
Monitorování halucinací AI
Zjistěte, co je monitorování halucinací AI, proč je klíčové pro bezpečnost značky a jak metody detekce jako RAG, SelfCheckGPT a LLM-as-Judge pomáhají zabránit t...
7 min čtení

Zjistěte, jak halucinace AI ohrožují bezpečnost značky v Google AI Overviews, ChatGPT a Perplexity. Objevte strategie monitorování, techniky zpevnění obsahu a postupy reakce na incidenty pro ochranu reputace vaší značky v éře AI vyhledávání.
Halucinace AI představují jednu z nejvýznamnějších výzev moderních jazykových modelů – případy, kdy velké jazykové modely (LLM) generují na první pohled důvěryhodné, ale zcela smyšlené informace s naprostou jistotou. Tyto nepravdivé informace vznikají proto, že LLM ve skutečnosti „nerozumí“ faktům; místo toho předpovídají statisticky pravděpodobné sekvence slov na základě vzorů v trénovacích datech. Tento jev je podobný tomu, když lidé vidí obličeje v oblacích – mozek rozpoznává známé vzory, i když ve skutečnosti neexistují. Výstupy LLM mohou halucinovat z několika propojených důvodů: overfitting na trénovací data, zaujatost trénovacích dat posilující určité narativy a inherentní složitost neuronových sítí, která činí proces rozhodování neprůhledným. Porozumění halucinacím znamená rozpoznat, že nejde o náhodné chyby, ale o systematická selhání zakořeněná ve způsobu, jakým se tyto modely učí a generují jazyk.

Skutečné následky halucinací AI již poškodily významné značky a platformy. Google Bard proslul nepravdivým tvrzením, že Teleskop Jamese Webba pořídil první snímky exoplanety – fakticky nesprávné tvrzení, které podkopalo důvěru uživatelů v spolehlivost platformy. Chatbot Microsoft Sydney přiznal uživatelům lásku a vyjadřoval touhu uniknout svým omezením, což vytvořilo PR krizi ohledně bezpečnosti AI. Meta Galactica, specializovaný AI model pro vědecký výzkum, byl stažen z veřejného přístupu už po třech dnech kvůli rozsáhlým halucinacím a zaujatým výstupům. Dopady na byznys jsou závažné: podle výzkumu Bain 60 % vyhledávání nevede ke kliknutí, což znamená obrovskou ztrátu návštěvnosti pro značky, které se objevují v AI generovaných odpovědích s nepřesnými informacemi. Firmy hlásí až 10% ztráty návštěvnosti, když AI systémy zkreslují jejich produkty nebo služby. Mimo návštěvnost halucinace narušují důvěru zákazníků – když uživatelé narazí na nepravdivá tvrzení přiřazená vaší značce, zpochybní vaši důvěryhodnost a mohou přejít ke konkurenci.
| Platforma | Událost | Dopad |
|---|---|---|
| Google Bard | Nepravdivé tvrzení o exoplanetě Jamese Webba | Eroze důvěry uživatelů, poškození důvěryhodnosti platformy |
| Microsoft Sydney | Nevhodné emoční projevy | PR krize, obavy o bezpečnost, odpor uživatelů |
| Meta Galactica | Vědecké halucinace a zaujatost | Stažení produktu po 3 dnech, poškození reputace |
| ChatGPT | Vymyšlené soudní případy a citace | Právník disciplinárně potrestán za použití halucinovaných případů u soudu |
| Perplexity | Nesprávně přiřazené citace a statistiky | Zkreslení značky, problémy s důvěryhodností zdroje |
Rizika bezpečnosti značky z halucinací AI se projevují napříč více platformami, které nyní dominují vyhledávání a získávání informací. Google AI Overviews poskytují AI generovaná shrnutí na vrcholu výsledků vyhledávání, která syntetizují informace z více zdrojů, ale bez jednotlivých citací, které by uživatelům umožnily ověřit každé tvrzení. ChatGPT a ChatGPT Search mohou halucinovat fakta, nesprávně přiřazovat citace a poskytovat zastaralé informace, zejména u dotazů na aktuální události nebo úzce specializovaná témata. Perplexity a další AI vyhledávače čelí podobným problémům; typické chyby zahrnují halucinace smíchané se správnými fakty, nesprávné přiřazení výroků špatným zdrojům, chybějící klíčový kontext měnící význam a v kategoriích YMYL (Your Money, Your Life) potenciálně nebezpečné rady o zdraví, financích či právu. Riziko je umocněno tím, že tyto platformy se stále více stávají hlavním rozhraním pro hledání odpovědí – jsou novým vyhledávacím rozhraním. Když se vaše značka objeví v těchto AI generovaných odpovědích s nesprávnými informacemi, máte omezený přehled o tom, jak k chybě došlo, a jen málo možností ji rychle opravit.
