proces, ktorý identifikuje a odstraňuje duplicitné alebo takmer duplicitné záznamy z veľkých dátových súborov pomocou umelej inteligencie a techník strojového učenia. Táto technológia automaticky rozpoznáva situácie, keď viaceré záznamy predstavujú tú istú entitu—či už ide o osobu, produkt, dokument alebo informáciu—a to aj napriek rozdielom vo formáte, pravopise alebo prezentácii. Hlavným cieľom deduplikácie je udržiavať integritu dát a predchádzať redundancii, ktorá môže skresliť analýzy, zvyšovať náklady na úložisko a negatívne ovplyvniť presnosť rozhodovania. V dnešnom svete riadenom údajmi, kde organizácie denne spracúvajú milióny záznamov, sa efektívna deduplikácia stala nevyhnutnou pre prevádzkovú efektivitu a spoľahlivé poznatky.
Deduplikácia AI využíva viacero komplementárnych techník na identifikáciu a zoskupovanie podobných záznamov s pozoruhodnou presnosťou. Proces začína analýzou atribútov dát—ako sú mená, adresy, e-mailové adresy a ďalšie identifikátory—a ich porovnávaním so stanovenými prahmi podobnosti. Moderné systémy deduplikácie používajú kombináciu fonetického porovnávania, algoritmov podobnosti reťazcov a sémantickej analýzy na zachytenie duplikátov, ktoré by tradičné pravidlové systémy mohli prehliadnuť. Systém priraďuje potenciálnym zhode skóre podobnosti a zoskupuje záznamy, ktoré prekročia nastavený prah, do skupín predstavujúcich tú istú entitu. Používatelia majú kontrolu nad úrovňou inkluzivity deduplikácie, čo im umožňuje prispôsobiť citlivosť podľa konkrétneho prípadu použitia a tolerancie k falošným pozitívam.
| Metóda | Popis | Najlepšie využitie |
|---|---|---|
| Fonetická podobnosť | Zoskupuje reťazce, ktoré znejú rovnako (napr. “Smith” vs “Smyth”) | Variácie mien, fonetické zámene |
| Pravopisná podobnosť | Zoskupuje reťazce s podobným pravopisom | Preklepy, drobné pravopisné rozdiely |
| TFIDF podobnosť | Používa algoritmus term frequency-inverse document frequency | Všeobecné porovnávanie textov, podobnosť dokumentov |
Deduplikačný engine spracováva záznamy vo viacerých cykloch, najskôr identifikuje zjavné zhody a následne postupne skúma jemnejšie variácie. Tento vrstvený prístup zaručuje komplexné pokrytie a zároveň zachováva výpočtovú efektivitu aj pri spracovaní dátových súborov s miliónmi záznamov.
Moderná deduplikácia AI využíva vektorové reprezentácie a sémantickú analýzu na pochopenie významu dát, nielen porovnávanie povrchových znakov. Spracovanie prirodzeného jazyka (NLP) umožňuje systémom chápať kontext a zámer, vďaka čomu rozpoznajú, že “Robert”, “Bob” a “Rob” označujú tú istú osobu, hoci majú rôzne formy. Fuzzy matching algoritmy počítajú editačnú vzdialenosť medzi reťazcami a identifikujú záznamy, ktoré sa líšia len o pár znakov—čo je kľúčové pri zachytávaní preklepov a prepisovacích chýb. Systém analyzuje aj metadáta ako časové pečiatky, dátumy vytvorenia a históriu úprav, aby poskytol dodatočné signály istoty pri určovaní, či sú záznamy duplikáty. Pokročilé implementácie zahŕňajú modely strojového učenia trénované na označených dátových súboroch, ktoré postupne zlepšujú presnosť s rastúcim objemom spracovaných dát a spätnou väzbou na deduplikačné rozhodnutia.
