Ciąg identyfikacyjny wysyłany przez AI crawlery do serwerów WWW w nagłówkach HTTP, używany do kontroli dostępu, śledzenia w analizie oraz odróżniania legalnych botów AI od złośliwych scraperów. Identyfikuje cel, wersję i pochodzenie crawlery.
AI Crawler User-Agent
Ciąg identyfikacyjny wysyłany przez AI crawlery do serwerów WWW w nagłówkach HTTP, używany do kontroli dostępu, śledzenia w analizie oraz odróżniania legalnych botów AI od złośliwych scraperów. Identyfikuje cel, wersję i pochodzenie crawlery.
Definicja AI Crawler User-Agent
AI crawler user-agent to ciąg nagłówka HTTP identyfikujący zautomatyzowane boty uzyskujące dostęp do treści internetowych w celach treningu sztucznej inteligencji, indeksowania lub badań. Ten ciąg służy jako cyfrowa tożsamość crawlery, informując serwery WWW kto składa żądanie i w jakim celu. User-agent jest kluczowy dla crawlerów AI, ponieważ pozwala właścicielom stron rozpoznawać, śledzić i kontrolować, w jaki sposób ich treści są pobierane przez różne systemy AI. Bez prawidłowej identyfikacji user-agenta rozróżnienie legalnych crawlerów AI od złośliwych botów jest znacznie trudniejsze, dlatego jest to istotny element odpowiedzialnego scrapingu oraz praktyk pozyskiwania danych.
Komunikacja HTTP i nagłówki User-Agent
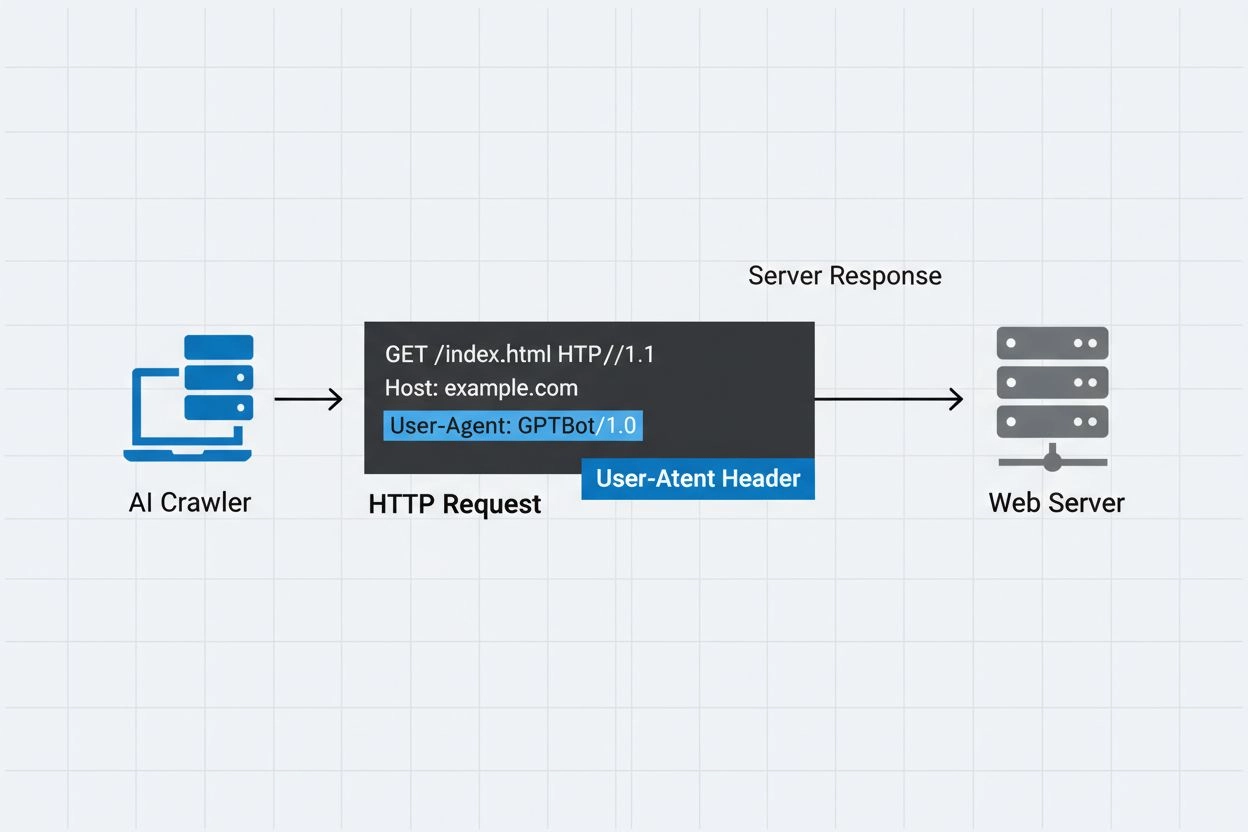
Nagłówek user-agent to kluczowy element żądań HTTP, pojawiający się w nagłówkach każdego żądania wysyłanego przez przeglądarkę lub bota podczas dostępu do zasobu WWW. Gdy crawler wysyła żądanie do serwera WWW, dołącza do nagłówków HTTP metadane o sobie, z których najważniejszym identyfikatorem jest właśnie ciąg user-agent. Typowo zawiera on informacje o nazwie crawlery, wersji, organizacji ją obsługującej oraz często adres URL lub e-mail do weryfikacji. User-agent pozwala serwerom identyfikować klienta realizującego żądanie i podejmować decyzje o udostępnieniu treści, ograniczeniu liczby żądań lub całkowitym blokowaniu dostępu. Przykłady user-agentów głównych crawlerów AI:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36; compatible; OAI-SearchBot/1.3; +https://openai.com/searchbot
