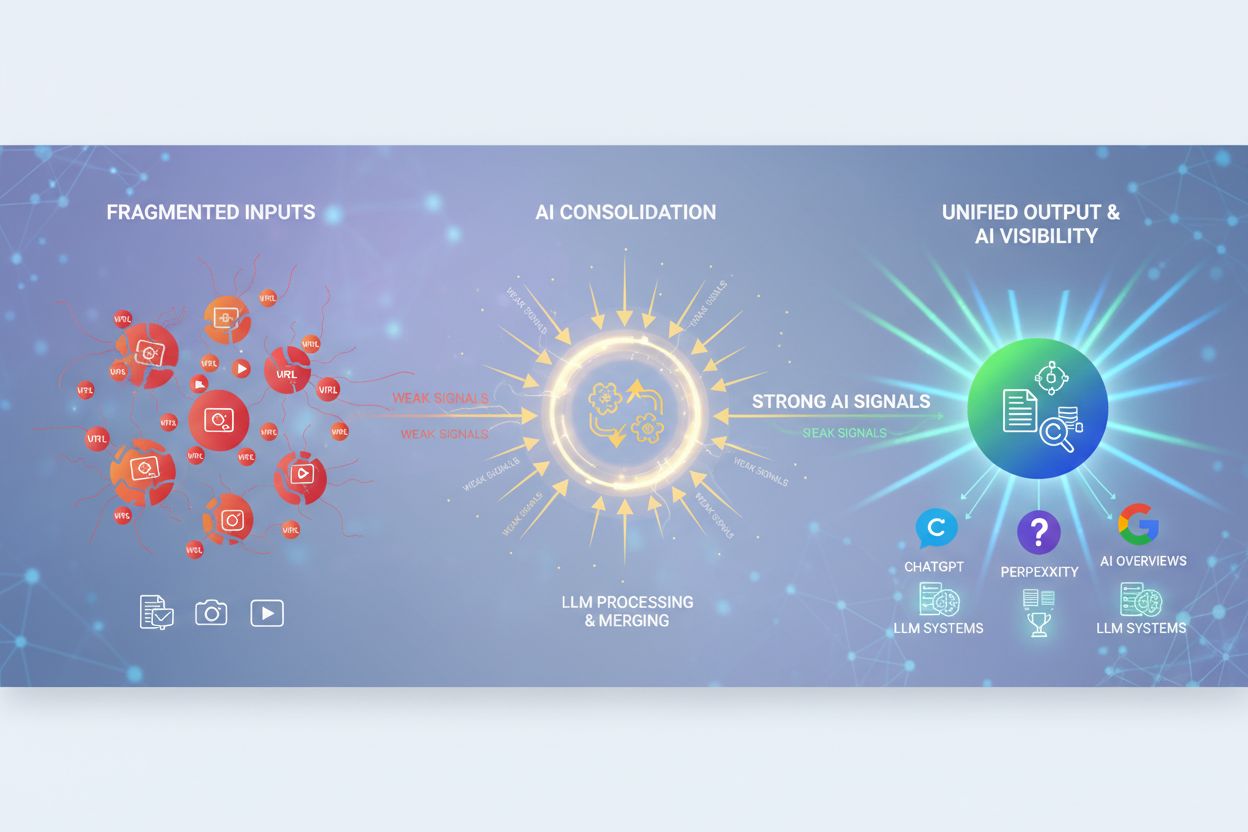
AI-indholdskonsolidering
Lær, hvad AI-indholdskonsolidering er, og hvordan sammenlægning af lignende indhold styrker synlighedssignaler for ChatGPT, Perplexity og Google AI Overviews. O...
10 min læsning
AI-dedupliceringslogik refererer til de automatiserede processer og algoritmer, som AI-systemer bruger til at identificere, analysere og eliminere redundante eller dublerede oplysninger fra flere kilder. Disse systemer anvender maskinlæring, naturlig sprogbehandling og teknikker til lighedsmatching for at genkende identisk eller meget lignende indhold på tværs af forskellige dataarkiver, hvilket sikrer datakvalitet, reducerer lageromkostninger og forbedrer beslutningsnøjagtigheden.