Logika deduplikácie AI sa stala nepostrádateľnou vo všetkých sektoroch, ktoré spravujú rozsiahle dátové operácie. Organizácie využívajú túto technológiu na udržiavanie čistých, spoľahlivých dátových súborov, ktoré podporujú presné analýzy a informované rozhodovanie. Praktické aplikácie pokrývajú množstvo kľúčových podnikových funkcií:

Tieto aplikácie ukazujú, ako deduplikácia priamo ovplyvňuje dodržiavanie predpisov, prevenciu podvodov a prevádzkovú integritu v rôznych odvetviach.
Finančné a prevádzkové prínosy deduplikácie AI sú výrazné a merateľné. Organizácie môžu výrazne znížiť náklady na úložisko odstránením redundantných dát, pričom niektoré implementácie dosahujú 20-40% zníženie požiadaviek na úložisko. Zlepšená kvalita dát priamo vedie k lepšej analytike a rozhodovaniu, pretože analýzy založené na čistých dátach prinášajú spoľahlivejšie poznatky a prognózy. Výskumy ukazujú, že dátoví analytici trávia približne 80% času prípravou dát, pričom duplicitné záznamy sú významným faktorom tejto záťaže—automatizovaná deduplikácia im uvoľňuje čas na hodnotnejšiu prácu. Štúdie uvádzajú, že 10-30% záznamov v typických databázach sú duplicity, čo je významný zdroj neefektivity a chýb. Okrem znižovania nákladov deduplikácia posilňuje dodržiavanie predpisov a regulačných požiadaviek zabezpečením presného vedenia záznamov a zabránením duplicitným podaniam, ktoré by mohli vyvolať audity alebo pokuty. Prevádzková efektivita sa prejavuje aj v rýchlejšom vyhľadávaní, nižšom výpočtovom zaťažení a lepšej spoľahlivosti systémov.
Napriek svojej vyspelosti nie je deduplikácia AI bez výziev a obmedzení, ktoré musia organizácie starostlivo riadiť. Falošné pozitíva—nesprávne identifikovanie odlišných záznamov ako duplikátov—môžu viesť k strate údajov alebo zlúčeniu záznamov, ktoré by mali ostať oddelené, zatiaľ čo falošné negatíva spôsobia, že skutočné duplicity uniknú detekcii. Deduplikácia je exponenciálne náročnejšia pri viacformátových dátach rozptýlených v rôznych systémoch, jazykoch a štruktúrach, pričom každý má svoje vlastné formátovacie konvencie a kódovanie. Obavy o súkromie a bezpečnosť vznikajú, keď deduplikácia vyžaduje analýzu citlivých osobných údajov, čo si vyžaduje silné šifrovanie a prístupové kontroly na ochranu dát počas porovnávania. Presnosť deduplikačných systémov je zásadne limitovaná kvalitou vstupných dát; ak sú vstupné dáta nekvalitné, ani najpokročilejšie algoritmy nedokážu dosiahnuť spoľahlivé výsledky.
Deduplikácia AI sa stala kľúčovou súčasťou moderných platforiem na monitorovanie odpovedí AI a vyhľadávacích systémov, ktoré agregujú informácie z viacerých zdrojov. Keď AI systémy syntetizujú odpovede z množstva dokumentov a zdrojov, deduplikácia zabezpečí, že tie isté informácie nie sú započítané viackrát, čím by sa umelo zvýšila dôveryhodnosť a skreslili rebríčky relevantnosti. Pripísanie zdroja je zmysluplnejšie, keď deduplikácia odstráni redundantné zdroje, čo používateľom umožňuje vidieť skutočnú rozmanitosť dôkazov podporujúcich odpoveď. Platformy ako AmICited.com využívajú deduplikačnú logiku na poskytovanie transparentného a presného sledovania zdrojov identifikovaním prípadov, keď viacero zdrojov obsahuje v podstate zhodné informácie, a ich vhodným zlúčením. Takto sa zabráni tomu, aby odpovede AI pôsobili, že majú širšiu podporu, než je skutočná, a zachová sa integrita pripisovania zdrojov a dôveryhodnosť odpovedí. Filtrovaním duplicitných zdrojov deduplikácia zlepšuje kvalitu výsledkov vyhľadávania AI a zabezpečuje, že používatelia dostanú skutočne rôznorodé pohľady, nie len variácie tých istých informácií opakovaných naprieč zdrojmi. Táto technológia napokon posilňuje dôveru v AI systémy tým, že poskytuje čistejšie, úprimnejšie zobrazenia dôkazov, na ktorých sú AI odpovede postavené.
