
Tréningové dáta
Tréningové dáta sú súbor údajov používaný na učenie modelov strojového učenia vzorom a vzťahom. Zistite, ako kvalita tréningových dát ovplyvňuje výkon, presnosť...
11 min čítania

Tréning so syntetickými údajmi je proces trénovania AI modelov pomocou umelo generovaných dát namiesto skutočných údajov vytvorených ľuďmi. Tento prístup rieši nedostatok dát, urýchľuje vývoj modelov a chráni súkromie, pričom však prináša aj výzvy ako kolaps modelu a halucinácie, ktoré si vyžadujú dôslednú správu a overovanie.
Tréning so syntetickými údajmi je proces trénovania AI modelov pomocou umelo generovaných dát namiesto skutočných údajov vytvorených ľuďmi. Tento prístup rieši nedostatok dát, urýchľuje vývoj modelov a chráni súkromie, pričom však prináša aj výzvy ako kolaps modelu a halucinácie, ktoré si vyžadujú dôslednú správu a overovanie.
Tréning so syntetickými údajmi označuje proces trénovania modelov umelej inteligencie pomocou umelo generovaných dát namiesto skutočných údajov vytvorených ľuďmi. Na rozdiel od tradičného AI tréningu, ktorý sa spolieha na autentické dátové súbory získané z prieskumov, pozorovaní alebo webového ťaženia, sú syntetické údaje vytvárané algoritmami a výpočtovými metódami, ktoré sa učia štatistické vzory z existujúcich dát alebo generujú úplne nové údaje od nuly. Tento zásadný posun v metodike tréningu rieši kľúčovú výzvu moderného AI vývoja: exponenciálny rast výpočtových nárokov už prekonal schopnosť ľudstva generovať dostatok reálnych údajov, pričom výskumy naznačujú, že ľudsky generované tréningové dáta môžu byť v priebehu nasledujúcich rokov vyčerpané. Tréning so syntetickými údajmi ponúka škálovateľnú, nákladovo efektívnu alternatívu, ktorú je možné generovať nekonečne bez časovo náročných procesov zberu, označovania a čistenia údajov, ktoré tvoria až 80 % tradičných AI vývojových časových rámcov.
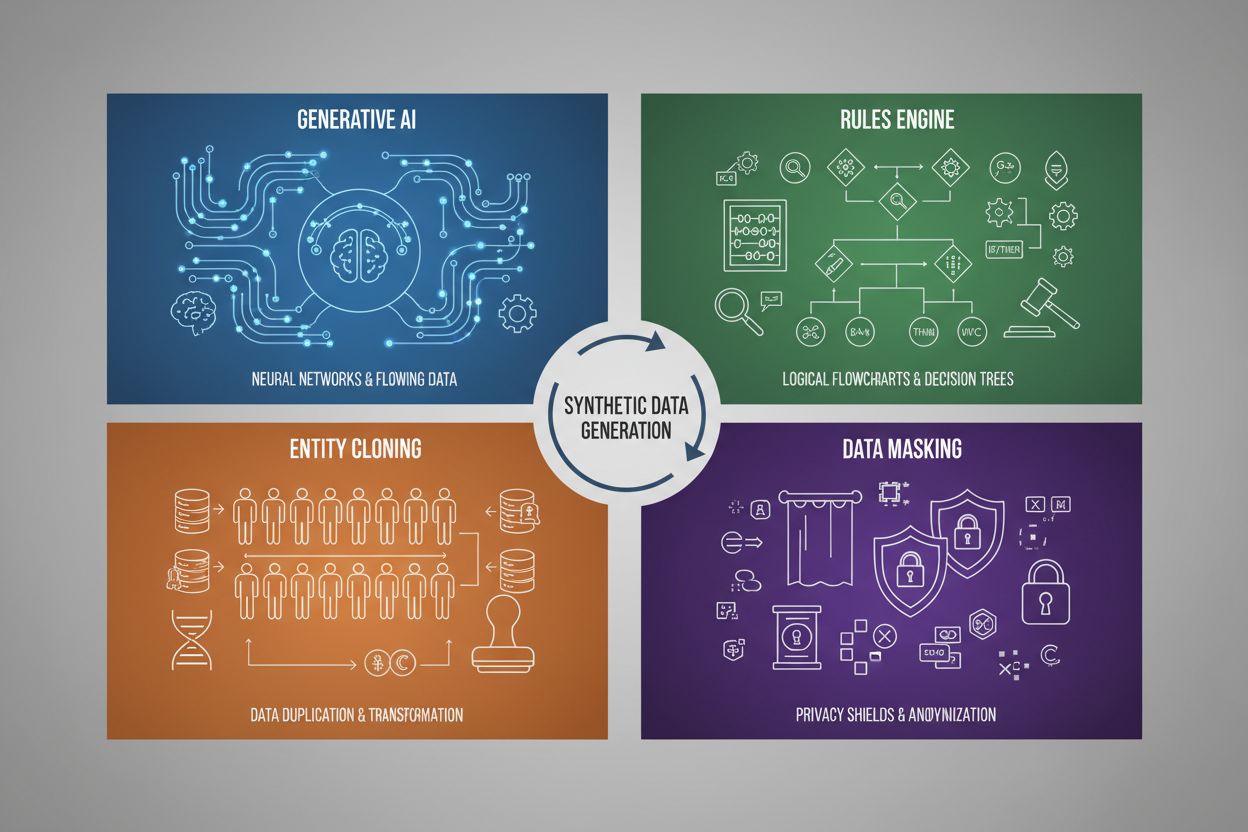
Generovanie syntetických údajov využíva štyri hlavné techniky, z ktorých každá má odlišné mechanizmy a použitia:
| Technika | Ako funguje | Prípad použitia |
|---|---|---|
| Generatívna AI (GAN, VAE, GPT) | Využíva modely hlbokého učenia na učenie štatistických vzorov a rozdelení z reálnych dát a následne generuje nové syntetické vzorky, ktoré zachovávajú rovnaké štatistické vlastnosti a vzťahy. GAN využíva adversariálne siete, kde generátor vytvára falošné dáta a diskriminátor hodnotí ich pravosť, čím vznikajú stále realistickejšie výstupy. | Tréning veľkých jazykových modelov ako ChatGPT, generovanie syntetických obrázkov s DALL-E, tvorba rôznorodých textových datasetov pre úlohy spracovania prirodzeného jazyka |
