AI-dedupliseringslogikk refererer til de automatiserte prosessene og algoritmene som AI-systemer bruker for å identifisere, analysere og eliminere overflødig eller duplisert informasjon fra flere kilder. Disse systemene benytter maskinlæring, naturlig språkprosessering og teknikker for likhetsmatching for å gjenkjenne identisk eller svært likt innhold på tvers av ulike datalagre, noe som sikrer datakvalitet, reduserer lagringskostnader og forbedrer nøyaktigheten i beslutningsprosesser.
AI-dedupliseringslogikk
AI-dedupliseringslogikk refererer til de automatiserte prosessene og algoritmene som AI-systemer bruker for å identifisere, analysere og eliminere overflødig eller duplisert informasjon fra flere kilder. Disse systemene benytter maskinlæring, naturlig språkprosessering og teknikker for likhetsmatching for å gjenkjenne identisk eller svært likt innhold på tvers av ulike datalagre, noe som sikrer datakvalitet, reduserer lagringskostnader og forbedrer nøyaktigheten i beslutningsprosesser.
Hva er AI-dedupliseringslogikk?
AI-dedupliseringslogikk er en avansert algoritmisk prosess som identifiserer og eliminerer dupliserte eller nesten like poster fra store datasett ved hjelp av kunstig intelligens og maskinlæringsteknikker. Denne teknologien oppdager automatisk når flere oppføringer representerer samme enhet—enten det er en person, et produkt, et dokument eller en informasjonsbit—til tross for variasjoner i formatering, staving eller presentasjon. Hovedformålet med deduplisering er å opprettholde dataintegritet og forhindre overflødighet som kan forvrenge analyser, øke lagringskostnader og redusere nøyaktigheten i beslutningsprosesser. I dagens datadrevne verden, hvor organisasjoner behandler millioner av poster daglig, har effektiv deduplisering blitt avgjørende for operasjonell effektivitet og pålitelige innsikter.
Hvordan fungerer AI-deduplisering
AI-deduplisering benytter flere komplementære teknikker for å identifisere og gruppere lignende poster med imponerende presisjon. Prosessen starter med å analysere dataattributter—slik som navn, adresser, e-postadresser og andre identifikatorer—og sammenligne dem mot etablerte likhetsterskler. Moderne dedupliseringssystemer bruker en kombinasjon av fonetisk matching, strenglikhetsalgoritmer og semantisk analyse for å fange opp duplikater som tradisjonelle regelbaserte systemer kan overse. Systemet tildeler likhetspoeng til potensielle treff, og grupperer poster som overskrider den konfigurerte terskelen i grupper som representerer samme enhet. Brukere beholder kontroll over inkluderingsnivået for deduplisering, slik at de kan justere følsomheten etter sitt spesifikke brukstilfelle og toleranse for falske positive.
Metode
Beskrivelse
Best egnet for
Fonetisk likhet
Grupperer strenger som høres like ut (f.eks. “Smith” vs “Smyth”)
Navnevariasjoner, fonetisk forvirring
Stave-likhet
Grupperer strenger med lignende staving
Tastefeil, mindre stavevariasjoner
TFIDF-likhet
Bruker termfrekvens/invers dokumentfrekvens-algoritme
Generell tekstmatching, dokumentsimilaritet
Dedupliseringsmotoren behandler poster gjennom flere omganger, først ved å identifisere åpenbare treff før den gradvis undersøker mer subtile variasjoner. Denne lagvise tilnærmingen sikrer omfattende dekning samtidig som den opprettholder beregningseffektivitet, selv ved behandling av datasett med millioner av poster.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Moderne AI-deduplisering benytter vektorinnbygging og semantisk analyse for å forstå meningen bak data, ikke bare sammenligne overfladiske karakteristikker. Naturlig språkprosessering (NLP) gjør det mulig for systemer å forstå kontekst og hensikt, slik at de kan gjenkjenne at “Robert”, “Bob” og “Rob” alle refererer til samme person til tross for ulike former. Fuzzy matching-algoritmer beregner redigeringsavstanden mellom strenger, og identifiserer poster som skiller seg med bare noen få tegn—viktig for å fange opp tastefeil og transkripsjonsfeil. Systemet analyserer også metadata som tidsstempler, opprettelsesdatoer og endringshistorikk for å gi ekstra sikkerhetssignaler ved avgjørelse om poster er duplikater. Avanserte implementeringer inkorporerer maskinlæringsmodeller trent på merkede datasett, som kontinuerlig forbedrer nøyaktigheten etter hvert som de behandler mer data og mottar tilbakemeldinger på dedupliseringsbeslutninger.
