
Canonieke URL's en AI: Voorkomen van problemen met dubbele content
Leer hoe canonieke URL's problemen met dubbele content in AI-zoeksystemen voorkomen. Ontdek best practices voor het implementeren van canonicals om AI-zichtbaar...
6 min lezen
AI-deduplicatielogica verwijst naar de geautomatiseerde processen en algoritmen die AI-systemen gebruiken om redundante of dubbele informatie uit meerdere bronnen te identificeren, analyseren en elimineren. Deze systemen maken gebruik van machine learning, natuurlijke taalverwerking en technieken voor het vergelijken van overeenkomsten om identieke of zeer vergelijkbare inhoud te herkennen in diverse dataopslagplaatsen, waardoor de datakwaliteit wordt gewaarborgd, de opslagkosten worden verlaagd en de nauwkeurigheid van besluitvorming wordt verbeterd.
AI-deduplicatielogica verwijst naar de geautomatiseerde processen en algoritmen die AI-systemen gebruiken om redundante of dubbele informatie uit meerdere bronnen te identificeren, analyseren en elimineren. Deze systemen maken gebruik van machine learning, natuurlijke taalverwerking en technieken voor het vergelijken van overeenkomsten om identieke of zeer vergelijkbare inhoud te herkennen in diverse dataopslagplaatsen, waardoor de datakwaliteit wordt gewaarborgd, de opslagkosten worden verlaagd en de nauwkeurigheid van besluitvorming wordt verbeterd.
AI-deduplicatielogica is een geavanceerd algoritmisch proces dat dubbele of bijna-dubbele records uit grote datasets identificeert en verwijdert met behulp van kunstmatige intelligentie en machine learning-technieken. Deze technologie detecteert automatisch wanneer meerdere vermeldingen dezelfde entiteit vertegenwoordigen—of dat nu een persoon, product, document of stukje informatie is—ondanks variaties in opmaak, spelling of presentatie. Het belangrijkste doel van deduplicatie is het behouden van dataintegriteit en het voorkomen van redundantie die analyses kan verstoren, opslagkosten kan verhogen en de nauwkeurigheid van besluitvorming kan ondermijnen. In de huidige datagedreven wereld, waarin organisaties dagelijks miljoenen records verwerken, is effectieve deduplicatie essentieel geworden voor operationele efficiëntie en betrouwbare inzichten.
AI-deduplicatie maakt gebruik van meerdere complementaire technieken om vergelijkbare records met opmerkelijke precisie te identificeren en te groeperen. Het proces begint met het analyseren van data-attributen—zoals namen, adressen, e-mailadressen en andere identificatoren—en deze te vergelijken met vastgestelde gelijkenisdrempels. Moderne deduplicatiesystemen gebruiken een combinatie van fonetische matching, string similarity-algoritmen en semantische analyse om duplicaten te vinden die traditionele regelgebaseerde systemen zouden missen. Het systeem kent gelijkenisscores toe aan potentiële matches en groepeert records die de ingestelde drempel overschrijden tot groepen die dezelfde entiteit vertegenwoordigen. Gebruikers behouden controle over het inclusiviteitsniveau van deduplicatie, waardoor ze de gevoeligheid kunnen aanpassen op basis van hun specifieke gebruikssituatie en tolerantie voor false positives.
| Methode | Beschrijving | Beste voor |
|---|---|---|
| Fonetische gelijkenis | Groepeert strings die hetzelfde klinken (bijv. “Smith” vs “Smyth”) | Naamvariaties, fonetische verwarring |
| Spellinggelijkenis | Groepeert strings met vergelijkbare spelling | Typfouten, kleine spellingvariaties |
| TFIDF-gelijkenis | Past term frequency-inverse document frequency algoritme toe | Algemene tekstmatching, documentsimilariteit |
De deduplicatiemotor verwerkt records in meerdere rondes, waarbij eerst duidelijke matches worden geïdentificeerd en daarna steeds subtielere variaties worden onderzocht. Deze gelaagde aanpak zorgt voor een uitgebreide dekking met behoud van computationele efficiëntie, zelfs bij het verwerken van datasets met miljoenen records.
