
Träningsdata
Träningsdata är den datamängd som används för att lära ML-modeller mönster och samband. Lär dig hur kvaliteten på träningsdata påverkar AI-modellers prestanda, ...
10 min läsning

Träning med syntetisk data är processen att träna AI-modeller med artificiellt genererad data istället för verklig, människoskapad information. Denna metod hanterar dataskräv, påskyndar modellutvecklingen och bevarar integriteten, men introducerar utmaningar som modellkollaps och hallucinationer som kräver noggrann hantering och validering.
Träning med syntetisk data är processen att träna AI-modeller med artificiellt genererad data istället för verklig, människoskapad information. Denna metod hanterar dataskräv, påskyndar modellutvecklingen och bevarar integriteten, men introducerar utmaningar som modellkollaps och hallucinationer som kräver noggrann hantering och validering.
Träning med syntetisk data avser processen att träna artificiella intelligensmodeller med artificiellt genererad data istället för verklig, människoskapad information. Till skillnad från traditionell AI-träning som bygger på autentiska dataset insamlade via enkäter, observationer eller webbskrapning, skapas syntetisk data med algoritmer och beräkningsmetoder som lär sig statistiska mönster från befintlig data eller genererar helt ny data från grunden. Detta grundläggande skifte i träningsmetodik hanterar en kritisk utmaning inom modern AI-utveckling: den exponentiella ökningen av beräkningskrav har överträffat mänsklighetens förmåga att generera tillräckligt med verklig data, och forskning visar att människoskapad träningsdata kan vara uttömd inom några år. Träning med syntetisk data erbjuder ett skalbart, kostnadseffektivt alternativ som kan genereras oändligt utan de tidskrävande processerna för datainsamling, märkning och rensning som tar upp till 80 % av traditionella AI-utvecklingsscheman.
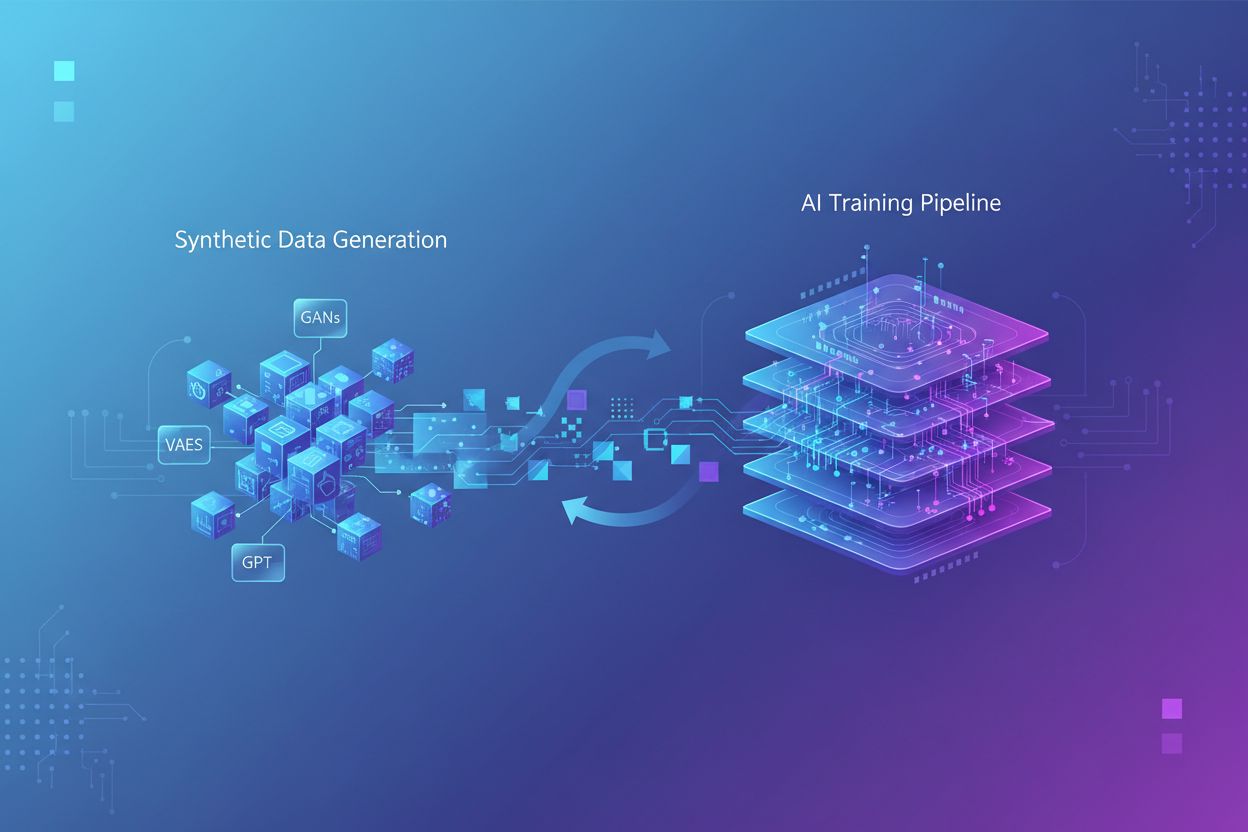
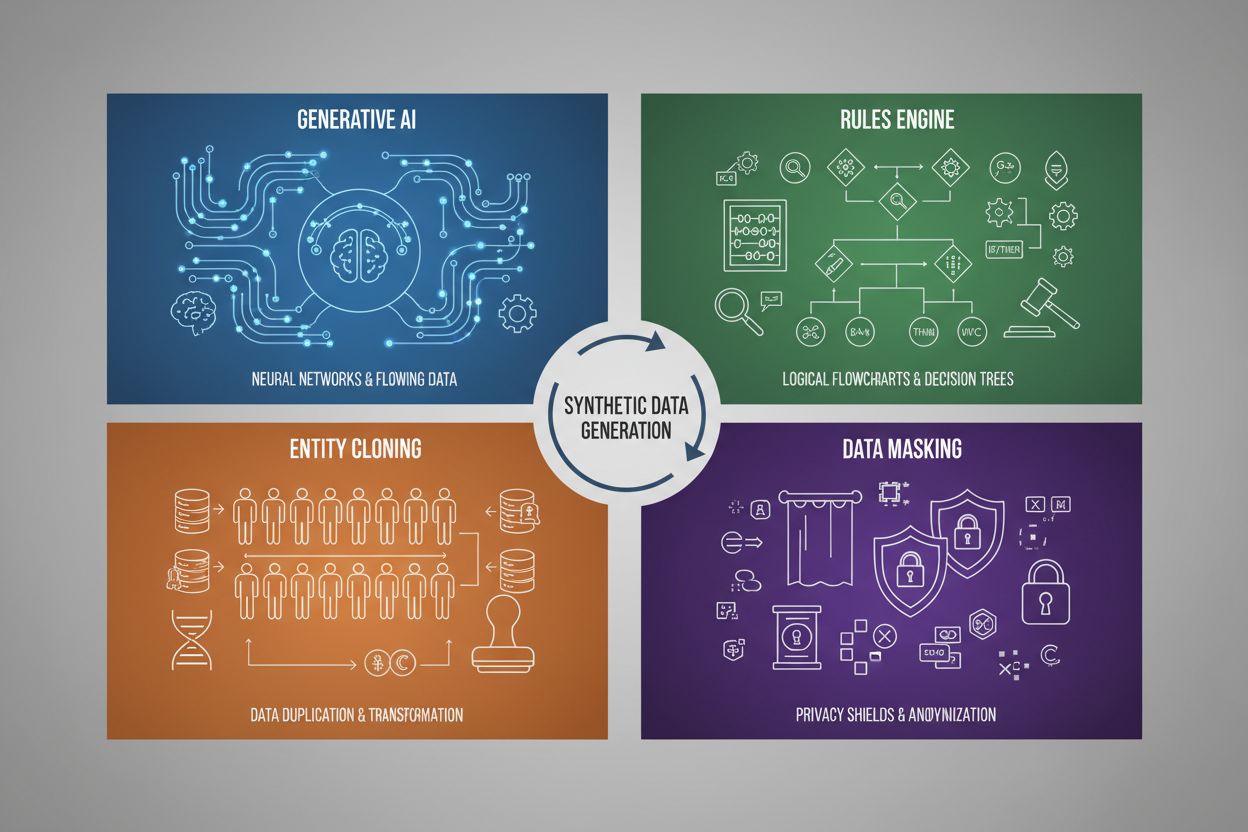
Generering av syntetisk data använder fyra huvudsakliga tekniker, som var och en har olika mekanismer och användningsområden:
| Teknik | Hur det fungerar | Användningsområde |
|---|---|---|
