Logika deduplikace pomocí AI označuje automatizované procesy a algoritmy, které systémy umělé inteligence používají k identifikaci, analýze a odstranění redundantních nebo duplicitních informací z více zdrojů. Tyto systémy využívají strojové učení, zpracování přirozeného jazyka a techniky porovnávání podobnosti, aby rozpoznaly totožný nebo velmi podobný obsah v různorodých datových úložištích, čímž zajišťují kvalitu dat, snižují náklady na úložiště a zvyšují přesnost rozhodování.
Logika deduplikace pomocí AI
Logika deduplikace pomocí AI označuje automatizované procesy a algoritmy, které systémy umělé inteligence používají k identifikaci, analýze a odstranění redundantních nebo duplicitních informací z více zdrojů. Tyto systémy využívají strojové učení, zpracování přirozeného jazyka a techniky porovnávání podobnosti, aby rozpoznaly totožný nebo velmi podobný obsah v různorodých datových úložištích, čímž zajišťují kvalitu dat, snižují náklady na úložiště a zvyšují přesnost rozhodování.
Co je logika deduplikace pomocí AI?
Logika deduplikace pomocí AI je sofistikovaný algoritmický proces, který pomocí umělé inteligence a strojového učení identifikuje a eliminuje duplicitní nebo téměř duplicitní záznamy z velkých datových sad. Tato technologie automaticky rozpozná, kdy více položek představuje stejnou entitu—ať už jde o osobu, produkt, dokument či informaci—a to i přes rozdíly ve formátování, pravopisu nebo prezentaci. Hlavním cílem deduplikace je udržet integritu dat a zabránit redundanci, která může zkreslit analýzu, zvýšit náklady na úložiště a snížit přesnost rozhodování. V dnešním světě řízeném daty, kde organizace denně zpracovávají miliony záznamů, se efektivní deduplikace stala nezbytnou pro provozní efektivitu a spolehlivé poznatky.
Jak deduplikace pomocí AI funguje
Deduplikace pomocí AI využívá několik vzájemně se doplňujících technik k identifikaci a seskupení podobných záznamů s pozoruhodnou přesností. Proces začíná analýzou datových atributů—jako jsou jména, adresy, e-maily a další identifikátory—a jejich porovnáním podle stanovených prahů podobnosti. Moderní deduplikační systémy kombinují fonetické porovnání, algoritmy podobnosti řetězců a sémantickou analýzu k zachycení duplikátů, které by tradiční pravidlové systémy mohly přehlédnout. Systém přiřazuje potenciálním shodám skóre podobnosti a záznamy překračující nastavený práh shlukuje do skupin představujících stejnou entitu. Uživatelé mají kontrolu nad úrovní zahrnutí deduplikace a mohou tak upravit citlivost dle konkrétního použití a tolerance k falešným pozitivům.
Metoda
Popis
Nejvhodnější pro
Fonetická podobnost
Seskupuje řetězce znějící podobně (např. “Smith” vs “Smyth”)
Variace jmen, fonetické záměny
Pravopisná podobnost
Seskupuje řetězce podobné v pravopisu
Překlepy, drobné pravopisné rozdíly
TFIDF podobnost
Využívá algoritmus term frequency-inverse document frequency
Obecné porovnání textu, podobnost dokumentů
Deduplikační engine zpracovává záznamy v několika průchodech—nejprve identifikuje zjevné shody a následně zkoumá jemnější odchylky. Tento vrstevnatý přístup zajišťuje důkladné pokrytí při zachování výpočetní efektivity i u datových sad obsahujících miliony záznamů.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Moderní deduplikace pomocí AI využívá vektorové embeddingy a sémantickou analýzu k pochopení významu dat, nejen k porovnávání jejich povrchových znaků. Zpracování přirozeného jazyka (NLP) umožňuje systémům chápat kontext a záměr, takže rozpoznají, že “Robert”, “Bob” a “Rob” jsou různé formy téhož jména. Fuzzy algoritmy počítají editační vzdálenost mezi řetězci a identifikují záznamy lišící se jen několika znaky—což je klíčové pro zachycení překlepů a chyb při přepisu. Systém také analyzuje metadata jako časová razítka, data vytvoření a historii úprav, aby získal další signály při určování duplicit. Pokročilé implementace zahrnují modely strojového učení trénované na označených datech, které svou přesnost zlepšují s přibývajícím množstvím zpracovaných dat a zpětnou vazbou k rozhodnutím o deduplikaci.