Moderne AI-deduplicatie maakt gebruik van vector embeddings en semantische analyse om de betekenis achter data te begrijpen in plaats van alleen oppervlakkige kenmerken te vergelijken. Natuurlijke taalverwerking (NLP) stelt systemen in staat context en intentie te begrijpen, zodat ze herkennen dat “Robert”, “Bob” en “Rob” allemaal naar dezelfde persoon verwijzen ondanks hun verschillende vormen. Fuzzy matching-algoritmen berekenen de bewerkingsafstand tussen strings, waardoor records die slechts enkele tekens verschillen—cruciaal bij typefouten en transcriptiefouten—worden herkend. Het systeem analyseert ook metadata zoals tijdstempels, aanmaakdata en wijzigingsgeschiedenis voor extra zekerheid bij het bepalen of records duplicaten zijn. Geavanceerde implementaties omvatten machine learning-modellen die zijn getraind op gelabelde datasets, waardoor de nauwkeurigheid continu verbetert naarmate ze meer data verwerken en feedback ontvangen over deduplicatiebeslissingen.
AI-deduplicatielogica is onmisbaar geworden in vrijwel elke sector die grootschalige dataverwerking uitvoert. Organisaties gebruiken deze technologie om schone, betrouwbare datasets te waarborgen die de basis vormen voor accurate analyses en onderbouwde besluitvorming. De praktische toepassingen bestrijken verschillende belangrijke bedrijfsfuncties:

Deze toepassingen laten zien hoe deduplicatie direct invloed heeft op compliance, fraudepreventie en operationele integriteit in uiteenlopende branches.
De financiële en operationele voordelen van AI-deduplicatie zijn aanzienlijk en meetbaar. Organisaties kunnen hun opslagkosten aanzienlijk verlagen door redundante data te elimineren; sommige implementaties boeken een reductie van 20-40% in opslagbehoefte. Verbeterde datakwaliteit vertaalt zich direct in betere analyses en besluitvorming, omdat analyses op schone data betrouwbaardere inzichten en voorspellingen opleveren. Onderzoek toont aan dat data scientists ongeveer 80% van hun tijd besteden aan datavoorbereiding, waarbij dubbele records een grote veroorzaker zijn van deze last—automatisering van deduplicatie geeft waardevolle analysetijd terug voor waardevoller werk. Studies tonen aan dat 10-30% van de records in typische databases duplicaten bevat, wat een aanzienlijke bron van inefficiëntie en fouten vertegenwoordigt. Naast kostenreductie versterkt deduplicatie de compliance en naleving van regelgeving door nauwkeurige administratie te garanderen en dubbele inzendingen te voorkomen die tot controles of boetes kunnen leiden. De efficiëntiewinst strekt zich uit tot snellere zoekopdrachten, minder computationele belasting en verbeterde systeembetrouwbaarheid.
Ondanks de geavanceerdheid kent AI-deduplicatie uitdagingen en beperkingen waar organisaties zorgvuldig mee om moeten gaan. False positives—ten onrechte verschillende records als duplicaten markeren—kunnen leiden tot dataverlies of samengevoegde records die gescheiden hadden moeten blijven, terwijl false negatives echte duplicaten ongezien laten. Deduplicatie wordt exponentieel complexer bij multiformaatdata over verschillende systemen, talen en datastructuren met elk hun eigen opmaakregels en codering. Privacy- en beveiligingsvraagstukken ontstaan wanneer deduplicatie vereist dat gevoelige persoonsgegevens worden geanalyseerd, wat sterke encryptie en toegangscontrole noodzakelijk maakt. De nauwkeurigheid van deduplicatiesystemen blijft uiteindelijk afhankelijk van de kwaliteit van de invoerdata; als de input rommelig is, levert het systeem ook rommel op, en onvolledige of corrupte records kunnen zelfs de meest geavanceerde algoritmen in de war brengen.