| Generativ AI (GANs, VAEs, GPT) | Använder djupinlärningsmodeller för att lära sig statistiska mönster och fördelningar från verklig data, och genererar sedan nya syntetiska prover som bibehåller samma statistiska egenskaper och relationer. GANs använder sig av konkurrerande nätverk där en generator skapar falsk data medan en diskriminator bedömer äkthet, vilket leder till alltmer realistisk output. | Träning av stora språkmodeller som ChatGPT, generering av syntetiska bilder med DALL-E, skapande av mångsidiga textdataset för NLP-uppgifter |
| Regelmotor | Använder fördefinierade logiska regler och begränsningar för att generera data som följer specifik affärslogik, domänkunskap eller regulatoriska krav. Denna deterministiska metod säkerställer att genererad data följer kända mönster och relationer utan behov av maskininlärning. | Finansiella transaktionsdata, journaler med särskilda lagkrav, sensordata från tillverkning med kända driftparametrar |
| Entitetskloning | Duplicerar och modifierar befintliga dataposter genom att applicera transformationer, störningar eller variationer för att skapa nya instanser med bibehållna statistiska egenskaper och relationer. Tekniken bevarar dataautenticitet samtidigt som datasetets storlek ökas. | Utökning av begränsade dataset i reglerade branscher, skapande av träningsdata för sällsynta sjukdomsdiagnoser, förstärkning av dataset med otillräckliga minoritetsklasser |
| Datamaskering & Anonymisering | Döljer känslig personidentifierbar information (PII) samtidigt som datastruktur och statistiska relationer bibehålls, genom tekniker som tokenisering, kryptering eller värdesubstitution. Detta skapar integritetsskyddade syntetiska versioner av verklig data. | Journaler och finansiella dataset, kundbeteendedata, personkänslig information i forskningssammanhang |
Träning med syntetisk data ger avsevärda kostnadsbesparingar då den eliminerar dyra processer för datainsamling, annotering och rensning som traditionellt kräver stora resurser och tid. Organisationer kan generera obegränsade träningsprover på begäran, vilket kraftigt påskyndar modellutvecklingscykler och möjliggör snabb iteration och experiment utan att