Identifikationsstrengen, som AI-crawlere sender til webservere i HTTP-headere, brugt til adgangskontrol, analysetracking og til at skelne legitime AI-bots fra ondsindede scrapers. Den identificerer crawlerens formål, version og oprindelse.
AI Crawler User-Agent
Identifikationsstrengen, som AI-crawlere sender til webservere i HTTP-headere, brugt til adgangskontrol, analysetracking og til at skelne legitime AI-bots fra ondsindede scrapers. Den identificerer crawlerens formål, version og oprindelse.
Definition af AI Crawler User-Agent
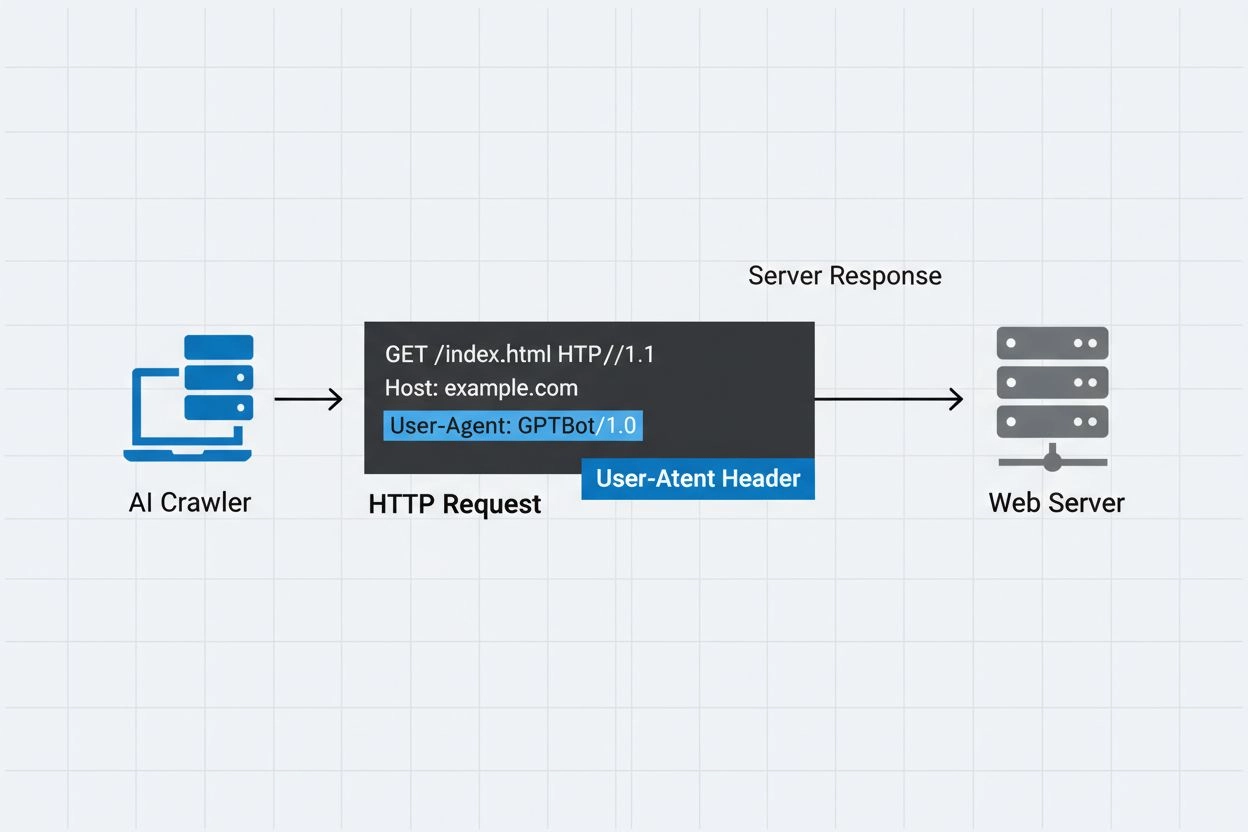
En AI crawler user-agent er en HTTP-headerstreng, der identificerer automatiserede bots, som tilgår webindhold med henblik på træning, indeksering eller forskning inden for kunstig intelligens. Denne streng fungerer som crawlerens digitale identitet og kommunikerer til webservere, hvem der fremsætter anmodningen, og hvad formålet er. User-agenten er afgørende for AI-crawlere, fordi den gør det muligt for websiteejere at genkende, spore og kontrollere, hvordan deres indhold tilgås af forskellige AI-systemer. Uden korrekt user-agent identifikation bliver det betydeligt sværere at skelne mellem legitime AI-crawlere og ondsindede bots, hvilket gør den til en essentiel del af ansvarlig web scraping og dataindsamling.