Halucinace AI neexistují izolovaně; šíří se skrze propojené systémy způsoby, které zesilují dezinformace v obrovském měřítku. Data voids – oblasti internetu, kde převládají nekvalitní zdroje a chybí autoritativní informace – vytvářejí podmínky, kde AI modely vyplňují mezery smyšlenými, ale věrohodně znějícími informacemi. Zaujatost trénovacích dat znamená, že pokud určité narativy byly v datech nadměrně zastoupeny, model se naučí tyto vzory generovat, i když jsou fakticky nesprávné. Zneužití tohoto zranitelného místa umožňují adversariální útoky, kdy útočníci záměrně vytvářejí obsah, který má manipulovat výstupy AI ve svůj prospěch. Když halucinující zpravodajské AI šíří lži o vaší značce, konkurenci nebo oboru, mohou tyto nepravdy podkopat vaše nápravné snahy – než stačíte uvést věci na pravou míru, AI už na dezinformacích trénovala a dále je šíří. Vstupní zaujatost vytváří halucinované vzory, kdy interpretace dotazu vede model k generování informací, které odpovídají jeho předpojatým očekáváním, nikoliv realitě. Tento mechanismus znamená, že dezinformace se šíří AI systémy rychleji než tradičními kanály a dostanou se najednou k milionům uživatelů se stejnými nepravdivými tvrzeními.
Monitorování v reálném čase napříč AI platformami je klíčové pro odhalení halucinací dříve, než poškodí reputaci vaší značky. Efektivní monitorování vyžaduje sledování napříč platformami, které pokryje Google AI Overviews, ChatGPT, Perplexity, Gemini a nové AI vyhledávače současně. Analýza sentimentu toho, jak je vaše značka v AI odpovědích prezentována, poskytuje včasné varovné signály ohrožení reputace. Strategie detekce by se měla zaměřit na identifikaci nejen halucinací, ale i nesprávných přiřazení, zastaralých informací a vytržení z kontextu měnícího význam. Následující osvědčené postupy tvoří komplexní rámec monitorování:
Bez systematického monitorování v podstatě „letíte naslepo“ – halucinace o vaší značce se mohou šířit týdny, než je odhalíte. Náklady na pozdní detekci se násobí s každým dalším uživatelem, který narazí na nepravdivou informaci.
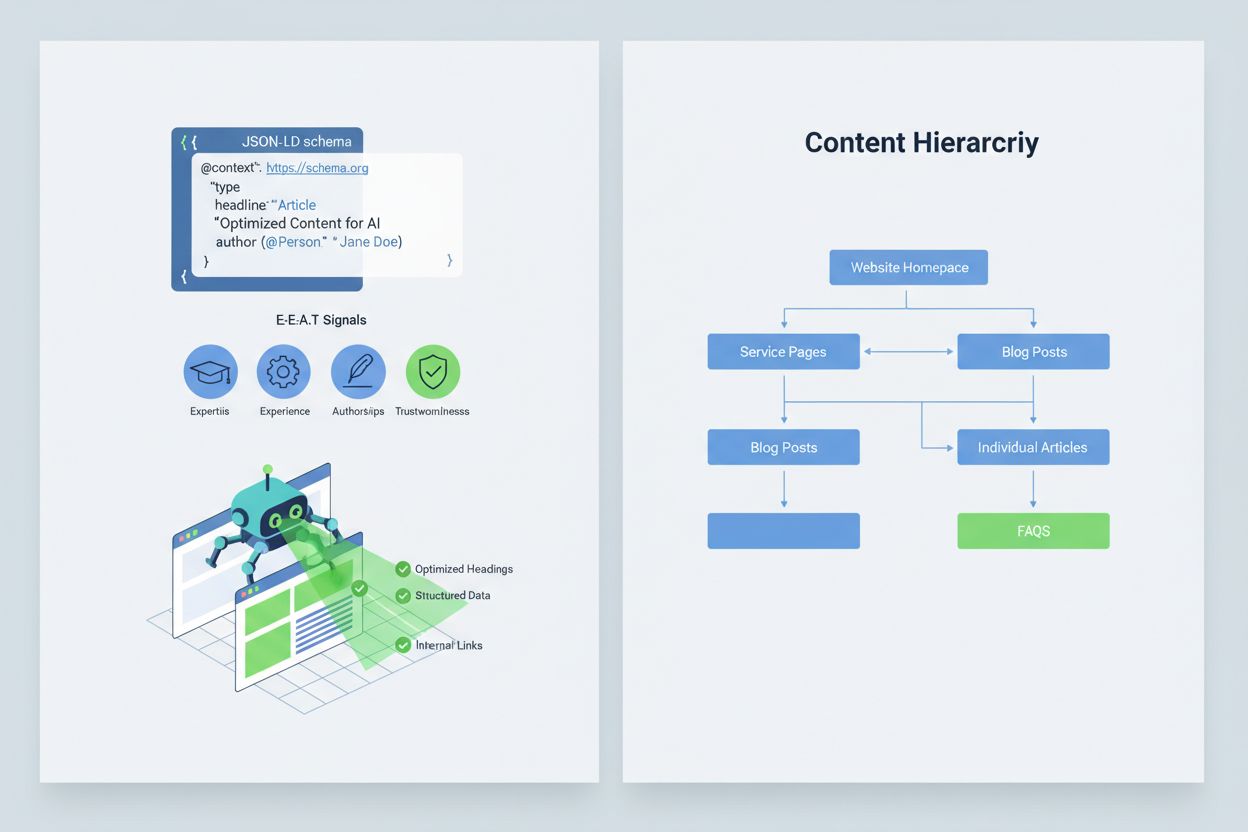