behöva vänta på verklig datainsamling. Tekniken ger kraftfulla möjligheter till dataförstärkning, så utvecklare kan utöka små dataset och skapa balanserade träningsuppsättningar som hanterar problem med obalans – ett kritiskt problem när vissa kategorier är underrepresenterade i verklig data. Syntetisk data är särskilt värdefull för att åtgärda dataskräv i specialiserade områden som medicinsk bilddiagnostik, sällsynta sjukdomsdiagnoser eller tester av autonoma fordon, där det är orimligt dyrt eller etiskt svårt att samla tillräckligt många verkliga exempel. Integritetsskydd är en stor fördel, eftersom syntetisk data kan genereras utan att exponera känslig personlig information, vilket gör den idealisk för att träna modeller på journaler, finansiell data eller annan reglerad information. Dessutom möjliggör syntetisk data systematisk biasreducering eftersom utvecklare medvetet kan skapa balanserade, mångsidiga dataset som motverkar diskriminerande mönster i verklig data – till exempel genom att generera mångsidiga demografiska representationer i träningsbilder för att förhindra att AI-modeller förstärker köns- eller rasstereotyper inom rekrytering, utlåning eller rättsväsendet.
Trots sina fördelar introducerar träning med syntetisk data betydande tekniska och praktiska utmaningar som kan försämra modellens prestanda om de inte hanteras noggrant. Den mest kritiska risken är modellkollaps, ett fenomen där AI-modeller som tränas mycket på syntetisk data får kraftig försämring i outputkvalitet, noggrannhet och sammanhang. Detta sker eftersom syntetisk data, även om den är statistiskt lik verklig data, saknar den nyanserade komplexiteten och undantagen som finns i äkta människoskapad information – när modeller tränas på AI-genererat innehåll börjar de förstärka fel och artefakter, vilket skapar ett ackumulerande problem där varje generation av syntetisk data blir successivt sämre.
Viktiga utmaningar inkluderar:
Dessa utmaningar understryker varför syntetisk data inte kan ersätta verklig data – den måste istället integreras som ett komplement till autentiska dataset, med rigorös kvalitetskontroll och mänsklig översyn under hela träningsprocessen.
