
Trainingsgegevens
Trainingsgegevens zijn de dataset die gebruikt worden om ML-modellen patronen en relaties te laten leren. Ontdek hoe de kwaliteit van trainingsgegevens de prest...
11 min lezen

Training met synthetische data is het proces waarbij AI-modellen worden getraind met kunstmatig gegenereerde data in plaats van echte, door mensen gecreëerde informatie. Deze aanpak pakt dataschaarste aan, versnelt de ontwikkeling van modellen en waarborgt privacy, maar introduceert ook uitdagingen zoals modelcollaps en hallucinaties die zorgvuldig beheer en validatie vereisen.
Training met synthetische data is het proces waarbij AI-modellen worden getraind met kunstmatig gegenereerde data in plaats van echte, door mensen gecreëerde informatie. Deze aanpak pakt dataschaarste aan, versnelt de ontwikkeling van modellen en waarborgt privacy, maar introduceert ook uitdagingen zoals modelcollaps en hallucinaties die zorgvuldig beheer en validatie vereisen.
Training met synthetische data verwijst naar het proces waarbij kunstmatige intelligentiemodellen worden getraind met kunstmatig gegenereerde data in plaats van echte, door mensen gecreëerde informatie. In tegenstelling tot traditionele AI-training, die afhankelijk is van authentieke datasets verzameld via enquêtes, observaties of webmining, wordt synthetische data gecreëerd door algoritmen en computationele methoden die statistische patronen uit bestaande data leren of volledig nieuwe data vanaf nul genereren. Deze fundamentele verschuiving in trainingsmethodologie adresseert een cruciale uitdaging in moderne AI-ontwikkeling: de exponentiële groei van computationele eisen heeft het menselijk vermogen om voldoende echte data te genereren overtroffen, waarbij onderzoek aangeeft dat door mensen gegenereerde trainingsdata binnen enkele jaren uitgeput kan raken. Training met synthetische data biedt een schaalbaar, kosteneffectief alternatief dat oneindig kan worden gegenereerd zonder de tijdrovende processen van dataverzameling, labeling en opschoning die tot wel 80% van de traditionele AI-ontwikkelingstijd in beslag nemen.
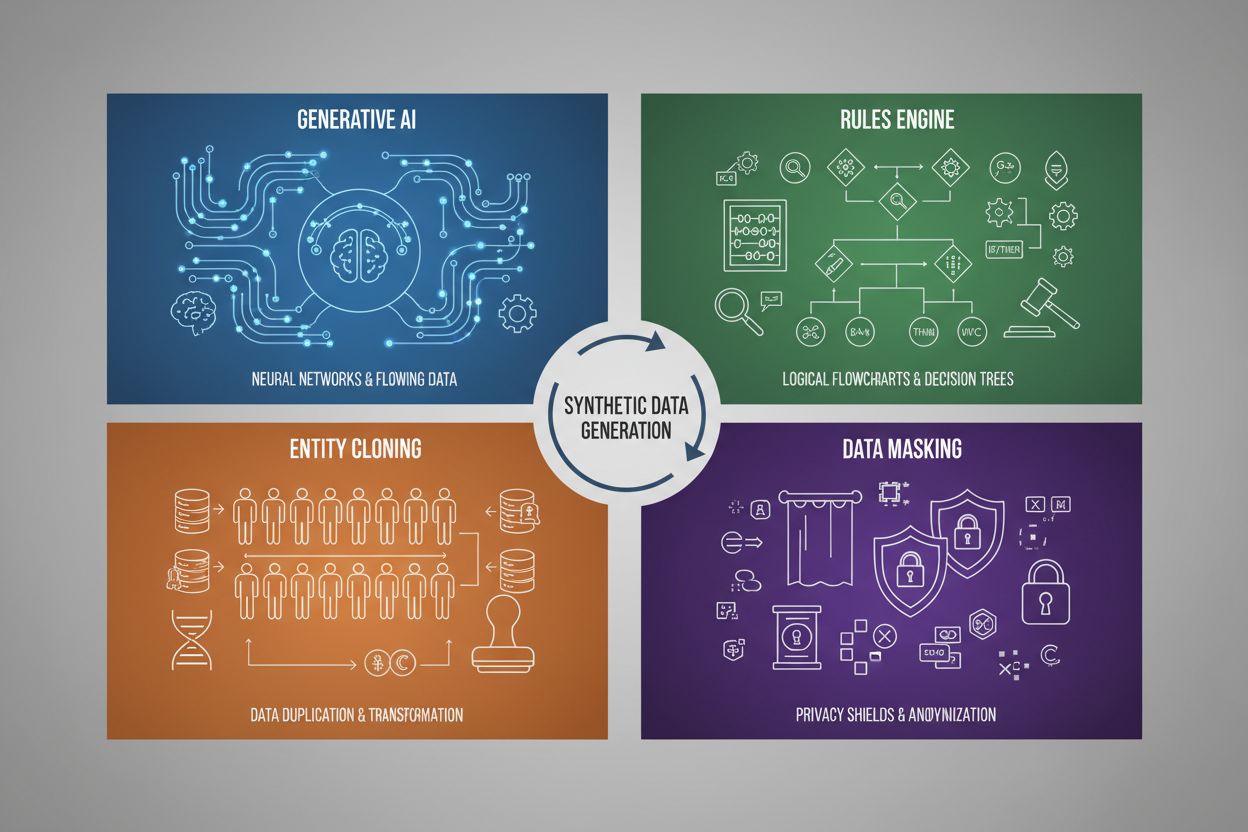
Het genereren van synthetische data maakt gebruik van vier primaire technieken, elk met eigen mechanismen en toepassingsgebieden:
| Techniek | Hoe het werkt | Toepassing |
|---|---|---|
| Generatieve AI (GAN’s, VAE’s, GPT) | Gebruikt deep learning-modellen om statistische patronen en verdelingen uit echte data te leren en genereert vervolgens nieuwe synthetische voorbeelden die dezelfde statistische eigenschappen en relaties behouden. GAN’s gebruiken adversariële netwerken waarbij een generator nepdata creëert en een discriminator de authenticiteit evalueert, wat leidt tot steeds realistischere output. | Training van grote taalmodellen zoals ChatGPT, genereren van synthetische beelden met DALL-E, creëren van diverse tekstdatasets voor taken in natuurlijke taalverwerking |
