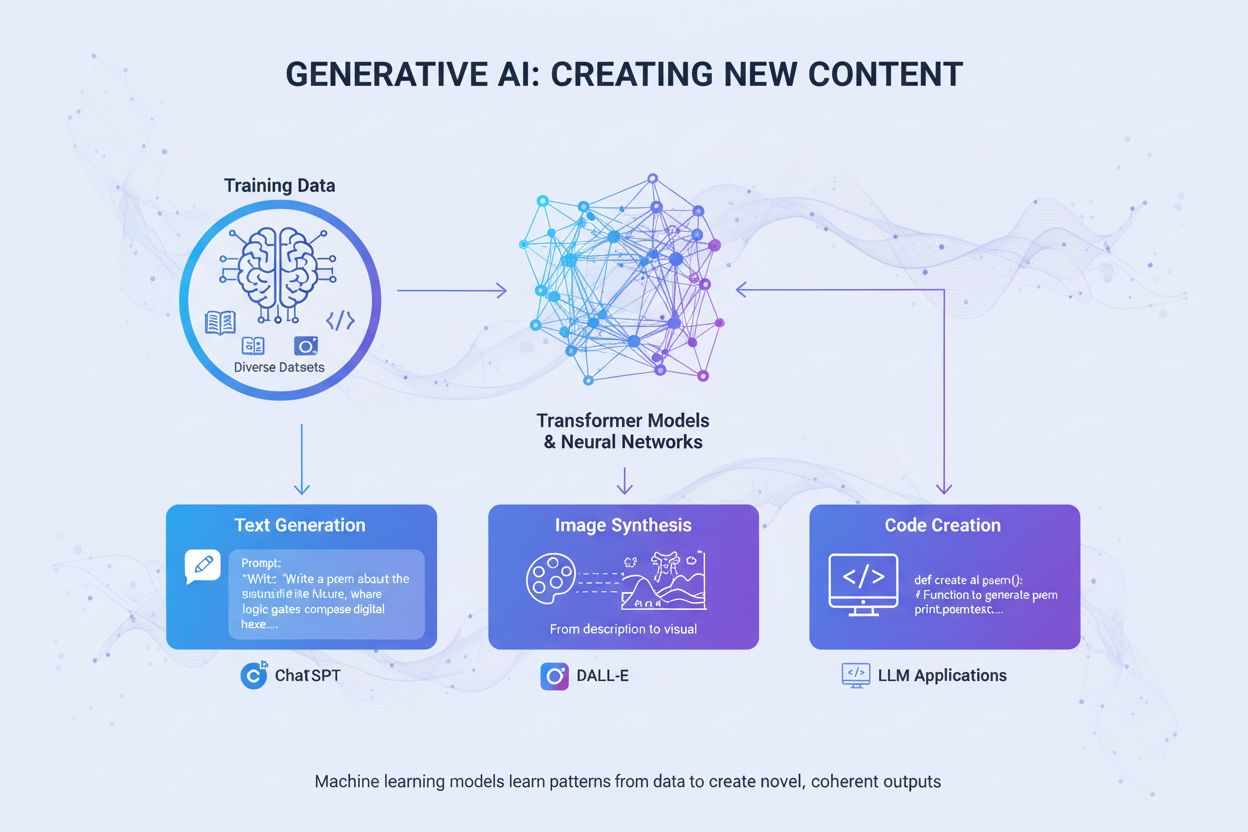
IA Generativa
IA generativa cria novos conteúdos a partir de dados de treinamento usando redes neurais. Saiba como funciona, suas aplicações no ChatGPT e DALL-E, e por que mo...
13 min de leitura

O treinamento com dados sintéticos é o processo de treinar modelos de IA utilizando dados gerados artificialmente em vez de informações reais criadas por humanos. Essa abordagem resolve a escassez de dados, acelera o desenvolvimento de modelos e preserva a privacidade, ao mesmo tempo em que introduz desafios como colapso de modelo e alucinações que exigem gerenciamento e validação cuidadosos.
O treinamento com dados sintéticos é o processo de treinar modelos de IA utilizando dados gerados artificialmente em vez de informações reais criadas por humanos. Essa abordagem resolve a escassez de dados, acelera o desenvolvimento de modelos e preserva a privacidade, ao mesmo tempo em que introduz desafios como colapso de modelo e alucinações que exigem gerenciamento e validação cuidadosos.