Reálné aplikace napříč odvětvími
Logika deduplikace pomocí AI se stala nepostradatelnou téměř ve všech odvětvích, která spravují rozsáhlé datové operace. Organizace využívají tuto technologii k udržení čistých a spolehlivých datových sad, které zajišťují přesné analýzy a informované rozhodování. Praktické aplikace pokrývají řadu klíčových podnikových funkcí:
Žádosti o půjčky a pojištění—detekce duplicitních žadatelů a prevence podvodů
CRM systémy—identifikace duplicitních zákaznických záznamů pro jednotný pohled na zákazníka
Zdravotnické systémy—odhalování duplicitních pacientských záznamů pro přesnou zdravotní historii a prevenci chyb v medikaci
E-commerce platformy—identifikace duplicitních produktových položek pro udržení integrity katalogu
Veřejné služby—označování duplicitních registrací voličů a žádostí o dávky k prevenci podvodů a zneužití
Tyto aplikace ukazují, jak deduplikace přímo ovlivňuje dodržování předpisů, prevenci podvodů a provozní integritu v různých odvětvích.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Přínos pro podnikání a úspora nákladů
Finanční a provozní přínosy deduplikace pomocí AI jsou podstatné a měřitelné. Organizace mohou výrazně snížit náklady na úložiště odstraněním redundantních dat—a některé implementace dosahují 20–40% snížení požadavků na kapacitu. Vyšší kvalita dat se přímo promítá do lepší analytiky a rozhodování, protože analýza vycházející z čistých dat přináší spolehlivější poznatky a predikce. Výzkumy ukazují, že datoví analytici tráví přibližně 80 % času přípravou dat, přičemž duplicitní záznamy jsou hlavním zdrojem této zátěže—automatizace deduplikace jim vrací čas na hodnotnější práci. Studie dokládají, že 10–30 % záznamů v typických databázích jsou duplicity, což je významný zdroj neefektivity a chyb. Kromě úspory nákladů deduplikace posiluje soulad s předpisy tím, že zajišťuje správnou evidenci a brání duplicitním podáním, která by mohla vést k auditům nebo sankcím. Provozní efektivita se projevuje i v rychlejším vyhledávání, nižší zátěži systémů a vyšší spolehlivosti.
Výzvy a omezení
Navzdory své vyspělosti má deduplikace pomocí AI výzvy a omezení, které musí organizace pečlivě řešit. Falešně pozitivní nálezy—tedy chybné označení odlišných záznamů za duplicity—mohou vést ke ztrátě dat nebo sloučení záznamů, které by měly zůstat oddělené, zatímco falešně negativní umožňují skutečným duplicitám uniknout detekci. Složitost deduplikace roste exponenciálně při práci s multi-formátovými daty napříč různými systémy, jazyky a strukturami, z nichž každý má své vlastní formátovací konvence a kódování. Otázky ochrany soukromí a bezpečnosti vyvstávají, pokud deduplikace vyžaduje analýzu citlivých osobních údajů, což vyžaduje robustní šifrování a řízení přístupu během procesu párování. Přesnost deduplikačních systémů je stále zásadně omezena kvalitou vstupních dat; pokud jsou data nekvalitní, žádný algoritmus nedokáže zajistit bezchybné výsledky.