Virkelige bruksområder på tvers av bransjer
AI-dedupliseringslogikk har blitt uunnværlig i nesten alle sektorer som håndterer storskala databehandling. Organisasjoner bruker denne teknologien for å vedlikeholde rene, pålitelige datasett som gir nøyaktige analyser og velinformerte beslutninger. De praktiske bruksområdene omfatter en rekke kritiske forretningsfunksjoner:
Låne- og forsikringssøknader—oppdage dupliserte søkere og forhindre svindel
Customer Relationship Management (CRM)—identifisere dupliserte kundeposter for å tilby enhetlig kundebilde
Helsesystemer—oppdage dupliserte pasientjournaler for å sikre nøyaktige medisinske historikker og forhindre feilmedisinering
E-handelsplattformer—identifisere dupliserte produktoppføringer for å ivareta katalogintegritet
Offentlige tjenester—flagge dupliserte velgerregistreringer og trygdesøknader for å hindre svindel og misbruk
Disse bruksområdene viser hvordan deduplisering direkte påvirker etterlevelse, svindelforebygging og operasjonell integritet på tvers av ulike bransjer.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Forretningspåvirkning og kostnadsfordeler
De økonomiske og driftsmessige fordelene ved AI-deduplisering er betydelige og målbare. Organisasjoner kan kraftig redusere lagringskostnader ved å eliminere overflødige data, hvor noen implementeringer oppnår 20-40% reduksjon i lagringsbehov. Forbedret datakvalitet gir umiddelbart bedre analyser og beslutninger, da analyser basert på rene data gir mer pålitelige innsikter og prognoser. Forskning viser at dataforskere bruker omtrent 80% av tiden på datapreparering, hvor dupliserte poster er en hovedårsak til denne belastningen—dedupliseringsautomatisering frigjør verdifull analysetid til mer verdiskapende arbeid. Studier viser at 10-30% av postene i vanlige databaser er duplikater, noe som representerer en betydelig kilde til ineffektivitet og feil. Utover kostnadsreduksjon styrker deduplisering etterlevelse og regulatorisk oppfølging ved å sikre nøyaktig journalføring og forhindre dupliserte innsendinger som kan utløse revisjoner eller sanksjoner. Effektivitetsgevinstene omfatter også raskere søk, redusert beregningsbelastning og bedre systempålitelighet.
Utfordringer og begrensninger
Til tross for sin avanserte natur er AI-deduplisering ikke uten utfordringer og begrensninger som organisasjoner må håndtere nøye. Falske positive—feilaktig identifisering av ulike poster som duplikater—kan føre til datatap eller sammenslåtte poster som burde vært separate, mens falske negative gjør at reelle duplikater slipper gjennom uoppdaget. Deduplisering blir eksponentielt mer komplekst ved håndtering av multiformatdata på tvers av ulike systemer, språk og datastrukturer, hver med egne formateringskonvensjoner og koding. Personvern- og sikkerhetsutfordringer oppstår når deduplisering krever analyse av sensitiv personlig informasjon, noe som krever robust kryptering og tilgangskontroller for å beskytte data under matchingprosessen. Nøyaktigheten til dedupliseringssystemene er fundamentalt avhengig av kvaliteten på inngangsdataene; dårlig inn gir dårlig ut, og ufullstendige eller ødelagte poster kan forvirre selv de mest avanserte algoritmene.