O treinamento com dados sintéticos refere-se ao processo de treinar modelos de inteligência artificial utilizando dados gerados artificialmente, em vez de informações reais criadas por humanos. Diferente do treinamento tradicional de IA, que depende de conjuntos de dados autênticos coletados por pesquisas, observações ou mineração na web, os dados sintéticos são criados por algoritmos e métodos computacionais que aprendem padrões estatísticos de dados existentes ou geram dados totalmente novos do zero. Essa mudança fundamental na metodologia de treinamento resolve um desafio crítico no desenvolvimento moderno de IA: o crescimento exponencial das demandas computacionais superou a capacidade humana de gerar dados reais suficientes, com pesquisas indicando que os dados de treinamento gerados por humanos podem se esgotar nos próximos anos. O treinamento com dados sintéticos oferece uma alternativa escalável e econômica, que pode ser gerada infinitamente sem os processos demorados de coleta, rotulagem e limpeza de dados que consomem até 80% das linhas do tempo de desenvolvimento tradicional de IA.
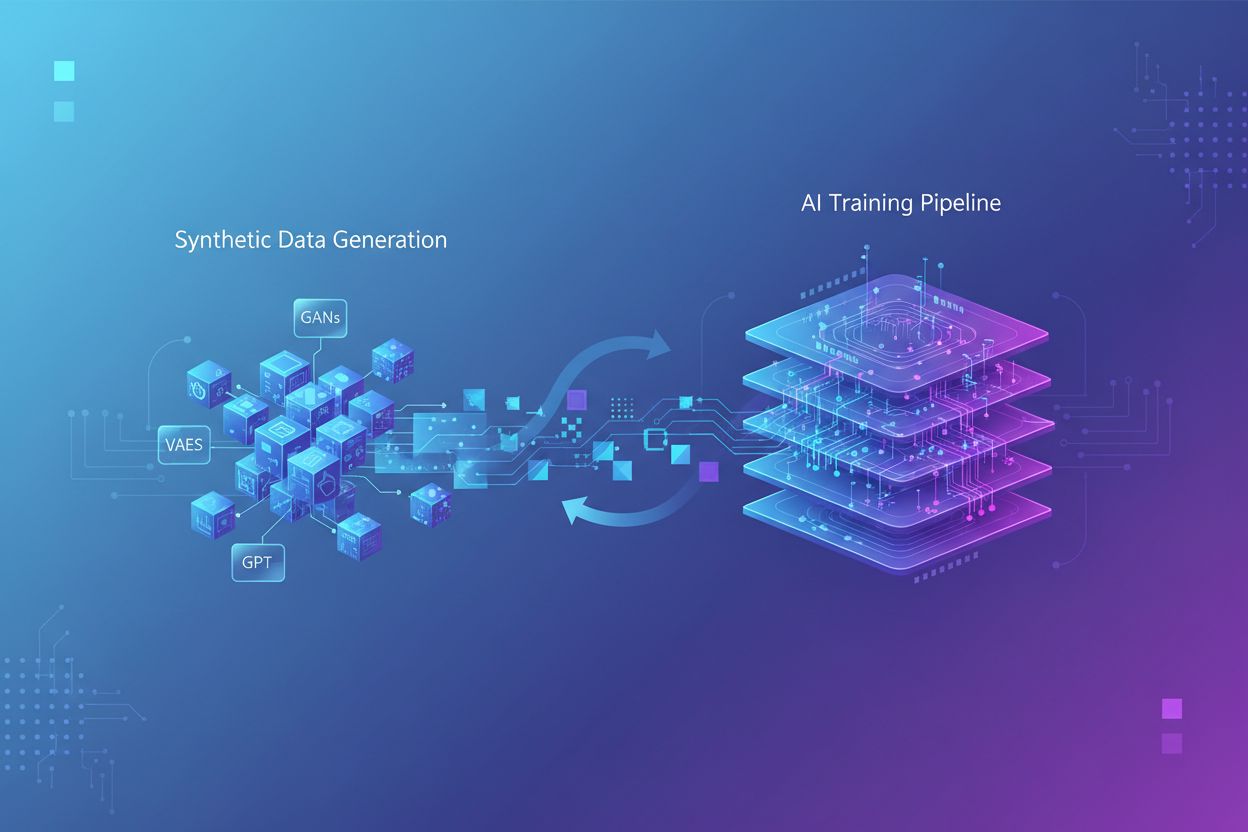
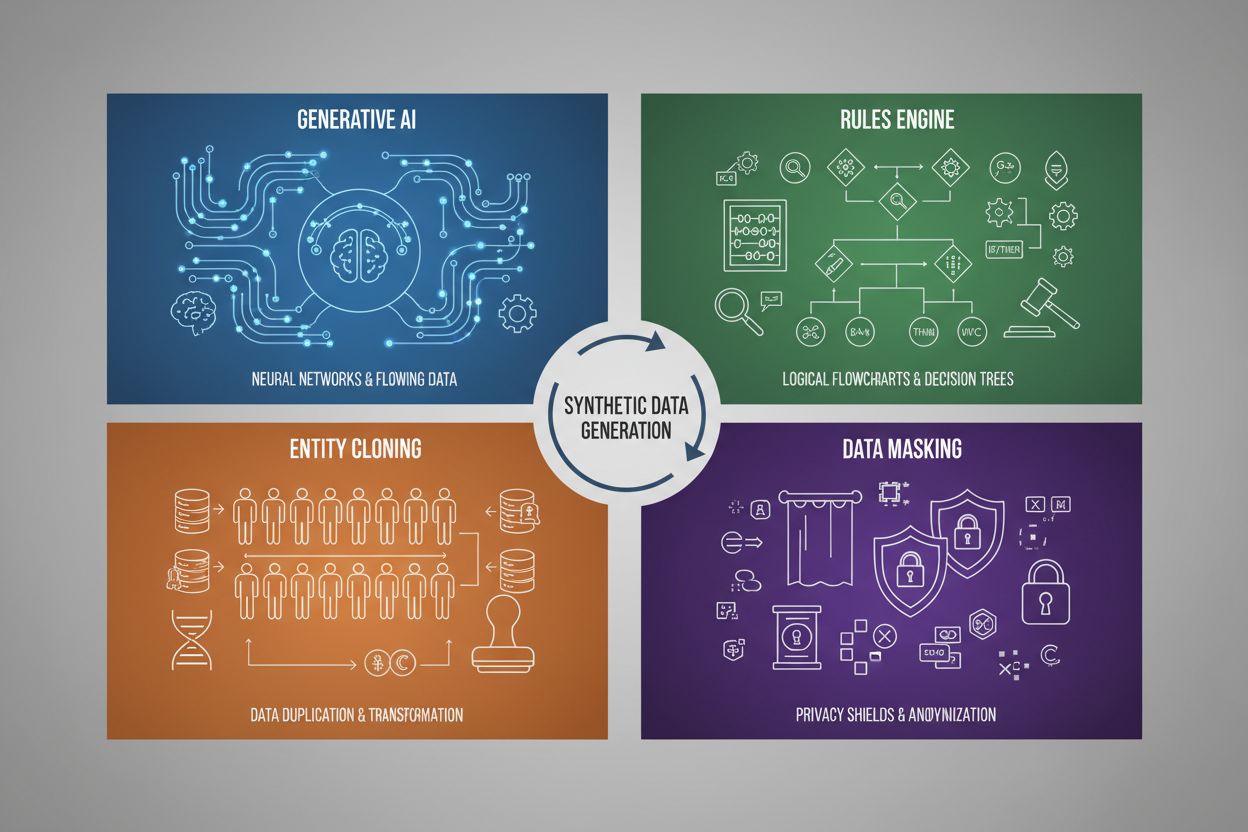
A geração de dados sintéticos emprega quatro técnicas principais, cada uma com mecanismos e aplicações distintas:
| Técnica | Como Funciona | Caso de Uso |
|---|---|---|
| IA Generativa (GANs, VAEs, GPT) | Utiliza modelos de deep learning para aprender padrões estatísticos e distribuições de dados reais, gerando novas amostras sintéticas que mantêm as mesmas propriedades e relações estatísticas. GANs utilizam redes adversariais onde um gerador cria dados falsos enquanto um discriminador avalia a autenticidade, produzindo resultados cada vez mais realistas. | Treinamento de grandes modelos de linguagem como o ChatGPT, geração de imagens sintéticas com o DALL-E, criação de conjuntos de textos diversos para tarefas de processamento de linguagem natural |
| Motor de Regras | Aplica regras lógicas e restrições pré-definidas para gerar dados que sigam lógica de negócios específica, conhecimento de domínio ou requisitos regulatórios. Esta abordagem determinística garante que os dados gerados sigam padrões e relações conhecidos sem exigir aprendizado de máquina. | Dados de transações financeiras, registros de saúde com requisitos regulatórios específicos, dados de sensores industriais com parâmetros operacionais conhecidos |
| Clonagem de Entidades | Duplica e modifica registros reais existentes aplicando transformações, perturbações ou variações para criar novas instâncias, preservando as propriedades e relações estatísticas principais. Essa técnica mantém a autenticidade dos dados enquanto expande o tamanho do conjunto de dados. | Expansão de conjuntos limitados em setores regulados, criação de dados de treinamento para diagnóstico de doenças raras, aumento de conjuntos com poucos exemplos de classes minoritárias |