Deduplikace pomocí AI v moderních AI platformách
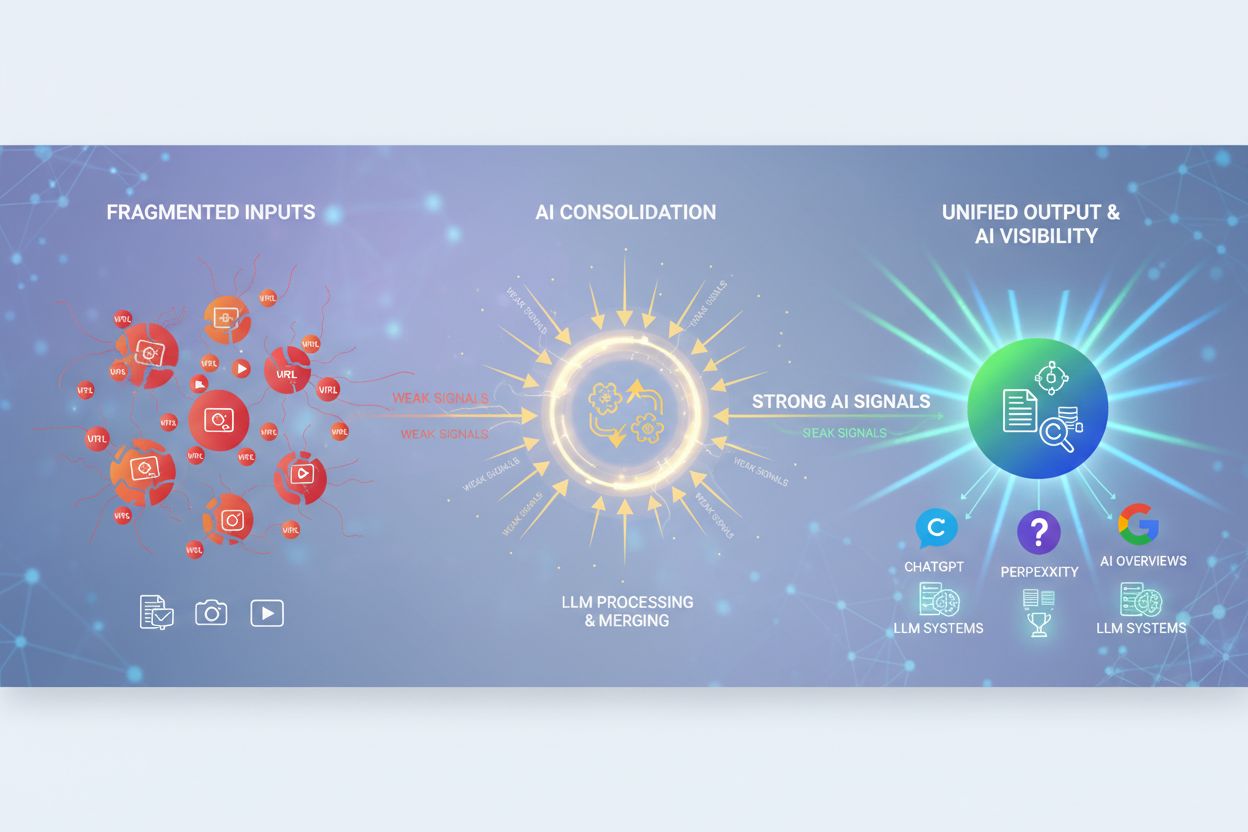
Deduplikace pomocí AI se stala klíčovou součástí moderních platformem pro monitorování odpovědí AI a vyhledávacích systémů, které agregují informace z více zdrojů. Když AI systémy syntetizují odpovědi z mnoha dokumentů a zdrojů, deduplikace zajišťuje, že stejná informace nebude započítána vícekrát, což by uměle navyšovalo skóre důvěryhodnosti a zkreslovalo hodnocení relevance. Přiřazení zdroje je smysluplnější, když deduplikace odstraní redundantní zdroje a uživatelé tak vidí skutečnou různorodost důkazů podporujících odpověď. Platformy jako AmICited.com využívají deduplikační logiku k transparentnímu a přesnému sledování zdrojů identifikací případů, kdy více zdrojů obsahuje v podstatě totožné informace, a jejich vhodnou konsolidací. Tím se zabrání tomu, aby odpovědi AI působily, že mají širší podporu, než ve skutečnosti mají, a zachovává se integrita přiřazení zdrojů a důvěryhodnost odpovědí. Odstraněním duplicitních zdrojů deduplikace zlepšuje kvalitu výsledků vyhledávání pomocí AI a zajišťuje, že uživatelé získávají skutečně rozmanité pohledy místo různých variant týchž informací opakovaných v několika zdrojích. Tato technologie nakonec posiluje důvěru v AI systémy tím, že nabízí čistší a poctivější obraz o důkazech, na nichž jsou odpovědi AI založeny.