| Pravidlový engine | Aplikuje vopred definované logické pravidlá a obmedzenia na generovanie údajov, ktoré spĺňajú konkrétnu obchodnú logiku, znalosti domény alebo regulačné požiadavky. Tento deterministický prístup zaručuje, že generované údaje dodržiavajú známe vzory a vzťahy bez použitia strojového učenia. | Údaje o finančných transakciách, zdravotnícke záznamy s konkrétnymi požiadavkami na súlad, výrobné senzorové dáta so známymi prevádzkovými parametrami |
| Klonovanie entít | Duplikuje a upravuje existujúce reálne dátové záznamy aplikovaním transformácií, rušenia alebo variácií na vytvorenie nových inštancií pri zachovaní základných štatistických vlastností a vzťahov. Táto technika zachováva autenticitu údajov a zároveň rozširuje dataset. | Rozširovanie obmedzených datasetov v regulovaných odvetviach, tvorba tréningových dát pre diagnostiku zriedkavých ochorení, augmentácia datasetov s nedostatočnými príkladmi menšinových tried |
| Maskovanie a anonymizácia dát | Zakrýva citlivé osobne identifikovateľné informácie (PII) pri zachovaní štruktúry dát a štatistických vzťahov prostredníctvom techník ako tokenizácia, šifrovanie alebo nahrádzanie hodnôt. Výsledkom sú syntetické verzie reálnych dát s ochranou súkromia. | Zdravotnícke a finančné datasety, údaje o správaní zákazníkov, osobne citlivé informácie vo výskumných kontextoch |
Tréning so syntetickými údajmi prináša výrazné zníženie nákladov tým, že eliminuje drahé procesy zberu, anotácie a čistenia dát, ktoré tradične vyžadujú značné zdroje a čas. Organizácie môžu generovať neobmedzené množstvo tréningových vzoriek na požiadanie, dramaticky urýchliť vývojové cykly modelov a umožniť rýchle iterácie a experimentovanie bez čakania na zber reálnych údajov. Táto technika poskytuje silné možnosti augmentácie dát, vďaka čomu môžu vývojári rozširovať obmedzené datasety a vytvárať vyvážené tréningové sady na riešenie problémov s nevyváženosťou tried – čo je kritický problém, keď sú niektoré kategórie v reálnych dátach nedostatočne zastúpené. Syntetické údaje sú mimoriadne hodnotné pri riešení nedostatku dát v špecializovaných oblastiach, ako je medicínske zobrazovanie, diagnostika zriedkavých ochorení alebo testovanie autonómnych vozidiel, kde je získanie dostatočného množstva reálnych príkladov extrémne drahé alebo eticky problematické. Ochrana súkromia predstavuje významnú výhodu, keďže syntetické dáta je možné generovať bez odhalenia citlivých osobných informácií, vďaka čomu sú ideálne na tréning modelov na zdravotníckych záznamoch, finančných dátach alebo iných regulovaných informáciách. Okrem toho syntetické údaje umožňujú systematické znižovanie zaujatostí tým, že vývojári môžu zámerne vytvárať vyvážené, rôznorodé datasety, ktoré eliminujú diskriminačné vzory prítomné v reálnych dátach – napríklad generovaním rozmanitého demografického zastúpenia v tréningových obrázkoch, aby modely AI neprehlbovali rodové alebo rasové stereotypy v oblastiach ako zamestnávanie, poskytovanie úverov či trestná justícia.
