
如何在服务器日志中识别AI爬虫:完整检测指南
了解如何在服务器日志中识别并监控GPTBot、PerplexityBot和ClaudeBot等AI爬虫。发现User-Agent字符串、IP验证方法以及跟踪AI流量的最佳实践。...
2 分钟阅读

AI爬虫在HTTP头中发送给Web服务器的标识字符串,用于访问控制、分析追踪,并区分合法AI机器人和恶意爬虫。它标识了爬虫的用途、版本和来源。
AI爬虫在HTTP头中发送给Web服务器的标识字符串,用于访问控制、分析追踪,并区分合法AI机器人和恶意爬虫。它标识了爬虫的用途、版本和来源。
AI爬虫user-agent是一种HTTP头字符串,用于标识为人工智能训练、索引或研究目的访问网站内容的自动化机器人。该字符串是爬虫的数字身份,向Web服务器传递请求者的身份及其意图。user-agent对于AI爬虫至关重要,因为它使网站所有者能够识别、追踪并管控不同AI系统如何访问自己的网站内容。缺乏规范的user-agent标识,将大大增加区分合法AI爬虫与恶意机器人的难度,因此它是负责任的数据抓取和采集实践的重要组成部分。
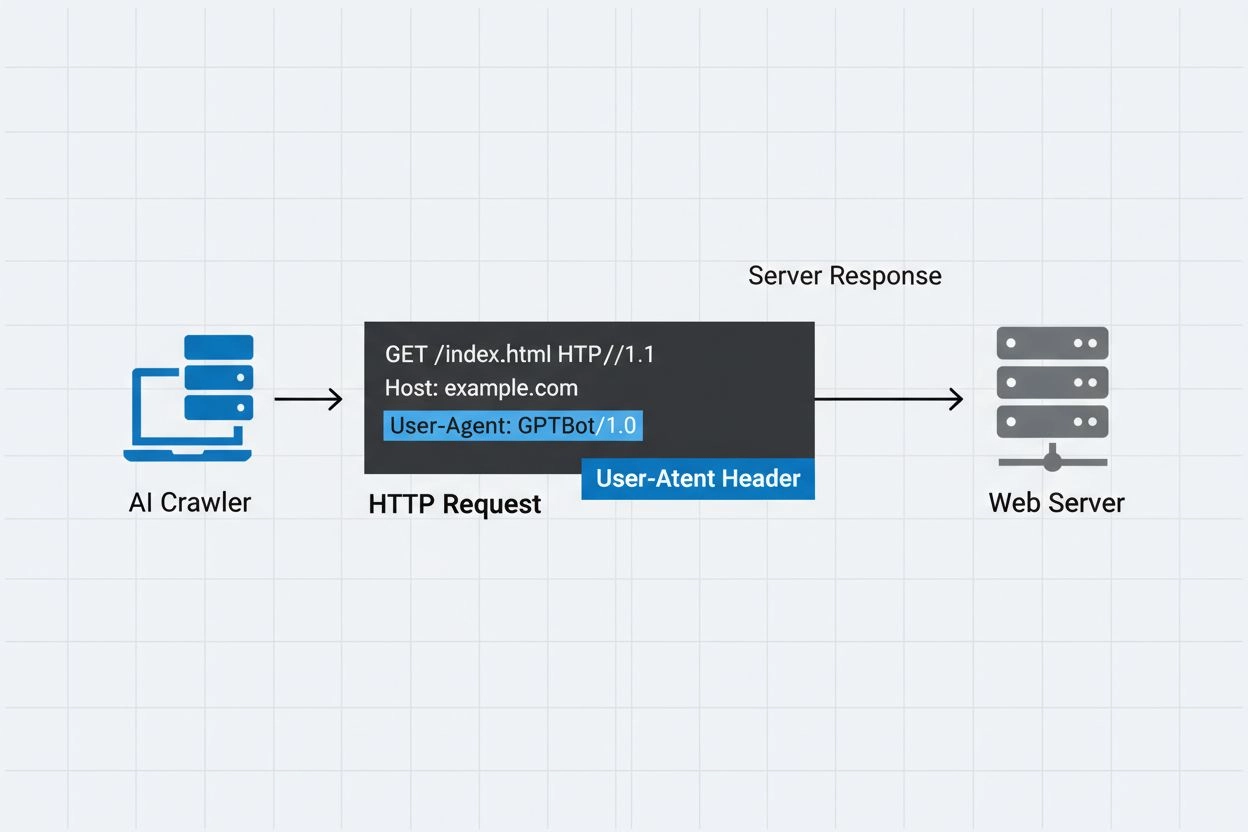
user-agent头是HTTP请求中的关键组成部分,出现在每个浏览器和机器人访问Web资源时发送的请求头中。当爬虫向Web服务器发送请求时,会在HTTP头中包含自身的元数据,其中user-agent字符串是最重要的标识之一。该字符串通常包含爬虫的名称、版本、运营机构,且常附带用于验证的联系URL或邮箱。user-agent让服务器能够识别请求客户端,并决定是否提供内容、限制请求频率或完全阻止访问。以下是主要AI爬虫的user-agent字符串示例:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36; compatible; OAI-SearchBot/1.3; +https://openai.com/searchbot
| 爬虫名称 | 用途 | 示例User-Agent | IP验证 |
|---|---|---|---|
| GPTBot | 训练数据收集 | Mozilla/5.0…compatible; GPTBot/1.3 | OpenAI IP范围 |
| ClaudeBot | 模型训练 | Mozilla/5.0…compatible; ClaudeBot/1.0 | Anthropic IP范围 |
| OAI-SearchBot | 搜索索引 | Mozilla/5.0…compatible; OAI-SearchBot/1.3 | OpenAI IP范围 |
| PerplexityBot | 搜索索引 | Mozilla/5.0…compatible; PerplexityBot/1.0 | Perplexity IP范围 |
多家知名AI公司运营着各自的爬虫,每个爬虫都有独特的user-agent标识和用途。这些爬虫代表了AI生态系统中的不同应用场景:
每个爬虫都有官方的IP范围和文档,网站所有者可据此验证合法性并实施访问控制。
任何客户端都能轻易伪造user-agent字符串,因此仅凭此无法完全认证爬虫身份。恶意爬虫常常冒用知名user-agent来隐藏真实身份,规避网站安全措施或robots.txt限制。为应对这一漏洞,安全专家建议增加IP验证层,检查请求是否来自AI公司公布的官方IP段。新兴的RFC 9421 HTTP消息签名标准则提供了加密验证能力,使爬虫可对请求进行数字签名,服务器据此进行加密认证。然而,鉴别真假爬虫依然具有挑战性,因为有心攻击者还可能通过代理或被攻陷的基础设施伪造user-agent和IP。这场爬虫运营方与重视安全的网站所有者之间的“攻防游戏”,正随着新技术的发展不断演进。
