
Hoe AI-crawlers identificeren in serverlogs: Complete detectiegids
Leer hoe je AI-crawlers zoals GPTBot, PerplexityBot en ClaudeBot kunt identificeren en monitoren in je serverlogs. Ontdek user-agent strings, IP-verificatiemeth...
8 min lezen

De identificatiestring die AI-crawlers naar webservers sturen in HTTP-headers, gebruikt voor toegangscontrole, analytische tracking en het onderscheiden van legitieme AI-bots van kwaadaardige scrapers. Het identificeert het doel, de versie en de herkomst van de crawler.
De identificatiestring die AI-crawlers naar webservers sturen in HTTP-headers, gebruikt voor toegangscontrole, analytische tracking en het onderscheiden van legitieme AI-bots van kwaadaardige scrapers. Het identificeert het doel, de versie en de herkomst van de crawler.
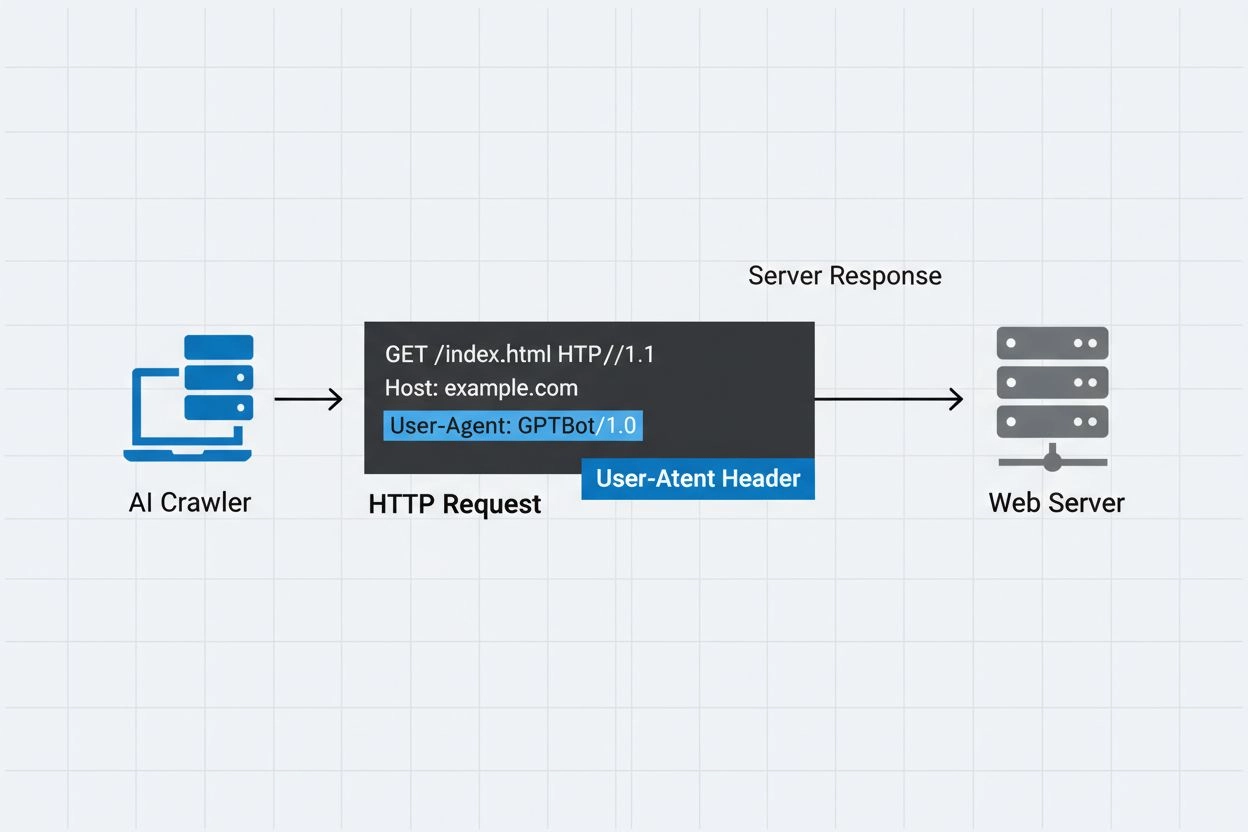
Een AI crawler user-agent is een HTTP-headerstring die geautomatiseerde bots identificeert die webcontent benaderen voor doeleinden als kunstmatige intelligentie training, indexering of onderzoek. Deze string dient als de digitale identiteit van de crawler en geeft aan webservers door wie het verzoek doet en met welk doel. De user-agent is cruciaal voor AI-crawlers omdat hiermee website-eigenaren kunnen herkennen, volgen en controleren hoe hun content door verschillende AI-systemen wordt benaderd. Zonder goede user-agent-identificatie wordt het aanzienlijk moeilijker om legitieme AI-crawlers van kwaadaardige bots te onderscheiden, waardoor het een essentieel onderdeel is van verantwoord webscrapen en dataverzamelingspraktijken.