Často kladené otázky
Deduplikace pomocí AI a komprese dat oba snižují objem dat, ale fungují odlišně. Deduplikace identifikuje a odstraňuje přesně nebo téměř duplicitní záznamy, ponechává pouze jednu instanci a ostatní nahrazuje odkazy. Komprese dat naopak zakóduje data efektivněji, aniž by odstraňovala duplicity. Deduplikace pracuje na makro úrovni (celé soubory či záznamy), zatímco komprese na mikro úrovni (jednotlivé bity a bajty). Pro organizace s velkým množstvím duplicitních dat zpravidla deduplikace přináší větší úspory úložiště.
AI používá několik sofistikovaných technik k zachycení ne zcela shodných duplikátů. Fonematické algoritmy rozpoznají podobně znějící jména (např. "Smith" vs "Smyth"). Fuzzy porovnání vypočítává editační vzdálenost a najde záznamy lišící se jen několika znaky. Vektorové embeddingy převádějí text do matematických reprezentací, které zachycují sémantický význam, což systému umožňuje rozpoznat parafrázovaný obsah. Modely strojového učení trénované na označených datech se učí, co je v konkrétním kontextu duplikát. Tyto techniky spolupracují na identifikaci duplikátů i přes rozdíly v pravopisu, formátování či prezentaci.
Deduplikace může výrazně snížit náklady na úložiště odstraněním redundantních dat. Organizace obvykle dosahují 20–40% snížení požadavků na úložiště po zavedení efektivní deduplikace. Tyto úspory se sčítají v průběhu času, jak se nová data průběžně deduplikují. Kromě přímé úspory nákladů na úložiště deduplikace snižuje i výdaje spojené se správou dat, zálohováním a údržbou systémů. U velkých podniků zpracovávajících miliony záznamů mohou tyto úspory ročně činit statisíce dolarů, což z deduplikace dělá investici s vysokou návratností.
Ano, moderní systémy deduplikace pomocí AI mohou fungovat napříč různými formáty souborů, i když to vyžaduje sofistikovanější zpracování. Systém musí nejprve normalizovat data z různých formátů (PDF, Word, tabulky, databáze atd.) do srovnatelné struktury. Pokročilé implementace používají optické rozpoznávání znaků (OCR) pro skenované dokumenty a specifické parsování pro extrakci smysluplného obsahu. Přesnost deduplikace se však může lišit podle složitosti formátu a kvality dat. Nejlepších výsledků obvykle organizace dosahují při aplikaci deduplikace na strukturovaná data v konzistentních formátech, ale deduplikace napříč formáty je s moderními AI technikami stále více možná.
Deduplikace zlepšuje výsledky vyhledávání pomocí AI tím, že zajišťuje, aby hodnocení relevance odráželo skutečnou rozmanitost zdrojů, a ne jen varianty týchž informací. Pokud více zdrojů obsahuje totožný nebo téměř totožný obsah, deduplikace je konsoliduje a zabrání umělému navýšení skóre důvěryhodnosti. Uživatelé tak dostávají čistší a pravdivější obraz o důkazech podporujících odpovědi generované AI. Deduplikace také zvyšuje výkon vyhledávání snížením objemu dat, které systém musí zpracovávat, což umožňuje rychlejší odpovědi na dotazy. Odstraněním redundantních zdrojů se systémy AI mohou zaměřit na skutečně různorodé pohledy a informace, což vede ke kvalitnějším a důvěryhodnějším výsledkům.