HTTP-kommunikation og User-Agent Headere
User-agent headeren er en kritisk del af HTTP-anmodninger og optræder i de anmodningsheadere, som enhver browser og bot sender, når de tilgår en webressource. Når en crawler sender en anmodning til en webserver, inkluderer den metadata om sig selv i HTTP-headerne, hvor user-agent strengen er en af de vigtigste identifikatorer. Denne streng indeholder typisk information om crawlerens navn, version, den organisation der driver den, og ofte en kontakt-URL eller e-mail til verifikation. User-agenten gør det muligt for servere at identificere den anmodende klient og træffe beslutninger om, hvorvidt de vil levere indhold, begrænse forespørgsler eller helt blokere adgang. Herunder ses eksempler på user-agent strenge fra større AI-crawlere:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36; compatible; OAI-SearchBot/1.3; +https://openai.com/searchbot
Flere fremtrædende AI-virksomheder driver deres egne crawlere med unikke user-agent identifikatorer og formål. Disse crawlere repræsenterer forskellige anvendelsestilfælde i AI-økosystemet:
GPTBot (OpenAI): Indsamler træningsdata til ChatGPT og andre OpenAI-modeller, respekterer robots.txt direktiver
ClaudeBot (Anthropic): Indsamler indhold til træning af Claude-modeller, kan blokeres via robots.txt
OAI-SearchBot (OpenAI): Indekserer webindhold specifikt til søgefunktionalitet og AI-drevne søgefunktioner
PerplexityBot (Perplexity AI): Crawler nettet for at levere søgeresultater og forskningsmuligheder i deres platform
Gemini-Deep-Research (Google): Udfører dybdegående forskning til Googles Gemini AI-model
Meta-ExternalAgent (Meta): Indsamler data til Metas AI-træning og forskningsinitiativer
Bingbot (Microsoft): Tjener både traditionelle søgeindekseringsformål og AI-drevet svarproduktion
Hver crawler har specifikke IP-ranges og officiel dokumentation, som websiteejere kan referere til for at verificere legitimitet og implementere passende adgangskontrol.
User-Agent spoofing og verifikationsudfordringer
User-agent strenge kan nemt forfalskes af enhver klient, der laver en HTTP-anmodning, hvilket gør dem utilstrækkelige som eneste autentifikationsmekanisme til at identificere legitime AI-crawlere. Ondsindede bots forfalsker ofte populære user-agent strenge for at skjule deres reelle identitet og omgå websidens sikkerhedsforanstaltninger eller robots.txt restriktioner. For at imødegå denne sårbarhed anbefaler sikkerhedseksperter at bruge IP-verifikation som et ekstra lag af autentifikation, hvor man tjekker, at anmodninger stammer fra de officielle IP-ranges offentliggjort af AI-virksomheder. Den nye RFC 9421 HTTP Message Signatures-standard giver kryptografiske verifikationsmuligheder, hvor crawlere digitalt kan underskrive deres anmodninger, så servere kryptografisk kan verificere ægtheden. Det er dog stadig udfordrende at skelne mellem ægte og falske crawlere, fordi målrettede angribere både kan forfalske user-agent strenge og IP-adresser via proxies eller kompromitteret infrastruktur. Dette er et evigt spil mellem crawler-operatører og sikkerhedsbevidste websiteejere, som udvikler sig, efterhånden som nye verifikationsteknikker bliver udviklet.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Brug af robots.txt med User-Agent direktiver