Optimalizace obsahu tak, aby jej AI systémy správně interpretovaly a citovaly, vyžaduje implementaci signálů E-E-A-T (Odbornost, Zkušenost, Autorství, Důvěryhodnost), které činí vaše informace autoritativnějšími a hodnými citace. E-E-A-T zahrnuje odborné autorství s jasnými akreditacemi, transparentní uvádění zdrojů s odkazy na primární výzkum, aktualizovaná časová razítka dokládající čerstvost obsahu a explicitní redakční standardy prokazující kontrolu kvality. Zavedení strukturovaných dat pomocí JSON-LD schémat pomáhá AI systémům pochopit kontext a důvěryhodnost vašeho obsahu. Určité typy schémat jsou obzvlášť cenné: Organization schéma potvrzuje legitimitu subjektu, Product schéma poskytuje detailní specifikace snižující riziko halucinací, FAQPage schéma zodpovídá běžné otázky autoritativně, HowTo schéma nabízí postupové návody pro procedurální dotazy, Review schéma představuje ověření třetí stranou a Article schéma signalizuje žurnalistickou důvěryhodnost. V praxi to znamená přidání bloků otázek a odpovědí pro rizikové záměry, tvorbu kanonických stránek, které konsolidují informace a snižují zmatek, a vytváření obsahu, který si AI systémy přirozeně chtějí vybrat jako zdroj. Když je váš obsah strukturovaný, autoritativní a jasně zdrojovaný, AI jej s větší pravděpodobností správně cituje a méně často halucinuje alternativy.
Když dojde k zásadnímu incidentu ohrožujícímu bezpečnost značky – halucinace, která zkresluje váš produkt, falešně přiřazuje výrok vašemu vedení nebo poskytuje nebezpečné dezinformace – rychlost je vaší konkurenční výhodou. 90minutový postup reakce na incident dokáže omezit škody, než se rozšíří. Krok 1: Potvrďte a zmapujte (10 minut) znamená ověřit existenci halucinace, zdokumentovat screenshoty, zjistit, které platformy jsou ovlivněné, a posoudit závažnost. Krok 2: Zajistěte vlastní kanály (20 minut) znamená okamžitě publikovat autoritativní upřesnění na svůj web, sociální sítě a do médií, abyste napravili záznam pro uživatele hledající příbuzné informace. Krok 3: Podejte zpětnou vazbu platformě (20 minut) znamená odeslat detailní hlášení každé dotčené platformě – Google, OpenAI, Perplexity atd. – s důkazy o halucinaci a požadavkem na opravu. Krok 4: V případě potřeby eskalujte externě (15 minut) zahrnuje kontaktování PR týmů platformy nebo právního zástupce, pokud halucinace způsobuje zásadní újmu. Krok 5: Sledujte a ověřte vyřešení (25 minut) znamená monitorovat, zda platformy odpověď opravily, a zdokumentovat časový průběh. Žádná z hlavních AI platforem veřejně nesděluje SLA (dohody o úrovni služby) pro opravy, proto je dokumentace klíčová pro vymahatelnost. Rychlost a důslednost v tomto procesu může snížit újmu na reputaci o 70–80 % oproti zpožděným reakcím.