网站所有者可通过robots.txt文件中的user-agent指令细致管控爬虫访问,实现对不同爬虫访问网站不同部分的精细管理。robots.txt通过user-agent标识针对特定爬虫制定自定义规则,使站长可选择性允许或屏蔽部分爬虫。如下为robots.txt配置示例:
User-agent: GPTBot
Disallow: /private
Allow: /
User-agent: ClaudeBot
Disallow: /
但robots.txt存在重要局限:
网站所有者可利用服务器日志追踪并分析AI爬虫活动,洞察哪些AI系统以何频率访问自身内容。通过分析HTTP请求日志并筛选已知AI爬虫user-agent,管理员可了解各AI公司的带宽占用与数据采集模式。日志分析平台、网站分析服务及自定义脚本都可以解析日志,识别爬虫流量、测量请求频率和数据传输量。这对内容创作者和出版者尤其重要,有助于了解自身作品被AI训练的情况,并评估是否需要施加访问限制。像AmICited.com这样的服务,在该生态系统中扮演着关键角色,它监控AI系统如何引用和标注全网内容,为创作者提供AI训练中内容使用的透明度。理解爬虫活动,有助于网站所有者制定内容政策并就数据使用权与AI公司协商。
有效管理AI爬虫访问需多层次结合多种验证和监控手段:
遵循上述实践,网站所有者既可掌控内容,又能支持AI系统的负责任发展。
User-agent是一种HTTP头字符串,用于标识发起Web请求的客户端。它包含请求应用的软件、操作系统及版本信息,无论是浏览器、爬虫还是机器人。该字符串使Web服务器能够识别并追踪访问其内容的不同类型客户端。
User-agent字符串让Web服务器能够识别是哪一个爬虫在访问其内容,使网站所有者能够控制访问、追踪爬虫活动,并区分不同类型机器人。这对于管理带宽、保护内容和了解AI系统如何使用您的数据都至关重要。
可以,user-agent字符串只是HTTP头中的文本值,很容易被伪造。因此,IP验证和HTTP消息签名是重要的补充验证方式,以确认爬虫真实身份并防止恶意机器人冒充合法爬虫。
您可以通过robots.txt中的user-agent指令请求爬虫不访问您的站点,但这并非强制。更强的控制方式包括服务器端验证、IP白名单/黑名单,或同时检查user-agent和IP地址的WAF规则。
GPTBot是OpenAI用于收集如ChatGPT等AI模型训练数据的爬虫,而OAI-SearchBot专为搜索索引和为ChatGPT的搜索功能提供支持。它们的用途、抓取频率和IP范围各不相同,因此需要制定不同的访问控制策略。
请将爬虫的IP地址与运营方公布的官方IP列表进行比对(例如GPTBot可查阅openai.com/gptbot.json)。合法爬虫会公开其IP范围,您可通过防火墙规则或WAF配置验证请求是否来自这些范围。
HTTP消息签名(RFC 9421)是一种加密方法,爬虫用私钥对请求进行签名。服务器则可使用爬虫.well-known目录下的公钥验证签名,从而证明请求的真实性且未被篡改。
AmICited.com监控AI系统如何在GPTs、Perplexity、Google AI Overviews等平台引用和标注您的品牌。它追踪爬虫活动与AI提及,帮助您了解在AI生成答案中的可见度及内容的实际使用情况。
了解如何在服务器日志中识别并监控GPTBot、PerplexityBot和ClaudeBot等AI爬虫。发现User-Agent字符串、IP验证方法以及跟踪AI流量的最佳实践。...

学习如何在服务器日志中识别并监控如 GPTBot、ClaudeBot 和 PerplexityBot 等AI爬虫。完整指南涵盖 user-agent 字符串、IP 验证及实用监控策略。...
了解应在robots.txt中允许或阻止哪些AI爬虫。全面指南涵盖GPTBot、ClaudeBot、PerplexityBot及25+种AI爬虫,并附配置示例。
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.