| Mascaramento e Anonimização de Dados | Oculta informações sensíveis de identificação pessoal (PII) preservando a estrutura e relações estatísticas dos dados por meio de técnicas como tokenização, criptografia ou substituição de valores. Isso cria versões sintéticas e privativas dos dados reais. | Conjuntos de dados de saúde e financeiros, dados comportamentais de clientes, informações pessoais sensíveis em contextos de pesquisa |
O treinamento com dados sintéticos proporciona reduções substanciais de custos ao eliminar processos caros de coleta, anotação e limpeza de dados, que tradicionalmente consomem muitos recursos e tempo. As organizações podem gerar amostras ilimitadas sob demanda, acelerando drasticamente os ciclos de desenvolvimento de modelos e permitindo iteração e experimentação rápidas sem esperar pela coleta de dados reais. A técnica oferece poderosas capacidades de aumento de dados, permitindo aos desenvolvedores expandir conjuntos limitados e criar conjuntos de treinamento balanceados que solucionam problemas de desbalanceamento de classes—uma questão crítica quando certas categorias estão sub-representadas nos dados reais. Os dados sintéticos são particularmente valiosos para enfrentar a escassez de dados em domínios especializados como imagens médicas, diagnóstico de doenças raras ou testes de veículos autônomos, onde coletar exemplos reais suficientes é proibitivamente caro ou eticamente desafiador. A preservação da privacidade representa uma grande vantagem, pois os dados sintéticos podem ser gerados sem expor informações pessoais sensíveis, sendo ideais para treinar modelos com registros de saúde, dados financeiros ou outras informações regulamentadas. Além disso, os dados sintéticos permitem a redução sistemática de viés, possibilitando a criação intencional de conjuntos de dados equilibrados e diversos para combater padrões discriminatórios presentes nos dados reais—por exemplo, gerando representações demográficas diversas em imagens de treinamento para impedir que modelos perpetuem estereótipos de gênero ou raça em aplicações como contratação, crédito ou justiça criminal.
Apesar do potencial, o treinamento com dados sintéticos introduz desafios técnicos e práticos significativos que podem comprometer o desempenho do modelo se não forem gerenciados cuidadosamente. A preocupação mais crítica é o colapso de modelo, fenômeno em que modelos de IA treinados extensivamente com dados sintéticos apresentam degradação severa na qualidade, precisão e coerência das respostas. Isso ocorre porque, apesar de estatisticamente semelhantes, os dados sintéticos carecem da complexidade e dos casos extremos presentes em informações autênticas geradas por humanos—quando modelos são treinados com conteúdo gerado por IA, eles acabam amplificando erros e artefatos, gerando um problema crescente em que cada geração de dados sintéticos se torna progressivamente de menor qualidade.