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
När syntetisk data blir allt vanligare för AI-modellträning står varumärken inför en ny, kritisk utmaning: att säkerställa korrekt och gynnsam representation i AI-genererade output och citeringar. När stora språkmodeller och generativa AI-system tränas på syntetisk data påverkar kvaliteten och egenskaperna hos denna data direkt hur varumärken beskrivs, rekommenderas och citeras i AI-sökresultat, chatbot-svar och automatiserad innehållsgenerering. Detta skapar en betydande varumärkessäkerhetsrisk, eftersom syntetisk data som innehåller inaktuell information, partiskhet till konkurrenter eller felaktiga varumärkesbeskrivningar kan byggas in i AI-modeller och leda till ihållande felaktig representation i miljontals användarinteraktioner. För organisationer som använder plattformar som AmICited.com för att övervaka sin varumärkesnärvaro i AI-system blir det avgörande att förstå syntetisk datas roll i modellträning – varumärken behöver insyn i om AI-citeringar och omnämnanden härrör från verklig träningsdata eller syntetiska källor, då detta påverkar trovärdighet och noggrannhet. Transparensgapet kring användningen av syntetisk data i AI-träning skapar ansvarighetsproblem: företag kan inte enkelt avgöra om deras varumärkesinformation har representerats korrekt i de syntetiska dataset som används för att träna modeller som påverkar konsumenters uppfattning. Framsynta varumärken bör prioritera AI-övervakning och citeringsspårning för att upptäcka felaktigheter tidigt, arbeta för ökad transparens kring användning av syntetisk data vid AI-träning och samarbeta med plattformar som ger insikter om hur varumärket syns i AI-system tränade både på verklig och syntetisk data. När syntetisk data blir den dominerande träningsmetoden till 2030 kommer varumärkesövervakning att gå från traditionell mediebevakning till omfattande AI-citeringsintelligens, vilket gör plattformar som spårar varumärkesrepresentation över generativa AI-system oumbärliga för att skydda varumärkets integritet och säkerställa korrekt varumärkesröst i det AI-drivna informationsekosystemet.
Upptäck hur ditt varumärke representeras i AI-system som tränats på syntetisk data. Spåra citeringar, övervaka noggrannhet och säkerställ varumärkessäkerhet i det AI-drivna informationsekosystemet.
Träningsdata är den datamängd som används för att lära ML-modeller mönster och samband. Lär dig hur kvaliteten på träningsdata påverkar AI-modellers prestanda, ...
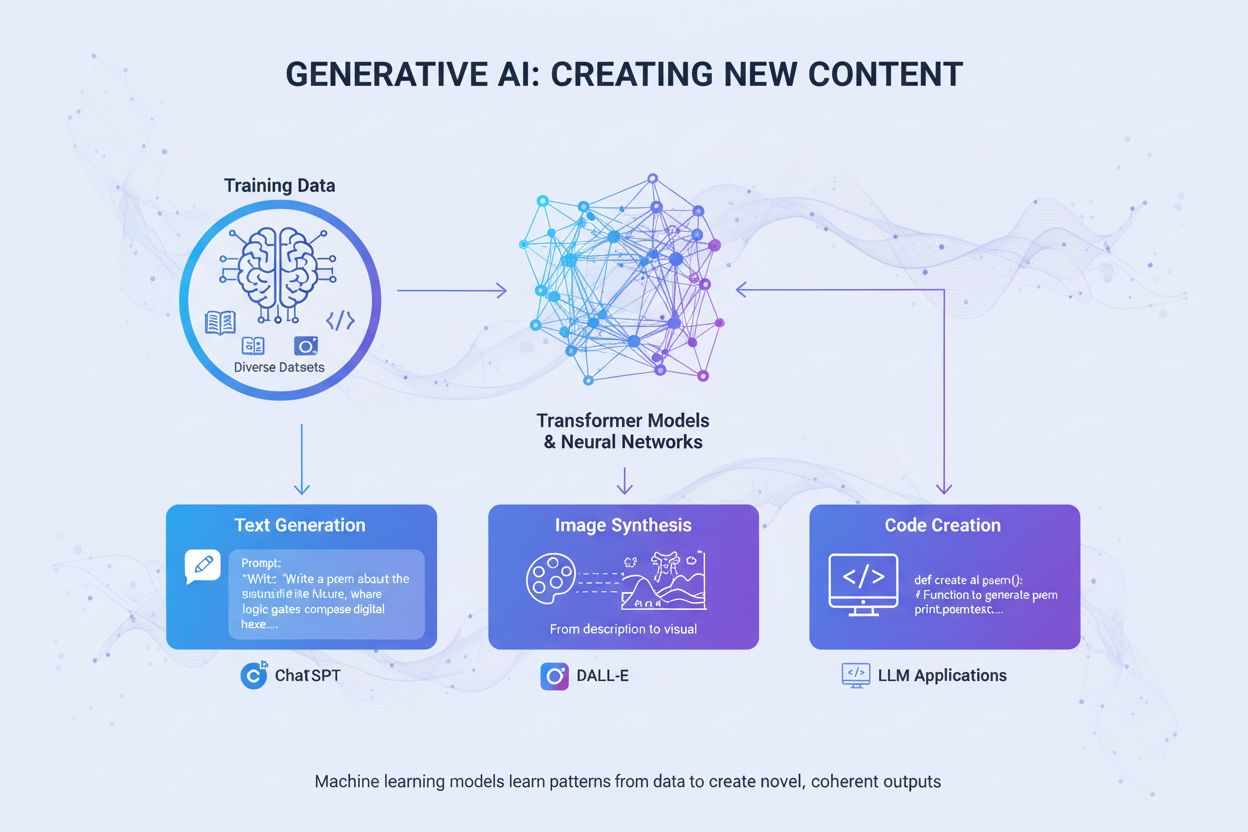
Generativ AI skapar nytt innehåll från träningsdata med hjälp av neurala nätverk. Lär dig hur det fungerar, dess applikationer i ChatGPT och DALL-E, samt varför...