AI-deduplicatie is een cruciaal onderdeel geworden van moderne AI-antwoordenmonitoringsplatforms en zoeksystemen die informatie uit meerdere bronnen samenvoegen. Wanneer AI-systemen antwoorden samenstellen uit talloze documenten en bronnen, zorgt deduplicatie ervoor dat dezelfde informatie niet meerdere keren meetelt, wat anders vertrouwensscores kunstmatig zou verhogen en relevantierangschikkingen zou vertekenen. Bronvermelding wordt betekenisvoller als deduplicatie dubbele bronnen verwijdert, zodat gebruikers de echte diversiteit van het bewijs achter een antwoord zien. Platforms zoals AmICited.com maken gebruik van deduplicatielogica om transparante, nauwkeurige brontracking te bieden door te herkennen wanneer meerdere bronnen in wezen identieke informatie bevatten en deze gepast te consolideren. Dit voorkomt dat AI-antwoorden breder gedragen lijken dan ze werkelijk zijn, en bewaakt zo de integriteit van bronvermelding en geloofwaardigheid van antwoorden. Door dubbele bronnen te filteren, verbetert deduplicatie de kwaliteit van AI-zoekresultaten en zorgt het ervoor dat gebruikers echt diverse perspectieven ontvangen in plaats van variaties van dezelfde informatie uit meerdere bronnen. De technologie versterkt uiteindelijk het vertrouwen in AI-systemen door een schoner, eerlijker beeld te geven van het bewijs onder AI-gegenereerde antwoorden.
AI-deduplicatie en datacompressie verlagen beide het datavolume, maar werken verschillend. Deduplicatie identificeert en verwijdert exacte of bijna-identieke records, waarbij slechts één exemplaar behouden blijft en de rest wordt vervangen door verwijzingen. Datacompressie daarentegen codeert data efficiënter zonder duplicaten te verwijderen. Deduplicatie werkt op macroniveau (volledige bestanden of records), terwijl compressie op microniveau werkt (individuele bits en bytes). Voor organisaties met veel dubbele data levert deduplicatie doorgaans grotere besparingen op opslagruimte op.
AI gebruikt meerdere geavanceerde technieken om niet-exacte duplicaten te herkennen. Fonetische algoritmen herkennen namen die hetzelfde klinken (bijv. 'Smith' vs 'Smyth'). Fuzzy matching berekent de bewerkingsafstand om records te vinden die slechts enkele tekens verschillen. Vector embeddings zetten tekst om in wiskundige representaties die semantische betekenis vastleggen, waardoor het systeem geparafraseerde inhoud kan herkennen. Machine learning-modellen die zijn getraind op gelabelde datasets leren patronen van wat in specifieke contexten een duplicaat is. Deze technieken werken samen om duplicaten te vinden ondanks variaties in spelling, opmaak of presentatie.
Deduplicatie kan opslagkosten aanzienlijk verlagen door redundante data te elimineren. Organisaties realiseren doorgaans een reductie van 20-40% in opslagbehoefte na effectieve deduplicatie. Deze besparingen nemen toe naarmate nieuwe data continu wordt gededupliceerd. Naast directe besparing op opslagkosten verlaagt deduplicatie ook kosten voor databeheer, back-upoperaties en systeemonderhoud. Voor grote ondernemingen die miljoenen records verwerken, kunnen deze besparingen jaarlijks oplopen tot honderdduizenden euro's, waardoor deduplicatie een investering met een hoog rendement is.
Ja, moderne AI-deduplicatiesystemen kunnen met verschillende bestandsformaten werken, al vereist dit geavanceerdere verwerking. Het systeem moet eerst data uit diverse formaten (PDF's, Word-documenten, spreadsheets, databases, enz.) normaliseren tot een vergelijkbare structuur. Geavanceerde implementaties gebruiken optische tekenherkenning (OCR) voor gescande documenten en formatspecifieke parsers om relevante inhoud te extraheren. De nauwkeurigheid van deduplicatie kan echter variëren afhankelijk van de complexiteit van het formaat en de datakwaliteit. Organisaties behalen doorgaans de beste resultaten als deduplicatie wordt toegepast op gestructureerde data in consistente formaten, al wordt cross-formaat deduplicatie steeds beter mogelijk met moderne AI-technieken.