| Regelengine | Past vooraf gedefinieerde logische regels en beperkingen toe om data te genereren die specifieke zakelijke logica, domeinkennis of regelgeving volgt. Deze deterministische aanpak zorgt ervoor dat de gegenereerde data voldoet aan bekende patronen en relaties zonder machine learning. | Financiële transactiedata, medische dossiers met specifieke compliancevereisten, productie-sensordata met bekende operationele parameters |
| Entiteitklonen | Dupliceert en wijzigt bestaande echte datagegevens door transformaties, verstoringen of variaties toe te passen om nieuwe instanties te creëren, terwijl de belangrijkste statistische eigenschappen en relaties behouden blijven. Deze techniek behoudt de authenticiteit van data en vergroot tegelijkertijd de dataset. | Uitbreiden van beperkte datasets in gereguleerde sectoren, creëren van trainingsdata voor diagnose van zeldzame ziekten, aanvullen van datasets met onvoldoende minderheidsvoorbeelden |
| Datamasking & Anonimisering | Maakt gevoelige persoonsgegevens (PII) onherkenbaar terwijl de datastructuur en statistische relaties behouden blijven door technieken zoals tokenisatie, encryptie of waardevervanging. Dit resulteert in privacybeschermende synthetische versies van echte data. | Medische en financiële datasets, klantgedragdata, persoonsgevoelige informatie in onderzoekscontexten |
Training met synthetische data levert aanzienlijke kostenbesparingen op door dure processen zoals dataverzameling, annotatie en opschoning te elimineren, die traditioneel veel middelen en tijd vergen. Organisaties kunnen onbeperkt trainingsvoorbeelden genereren op aanvraag, waardoor modelontwikkeling veel sneller verloopt en snelle iteratie en experimentatie mogelijk wordt zonder te hoeven wachten op het verzamelen van echte data. De techniek biedt krachtige data-augmentatiemogelijkheden, waarmee ontwikkelaars beperkte datasets kunnen uitbreiden en gebalanceerde trainingssets kunnen maken om problemen met klassenonbalans aan te pakken—een cruciale kwestie waarbij bepaalde categorieën ondervertegenwoordigd zijn in echte data. Synthetische data is vooral waardevol voor het oplossen van dataschaarste in gespecialiseerde domeinen zoals medische beeldvorming, diagnose van zeldzame ziekten of testen van autonome voertuigen, waar het verzamelen van voldoende echte voorbeelden prohibitief duur of ethisch gevoelig is. Privacybescherming is een belangrijk voordeel, omdat synthetische data kan worden gegenereerd zonder gevoelige persoonsgegevens bloot te stellen, waardoor het ideaal is voor het trainen van modellen op medische dossiers, financiële data of andere gereguleerde informatie. Daarnaast maakt synthetische data systematische biasreductie mogelijk doordat ontwikkelaars bewust gebalanceerde, diverse datasets kunnen creëren die discriminerende patronen in echte data tegengaan—bijvoorbeeld door diverse demografische representaties te genereren in trainingsafbeeldingen om te voorkomen dat AI-modellen gender- of raciale stereotypen versterken in werving, kredietverlening of strafrechtelijke toepassingen.