Deduplikácia AI a kompresia dát obe znižujú objem dát, ale pracujú odlišne. Deduplikácia identifikuje a odstraňuje presné alebo takmer identické záznamy, pričom zachováva iba jednu inštanciu a ostatné nahrádza odkazmi. Kompresia dát naopak kóduje dáta efektívnejšie bez odstránenia duplicitných údajov. Deduplikácia funguje na makro úrovni (celé súbory alebo záznamy), zatiaľ čo kompresia na mikro úrovni (jednotlivé bity a bajty). Pre organizácie s veľkým množstvom duplicitných dát poskytuje deduplikácia zvyčajne väčšie úspory na úložisku.
AI využíva viacero sofistikovaných techník na zachytenie nepresných duplikátov. Fonetické algoritmy rozpoznávajú mená, ktoré znejú podobne (napr. 'Smith' vs 'Smyth'). Fuzzy matching vypočítava editačnú vzdialenosť, aby našiel záznamy, ktoré sa líšia len o pár znakov. Vektorové reprezentácie prevádzajú text na matematické vyjadrenia zachytávajúce sémantický význam, čo umožňuje systému rozpoznať parafrázovaný obsah. Modely strojového učenia trénované na označených dátach sa učia vzory toho, čo v konkrétnych kontextoch tvorí duplikát. Tieto techniky spolupracujú, aby identifikovali duplicity aj napriek rozdielom v pravopise, formáte alebo prezentácii.
Deduplikácia môže výrazne znížiť náklady na úložisko odstránením redundantných dát. Organizácie bežne dosahujú 20-40% zníženie požiadaviek na úložisko po zavedení efektívnej deduplikácie. Tieto úspory sa časom kumulujú, keďže nové dáta sa priebežne deduplikujú. Okrem priameho zníženia nákladov na úložisko deduplikácia znižuje aj náklady spojené so správou dát, zálohovacími operáciami a údržbou systémov. Pre veľké podniky spracovávajúce milióny záznamov môžu tieto úspory predstavovať stovky tisíc eur ročne, vďaka čomu je deduplikácia investíciou s vysokou návratnosťou.
Áno, moderné systémy deduplikácie AI môžu fungovať naprieč rôznymi formátmi súborov, hoci to vyžaduje sofistikovanejšie spracovanie. Systém najskôr musí normalizovať dáta z rôznych formátov (PDF, Word dokumenty, tabuľky, databázy atď.) do porovnateľnej štruktúry. Pokročilé implementácie používajú optické rozpoznávanie znakov (OCR) pre skenované dokumenty a špecifické parsre pre jednotlivé formáty na extrakciu zmysluplného obsahu. Presnosť deduplikácie však môže závisieť od zložitosti formátu a kvality dát. Organizácie dosahujú najlepšie výsledky, keď sa deduplikácia aplikuje na štruktúrované dáta v konzistentných formátoch, no deduplikácia naprieč formátmi je s modernými AI technikami čoraz viac možná.