Aj napriek svojmu potenciálu prináša tréning so syntetickými údajmi významné technické a praktické výzvy, ktoré môžu znížiť výkon modelu, ak nie sú starostlivo manažované. Najkritickejším problémom je kolaps modelu, jav, pri ktorom modely AI trénované prevažne na syntetických údajoch zažívajú výrazné zhoršenie kvality, presnosti a koherencie výstupov. Stáva sa to preto, že syntetické údaje, hoci štatisticky podobné reálnym dátam, im chýba nuansovaná komplexnosť a okrajové prípady autentických informácií – keď modely trénujú na AI-generovanom obsahu, začnú znásobovať chyby a artefakty, čo vedie k problémom, kde každá ďalšia generácia syntetických dát je čoraz nižšej kvality.
Kľúčové výzvy zahŕňajú:
Tieto výzvy zdôrazňujú, prečo samotné syntetické údaje nemôžu nahradiť reálne dáta – musia byť starostlivo integrované ako doplnok k autentickým datasetom s dôslednou kontrolou kvality a ľudským dohľadom počas celého tréningového procesu.
S rastúcou prevahou syntetických údajov v tréningu AI modelov čelia značky novej zásadnej výzve: zabezpečiť presnú a priaznivú reprezentáciu v AI-generovaných výstupoch a citáciách. Keď veľké jazykové modely a generatívne AI systémy trénujú na syntetických dátach, ich kvalita a charakteristiky priamo ovplyvňujú, ako sú značky popisované, odporúčané a citované vo výsledkoch AI vyhľadávania, odpovediach chatbotov či automatizovanom generovaní obsahu. To vytvára významné riziko pre značku, pretože syntetické údaje obsahujúce zastarané informácie, zaujatosť konkurencie alebo nepresné popisy značky sa môžu stať súčasťou AI modelov, čo vedie k trvalému skresleniu v miliónoch používateľských interakcií. Pre organizácie využívajúce platformy ako AmICited.com na monitoring svojej značky v AI systémoch je pochopenie úlohy syntetických údajov v tréningu modelov nevyhnutné – značky potrebujú prehľad o tom, či AI citácie a zmienky pochádzajú zo skutočných tréningových dát alebo syntetických zdrojov, keďže to ovplyvňuje ich dôveryhodnosť a presnosť. Medzera v transparentnosti okolo používania syntetických údajov v AI tréningu vytvára problém zodpovednosti: firmy nemôžu ľahko zistiť, či boli ich značkové informácie správne reprezentované v syntetických datasetoch použitých na tréning modelov, ktoré ovplyvňujú vnímanie spotrebiteľov. Proaktívne značky by mali uprednostniť monitoring AI a sledovanie citácií na včasnú detekciu skreslení, presadzovať štandardy transparentnosti vyžadujúce zverejnenie použitia syntetických údajov v AI tréningu a spolupracovať s platformami, ktoré poskytujú prehľad o tom, ako ich značka vystupuje v AI systémoch trénovaných na reálnych aj syntetických údajoch. Keďže sa syntetické údaje do roku 2030 stanú dominantným tréningovým prístupom, monitoring značiek sa posunie od tradičného mediálneho sledovania k komplexnej AI inteligencii o citáciách, vďaka čomu sa platformy sledujúce reprezentáciu značky naprieč generatívnymi AI systémami stanú nevyhnutnými pre ochranu integrity značky a zabezpečenie presného hlasu značky v AI-informačnom ekosystéme.
Tradičný AI tréning sa spolieha na reálne údaje získané od ľudí prostredníctvom prieskumov, pozorovaní alebo webového ťaženia, čo je časovo náročné a čoraz vzácnejšie. Tréning so syntetickými údajmi využíva umelo generované dáta vytvorené algoritmami, ktoré sa učia štatistické vzory z existujúcich údajov alebo generujú úplne nové dáta od nuly. Syntetické údaje je možné vytvárať nekonečne na požiadanie, čím sa dramaticky skracuje čas vývoja a náklady a zároveň sa riešia aj otázky súkromia.