Principais desafios incluem:
Esses desafios reforçam por que os dados sintéticos não podem substituir os dados reais—devem ser integrados cuidadosamente como complemento a conjuntos autênticos, com rigorosa garantia de qualidade e supervisão humana durante todo o processo de treinamento.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Com o aumento da prevalência de dados sintéticos no treinamento de modelos de IA, as marcas enfrentam um novo desafio crítico: garantir representação precisa e favorável em resultados e citações gerados por IA. Quando grandes modelos de linguagem e sistemas de IA generativa são treinados com dados sintéticos, a qualidade e as características desses dados influenciam diretamente como as marcas são descritas, recomendadas e citadas nos resultados de buscas, respostas de chatbots e geração automatizada de conteúdo. Isso cria uma preocupação significativa de segurança de marca, pois dados sintéticos que contenham informações desatualizadas, viés de concorrentes ou descrições imprecisas podem ser incorporados aos modelos, levando a uma má representação persistente em milhões de interações. Para organizações que utilizam plataformas como o AmICited.com para monitorar a presença da marca em sistemas de IA, entender o papel dos dados sintéticos no treinamento de modelos torna-se essencial—as marcas precisam de visibilidade sobre se as citações e menções em IA têm origem em dados reais ou sintéticos, já que isso afeta credibilidade e precisão. A falta de transparência sobre o uso de dados sintéticos no treinamento de IA cria desafios de responsabilização: as empresas não conseguem facilmente determinar se as informações de suas marcas foram representadas com precisão em conjuntos sintéticos usados para treinar modelos que influenciam a percepção do consumidor. Marcas inovadoras devem priorizar o monitoramento de IA e rastreamento de citações para detectar distorções precocemente, defender padrões de transparência que exijam divulgação do uso de dados sintéticos no treinamento de IA e trabalhar com plataformas que ofereçam insights sobre como sua marca aparece em sistemas de IA treinados tanto com dados reais quanto sintéticos. À medida que os dados sintéticos se tornam o paradigma dominante de treinamento até 2030, o monitoramento de marca migrará do rastreamento tradicional de mídia para uma inteligência abrangente de citações em IA, tornando indispensáveis plataformas que acompanham a representação da marca em sistemas de IA generativa para proteger a integridade e garantir a voz correta da marca no ecossistema informacional impulsionado por IA.