Deduplikácia zlepšuje výsledky vyhľadávania AI tým, že zabezpečuje, aby rebríčky relevantnosti odrážali skutočnú rozmanitosť zdrojov, nie len variácie tých istých informácií. Keď viaceré zdroje obsahujú identický alebo takmer identický obsah, deduplikácia ich konsoliduje, čím bráni umelému navýšeniu skóre dôveryhodnosti. Používateľom to poskytuje čistejšie a úprimnejšie zobrazenie dôkazov podporujúcich odpovede generované AI. Deduplikácia tiež zlepšuje výkon vyhľadávania znížením množstva dát, ktoré systém musí spracovať, čo umožňuje rýchlejšie odpovede na dotazy. Filtrovaním redundantných zdrojov sa AI systémy môžu sústrediť na skutočne rozmanité pohľady a informácie, čím nakoniec poskytujú kvalitnejšie a dôveryhodnejšie výsledky.
Falošné pozitíva nastávajú, keď deduplikácia nesprávne identifikuje odlišné záznamy ako duplicity a zlúči ich. Napríklad zlúčenie záznamov pre 'John Smith' a 'Jane Smith', ktorí sú rôzne osoby, ale majú rovnaké priezvisko. Falošné pozitíva sú problémové, pretože spôsobujú trvalú stratu dát—po zlúčení je obnovenie pôvodných odlišných informácií ťažké alebo nemožné. V kritických oblastiach ako zdravotníctvo alebo finančné služby môžu mať falošné pozitíva vážne následky, vrátane nesprávnych lekárskych záznamov alebo podvodných transakcií. Organizácie musia starostlivo kalibrovať citlivosť deduplikácie, aby minimalizovali falošné pozitíva, často radšej akceptujú niektoré falošné negatíva (nezachytené duplicity) ako bezpečnejší kompromis.
Deduplikácia je kľúčová pre platformy monitorovania obsahu AI ako AmICited, ktoré sledujú, ako AI systémy odkazujú na značky a zdroje. Pri monitorovaní odpovedí AI naprieč viacerými platformami (GPTs, Perplexity, Google AI) deduplikácia zabraňuje tomu, aby bol ten istý zdroj započítaný viackrát, ak sa objaví v rôznych AI systémoch alebo formátoch. To zabezpečuje presné pripísanie a bráni nadhodnoteniu metrík viditeľnosti. Deduplikácia tiež pomáha odhaliť, keď AI systémy čerpajú z obmedzeného množstva zdrojov aj napriek zdanlivej rozmanitosti dôkazov. Konsolidovaním duplicitných zdrojov poskytujú monitorovacie platformy jasnejší pohľad na to, ktoré jedinečné zdroje skutočne ovplyvňujú odpovede AI.
Metadáta—informačné údaje o dátach, ako dátumy vytvorenia, časy úprav, informácie o autorovi a vlastnosti súboru—zohrávajú kľúčovú úlohu pri detekcii duplikátov. Metadáta pomáhajú určovať životný cyklus záznamov, odhaľujú, kedy boli dokumenty vytvorené, upravené alebo otvorené. Tieto časové informácie pomáhajú rozlišovať medzi legitímnymi verziami vyvíjajúcich sa dokumentov a skutočnými duplikátmi. Informácie o autorovi a oddelení poskytujú kontext o pôvode a účele záznamu. Vzory prístupu naznačujú, či sú dokumenty aktívne používané alebo zastarané. Pokročilé deduplikačné systémy integrujú analýzu metadát s obsahovou analýzou a využívajú obidve signály na presnejšie určenie duplikátov a na identifikáciu, ktorá verzia duplikátu by mala byť zachovaná ako autoritatívny zdroj.
AmICited sleduje, ako systémy AI ako GPTs, Perplexity a Google AI odkazujú na vašu značku naprieč viacerými zdrojmi. Zabezpečte presné pripísanie zdrojov a zabráňte tomu, aby duplicitný obsah skreslil vašu viditeľnosť v AI.
Zistite, ako kanonické URL adresy predchádzajú problémom s duplicitným obsahom v AI vyhľadávacích systémoch. Objavte najlepšie postupy implementácie kanoník na ...