Websiteejere kan kontrollere crawleradgang ved at specificere user-agent direktiver i deres robots.txt-fil, hvilket muliggør detaljeret kontrol over, hvilke crawlere der kan tilgå hvilke dele af deres site. Robots.txt-filen bruger user-agent identifikatorer til at målrette specifikke crawlere med tilpassede regler, så siteejere kan tillade nogle crawlere og blokere andre. Her er et eksempel på en robots.txt-konfiguration:
Selvom robots.txt giver en bekvem mekanisme til crawlerkontrol, har den vigtige begrænsninger:
Robots.txt er udelukkende vejledende og ikke håndhævelig; crawlere kan ignorere den
Forfalskede user-agents kan fuldstændigt omgå robots.txt restriktioner
Server-side verifikation med IP-tilladelister giver stærkere beskyttelse
Web Application Firewall (WAF) regler kan blokere anmodninger fra uautoriserede IP-ranges
Kombination af robots.txt med IP-verifikation skaber en mere robust adgangskontrolstrategi
Analyse af crawleraktivitet via serverlogs
Websiteejere kan udnytte serverlogs til at spore og analysere AI-crawleraktivitet og få indsigt i, hvilke AI-systemer der tilgår deres indhold og hvor ofte. Ved at undersøge HTTP-anmodningslogs og filtrere efter kendte AI crawler user-agents kan administratorer forstå båndbreddepåvirkning og dataindsamlingsmønstre for forskellige AI-virksomheder. Værktøjer som loganalyseplatforme, webanalysetjenester og egne scripts kan parse serverlogs for at identificere crawlertrafik, måle forespørgselsfrekvens og beregne datatransfervolumener. Denne synlighed er særligt vigtig for indholdsskabere og udgivere, der ønsker at forstå, hvordan deres arbejde bruges til AI-træning, og om de bør implementere adgangsbegrænsninger. Tjenester som AmICited.com spiller en afgørende rolle i dette økosystem ved at overvåge og spore, hvordan AI-systemer citerer og refererer indhold fra hele internettet, og giver skabere transparens om deres indholds brug i AI-træning. Forståelse af crawleraktivitet hjælper websiteejere med at træffe informerede beslutninger om deres indholdspolitikker og forhandle med AI-virksomheder om databrugsrettigheder.
Bedste praksis for håndtering af AI-crawleradgang
Effektiv håndtering af AI-crawleradgang kræver en lagdelt tilgang, der kombinerer flere verifikations- og overvågningsteknikker:
Kombiner user-agent tjek med IP-verifikation – Stol aldrig kun på user-agent strenge; krydstjek altid med officielle IP-ranges offentliggjort af AI-virksomheder
Vedligehold opdaterede IP-tilladelister – Gennemgå og opdater regelmæssigt dine firewall-regler med de nyeste IP-ranges fra OpenAI, Anthropic, Google og andre AI-udbydere
Implementer regelmæssig loganalyse – Planlæg periodiske gennemgange af serverlogs for at identificere mistænkelig crawleraktivitet og uautoriserede adgangsforsøg
Skeln mellem crawler-typer – Differentier mellem træningscrawlere (GPTBot, ClaudeBot) og søgecrawlere (OAI-SearchBot, PerplexityBot) for at anvende passende politikker
Overvej etiske implikationer – Afvej adgangsbegrænsninger mod det faktum, at AI-træning har gavn af mangfoldige, høj-kvalitets indholdskilder
Brug overvågningstjenester – Udnyt platforme som AmICited.com til at spore, hvordan dit indhold bruges og citeres af AI-systemer, så du sikrer korrekt attribuering og forstår dit indholds indflydelse
Ved at følge disse praksisser kan websiteejere bevare kontrollen over deres indhold og samtidig understøtte ansvarlig udvikling af AI-systemer.
Ofte stillede spørgsmål
Hvad er en user-agent streng?