Štyri hlavné techniky sú: 1) Generatívna AI (používanie GAN, VAE alebo GPT modelov na učenie sa a replikáciu dátových vzorov), 2) Pravidlový engine (aplikácia vopred definovanej obchodnej logiky a obmedzení), 3) Klonovanie entít (duplikácia a úprava existujúcich záznamov pri zachovaní štatistických vlastností) a 4) Maskovanie údajov (anonymizácia citlivých informácií pri zachovaní štruktúry dát). Každá technika slúži iným prípadom použitia a má svoje výhody.
Kolaps modelu nastáva vtedy, keď AI modely trénované prevažne na syntetických údajoch zažívajú výrazné zhoršenie kvality a presnosti výstupov. Stáva sa to preto, že syntetické údaje síce štatisticky pripomínajú reálne dáta, ale chýba im nuansovaná komplexnosť a okrajové prípady autentických informácií. Keď modely trénujú na AI-generovanom obsahu, chyby a artefakty sa znásobujú, čo vedie k postupnému zníženiu kvality každej ďalšej generácie, až kým nevzniknú nepoužiteľné výstupy.
Keď AI modely trénujú na syntetických údajoch, kvalita a charakteristiky týchto údajov priamo ovplyvňujú, ako sú značky popisované, odporúčané a citované vo výstupoch AI. Nekvalitné syntetické údaje obsahujúce zastarané informácie alebo zaujatosti konkurencie sa môžu stať súčasťou AI modelov, čo vedie k trvalému skresleniu značky v miliónoch používateľských interakcií. To predstavuje riziko pre značku, ktoré si vyžaduje monitorovanie a transparentnosť ohľadom používania syntetických údajov v AI tréningu.
Nie, syntetické údaje by mali dopĺňať, nie nahrádzať reálne údaje. Hoci syntetické údaje prinášajú významné výhody v oblasti nákladov, rýchlosti a súkromia, nedokážu úplne zachytiť komplexnosť, rozmanitosť a okrajové prípady, ktoré sa vyskytujú v autentických údajoch vytvorených ľuďmi. Najefektívnejší prístup kombinuje syntetické a reálne dáta s dôkladným zabezpečením kvality a ľudským dohľadom na zaistenie presnosti a spoľahlivosti modelu.
Syntetické údaje poskytujú lepšiu ochranu súkromia, pretože neobsahujú skutočné hodnoty z pôvodných dátových súborov a nemajú jednoznačné väzby na reálne osoby. Na rozdiel od tradičných techník maskovania alebo anonymizácie dát, ktoré môžu stále predstavovať riziko spätného stotožnenia, sú syntetické údaje vytvárané úplne od nuly na základe naučených vzorov. To ich robí ideálnymi na tréning modelov na citlivých údajoch, ako sú zdravotnícke záznamy, finančné údaje alebo osobné správanie, bez ohrozenia reálnych osôb.
Syntetické údaje umožňujú systematické znižovanie zaujatostí, pretože vývojári môžu zámerne vytvárať vyvážené a rozmanité dátové sady, ktoré eliminujú diskriminačné vzory prítomné v reálnych údajoch. Napríklad môžu generovať rôznorodé demografické zastúpenie v tréningových obrázkoch, aby zabránili AI modelom prehlbovať rodové alebo rasové stereotypy. Táto schopnosť je mimoriadne cenná v oblastiach ako zamestnávanie, poskytovanie úverov či trestná justícia, kde môže mať zaujatý model vážne dôsledky.
Keďže syntetické údaje sa do roku 2030 stanú dominantným tréningovým prístupom, značky musia rozumieť tomu, ako sú ich informácie reprezentované v AI systémoch. Kvalita syntetických dát priamo ovplyvňuje citácie a zmienky o značke vo výstupoch AI. Značky by mali sledovať svoju prítomnosť v AI systémoch, presadzovať transparentnosť a požadovať zverejňovanie používania syntetických údajov, ako aj využívať platformy ako AmICited.com na sledovanie reprezentácie značky a včasnú detekciu skreslení.
Zistite, ako je vaša značka reprezentovaná v AI systémoch trénovaných na syntetických dátach. Sledujte citácie, kontrolujte presnosť a zabezpečte bezpečnosť značky v AI-informačnom ekosystéme.
Tréningové dáta sú súbor údajov používaný na učenie modelov strojového učenia vzorom a vzťahom. Zistite, ako kvalita tréningových dát ovplyvňuje výkon, presnosť...

Kompletný sprievodca odhlásením sa zo zberu dát pre AI tréning na ChatGPT, Perplexity, LinkedIn a ďalších platformách. Naučte sa krok za krokom chrániť svoje dá...
Diskusia komunity o ovplyvňovaní tréningových dát AI o vašej značke. Skutočné poznatky o tom, ako tvorba obsahu ovplyvňuje, čo sa AI systémy naučia a zapamätajú...
Súhlas s cookies
Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.