Nazwa crawlery
Cel
Przykład user-agenta
Weryfikacja IP
GPTBot
Zbieranie danych treningowych
Mozilla/5.0…compatible; GPTBot/1.3
Zakresy IP OpenAI
ClaudeBot
Trening modeli
Mozilla/5.0…compatible; ClaudeBot/1.0
Zakresy IP Anthropic
OAI-SearchBot
Indeksowanie wyszukiwania
Mozilla/5.0…compatible; OAI-SearchBot/1.3
Zakresy IP OpenAI
PerplexityBot
Indeksowanie wyszukiwania
Mozilla/5.0…compatible; PerplexityBot/1.0
Zakresy IP Perplexity
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Kilka czołowych firm AI obsługuje własne crawlery z unikalnymi identyfikatorami user-agent i specyficznymi celami. Te crawlery reprezentują różne zastosowania w ekosystemie AI:
GPTBot (OpenAI): Zbiera dane treningowe dla ChatGPT i innych modeli OpenAI, respektuje dyrektywy robots.txt
ClaudeBot (Anthropic): Pozyskuje treści do treningu modeli Claude, można go blokować przez robots.txt
OAI-SearchBot (OpenAI): Indeksuje treści WWW specjalnie pod wyszukiwarkę oraz funkcje wyszukiwania opartych na AI
PerplexityBot (Perplexity AI): Crawlery internet w celu dostarczania wyników wyszukiwania i możliwości badawczych na swojej platformie
Gemini-Deep-Research (Google): Realizuje zadania deep research dla modelu Gemini AI Google’a
Meta-ExternalAgent (Meta): Zbiera dane dla inicjatyw treningowych i badawczych AI firmy Meta
Bingbot (Microsoft): Pełni podwójną rolę: tradycyjne indeksowanie wyszukiwania oraz generowanie odpowiedzi AI
Każda z tych crawlery ma określone zakresy IP i oficjalną dokumentację, do której mogą się odwoływać właściciele stron, aby potwierdzić legalność oraz wdrożyć odpowiednie zabezpieczenia dostępu.