Deduplicatie verbetert AI-zoekresultaten door ervoor te zorgen dat relevantierangschikkingen echte diversiteit van bronnen weerspiegelen in plaats van variaties van dezelfde informatie. Wanneer meerdere bronnen identieke of bijna-identieke inhoud bevatten, consolideert deduplicatie deze, waardoor kunstmatige verhoging van vertrouwensscores wordt voorkomen. Dit biedt gebruikers schonere, eerlijkere representaties van bewijs ter ondersteuning van AI-gegenereerde antwoorden. Deduplicatie verbetert ook de zoekprestaties door het datavolume dat het systeem moet verwerken te verminderen, wat snellere zoekopdrachten mogelijk maakt. Door dubbele bronnen te filteren, kunnen AI-systemen zich richten op echt diverse perspectieven en informatie, wat uiteindelijk resulteert in hogere kwaliteit en betrouwbaarheid van de resultaten.
False positives ontstaan wanneer deduplicatie ten onrechte verschillende records als duplicaten aanmerkt en samenvoegt. Bijvoorbeeld het samenvoegen van records van 'John Smith' en 'Jane Smith' die verschillende personen zijn maar dezelfde achternaam delen. False positives zijn problematisch omdat ze leiden tot permanent dataverlies—als records eenmaal zijn samengevoegd, is het moeilijk of onmogelijk om de oorspronkelijke informatie terug te krijgen. In kritieke toepassingen zoals gezondheidszorg of financiële diensten kunnen false positives ernstige gevolgen hebben, waaronder onjuiste medische dossiers of frauduleuze transacties. Organisaties moeten de gevoeligheid van deduplicatie zorgvuldig afstemmen om false positives te minimaliseren, waarbij soms enkele false negatives (gemiste duplicaten) worden geaccepteerd als een veiligere keuze.
Deduplicatie is essentieel voor AI-contentmonitoringsplatforms zoals AmICited die bijhouden hoe AI-systemen merken en bronnen noemen. Wanneer AI-antwoorden op meerdere platforms (GPT's, Perplexity, Google AI) worden gemonitord, voorkomt deduplicatie dat dezelfde bron meerdere keren wordt geteld als deze in verschillende AI-systemen of formaten verschijnt. Dit zorgt voor correcte bronvermelding en voorkomt opgeblazen zichtbaarheidscijfers. Deduplicatie helpt ook te herkennen wanneer AI-systemen putten uit een beperkt aantal bronnen, ondanks schijnbare diversiteit. Door dubbele bronnen te consolideren bieden contentmonitoringsplatforms helderder inzicht in welke unieke bronnen daadwerkelijk AI-antwoorden beïnvloeden.
Metadata—informatie over data zoals aanmaakdatum, wijzigingstijdstempels, auteursinformatie en bestandskenmerken—speelt een cruciale rol bij duplicaatherkenning. Metadata helpt de levenscyclus van records vast te stellen en toont wanneer documenten zijn aangemaakt, bijgewerkt of geraadpleegd. Deze tijdsinformatie helpt onderscheid te maken tussen legitieme versies van documenten in ontwikkeling en echte duplicaten. Auteursinformatie en afdelingskoppelingen geven context over de oorsprong en het doel van een record. Toegangspatronen geven aan of documenten actief worden gebruikt of verouderd zijn. Geavanceerde deduplicatiesystemen combineren metadata-analyse met inhoudsanalyse en gebruiken beide signalen om nauwkeuriger duplicaten vast te stellen en te bepalen welke versie als gezaghebbende bron moet worden behouden.
AmICited volgt hoe AI-systemen zoals GPT's, Perplexity en Google AI jouw merk noemen in meerdere bronnen. Zorg voor correcte bronvermelding en voorkom dat dubbele inhoud jouw AI-zichtbaarheid vertekent.
