
How to Handle Duplicate Content for AI Search Engines
Learn how to manage and prevent duplicate content when using AI tools. Discover canonical tags, redirects, detection tools, and best practices for maintaining u...
12 min read
AI Deduplication Logic refers to the automated processes and algorithms that AI systems use to identify, analyze, and eliminate redundant or duplicate information from multiple sources. These systems employ machine learning, natural language processing, and similarity matching techniques to recognize identical or highly similar content across diverse data repositories, ensuring data quality, reducing storage costs, and improving decision-making accuracy.
AI Deduplication Logic refers to the automated processes and algorithms that AI systems use to identify, analyze, and eliminate redundant or duplicate information from multiple sources. These systems employ machine learning, natural language processing, and similarity matching techniques to recognize identical or highly similar content across diverse data repositories, ensuring data quality, reducing storage costs, and improving decision-making accuracy.
AI deduplication logic is a sophisticated algorithmic process that identifies and eliminates duplicate or near-duplicate records from large datasets using artificial intelligence and machine learning techniques. This technology automatically detects when multiple entries represent the same entity—whether that’s a person, product, document, or piece of information—despite variations in formatting, spelling, or presentation. The core purpose of deduplication is to maintain data integrity and prevent redundancy that can skew analysis, inflate storage costs, and compromise decision-making accuracy. In today’s data-driven world, where organizations process millions of records daily, effective deduplication has become essential for operational efficiency and reliable insights.
AI deduplication employs multiple complementary techniques to identify and group similar records with remarkable precision. The process begins by analyzing data attributes—such as names, addresses, email addresses, and other identifiers—and comparing them against established similarity thresholds. Modern deduplication systems use a combination of phonetic matching, string similarity algorithms, and semantic analysis to catch duplicates that traditional rule-based systems might miss. The system assigns similarity scores to potential matches, clustering records that exceed the configured threshold into groups representing the same entity. Users maintain control over the inclusiveness level of deduplication, allowing them to adjust sensitivity based on their specific use case and tolerance for false positives.
| Method | Description | Best For |
|---|---|---|
| Phonetic Similarity | Groups strings that sound alike (e.g., “Smith” vs “Smyth”) | Name variations, phonetic confusion |
| Spelling Similarity | Groups strings similar in spelling | Typos, minor spelling variations |
| TFIDF Similarity | Applies term frequency-inverse document frequency algorithm | General text matching, document similarity |
The deduplication engine processes records through multiple passes, first identifying obvious matches before progressively examining more subtle variations. This layered approach ensures comprehensive coverage while maintaining computational efficiency, even when processing datasets containing millions of records.
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Modern AI deduplication leverages vector embeddings and semantic analysis to understand the meaning behind data rather than just comparing surface-level characteristics. Natural Language Processing (NLP) enables systems to comprehend context and intent, allowing them to recognize that “Robert,” “Bob,” and “Rob” all refer to the same person despite their different forms. Fuzzy matching algorithms calculate the edit distance between strings, identifying records that differ by only a few characters—critical for catching typos and transcription errors. The system also analyzes metadata such as timestamps, creation dates, and modification history to provide additional confidence signals when determining whether records are duplicates. Advanced implementations incorporate machine learning models trained on labeled datasets, continuously improving accuracy as they process more data and receive feedback on deduplication decisions.
AI deduplication logic has become indispensable across virtually every sector that manages large-scale data operations. Organizations leverage this technology to maintain clean, reliable datasets that drive accurate analytics and informed decision-making. The practical applications span numerous critical business functions:

These applications demonstrate how deduplication directly impacts compliance, fraud prevention, and operational integrity across diverse industries.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
The financial and operational benefits of AI deduplication are substantial and measurable. Organizations can significantly reduce storage costs by eliminating redundant data, with some implementations achieving 20-40% reductions in storage requirements. Improved data quality directly translates to better analytics and decision-making, as analysis based on clean data produces more reliable insights and forecasts. Research indicates that data scientists spend approximately 80% of their time on data preparation, with duplicate records being a major contributor to this burden—deduplication automation reclaims valuable analyst time for higher-value work. Studies show that 10-30% of records in typical databases contain duplicates, representing a significant source of inefficiency and error. Beyond cost reduction, deduplication strengthens compliance and regulatory adherence by ensuring accurate record-keeping and preventing duplicate submissions that could trigger audits or penalties. The operational efficiency gains extend to faster query performance, reduced computational overhead, and improved system reliability.
Despite its sophistication, AI deduplication is not without challenges and limitations that organizations must carefully manage. False positives—incorrectly identifying distinct records as duplicates—can lead to data loss or merged records that should remain separate, while false negatives allow actual duplicates to slip through undetected. Deduplication becomes exponentially more complex when dealing with multi-format data spanning different systems, languages, and data structures, each with unique formatting conventions and encoding standards. Privacy and security concerns arise when deduplication requires analyzing sensitive personal information, necessitating robust encryption and access controls to protect data during the matching process. The accuracy of deduplication systems remains fundamentally limited by the quality of input data; garbage in produces garbage out, and incomplete or corrupted records can confound even the most advanced algorithms.