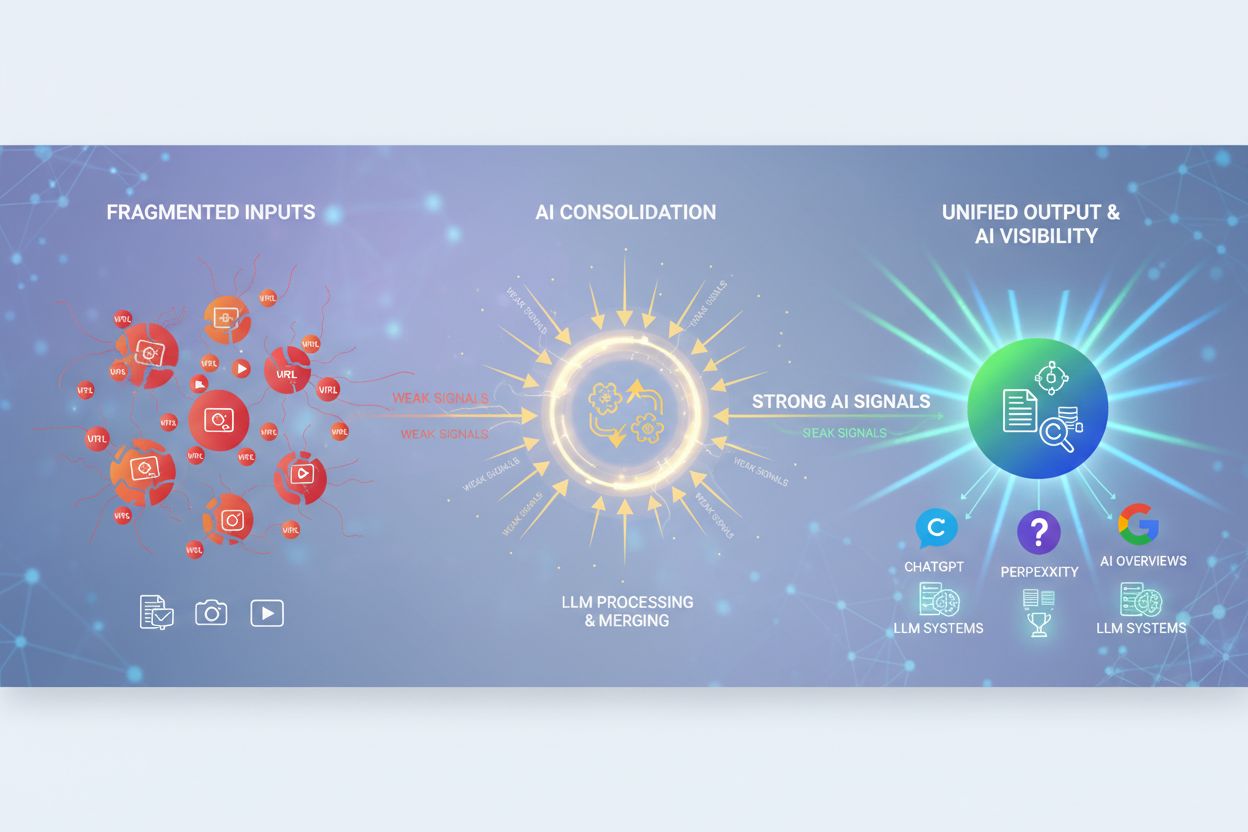
AI-deduplisering i moderne AI-plattformer
AI-deduplisering har blitt en kritisk komponent i moderne AI-svarovervåkingsplattformer og søkesystemer som samler informasjon fra flere kilder. Når AI-systemer setter sammen svar fra en rekke dokumenter og kilder, sikrer deduplisering at samme informasjon ikke telles flere ganger, noe som ellers ville gitt kunstig høye tillitsscore og forvrengt relevansvurderinger. Kildeattribusjon blir mer meningsfull når deduplisering fjerner overflødige kilder, slik at brukerne ser det reelle mangfoldet av bevis bak et svar. Plattformer som AmICited.com benytter dedupliseringslogikk for å gi transparent, nøyaktig kildeovervåking ved å identifisere når flere kilder inneholder tilnærmet identisk informasjon og konsolidere dem riktig. Dette hindrer at AI-svar fremstår som om de har bredere støtte enn de egentlig har, og opprettholder integriteten til kildehenvisning og troverdigheten til svarene. Ved å filtrere ut dupliserte kilder forbedrer deduplisering kvaliteten på AI-søkeresultater og sikrer at brukerne får virkelig ulike perspektiver, ikke bare varianter av samme informasjon gjentatt på tvers av flere kilder. Teknologien styrker til syvende og sist tilliten til AI-systemer ved å gi renere og mer ærlige fremstillinger av bevisene bak AI-genererte svar.