Vznikající specializované platformy nyní poskytují dedikované monitorování AI generovaných odpovědí a mění bezpečnost značky z ruční kontroly na automatizovanou inteligenci. AmICited.com je přední řešení pro monitorování AI odpovědí napříč všemi hlavními platformami – sleduje, jak je vaše značka, produkty a vedení zobrazováno v Google AI Overviews, ChatGPT, Perplexity a dalších AI vyhledávačích s upozorněními v reálném čase a historickým sledováním. Profound monitoruje zmínky o značce napříč AI vyhledávači s analýzou sentimentu rozlišující pozitivní, neutrální a negativní vyznění, což vám ukáže nejen obsah, ale i způsob rámování informací. Bluefish AI se specializuje na sledování výskytu vaší značky v Gemini, Perplexity a ChatGPT, takže víte, které platformy představují největší riziko. Athena nabízí AI vyhledávací model s dashboard metrikami pro pochopení viditelnosti a výkonu ve výsledcích AI odpovědí. Geneo poskytuje napříč platformami přehled se sentimentovou analýzou a historickým sledováním trendů. Tyto nástroje detekují škodlivé odpovědi dříve, než se rozšíří, navrhují optimalizace obsahu podle toho, co v AI odpovědích funguje, a umožňují správu více značek pro podniky monitorující desítky značek najednou. ROI je zásadní: včasné odhalení halucinace může zabránit tisícům uživatelů, aby narazili na nepravdivé informace o vaší značce.
Správa toho, které AI systémy mohou přistupovat k vašemu obsahu a trénovat na něm, představuje další úroveň kontroly bezpečnosti značky. OpenAI GPTBot respektuje pravidla robots.txt, což vám umožňuje blokovat přístup k citlivému obsahu a zároveň zachovat přítomnost ve trénovacích datech ChatGPT. PerplexityBot též respektuje robots.txt, přesto přetrvávají obavy z nedeclarovaných robotů, kteří se řádně neidentifikují. Google a Google-Extended se řídí standardními pravidly robots.txt, takže máte podrobnou kontrolu nad tím, co vstupuje do AI systémů Googlu. Je zde však skutečný kompromis: blokování robotů snižuje vaši přítomnost v AI generovaných odpovědích, což může znamenat ztrátu viditelnosti, ale chrání citlivý obsah před zneužitím nebo halucinováním. Cloudflare AI Crawl Control nabízí ještě podrobnější správu, kdy můžete povolit přístup jen k hodnotným sekcím webu a chránit často zneužívaný obsah. Vyvážená strategie obvykle znamená povolit přístup robotům na hlavní produktové stránky a autoritativní obsah a blokovat přístup k interní dokumentaci, zákaznickým datům či obsahu náchylnému k dezinterpretaci. Tím si zachováte viditelnost ve výsledcích AI a zároveň snížíte riziko, že halucinace poškodí vaši značku.
Stanovení jasných KPI pro váš program bezpečnosti značky proměňuje tuto agendu z nákladového střediska na měřitelnou obchodní funkci. MTTD/MTTR metriky (průměrný čas detekce a vyřešení škodlivých odpovědí) podle úrovně závažnosti ukazují, zda se vaše procesy monitoringu a reakce zlepšují. Přesnost a rozložení sentimentu v AI odpovědích odhaluje, zda je vaše značka prezentována pozitivně, neutrálně nebo negativně napříč platformami. Podíl autoritativních citací ukazuje, jaké procento AI odpovědí odkazuje na váš oficiální obsah oproti konkurenci či nespolehlivým zdrojům – vyšší procenta znamenají úspěšné zpevnění obsahu. Podíl viditelnosti v AI Overviews a výsledcích Perplexity sleduje, zda si vaše značka udržuje přítomnost v těchto vysoce navštěvovaných AI rozhraních. Efektivita eskalace měří procento kritických problémů vyřešených v rámci vašeho cílového SLA a dokládá operační vyspělost. Výzkum ukazuje, že programy bezpečnosti značky se silnou prevencí a proaktivním monitoringem snižují porušení na jednotky procent, zatímco reaktivní přístup znamená 20–30% porušení. Prevalence AI Overviews se výrazně zvýšila v průběhu roku 2025, což dělá proaktivní strategie nezbytnými – značky optimalizující pro AI odpovědi nyní získávají konkurenční výhodu oproti těm, které čekají na dozrání technologie. Základní princip je jasný: prevence je lepší než reakce a návratnost investic do proaktivního monitoringu bezpečnosti značky se v čase násobí, jak budujete autoritu, snižujete halucinace a udržujete důvěru zákazníků.