AI deduplication has become a critical component of modern AI answer monitoring platforms and search systems that aggregate information from multiple sources. When AI systems synthesize responses from numerous documents and sources, deduplication ensures that the same information isn’t counted multiple times, which would artificially inflate confidence scores and skew relevance rankings. Source attribution becomes more meaningful when deduplication removes redundant sources, allowing users to see the true diversity of evidence supporting an answer. Platforms like AmICited.com leverage deduplication logic to provide transparent, accurate source tracking by identifying when multiple sources contain essentially identical information and consolidating them appropriately. This prevents AI responses from appearing to have broader support than they actually do, maintaining the integrity of source attribution and answer credibility. By filtering out duplicate sources, deduplication improves the quality of AI search results and ensures that users receive genuinely diverse perspectives rather than variations of the same information repeated across multiple sources. The technology ultimately strengthens trust in AI systems by providing cleaner, more honest representations of the evidence underlying AI-generated answers.
AmICited tracks how AI systems like GPTs, Perplexity, and Google AI reference your brand across multiple sources. Ensure accurate source attribution and prevent duplicate content from skewing your AI visibility.
Learn how to manage and prevent duplicate content when using AI tools. Discover canonical tags, redirects, detection tools, and best practices for maintaining u...

Learn how canonical URLs prevent duplicate content problems in AI search systems. Discover best practices for implementing canonicals to improve AI visibility a...
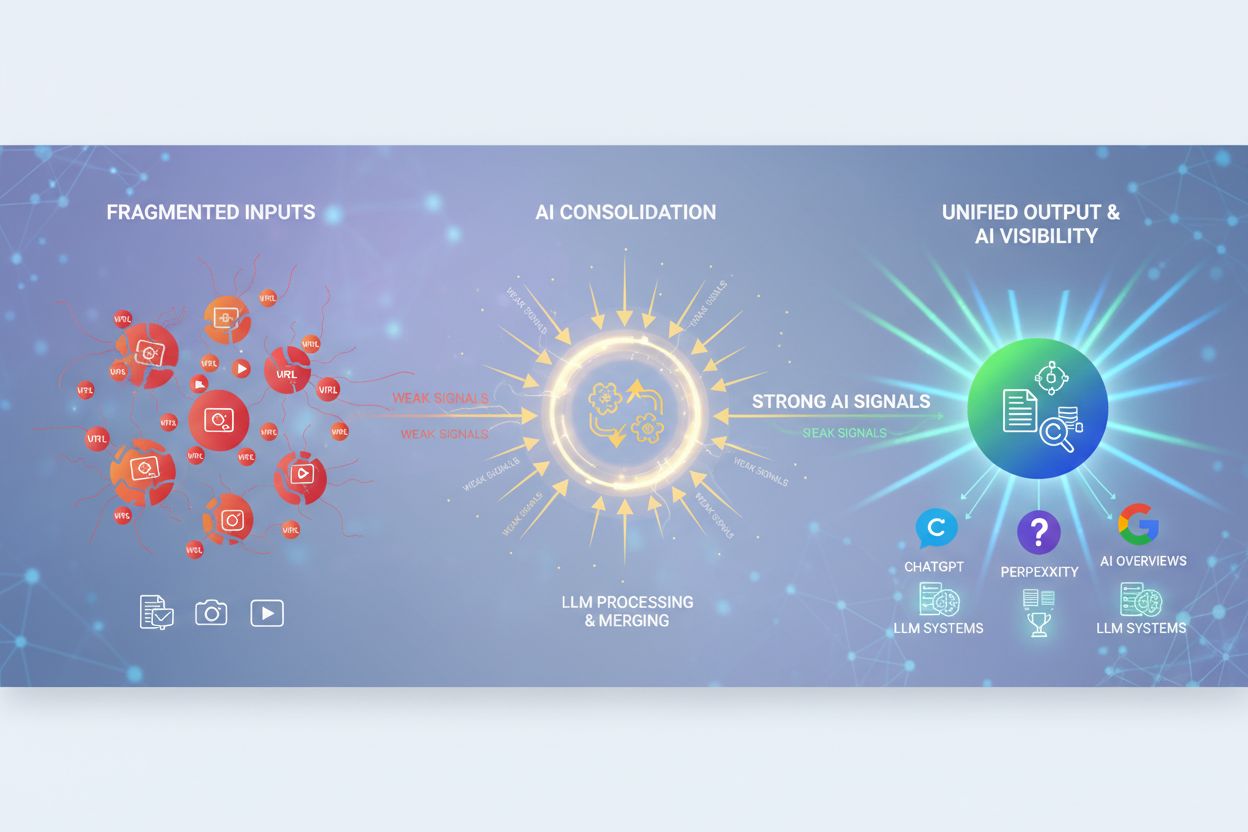
Learn what AI Content Consolidation is and how merging similar content strengthens visibility signals for ChatGPT, Perplexity, and Google AI Overviews. Discover...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.