Ondanks de beloften introduceert training met synthetische data aanzienlijke technische en praktische uitdagingen die de modelprestatie kunnen ondermijnen als ze niet zorgvuldig worden beheerd. De belangrijkste zorg is modelcollaps, een fenomeen waarbij AI-modellen die uitgebreid zijn getraind op synthetische data een ernstige achteruitgang in outputkwaliteit, nauwkeurigheid en samenhang ervaren. Dit gebeurt omdat synthetische data, hoewel statistisch vergelijkbaar met echte data, de fijnzinnige complexiteit en uitzonderingen van authentieke, door mensen gegenereerde informatie mist—wanneer modellen worden getraind op AI-gegenereerde content, gaan ze fouten en artefacten versterken, waardoor een probleem ontstaat waarbij elke generatie synthetische data van steeds lagere kwaliteit wordt.
Belangrijke uitdagingen zijn onder andere:
Deze uitdagingen onderstrepen waarom synthetische data niet als vervanging voor echte data kan dienen—het moet zorgvuldig worden geïntegreerd als aanvulling op authentieke datasets, met strikte kwaliteitsbewaking en menselijk toezicht tijdens het hele trainingsproces.
Nu synthetische data steeds vaker wordt gebruikt bij AI-modeltraining, staan merken voor een nieuwe, kritieke uitdaging: zorgen voor een correcte en gunstige weergave in AI-gegenereerde output en citaties. Wanneer grote taalmodellen en generatieve AI-systemen worden getraind op synthetische data, beïnvloeden de kwaliteit en eigenschappen van die synthetische data rechtstreeks hoe merken worden beschreven, aanbevolen en geciteerd in AI-zoekresultaten, chatbot-antwoorden en geautomatiseerde contentgeneratie. Dit creëert een aanzienlijk merkveiligheidsrisico, omdat synthetische data met verouderde informatie, concurrentiebias of onnauwkeurige merkbeschrijvingen kan worden ingebed in AI-modellen, wat leidt tot aanhoudende misrepresentatie bij miljoenen gebruikersinteracties. Voor organisaties die platforms zoals AmICited.com gebruiken om hun merkpositie in AI-systemen te monitoren, wordt inzicht in de rol van synthetische data in modeltraining essentieel—merken moeten zicht hebben op of AI-citaties en vermeldingen afkomstig zijn van echte trainingsdata of van synthetische bronnen, omdat dit invloed heeft op geloofwaardigheid en nauwkeurigheid. De transparantiekloof rond het gebruik van synthetische data in AI-training zorgt voor verantwoordingsproblemen: bedrijven kunnen niet gemakkelijk bepalen of hun merkinformatie accuraat is weergegeven in synthetische datasets die zijn gebruikt om modellen te trainen die consumentenperceptie beïnvloeden. Vooruitstrevende merken moeten AI-monitoring en citatietracking prioriteren om misrepresentaties vroegtijdig te detecteren, pleiten voor transparantiestandaarden die openbaarmaking van synthetisch datagebruik in AI-training vereisen en samenwerken met platforms die inzicht geven in hoe hun merk wordt weergegeven in AI-systemen die zijn getraind met zowel echte als synthetische data. Naarmate synthetische data tegen 2030 het dominante trainingsparadigma wordt, verschuift merkmonitoring van traditionele mediatracking naar uitgebreide AI-citatie-intelligentie, waardoor platforms die merkrepresentatie in generatieve AI-systemen volgen onmisbaar worden voor het beschermen van merkidentiteit en het waarborgen van een correcte merkstem in het AI-gedreven informatie-ecosysteem.
Traditionele AI-training is afhankelijk van echte data die door mensen is verzameld via enquêtes, observaties of webmining, wat tijdrovend is en steeds schaarser wordt. Training met synthetische data gebruikt kunstmatig gegenereerde gegevens die zijn gemaakt door algoritmen die statistische patronen uit bestaande data leren of volledig nieuwe data vanaf nul genereren. Synthetische data kan oneindig op aanvraag worden geproduceerd, waardoor de ontwikkeltijd en -kosten drastisch verminderen en privacyproblemen worden aangepakt.