Leer hoe canonieke URL's problemen met dubbele content in AI-zoeksystemen voorkomen. Ontdek best practices voor het implementeren van canonicals om AI-zichtbaar...

Discussie binnen de community over hoe AI-systemen anders omgaan met dubbele content dan traditionele zoekmachines. SEO-professionals delen inzichten over conte...
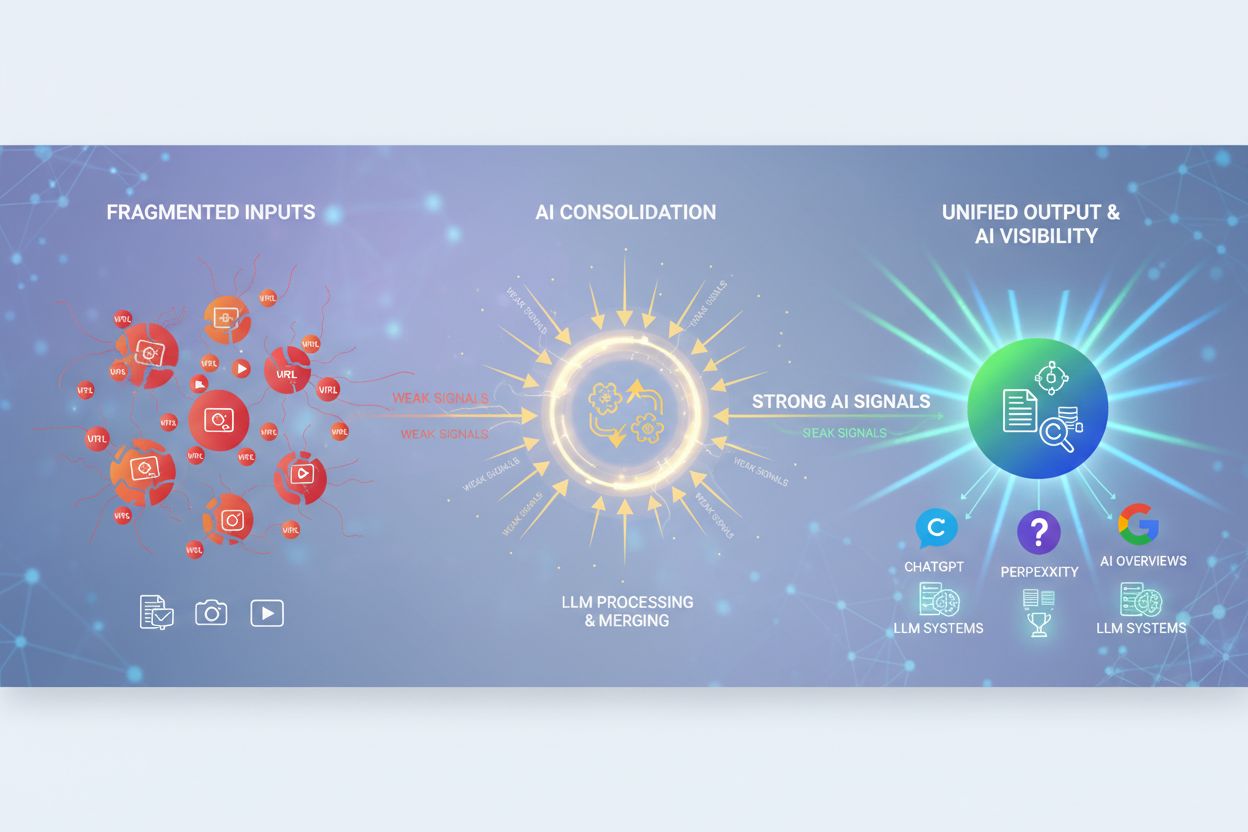
Ontdek wat AI-inhoudsconsolidatie is en hoe het samenvoegen van vergelijkbare content zichtbaarheidssignalen voor ChatGPT, Perplexity en Google AI Overviews ver...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.