De user-agent header is een cruciaal onderdeel van HTTP-verzoeken en verschijnt in de request headers die elke browser en bot meestuurt bij het benaderen van een webbron. Wanneer een crawler een verzoek doet aan een webserver, wordt metadata over zichzelf meegestuurd in de HTTP-headers, waarbij de user-agent string een van de belangrijkste identificatoren is. Deze string bevat doorgaans informatie over de naam van de crawler, de versie, de organisatie die hem exploiteert, en vaak een contact-URL of e-mailadres voor verificatie. De user-agent stelt servers in staat om de verzoekende client te identificeren en beslissingen te nemen over het al dan niet leveren van content, het beperken van verzoeken of het volledig blokkeren van toegang. Hier zijn voorbeelden van user-agent strings van grote AI-crawlers:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36; compatible; OAI-SearchBot/1.3; +https://openai.com/searchbot
| Crawlernaam | Doel | Voorbeeld User-Agent | IP-verificatie |
|---|---|---|---|
| GPTBot | Trainingsdataverzameling | Mozilla/5.0…compatible; GPTBot/1.3 | OpenAI IP-ranges |
| ClaudeBot | Modeltraining | Mozilla/5.0…compatible; ClaudeBot/1.0 | Anthropic IP-ranges |
| OAI-SearchBot | Zoekindexering | Mozilla/5.0…compatible; OAI-SearchBot/1.3 | OpenAI IP-ranges |
| PerplexityBot | Zoekindexering | Mozilla/5.0…compatible; PerplexityBot/1.0 | Perplexity IP-ranges |
Verschillende prominente AI-bedrijven exploiteren hun eigen crawlers met verschillende user-agent-identificaties en doelen. Deze crawlers vertegenwoordigen uiteenlopende toepassingen binnen het AI-ecosysteem:
Elke crawler heeft specifieke IP-ranges en officiële documentatie die website-eigenaren kunnen raadplegen om de legitimiteit te verifiëren en passende toegangscontroles te implementeren.
User-agent strings kunnen eenvoudig worden gespoofd door elke client die een HTTP-verzoek doet, waardoor ze onvoldoende zijn als enige authenticatiemechanisme om legitieme AI-crawlers te identificeren. Kwaadaardige bots spoofen vaak populaire user-agent strings om hun ware identiteit te verhullen en beveiligingsmaatregelen of robots.txt-beperkingen te omzeilen. Om dit probleem aan te pakken, adviseren beveiligingsexperts om IP-verificatie als extra authenticatielaag te gebruiken en te controleren of verzoeken afkomstig zijn uit de officiële IP-ranges die door AI-bedrijven worden gepubliceerd. De opkomende RFC 9421 HTTP Message Signatures-standaard biedt cryptografische verificatiemogelijkheden, waarmee crawlers hun verzoeken digitaal kunnen ondertekenen zodat servers de authenticiteit cryptografisch kunnen verifiëren. Toch blijft het onderscheiden van echte en valse crawlers uitdagend, omdat vastberaden aanvallers zowel user-agent strings als IP-adressen kunnen spoofen via proxies of gecompromitteerde infrastructuur. Dit kat-en-muisspel tussen crawler-operators en beveiligingsbewuste website-eigenaren blijft zich ontwikkelen naarmate er nieuwe verificatietechnieken ontstaan.
Website-eigenaren kunnen crawler-toegang beheren door user-agent directieven in hun robots.txt-bestand te specificeren, wat gedetailleerde controle mogelijk maakt over welke crawlers toegang hebben tot welke delen van hun site. Het robots.txt-bestand gebruikt user-agent identifiers om specifieke crawlers te targeten met aangepaste regels, waardoor site-eigenaren sommige crawlers kunnen toestaan en andere kunnen blokkeren. Hier is een voorbeeld van een robots.txt-configuratie:
User-agent: GPTBot
Disallow: /private
Allow: /
User-agent: ClaudeBot
Disallow: /
Hoewel robots.txt een handig mechanisme biedt voor crawlercontrole, zijn er belangrijke beperkingen:
Website-eigenaren kunnen serverlogs gebruiken om AI-crawleractiviteit te volgen en te analyseren, zodat ze inzicht krijgen in welke AI-systemen hun content benaderen en hoe vaak. Door HTTP-verzoeklogs te onderzoeken en te filteren op bekende AI crawler user-agents, kunnen beheerders het bandbreedtegebruik en de dataverzamelingspatronen van verschillende AI-bedrijven begrijpen. Tools zoals loganalyseplatforms, webanalysediensten en eigen scripts kunnen serverlogs uitlezen om crawlerverkeer te identificeren, verzoekfrequentie te meten en datavolumes te berekenen. Deze zichtbaarheid is met name belangrijk voor contentmakers en uitgevers die willen weten hoe hun werk wordt gebruikt voor AI-training en of ze toegangsbeperkingen moeten toepassen. Diensten zoals AmICited.com spelen een cruciale rol in dit ecosysteem door te monitoren hoe AI-systemen content van het web citeren en vermelden, zodat makers transparantie krijgen over het gebruik van hun content bij AI-training. Inzicht in crawleractiviteit helpt website-eigenaren om weloverwogen beslissingen te nemen over hun contentbeleid en te onderhandelen met AI-bedrijven over datagebruiksrechten.