Diskusia komunity o tom, ako AI systémy pracujú s duplicitným obsahom inak ako tradičné vyhľadávače. SEO odborníci zdieľajú postrehy o jedinečnosti obsahu pre v...
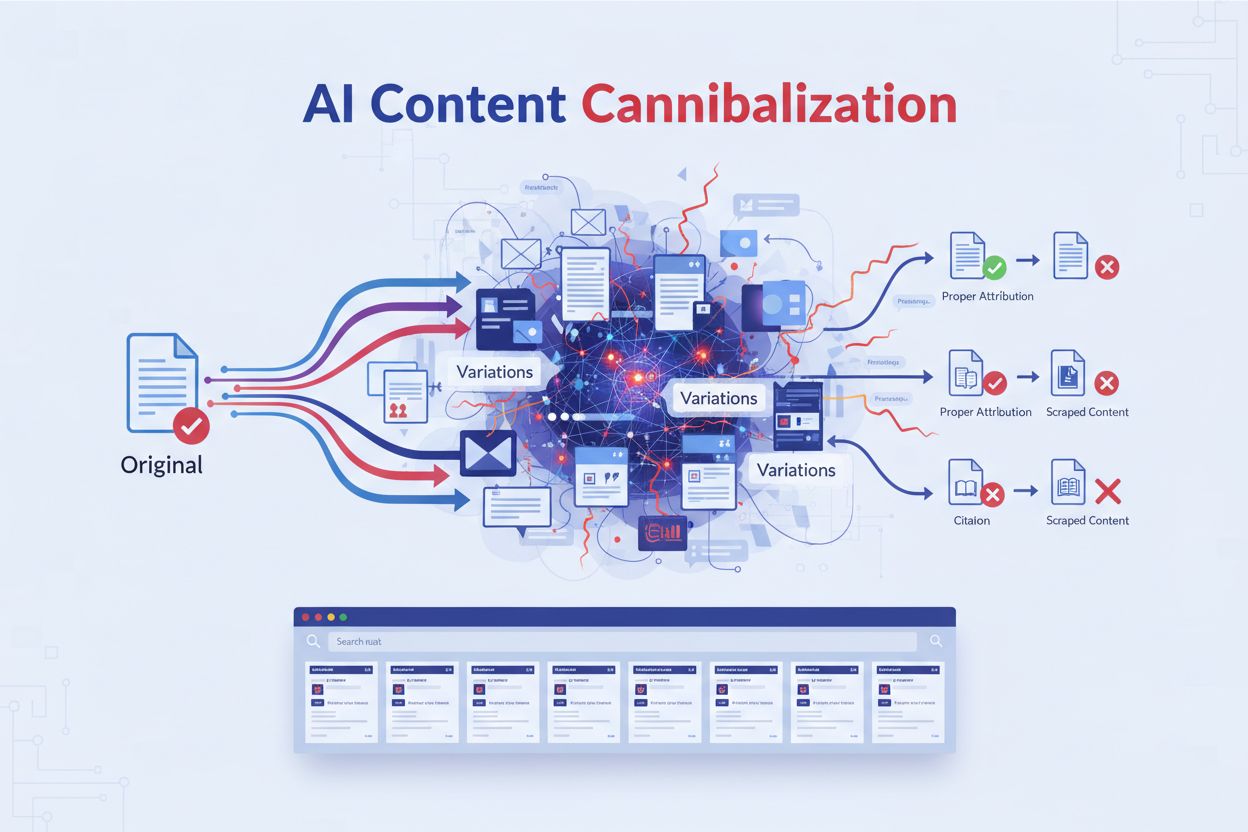
Zistite, čo je kanibalizácia AI obsahu, ako sa líši od duplicitného obsahu, prečo škodí pozíciám a aké stratégie ochránia váš obsah pred skenovaním a prepísaním...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.