AI-dedupliceringslogik refererer til de automatiserede processer og algoritmer, som AI-systemer bruger til at identificere, analysere og eliminere redundante eller dublerede oplysninger fra flere kilder. Disse systemer anvender maskinlæring, naturlig sprogbehandling og teknikker til lighedsmatching for at genkende identisk eller meget lignende indhold på tværs af forskellige dataarkiver, hvilket sikrer datakvalitet, reducerer lageromkostninger og forbedrer beslutningsnøjagtigheden.
AI-dedupliceringslogik er en sofistikeret algoritmisk proces, der identificerer og fjerner dublerede eller næsten dublerede poster fra store datasæt ved hjælp af kunstig intelligens og maskinlæringsteknikker. Denne teknologi opdager automatisk, når flere poster repræsenterer den samme enhed – uanset om det er en person, et produkt, et dokument eller en oplysning – trods variationer i formatering, stavning eller præsentation. Hovedformålet med deduplikering er at opretholde dataintegritet og forhindre redundans, der kan forvride analyser, øge lageromkostninger og kompromittere nøjagtigheden af beslutningstagning. I en datadrevet verden, hvor organisationer dagligt behandler millioner af poster, er effektiv deduplikering blevet essentiel for driftsmæssig effektivitet og pålidelige indsigter.
AI-deduplicering anvender flere supplerende teknikker til at identificere og gruppere lignende poster med bemærkelsesværdig præcision. Processen starter med analyse af dataattributter – såsom navne, adresser, e-mailadresser og andre identificerende oplysninger – hvor disse sammenlignes med fastlagte lighedstærskler. Moderne deduplikeringssystemer bruger en kombination af fonetisk matching, streng-similaritetsalgoritmer og semantisk analyse til at fange dubletter, som traditionelle regelbaserede systemer kunne overse. Systemet tildeler lighedsscorer til potentielle match og samler poster, der overstiger den konfigurerede tærskel, i grupper, der repræsenterer den samme enhed. Brugerne bevarer kontrollen over inklusionniveauet for deduplikering og kan justere følsomheden ud fra deres specifikke brugssituation og tolerance over for falske positiver.
| Metode | Beskrivelse | Bedst til |
|---|---|---|
| Fonetisk lighed | Grupperer strenge, der lyder ens (fx “Smith” vs “Smyth”) | Navnevarianter, fonetisk forveksling |
| Stavningslighed | Grupperer strenge med lignende stavning | Tastefejl, mindre stavevariationer |
| TFIDF-lighed | Anvender algoritmen term frequency-inverse document frequency | Generel tekstmatching, dokumentsimilaritet |
Deduplikeringsmotoren behandler poster i flere omgange, hvor åbenlyse match identificeres først, inden mere subtile variationer undersøges. Denne lagdelte tilgang sikrer omfattende dækning og bevarer samtidig beregningsmæssig effektivitet – selv ved behandling af datasæt med millioner af poster.
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Moderne AI-deduplikering udnytter vektorembedding og semantisk analyse til at forstå betydningen bag data i stedet for blot at sammenligne overfladiske karakteristika. Naturlig sprogbehandling (NLP) gør det muligt for systemer at forstå kontekst og intention, så de kan genkende, at “Robert”, “Bob” og “Rob” alle kan referere til samme person trods forskellige former. Fuzzy matching-algoritmer beregner redigeringsafstanden mellem strenge og identificerer poster, der kun adskiller sig med få tegn – afgørende for at opfange tastefejl og transskriptionsfejl. Systemet analyserer også metadata såsom tidsstempler, oprettelsesdatoer og ændringshistorik for at give yderligere tillidssignaler ved afgørelse af, om poster er dubletter. Avancerede implementeringer inkorporerer maskinlæringsmodeller trænet på mærkede datasæt, så nøjagtigheden hele tiden forbedres, efterhånden som der behandles mere data og gives feedback på deduplikeringsbeslutninger.