Het effectief beheren van toegang door AI-crawlers vereist een gelaagde aanpak waarbij verschillende verificatie- en monitoringtechnieken worden gecombineerd:
Door deze best practices te volgen, behouden website-eigenaren controle over hun content en ondersteunen ze tegelijkertijd de verantwoorde ontwikkeling van AI-systemen.
Een user-agent is een HTTP-headerstring die de client identificeert die een webverzoek doet. Het bevat informatie over de software, het besturingssysteem en de versie van de verzoekende applicatie, of dat nu een browser, crawler of bot is. Dankzij deze string kunnen webservers verschillende soorten clients identificeren en volgen die toegang krijgen tot hun content.
User-agent strings stellen webservers in staat om te identificeren welke crawler hun content benadert, zodat website-eigenaren toegang kunnen controleren, crawleractiviteit kunnen volgen en verschillende soorten bots van elkaar kunnen onderscheiden. Dit is essentieel voor bandbreedtebeheer, contentbescherming en inzicht in hoe AI-systemen je data gebruiken.
Ja, user-agent strings kunnen gemakkelijk worden gespoofd omdat het slechts tekstwaarden zijn in HTTP-headers. Daarom zijn IP-verificatie en HTTP Message Signatures belangrijke aanvullende verificatiemethoden om de ware identiteit van een crawler te bevestigen en te voorkomen dat kwaadaardige bots zich voordoen als legitieme crawlers.
Je kunt robots.txt gebruiken met user-agent directieven om crawlers te verzoeken je site niet te benaderen, maar dit is niet afdwingbaar. Voor sterkere controle kun je server-side verificatie, IP-allowlisting/blocklisting of WAF-regels gebruiken die zowel de user-agent als het IP-adres tegelijkertijd controleren.
GPTBot is de crawler van OpenAI voor het verzamelen van trainingsdata voor AI-modellen zoals ChatGPT, terwijl OAI-SearchBot is ontworpen voor zoekindexering en het aandrijven van zoekfuncties in ChatGPT. Ze hebben verschillende doelen, crawl-snelheden en IP-ranges, wat verschillende strategieën voor toegangscontrole vereist.
Controleer het IP-adres van de crawler met de officiële IP-lijst die door de crawler-operator wordt gepubliceerd (bijvoorbeeld openai.com/gptbot.json voor GPTBot). Legitieme crawlers publiceren hun IP-ranges en je kunt met firewallregels of WAF-configuraties controleren of verzoeken uit die ranges komen.
HTTP Message Signatures (RFC 9421) is een cryptografische methode waarbij crawlers hun verzoeken ondertekenen met een privésleutel. Servers kunnen de handtekening verifiëren met de publieke sleutel van de crawler uit hun .well-known directory, waarmee wordt bewezen dat het verzoek authentiek is en niet is gemanipuleerd.
AmICited.com monitort hoe AI-systemen je merk vermelden en citeren in GPT's, Perplexity, Google AI Overviews en andere AI-platforms. Het volgt crawleractiviteit en AI-vermeldingen, zodat je inzicht krijgt in je zichtbaarheid in AI-gegenereerde antwoorden en hoe je content wordt gebruikt.
Volg hoe AI-crawlers je content vermelden en citeren in ChatGPT, Perplexity, Google AI Overviews en andere AI-platforms met AmICited.
Leer hoe je AI-crawlers zoals GPTBot, PerplexityBot en ClaudeBot kunt identificeren en monitoren in je serverlogs. Ontdek user-agent strings, IP-verificatiemeth...
Ontdek welke AI-crawlers je moet toestaan of blokkeren in je robots.txt. Uitgebreide gids over GPTBot, ClaudeBot, PerplexityBot en 25+ AI-crawlers met configura...

Begrijp hoe AI-crawlers zoals GPTBot en ClaudeBot werken, hun verschillen met traditionele zoekmachine-crawlers en hoe je je site optimaliseert voor AI-zoekzich...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.