
Treningsdata
Treningsdata er datasettet som brukes til å lære ML-modeller mønstre og sammenhenger. Lær hvordan kvaliteten på treningsdata påvirker AI-modellers ytelse, nøyak...
10 min lesing

Trening med syntetiske data er prosessen med å trene KI-modeller ved hjelp av kunstig genererte data i stedet for virkelige, menneskeskapte opplysninger. Denne tilnærmingen løser problemer med datamangel, akselererer modellutvikling og ivaretar personvern, samtidig som utfordringer som modellkollaps og hallusinasjoner krever nøye håndtering og validering.
Trening med syntetiske data er prosessen med å trene KI-modeller ved hjelp av kunstig genererte data i stedet for virkelige, menneskeskapte opplysninger. Denne tilnærmingen løser problemer med datamangel, akselererer modellutvikling og ivaretar personvern, samtidig som utfordringer som modellkollaps og hallusinasjoner krever nøye håndtering og validering.
Trening med syntetiske data viser til prosessen med å trene kunstig intelligens-modeller ved hjelp av kunstig genererte data i stedet for virkelige, menneskeskapte opplysninger. I motsetning til tradisjonell KI-trening, som er avhengig av autentiske datasett samlet inn gjennom undersøkelser, observasjoner eller nettgruvedrift, lages syntetiske data gjennom algoritmer og beregningsmetoder som lærer statistiske mønstre fra eksisterende data eller genererer helt nye data fra bunnen av. Dette grunnleggende skiftet i treningsmetodikk løser en kritisk utfordring i moderne KI-utvikling: Den eksponentielle veksten i datakraft har overgått menneskehetens evne til å generere tilstrekkelige virkelige data, og forskning antyder at menneskegenererte treningsdata kan bli oppbrukt i løpet av de neste årene. Trening med syntetiske data tilbyr et skalerbart, kostnadseffektivt alternativ som kan genereres i det uendelige uten de tidkrevende prosessene med datainnsamling, merking og rensing som opptar opptil 80 % av tradisjonelle KI-utviklingsløp.
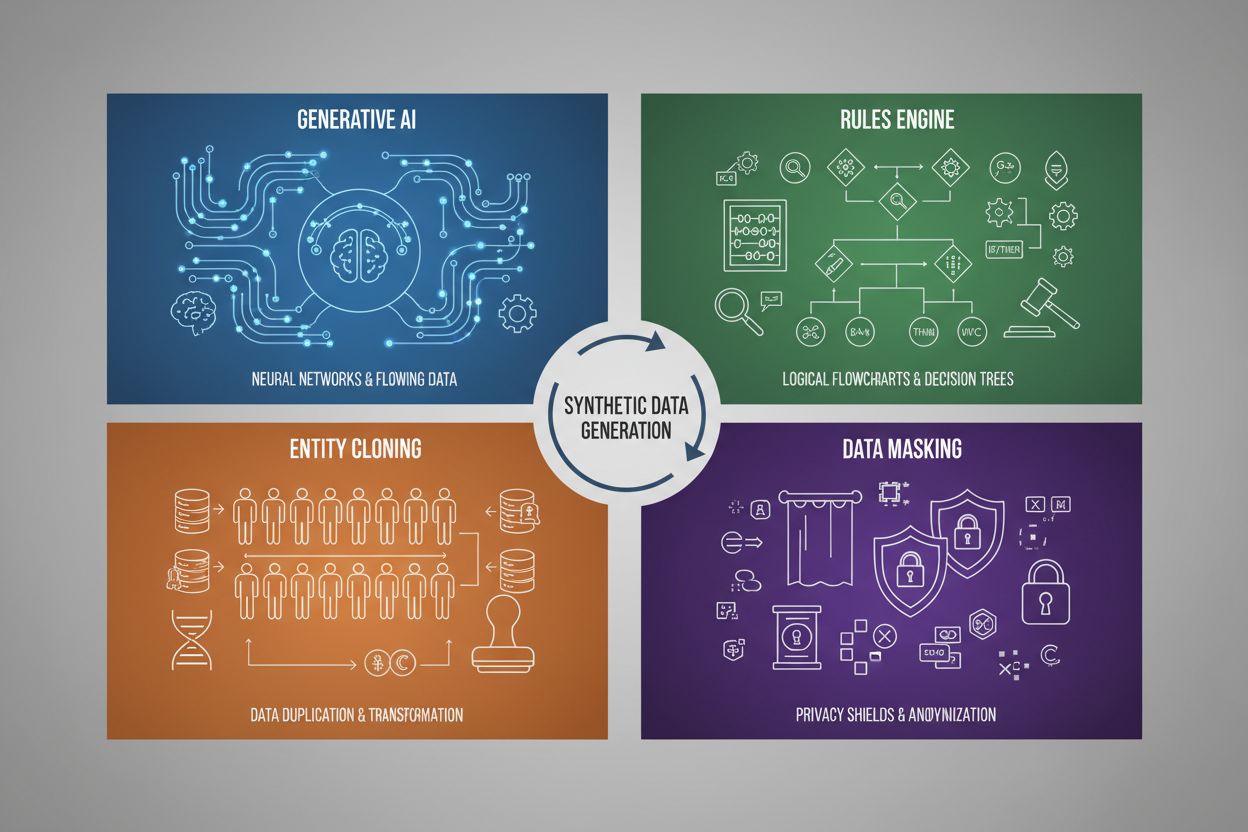
Generering av syntetiske data benytter fire hovedteknikker, hver med ulike mekanismer og bruksområder:
| Teknikk | Hvordan det fungerer | Bruksområde |
|---|---|---|
| Generativ KI (GANs, VAEs, GPT) | Bruker dype læringsmodeller til å lære statistiske mønstre og fordelinger fra virkelige data, og genererer deretter nye syntetiske eksempler som opprettholder de samme statistiske egenskapene og relasjonene. GANs bruker konkurrerende nettverk der en generator lager falske data mens en diskriminator vurderer ektheten, noe som gir stadig mer realistiske utdata. | Trening av store språkmodeller som ChatGPT, generering av syntetiske bilder med DALL-E, skape mangfoldige tekstdatasett for naturlig språkprosessering |