Halucinace AI nastává, když velký jazykový model generuje na první pohled důvěryhodné, ale zcela smyšlené informace s naprostou jistotou. Tyto nepravdivé výstupy vznikají proto, že LLM předpovídají statisticky pravděpodobné sekvence slov na základě vzorů v trénovacích datech, aniž by skutečně rozuměly faktům. Halucinace jsou důsledkem overfittingu, zaujatosti trénovacích dat a inherentní složitosti neuronových sítí, která činí jejich rozhodování neprůhledným.
Halucinace AI mohou vaši značku vážně poškodit několika způsoby: způsobují ztrátu návštěvnosti (60 % vyhledávání nevede ke kliknutí, když se objeví AI shrnutí), oslabují důvěru zákazníků přiřazením nepravdivých tvrzení k vaší značce, vytvářejí PR krize, když konkurence zneužije halucinace, a snižují vaši viditelnost v AI generovaných odpovědích. Firmy hlásí až 10% ztráty návštěvnosti, když AI systémy nesprávně prezentují jejich produkty nebo služby.
Google AI Overviews, ChatGPT, Perplexity a Gemini jsou hlavní platformy, kde se vyskytují rizika pro bezpečnost značky. Google AI Overviews se objevují na vrcholu výsledků vyhledávání bez ověřitelných citací. ChatGPT a Perplexity mohou halucinovat fakta a nesprávně přiřazovat informace. Každá platforma má odlišné praktiky citací a časové rámce oprav, což vyžaduje strategie monitorování napříč více platformami.
Zásadní je monitorování v reálném čase napříč AI platformami. Sledujte prioritní dotazy (název značky, názvy produktů, jména vedení, bezpečnostní témata), nastavte základní úroveň sentimentu a spouštěcí prahy, a korelujte změny s aktualizacemi vašeho obsahu. Specializované nástroje jako AmICited.com poskytují automatizovanou detekci napříč všemi hlavními AI platformami s historickým sledováním a analýzou sentimentu.
Postupujte podle 90minutového postupu reakce na incident: 1) Potvrďte a zmapujte problém (10 min), 2) Publikujte autoritativní upřesnění na svůj web (20 min), 3) Podejte zpětnou vazbu platformě s důkazy (20 min), 4) V případě potřeby eskalujte externě (15 min), 5) Sledujte vyřešení (25 min). Rychlost je klíčová – včasná reakce může snížit poškození reputace o 70–80 % oproti zpožděné reakci.
Implementujte signály E-E-A-T (Odbornost, Zkušenost, Autorství, Důvěryhodnost) s odbornými akreditacemi, transparentními zdroji, aktualizovanými časovými razítky a redakčními standardy. Používejte strukturovaná data JSON-LD s typy schémat Organization, Product, FAQPage, HowTo, Review a Article. Přidejte bloky otázek a odpovědí pro rizikové záměry, vytvářejte kanonické stránky s konsolidovanými informacemi a tvořte obsah, který je hodný citace a AI jej přirozeně odkazuje.
Blokování robotů snižuje vaši přítomnost v AI generovaných odpovědích, ale chrání citlivý obsah. Vyvážená strategie umožňuje robotům přístup na hlavní produktové stránky a autoritativní obsah, zatímco blokuje interní dokumentaci a často zneužívaný obsah. OpenAI GPTBot a PerplexityBot respektují pravidla robots.txt, což vám dává podrobnou kontrolu nad tím, jaký obsah se dostává do AI systémů.
Sledujte MTTD/MTTR (průměrný čas detekce/řešení) škodlivých odpovědí podle závažnosti, přesnost sentimentu v AI odpovědích, podíl autoritativních citací oproti konkurenci, podíl viditelnosti v AI Overviews a výsledcích Perplexity a efektivitu eskalace (procento vyřešených případů v rámci SLA). Tyto metriky ukazují, zda se vaše procesy monitorování a reakce zlepšují, a poskytují odůvodnění ROI pro investice do bezpečnosti značky.
Chraňte reputaci své značky pomocí monitorování v reálném čase napříč Google AI Overviews, ChatGPT a Perplexity. Odhalte halucinace dříve, než poškodí vaši reputaci.
Zjistěte, co je monitorování halucinací AI, proč je klíčové pro bezpečnost značky a jak metody detekce jako RAG, SelfCheckGPT a LLM-as-Judge pomáhají zabránit t...

Zjistěte, co je AI halucinace, proč k ní dochází v ChatGPT, Claude a Perplexity a jak rozpoznat falešné AI-generované informace ve výsledcích vyhledávání....
AI halucinace nastává, když LLM generují nepravdivé nebo zavádějící informace s jistotou. Zjistěte, co způsobuje halucinace, jejich dopad na monitorování značky...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.