Vanlige spørsmål
AI-deduplisering og datakomprimering reduserer begge datavolumet, men de fungerer forskjellig. Deduplisering identifiserer og fjerner nøyaktige eller nesten identiske poster, beholder kun én forekomst og erstatter andre med referanser. Datakomprimering, derimot, koder data mer effektivt uten å fjerne duplikater. Deduplisering fungerer på makronivå (hele filer eller poster), mens komprimering fungerer på mikronivå (enkeltbiter og bytes). For organisasjoner med betydelig dupliserte data gir deduplisering vanligvis større lagringsbesparelser.
AI bruker flere sofistikerte teknikker for å fange ikke-eksakte duplikater. Fonetiske algoritmer gjenkjenner navn som høres like ut (f.eks. "Smith" vs "Smyth"). Fuzzy matching beregner redigeringsavstand for å finne poster som avviker med bare noen få tegn. Vektorinnebygging konverterer tekst til matematiske representasjoner som fanger semantisk mening, slik at systemet kan gjenkjenne omskrevet innhold. Maskinlæringsmodeller trent på merkede datasett lærer mønstre for hva som utgjør et duplikat i bestemte sammenhenger. Disse teknikkene samarbeider for å identifisere duplikater til tross for variasjoner i staving, formatering eller presentasjon.
Deduplisering kan redusere lagringskostnadene betydelig ved å eliminere overflødige data. Organisasjoner oppnår vanligvis 20-40% reduksjon i lagringsbehov etter effektiv deduplisering. Disse besparelsene forsterkes over tid etter hvert som nye data kontinuerlig dedupliseres. I tillegg til direkte reduksjon av lagringskostnader, reduserer deduplisering også utgifter knyttet til databehandling, backup-operasjoner og systemvedlikehold. For store virksomheter som behandler millioner av poster, kan disse besparelsene utgjøre hundretusener av kroner årlig, noe som gjør deduplisering til en investering med høy avkastning.
Ja, moderne AI-dedupliseringssystemer kan fungere på tvers av ulike filformater, men det krever mer avansert behandling. Systemet må først normalisere data fra ulike formater (PDF-filer, Word-dokumenter, regneark, databaser osv.) til en sammenlignbar struktur. Avanserte løsninger bruker optisk tegngjenkjenning (OCR) for skannede dokumenter og formatspesifikke tolker for å trekke ut meningsfullt innhold. Likevel kan nøyaktigheten variere avhengig av formatets kompleksitet og datakvalitet. Organisasjoner oppnår vanligvis best resultat når deduplisering brukes på strukturerte data i konsistente formater, selv om deduplisering på tvers av formater blir stadig mer mulig med moderne AI-teknikker.
Deduplisering forbedrer AI-søkeresultater ved å sikre at relevansvurderinger gjenspeiler reell kildevariasjon fremfor variasjoner av samme informasjon. Når flere kilder inneholder identisk eller nær-identisk innhold, konsoliderer deduplisering dem og forhindrer kunstig oppblåsing av tillitsscore. Dette gir brukerne renere og mer ærlige fremstillinger av bevis som støtter AI-genererte svar. Deduplisering forbedrer også søkeytelsen ved å redusere datamengden systemet må behandle, noe som gir raskere respons på forespørsler. Ved å filtrere ut overflødige kilder kan AI-systemer fokusere på genuint forskjellige perspektiver og informasjon, og til slutt levere mer kvalitetsrike og pålitelige resultater.