Podszywanie się pod user-agent i wyzwania weryfikacji
Ciągi user-agent mogą być łatwo podrobione przez dowolnego klienta wysyłającego żądanie HTTP, dlatego same w sobie nie mogą stanowić jedynego mechanizmu uwierzytelniania crawlerów AI. Złośliwe boty często podszywają się pod popularne user-agenty, ukrywając swoją prawdziwą tożsamość i omijając zabezpieczenia stron lub restrykcje robots.txt. Aby przeciwdziałać tej podatności, eksperci ds. bezpieczeństwa zalecają stosowanie dodatkowej warstwy autoryzacji w postaci weryfikacji IP, czyli sprawdzania, czy żądania pochodzą z oficjalnych zakresów IP publikowanych przez firmy AI. Standard RFC 9421 HTTP Message Signatures wprowadza możliwości kryptograficznej weryfikacji, pozwalając crawlerom podpisywać żądania cyfrowo, aby serwery mogły zweryfikować ich autentyczność. Jednak rozróżnienie prawdziwych i fałszywych crawlerów wciąż stanowi wyzwanie, ponieważ zdeterminowani atakujący mogą podszywać się nie tylko pod user-agent, ale i adresy IP, korzystając z proxy lub przejętej infrastruktury. Ten ciągły wyścig między operatorami crawlerów a właścicielami stron dbającymi o bezpieczeństwo napędza rozwój nowych technik weryfikacji.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Użycie robots.txt z dyrektywami user-agent
Właściciele stron mogą zarządzać dostępem crawlerów poprzez określanie dyrektyw user-agent w pliku robots.txt, co pozwala na szczegółową kontrolę, które crawlery mogą indeksować poszczególne części witryny. Plik robots.txt wykorzystuje identyfikatory user-agent do kierowania konkretnych reguł do wybranych crawlerów, umożliwiając pozwolenie jednym, a blokowanie innych. Przykładowa konfiguracja robots.txt:
Choć robots.txt to wygodny mechanizm kontroli crawlerów, ma istotne ograniczenia:
Robots.txt ma charakter wyłącznie doradczy i nie jest egzekwowany – crawlery mogą go zignorować
Podrobione user-agenty mogą całkowicie ominąć restrykcje z robots.txt
Weryfikacja po stronie serwera przez białe listy IP zapewnia silniejszą ochronę
Reguły zapory aplikacyjnej (WAF) mogą blokować żądania z nieautoryzowanych zakresów IP
Połączenie robots.txt i weryfikacji IP daje bardziej solidną strategię kontroli dostępu
Analiza aktywności crawlerów w logach serwera
Właściciele stron mogą wykorzystać logi serwera do śledzenia i analizy aktywności crawlerów AI, uzyskując wgląd w to, które systemy AI pobierają ich treści oraz jak często to robią. Analizując logi żądań HTTP i filtrując znane user-agenty crawlerów AI, administratorzy mogą ocenić wpływ na transfer oraz schematy pozyskiwania danych przez różne firmy AI. Narzędzia do analizy logów, usługi web analytics i własne skrypty mogą przetwarzać logi serwera, identyfikując ruch crawlerów, mierząc częstotliwość żądań oraz wolumen przesyłanych danych. Jest to szczególnie ważne dla twórców treści i wydawców, którzy chcą wiedzieć, jak ich praca jest wykorzystywana do trenowania AI i czy warto wdrożyć ograniczenia dostępu. Serwisy takie jak AmICited.com odgrywają tu kluczową rolę, monitorując i śledząc, jak systemy AI cytują i odwołują się do treści z całego internetu, zapewniając twórcom przejrzystość w zakresie wykorzystania ich materiałów w treningu AI. Zrozumienie aktywności crawlerów pomaga właścicielom stron podejmować świadome decyzje dotyczące polityki treści oraz negocjować z firmami AI warunki wykorzystania danych.