En user-agent er en HTTP-headerstreng, der identificerer klienten, som laver en webanmodning. Den indeholder information om softwaren, operativsystemet og versionen af den anmodende applikation, uanset om det er en browser, crawler eller bot. Denne streng gør det muligt for webservere at identificere og spore forskellige typer af klienter, der tilgår deres indhold.
Hvorfor har AI-crawlere brug for user-agent strenge?
User-agent strenge giver webservere mulighed for at identificere, hvilken crawler der tilgår deres indhold, hvilket gør det muligt for websiteejere at kontrollere adgang, spore crawleraktivitet og skelne mellem forskellige typer bots. Dette er essentielt for at håndtere båndbredde, beskytte indhold og forstå, hvordan AI-systemer bruger dine data.
Kan user-agent strenge forfalskes?
Ja, user-agent strenge kan let forfalskes, da de blot er tekstværdier i HTTP-headere. Derfor er IP-verifikation og HTTP Message Signatures vigtige supplerende verifikationsmetoder for at bekræfte en crawlers sande identitet og forhindre ondsindede bots i at udgive sig for legitime crawlere.
Hvordan blokerer jeg specifikke AI-crawlere?
Du kan bruge robots.txt med user-agent direktiver for at anmode crawlere om ikke at tilgå dit site, men dette kan ikke håndhæves. For stærkere kontrol skal du bruge server-side verifikation, IP tillade-/bloklister eller WAF-regler, der tjekker både user-agent og IP-adresse samtidigt.
Hvad er forskellen på GPTBot og OAI-SearchBot?
GPTBot er OpenAI's crawler til indsamling af træningsdata til AI-modeller som ChatGPT, mens OAI-SearchBot er designet til søgeindeksering og driver søgefunktioner i ChatGPT. De har forskellige formål, crawl-hastigheder og IP-ranges, hvilket kræver forskellige adgangskontrolstrategier.
Hvordan kan jeg verificere, om en crawler er legitim?
Tjek crawlerens IP-adresse mod den officielle IP-liste, som crawleroperatøren har offentliggjort (fx openai.com/gptbot.json for GPTBot). Legitime crawlere offentliggør deres IP-ranges, og du kan verificere, at anmodninger kommer fra disse ranges ved hjælp af firewall-regler eller WAF-konfigurationer.
Hvad er HTTP Message Signature-verifikation?
HTTP Message Signatures (RFC 9421) er en kryptografisk metode, hvor crawlere underskriver deres anmodninger med en privat nøgle. Servere kan verificere signaturen ved at bruge crawlerens offentlige nøgle fra deres .well-known mappe, hvilket beviser, at anmodningen er autentisk og ikke er blevet manipuleret.
Hvordan hjælper AmICited.com med AI-crawlerovervågning?
AmICited.com overvåger, hvordan AI-systemer refererer til og citerer dit brand på tværs af GPTs, Perplexity, Google AI Overviews og andre AI-platforme. Det sporer crawleraktivitet og AI-omtaler, så du kan forstå din synlighed i AI-genererede svar og hvordan dit indhold bliver brugt.
Overvåg Dit Brand i AI-systemer
Følg, hvordan AI-crawlere refererer til og citerer dit indhold på tværs af ChatGPT, Perplexity, Google AI Overviews og andre AI-platforme med AmICited.
Sådan identificerer du AI-crawlere i serverlogs: Komplet detektionsguide
Lær hvordan du identificerer og overvåger AI-crawlere som GPTBot, PerplexityBot og ClaudeBot i dine serverlogs. Opdag user-agent-strenge, IP-verificeringsmetode...
Hvilke AI-crawlere bør jeg give adgang? Komplet guide til 2025
Lær hvilke AI-crawlere du skal tillade eller blokere i din robots.txt. Omfattende guide, der dækker GPTBot, ClaudeBot, PerplexityBot og 25+ AI-crawlere med konf...
Sådan Tillader du AI-bots at Crawle Dit Website: Komplet robots.txt & llms.txt Guide
Lær hvordan du tillader AI-bots som GPTBot, PerplexityBot og ClaudeBot at crawle dit website. Konfigurer robots.txt, opsæt llms.txt og optimer for AI-synlighed....
14 min læsning
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.