| Regelmotor | Anvender forhåndsbestemte logiske regler og begrensninger for å generere data som følger spesifikk forretningslogikk, domeneinnsikt eller regulatoriske krav. Denne deterministiske tilnærmingen sikrer at genererte data følger kjente mønstre og relasjoner uten å bruke maskinlæring. | Finansielle transaksjonsdata, helsedata med spesifikke samsvarskrav, produksjonssensordata med kjente driftsparametere |
| Entitetskloning | Dupliserer og modifiserer eksisterende virkelige dataoppføringer ved å bruke transformasjoner, forstyrrelser eller variasjoner for å lage nye instanser, samtidig som sentrale statistiske egenskaper og relasjoner bevares. Denne teknikken opprettholder dataautentisitet og øker datasettstørrelsen. | Utvide begrensede datasett i regulerte bransjer, lage treningsdata for sjeldne sykdomsdiagnoser, øke datasett med for få minoritetseksempler |
| Datamaskering og anonymisering | Skjuler sensitivt identifiserbar informasjon (PII) samtidig som datastruktur og statistiske relasjoner bevares gjennom teknikker som tokenisering, kryptering eller verdierstatning. Dette skaper personvern-ivaretakende syntetiske versjoner av virkelige data. | Helse- og finansdatasett, kundeatferdsdata, sensitiv personlig informasjon i forskningssammenheng |
Trening med syntetiske data gir betydelige kostnadsreduksjoner ved å fjerne dyre prosesser for datainnsamling, merking og rensing som tradisjonelt krever mye ressurser og tid. Organisasjoner kan generere ubegrensede treningsprøver på forespørsel, noe som dramatisk akselererer modellutviklingssykluser og muliggjør rask iterasjon og eksperimentering uten å måtte vente på datainnsamling fra virkeligheten. Teknikken gir kraftige muligheter for dataforsterkning, slik at utviklere kan utvide begrensede datasett og lage balanserte treningssett som adresserer problemer med ubalanserte klasser – et kritisk problem der enkelte kategorier er underrepresentert i virkelige data. Syntetiske data er spesielt verdifulle for å løse datamangel i spesialiserte domener som medisinsk bildebehandling, sjeldne sykdomsdiagnoser eller testing av autonome kjøretøy, der det er for dyrt eller etisk utfordrende å samle inn tilstrekkelige virkelige eksempler. Personvern er en stor fordel, fordi syntetiske data kan genereres uten å eksponere sensitiv personlig informasjon, noe som gjør dem ideelle for trening av modeller på helsedata, finansielle data eller annen regulert informasjon. I tillegg muliggjør syntetiske data systematisk reduksjon av skjevhet ved at utviklere kan lage balanserte, mangfoldige datasett som motvirker diskriminerende mønstre i virkelige data – for eksempel ved å generere ulike demografiske representasjoner i treningsbilder for å forhindre at KI-modeller viderefører kjønns- eller raseskjevheter i rekruttering, utlån eller rettsvesen.