De vier primaire technieken zijn: 1) Generatieve AI (met GAN's, VAE's of GPT-modellen die datapatronen leren en repliceren), 2) Regelengine (toepassen van vooraf gedefinieerde zakelijke logica en beperkingen), 3) Entiteitklonen (bestaande records dupliceren en aanpassen met behoud van statistische eigenschappen), en 4) Datamasking (anoniem maken van gevoelige informatie met behoud van datastructuur). Elke techniek heeft verschillende toepassingsgebieden en eigen voordelen.
Modelcollaps treedt op wanneer AI-modellen die uitgebreid zijn getraind op synthetische data een ernstige achteruitgang in outputkwaliteit en nauwkeurigheid ervaren. Dit gebeurt omdat synthetische data, hoewel statistisch vergelijkbaar met echte data, de genuanceerde complexiteit en uitzonderingen van authentieke informatie mist. Wanneer modellen worden getraind op AI-gegenereerde content, versterken ze fouten en artefacten, waardoor een probleem ontstaat waarbij elke generatie steeds lagere kwaliteit oplevert en uiteindelijk onbruikbare resultaten produceert.
Wanneer AI-modellen worden getraind op synthetische data, beïnvloeden de kwaliteit en eigenschappen van die synthetische data direct hoe merken worden beschreven, aanbevolen en geciteerd in AI-uitvoer. Synthetische data van slechte kwaliteit met verouderde informatie of concurrentiebias kan worden ingebed in AI-modellen, wat leidt tot aanhoudende merkmisrepresentatie bij miljoenen gebruikersinteracties. Dit creëert een merkveiligheidsprobleem dat monitoring en transparantie vereist over het gebruik van synthetische data in AI-training.
Nee, synthetische data moet echte data aanvullen en niet vervangen. Hoewel synthetische data aanzienlijke voordelen biedt qua kosten, snelheid en privacy, kan het de complexiteit, diversiteit en uitzonderingen van authentieke, door mensen gegenereerde data niet volledig repliceren. De meest effectieve aanpak combineert synthetische en echte data, met strenge kwaliteitsbewaking en menselijk toezicht om de nauwkeurigheid en betrouwbaarheid van het model te waarborgen.
Synthetische data biedt superieure privacybescherming omdat het geen echte waarden uit originele datasets bevat en geen één-op-één-relaties met echte personen heeft. In tegenstelling tot traditionele technieken voor datamasking of anonimisering, die nog steeds risico's op heridentificatie kunnen opleveren, wordt synthetische data volledig vanaf nul gecreëerd op basis van geleerde patronen. Dit maakt het ideaal voor het trainen van modellen op gevoelige informatie zoals medische dossiers, financiële gegevens of persoonlijk gedrag zonder echte persoonsgegevens bloot te stellen.
Synthetische data maakt systematische biasreductie mogelijk doordat ontwikkelaars bewust gebalanceerde, diverse datasets kunnen maken die discriminerende patronen in echte data tegengaan. Zo kunnen ontwikkelaars bijvoorbeeld diverse demografische representaties genereren in trainingsafbeeldingen om te voorkomen dat AI-modellen gender- of raciale stereotypen versterken. Deze mogelijkheid is vooral waardevol in toepassingen zoals werving, kredietverlening en strafrecht, waar bias ernstige gevolgen kan hebben.
Aangezien synthetische data tegen 2030 het dominante trainingsparadigma wordt, moeten merken begrijpen hoe hun informatie wordt weergegeven in AI-systemen. De kwaliteit van synthetische data beïnvloedt direct merkcitaten en vermeldingen in AI-uitvoer. Merken moeten hun aanwezigheid in AI-systemen monitoren, pleiten voor transparantiestandaarden die openbaarmaking van synthetisch datagebruik vereisen, en platforms zoals AmICited.com gebruiken om merkrepresentatie te volgen en misrepresentaties vroegtijdig te detecteren.
Ontdek hoe uw merk wordt weergegeven in AI-systemen die zijn getraind op synthetische data. Volg citaties, bewaak nauwkeurigheid en waarborg merkveiligheid in het AI-gedreven informatie-ecosysteem.
Trainingsgegevens zijn de dataset die gebruikt worden om ML-modellen patronen en relaties te laten leren. Ontdek hoe de kwaliteit van trainingsgegevens de prest...

Compleet overzicht van het afmelden voor AI-trainingsgegevensverzameling bij ChatGPT, Perplexity, LinkedIn en andere platforms. Leer stapsgewijze instructies om...

Vergelijk optimalisatiestrategieën van trainingsdata en real-time retrieval voor AI. Leer wanneer je fine-tuning of RAG gebruikt, kostenoverwegingen en hybride ...
Cookie Toestemming
We gebruiken cookies om uw browse-ervaring te verbeteren en ons verkeer te analyseren. See our privacy policy.