Falske positive oppstår når deduplisering feilaktig identifiserer ulike poster som duplikater og slår dem sammen. For eksempel å slå sammen poster for "John Smith" og "Jane Smith" som er ulike personer, men med samme etternavn. Falske positive er problematiske fordi de resulterer i permanent datatap—når poster slås sammen, blir det vanskelig eller umulig å gjenvinne den opprinnelige, distinkte informasjonen. I kritiske bruksområder som helsevesen eller finans, kan falske positive ha alvorlige konsekvenser, inkludert feil medisinsk historikk eller svindeltransaksjoner. Organisasjoner må nøye kalibrere dedupliseringsfølsomheten for å minimere falske positive, og ofte akseptere noen falske negative (oversette duplikater) som en tryggere løsning.
Deduplisering er avgjørende for AI-innholdsovervåkingsplattformer som AmICited, som sporer hvordan AI-systemer refererer til merkevarer og kilder. Ved overvåking av AI-responser på tvers av flere plattformer (GPT-er, Perplexity, Google AI), hindrer deduplisering at samme kilde telles flere ganger hvis den vises i ulike AI-systemer eller i forskjellige formater. Dette sikrer nøyaktig attribusjon og forhindrer oppblåste synlighetsmålinger. Deduplisering hjelper også til med å identifisere når AI-systemer henter fra et begrenset antall kilder til tross for at de ser ut til å ha variert bevis. Ved å konsolidere dupliserte kilder gir overvåkingsplattformer tydeligere innsikt i hvilke unike kilder som faktisk påvirker AI-responser.
Metadata—informasjon om data, som opprettelsesdatoer, endringstidspunkter, forfatterinformasjon og fil-egenskaper—spiller en avgjørende rolle i duplikatdeteksjon. Metadata hjelper til med å fastslå livssyklusen til poster, og viser når dokumenter ble opprettet, oppdatert eller åpnet. Denne tidsmessige informasjonen hjelper til med å skille mellom legitime versjoner av utviklende dokumenter og faktiske duplikater. Forfatterinformasjon og avdelingsassosiasjoner gir kontekst om opprinnelse og hensikt. Bruksmønstre indikerer om dokumenter er i aktiv bruk eller foreldet. Avanserte dedupliseringssystemer integrerer metadata-analyse med innholdsanalyse, og bruker begge signaler for å gjøre mer nøyaktige vurderinger av duplikater samt å avgjøre hvilken versjon som skal beholdes som autoritativ kilde.
Overvåk hvordan AI refererer til ditt varemerke
AmICited sporer hvordan AI-systemer som GPT-er, Perplexity og Google AI refererer til ditt varemerke på tvers av flere kilder. Sikre nøyaktig kildehenvisning og forhindre at duplisert innhold påvirker din AI-synlighet.
Hvordan håndterer AI-søkemotorer duplisert innhold? Er det annerledes enn Google?
Diskusjon i fellesskapet om hvordan AI-systemer håndterer duplisert innhold annerledes enn tradisjonelle søkemotorer. SEO-fagfolk deler innsikt om innholdsunikh...
Hvordan håndtere duplikatinnhold for AI-søkemotorer
Lær hvordan du håndterer og forhindrer duplikatinnhold når du bruker AI-verktøy. Oppdag kanoniske tagger, videresendinger, deteksjonsverktøy og beste praksis fo...
Lær hva AI-innholdskonsolidering er og hvordan sammenslåing av lignende innhold styrker synlighetssignaler for ChatGPT, Perplexity og Google AI Overviews. Oppda...
10 min lesing
Informasjonskapselsamtykke Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.