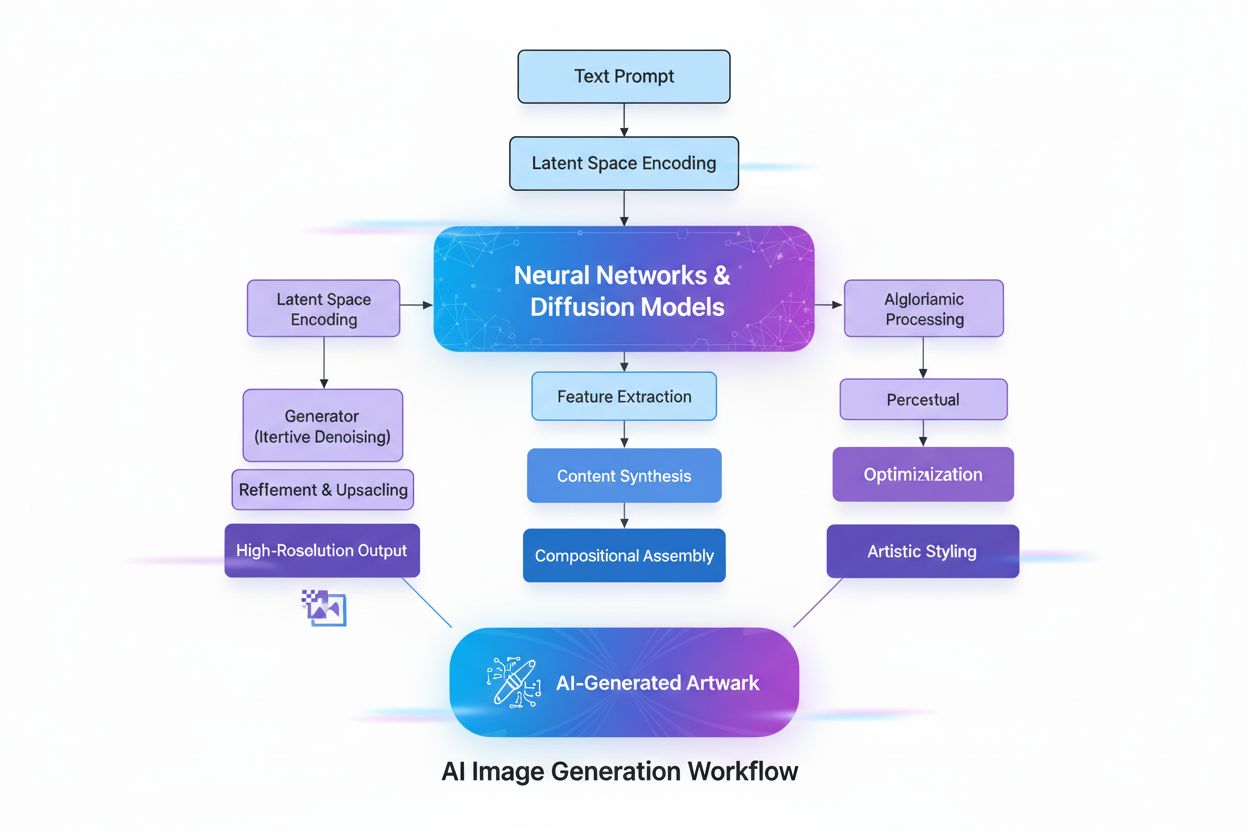
Lär dig vad AI-genererade bilder är, hur de skapas med diffusionsmodeller och neurala nätverk, deras användningsområden inom marknadsföring och design samt de e...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.