Til tross for sitt potensial, introduserer trening med syntetiske data betydelige tekniske og praktiske utfordringer som kan svekke modellens ytelse dersom de ikke håndteres nøye. Den mest kritiske bekymringen er modellkollaps, et fenomen der KI-modeller som trenes omfattende på syntetiske data, får kraftig svekket kvalitet, nøyaktighet og sammenheng i utdataene. Dette skjer fordi syntetiske data, selv om de er statistisk like virkelige data, mangler den nyanserte kompleksiteten og særtilfellene som finnes i autentiske menneskeskapte opplysninger – når modeller trenes på KI-generert innhold, begynner de å forsterke feil og artefakter, noe som skaper et kumulativt problem der hver generasjon syntetiske data blir stadig dårligere.
Viktige utfordringer inkluderer:
Disse utfordringene understreker hvorfor syntetiske data ikke kan erstatte virkelige data alene – de må integreres nøye som supplement til autentiske datasett, med streng kvalitetskontroll og menneskelig tilsyn gjennom hele treningsprosessen.
Etter hvert som syntetiske data blir stadig mer utbredt i KI-modelltrening, står merkevarer overfor en ny, kritisk utfordring: å sikre nøyaktig og gunstig representasjon i KI-genererte utdata og sitater. Når store språkmodeller og generativ KI trenes på syntetiske data, påvirker kvaliteten og egenskapene til disse dataene direkte hvordan merkevarer beskrives, anbefales og siteres i KI-søkeresultater, chatbot-svar og automatisert innhold. Dette skaper en betydelig risiko for merkevaresikkerhet, fordi syntetiske data med foreldet informasjon, konkurransevridning eller unøyaktige merkevarebeskrivelser kan bli innebygd i KI-modeller, og føre til vedvarende feilrepresentasjon gjennom millioner av brukerinteraksjoner. For organisasjoner som bruker plattformer som AmICited.com for å overvåke sin merkevaretilstedeværelse i KI-systemer, blir forståelsen av syntetiske datas rolle i modelltrening essensiell – merkevarer trenger innsikt i om KI-sitater og omtaler stammer fra virkelige treningsdata eller syntetiske kilder, ettersom dette påvirker troverdighet og nøyaktighet. Transparensmangelen rundt bruk av syntetiske data i KI-trening skaper ansvarlighetsutfordringer: Selskaper kan ikke enkelt avgjøre om deres merkevareinformasjon er korrekt representert i syntetiske datasett brukt til å trene modeller som påvirker forbrukeroppfatning. Fremoverlente merkevarer bør prioritere KI-overvåkning og siteringssporing for å oppdage feilrepresentasjoner tidlig, arbeide for transparenskrav som krever åpenhet om bruk av syntetiske data i KI-trening, og samarbeide med plattformer som gir innsikt i hvordan merkevaren fremstår på tvers av KI-systemer trent på både virkelige og syntetiske data. Etter hvert som syntetiske data blir det dominerende treningsparadigmet innen 2030, vil merkevareovervåkning gå fra tradisjonell mediesporing til helhetlig KI-siteringsintelligens, og plattformer som sporer merkevarerepresentasjon på tvers av generative KI-systemer blir uunnværlige for å beskytte merkevareintegritet og sikre riktig merkevarestemme i det KI-drevne informasjonssystemet.
Tradisjonell KI-trening er avhengig av virkelige data samlet inn fra mennesker gjennom undersøkelser, observasjoner eller nettgruvedrift, som er tidkrevende og blir stadig mer knapp. Trening med syntetiske data bruker kunstig genererte data laget av algoritmer som lærer statistiske mønstre fra eksisterende data eller genererer helt nye data fra bunnen av. Syntetiske data kan produseres uendelig på forespørsel, noe som dramatisk reduserer utviklingstid og kostnader, samtidig som personvernhensyn ivaretas.