AI-dedupliceringslogik er blevet uundværlig i stort set alle sektorer, der håndterer datadrift i stor skala. Organisationer udnytter denne teknologi til at opretholde rene, pålidelige datasæt, der muliggør præcis analyse og informerede beslutninger. De praktiske anvendelser spænder over en lang række centrale forretningsfunktioner:

Disse anvendelser viser, hvordan deduplikering har direkte indflydelse på compliance, svindelforebyggelse og driftssikkerhed på tværs af brancher.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
De økonomiske og driftsmæssige fordele ved AI-deduplikering er betydelige og målbare. Organisationer kan reducere lageromkostninger markant ved at eliminere redundant data – nogle implementeringer opnår 20-40% reduktion i lagerkrav. Forbedret datakvalitet fører direkte til bedre analyser og beslutninger, da analyser baseret på rene data giver mere pålidelige indsigter og prognoser. Forskning viser, at data science-specialister bruger ca. 80% af deres tid på datapreparation, hvor dublerede poster er en stor belastning – deduplikeringsautomatisering frigør værdifuld analysetid til arbejde med højere værdi. Studier viser, at 10-30% af posterne i typiske databaser indeholder dubletter, hvilket udgør en væsentlig kilde til ineffektivitet og fejl. Ud over besparelser styrker deduplikering compliance og overholdelse af regler ved at sikre korrekt journalføring og forhindre dublerede indsendelser, som kan udløse revisioner eller bøder. De driftsmæssige effektivitetsgevinster omfatter hurtigere forespørgsler, reduceret beregningsmæssig belastning og forbedret systempålidelighed.
På trods af sin avancerede karakter er AI-deduplikering ikke uden udfordringer og begrænsninger, som organisationer skal håndtere omhyggeligt. Falske positiver – at forskellige poster fejlagtigt identificeres som dubletter – kan føre til datatab eller sammenflettede poster, der burde forblive separate, mens falske negativer lader reelle dubletter slippe igennem uopdaget. Deduplikering bliver eksponentielt mere kompleks, når der arbejdes med multiformatdata fra forskellige systemer, sprog og datastrukturer, hver med unikke konventioner og kodningsstandarder. Privatlivs- og sikkerhedshensyn opstår, når deduplikering kræver analyse af følsomme personoplysninger, hvilket forudsætter robust kryptering og adgangskontrol for at beskytte data under matchingprocessen. Nøjagtigheden af deduplikeringssystemer er grundlæggende begrænset af kvaliteten af inputdata; garbage in, garbage out – og ufuldstændige eller korrupte poster kan forvirre selv de mest avancerede algoritmer.
AI-deduplikering er blevet en kritisk komponent i moderne AI-svarovervågningsplatforme og søgesystemer, der samler information fra flere kilder. Når AI-systemer sammenfatter svar fra mange dokumenter og kilder, sikrer deduplikering, at den samme information ikke tælles flere gange, hvilket ellers ville oppuste tillidsscorer og forvride relevansrangeringer. Kildeangivelse bliver mere meningsfuld, når deduplikering fjerner redundante kilder, så brugerne kan se det reelle mangfoldige bevisgrundlag for et svar. Platforme som AmICited.com udnytter deduplikeringslogik til at levere transparent og nøjagtig kildeovervågning ved at identificere, når flere kilder reelt indeholder identisk information og konsolidere dem passende. Dette forhindrer, at AI-svar ser ud til at have større opbakning, end de faktisk har, og fastholder integriteten af kildeangivelse og svarenes troværdighed. Ved at filtrere dublerede kilder fra forbedrer deduplikering kvaliteten af AI-søgeresultater og sikrer, at brugerne får ægte mangfoldige perspektiver i stedet for gentagelser af samme information på tværs af kilder. Teknologien styrker til syvende og sidst tilliden til AI-systemer ved at give et renere og mere ærligt billede af det bevismateriale, der ligger til grund for AI-genererede svar.
AmICited sporer, hvordan AI-systemer som GPT'er, Perplexity og Google AI refererer til dit brand på tværs af flere kilder. Sikr nøjagtig kildeangivelse og forhindre, at dubleret indhold forvrænger din AI-synlighed.
Lær, hvad AI-indholdskonsolidering er, og hvordan sammenlægning af lignende indhold styrker synlighedssignaler for ChatGPT, Perplexity og Google AI Overviews. O...

Fællesskabsdiskussion om, hvordan AI-systemer håndterer duplikeret indhold anderledes end traditionelle søgemaskiner. SEO-professionelle deler indsigt om indhol...

Lær hvordan genudgivelse af indhold skaber problemer med duplikeret indhold, der skader AI-synlighed mere alvorligt end traditionel søgning. Opdag tekniske forh...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.