Falešně pozitivní nálezy nastávají, když deduplikace nesprávně identifikuje odlišné záznamy jako duplicity a sloučí je. Například sloučení záznamů 'John Smith' a 'Jane Smith', kteří jsou různí lidé, ale sdílí příjmení. Falešné pozitivy jsou problematické, protože vedou k trvalé ztrátě dat—po sloučení je obtížné či nemožné obnovit původní odlišné informace. V kritických aplikacích, jako je zdravotnictví nebo finanční služby, mohou mít falešná sloučení vážné důsledky, včetně chybných zdravotních záznamů nebo podvodných transakcí. Organizace musí pečlivě kalibrovat citlivost deduplikace, aby minimalizovaly falešně pozitivní nálezy, a často raději přijímají některé falešně negativní (opomenuté duplicity) jako bezpečnější kompromis.
Deduplikace je zásadní pro platformy monitorování obsahu pomocí AI, jako je AmICited, které sledují, jak AI systémy odkazují na značky a zdroje. Při sledování odpovědí AI napříč více platformami (GPTs, Perplexity, Google AI) deduplikace zabrání tomu, aby byl stejný zdroj počítán vícekrát, pokud se objeví v různých systémech nebo formátech. Tím je zajištěno přesné přiřazení zdrojů a brání se nadhodnocení metrik viditelnosti. Deduplikace také pomáhá rozpoznat, když AI systémy čerpají z omezené sady zdrojů navzdory zdánlivé různorodosti důkazů. Konsolidací duplicitních zdrojů poskytují monitorovací platformy jasnější pohled na to, které unikátní zdroje skutečně ovlivňují odpovědi AI.
Metadata—informační údaje o datech, jako jsou data vytvoření, časy změn, informace o autorovi a vlastnosti souborů—hrají klíčovou roli při detekci duplicit. Metadata pomáhají určit životní cyklus záznamů a ukazují, kdy byly dokumenty vytvořeny, aktualizovány nebo otevřeny. Tyto časové informace pomáhají rozlišit mezi legitimními verzemi vyvíjených dokumentů a skutečnými duplikáty. Informace o autorovi a příslušnosti k oddělení dávají kontext o původu a účelu záznamu. Vzorce přístupu ukazují, zda jsou dokumenty aktivně používány nebo jsou zastaralé. Pokročilé systémy deduplikace integrují analýzu metadat s analýzou obsahu a využívají oba signály k přesnějšímu rozhodování o duplicitách a k určení, která verze duplikátu má být uchována jako autoritativní zdroj.
Sledujte, jak AI odkazuje na vaši značku
AmICited sleduje, jak systémy umělé inteligence jako GPTs, Perplexity a Google AI odkazují na vaši značku v různých zdrojích. Zajistěte přesné přiřazení zdrojů a zabraňte tomu, aby duplicitní obsah zkresloval vaši viditelnost v AI.
Jak AI vyhledávače zacházejí s duplicitním obsahem? Je to jiné než u Googlu?
Diskuze komunity o tom, jak AI systémy zacházejí s duplicitním obsahem odlišně než tradiční vyhledávače. SEO profesionálové sdílí postřehy k jedinečnosti obsahu...
Zjistěte, co je konsolidace AI obsahu a jak slučování podobného obsahu posiluje signály viditelnosti pro ChatGPT, Perplexity a Google AI Overviews. Objevte stra...
Kanonické URL a AI: Prevence problémů s duplicitním obsahem
Zjistěte, jak kanonické URL předcházejí problémům s duplicitním obsahem v AI vyhledávačích. Objevte osvědčené postupy pro implementaci kanonických URL, které zl...
6 min čtení
Souhlas s cookies Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.