Descubra como sua marca é representada em sistemas de IA treinados com dados sintéticos. Acompanhe citações, monitore a precisão e garanta a segurança da marca no ecossistema de informações impulsionado por IA.
IA generativa cria novos conteúdos a partir de dados de treinamento usando redes neurais. Saiba como funciona, suas aplicações no ChatGPT e DALL-E, e por que mo...

Dados de treinamento são o conjunto de dados usado para ensinar modelos de ML padrões e relações. Saiba como a qualidade dos dados de treinamento impacta o dese...
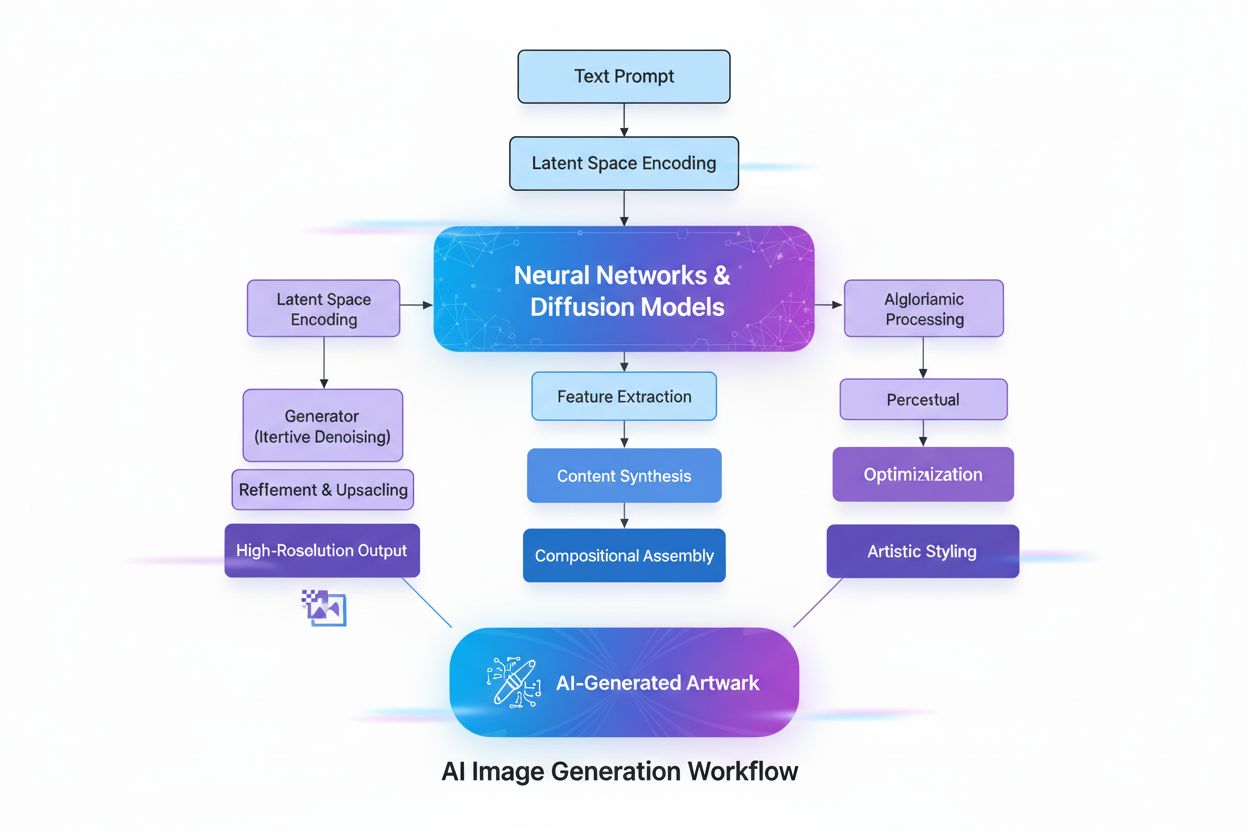
Saiba o que são imagens geradas por IA, como são criadas usando modelos de difusão e redes neurais, suas aplicações em marketing e design, e as considerações ét...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.