De fire primære teknikkene er: 1) Generativ KI (bruk av GANs, VAEs eller GPT-modeller for å lære og reprodusere datamønstre), 2) Regelmotor (anvendelse av forhåndsdefinert forretningslogikk og begrensninger), 3) Entitetskloning (duplisering og modifisering av eksisterende oppføringer samtidig som statistiske egenskaper bevares), og 4) Datamaskering (anonymisering av sensitiv informasjon samtidig som datastruktur opprettholdes). Hver teknikk har ulike bruksområder og fordeler.
Modellkollaps oppstår når KI-modeller som trenes omfattende på syntetiske data, opplever kraftig forringelse i kvalitet og nøyaktighet på utdataene. Dette skjer fordi syntetiske data, selv om de er statistisk lik virkelige data, mangler den nyanserte kompleksiteten og særtilfellene til autentisk informasjon. Når modeller trenes på KI-generert innhold, forsterker de feil og artefakter, noe som skaper et sammensatt problem der hver generasjon blir stadig lavere i kvalitet, til det til slutt produseres ubrukelige utdata.
Når KI-modeller trenes på syntetiske data, påvirker kvaliteten og egenskapene til disse dataene direkte hvordan merkevarer beskrives, anbefales og siteres i KI-utdata. Syntetiske data av dårlig kvalitet med foreldet informasjon eller konkurransevridning kan bli innebygd i KI-modeller, noe som fører til vedvarende feilrepresentasjon av merkevaren gjennom millioner av brukerinteraksjoner. Dette skaper et behov for overvåkning og transparens rundt bruk av syntetiske data i KI-trening.
Nei, syntetiske data bør supplere, ikke erstatte, virkelige data. Selv om syntetiske data gir store fordeler i kostnad, hastighet og personvern, kan de ikke fullt ut replikere kompleksiteten, mangfoldet og særtilfellene som finnes i autentiske menneskeskapte data. Den mest effektive tilnærmingen kombinerer syntetiske og virkelige data, med streng kvalitetskontroll og menneskelig tilsyn for å sikre modellens nøyaktighet og pålitelighet.
Syntetiske data gir overlegen personvern fordi de ikke inneholder faktiske verdier fra de opprinnelige datakildene og ikke har én-til-én-forhold til ekte individer. I motsetning til tradisjonelle teknikker som datamaskering eller anonymisering, som fortsatt kan innebære risiko for re-identifisering, lages syntetiske data helt fra bunnen av basert på innlærte mønstre. Dette gjør dem ideelle for å trene modeller på sensitive data som helseregistre, finansielle data eller personadferd uten å eksponere reelle personopplysninger.
Syntetiske data muliggjør systematisk reduksjon av skjevhet ved at utviklerne bevisst kan lage balanserte, mangfoldige datasett som motvirker diskriminerende mønstre i virkelige data. For eksempel kan utviklere generere ulike demografiske representasjoner i treningsbilder for å forhindre at KI-modeller viderefører kjønns- eller rasestereotypier. Dette er spesielt verdifullt i applikasjoner som rekruttering, utlån og strafferett, hvor skjevhet kan få alvorlige konsekvenser.
Etter hvert som syntetiske data blir det dominerende treningsparadigmet innen 2030, må merkevarer forstå hvordan deres informasjon representeres i KI-systemer. Kvaliteten på syntetiske data påvirker direkte hvordan merkevaren siteres og nevnes i KI-utdata. Merkevarer bør overvåke sin tilstedeværelse i KI-systemer, arbeide for transparensstandarder som krever åpenhet om bruk av syntetiske data, og benytte plattformer som AmICited.com for å spore merkevarerepresentasjon og oppdage feilrepresentasjoner tidlig.
Oppdag hvordan din merkevare representeres på tvers av KI-systemer trent på syntetiske data. Spor sitater, overvåk nøyaktighet, og sørg for merkevaresikkerhet i det KI-drevne informasjonssystemet.
Treningsdata er datasettet som brukes til å lære ML-modeller mønstre og sammenhenger. Lær hvordan kvaliteten på treningsdata påvirker AI-modellers ytelse, nøyak...

Sammenlign optimalisering av treningsdata og strategier for sanntids-henting for KI. Lær når du bør bruke finjustering kontra RAG, kostnadsaspekter og hybride t...

Fullstendig guide til hvordan du reserverer deg mot innsamling av AI-treningsdata på tvers av ChatGPT, Perplexity, LinkedIn og andre plattformer. Lær trinn-for-...
Informasjonskapselsamtykke
Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.