Najlepsze praktyki zarządzania dostępem crawlerów AI
Skuteczne zarządzanie dostępem crawlerów AI wymaga wielowarstwowego podejścia, łączącego różne techniki weryfikacji i monitorowania:
Łącz sprawdzanie user-agenta z weryfikacją IP – Nigdy nie polegaj wyłącznie na user-agencie; zawsze sprawdzaj oficjalne zakresy IP publikowane przez firmy AI
Aktualizuj białe listy IP – Regularnie przeglądaj i uaktualniaj reguły zapory z najnowszymi zakresami IP od OpenAI, Anthropic, Google i innych dostawców AI
Regularnie analizuj logi – Planuj okresowe przeglądy logów serwera, aby wykrywać podejrzaną aktywność crawlerów i próby nieautoryzowanego dostępu
Rozróżniaj typy crawlerów – Oddziel crawlery treningowe (GPTBot, ClaudeBot) od crawlerów wyszukiwarkowych (OAI-SearchBot, PerplexityBot), aby stosować odpowiednie polityki
Uwzględnij aspekty etyczne – Wyważ restrykcje dostępu z realiami, że trening AI korzysta z różnorodnych, wysokiej jakości źródeł treści
Korzystaj z usług monitorowania – Wykorzystuj platformy takie jak AmICited.com do śledzenia, jak Twoje treści są używane i cytowane przez systemy AI, zapewniając sobie właściwe przypisanie oraz wiedzę o wpływie Twoich materiałów
Stosując te praktyki, właściciele stron mogą kontrolować swoje treści, wspierając jednocześnie odpowiedzialny rozwój systemów AI.
Najczęściej zadawane pytania
Czym jest ciąg user-agent?
User-agent to ciąg nagłówka HTTP identyfikujący klienta wykonującego żądanie do strony internetowej. Zawiera informacje o oprogramowaniu, systemie operacyjnym i wersji aplikacji wykonującej żądanie – czy to przeglądarka, crawler, czy bot. Pozwala serwerom WWW identyfikować i śledzić różne typy klientów uzyskujących dostęp do treści.
Dlaczego AI crawlery potrzebują ciągów user-agent?
Ciągi user-agent pozwalają serwerom WWW zidentyfikować, który crawler uzyskuje dostęp do treści, umożliwiając właścicielom stron kontrolę dostępu, śledzenie aktywności crawlerów i rozróżnianie różnych typów botów. Jest to kluczowe dla zarządzania transferem, ochrony treści i zrozumienia, jak systemy AI wykorzystują Twoje dane.
Czy ciągi user-agent można podrobić?
Tak, ciągi user-agent można łatwo podrobić, ponieważ są to tylko wartości tekstowe w nagłówkach HTTP. Dlatego ważna jest dodatkowa weryfikacja IP oraz stosowanie podpisów wiadomości HTTP jako metod potwierdzających prawdziwą tożsamość crawlery i chroniących przed podszywaniem się złośliwych botów pod legalne crawlery.
Jak zablokować konkretne crawlery AI?
Możesz użyć robots.txt z dyrektywami user-agent, aby poprosić crawlery o nieodwiedzanie strony, ale nie jest to wymuszane. Dla większej kontroli stosuj weryfikację po stronie serwera, białe/czarne listy IP lub reguły WAF sprawdzające jednocześnie user-agent i adres IP.
Jaka jest różnica między GPTBot a OAI-SearchBot?
GPTBot to crawler OpenAI zbierający dane treningowe dla modeli AI takich jak ChatGPT, natomiast OAI-SearchBot służy do indeksowania i zasilania wyszukiwarki w ChatGPT. Mają różne cele, częstotliwości crawlowań i zakresy IP, co wymaga odmiennych strategii kontroli dostępu.
Jak sprawdzić, czy crawler jest legalny?
Sprawdź adres IP crawlera z oficjalną listą IP publikowaną przez operatora crawlera (np. openai.com/gptbot.json dla GPTBot). Legalne crawlery publikują swoje zakresy IP i możesz potwierdzić pochodzenie żądań przez reguły zapory lub konfigurację WAF.
Czym jest weryfikacja podpisu wiadomości HTTP?
HTTP Message Signatures (RFC 9421) to metoda kryptograficzna, w której crawlery podpisują żądania kluczem prywatnym. Serwery mogą zweryfikować podpis używając klucza publicznego crawlery z katalogu .well-known, co potwierdza autentyczność żądania i jego integralność.
Jak AmICited.com pomaga monitorować crawlery AI?
AmICited.com monitoruje, jak systemy AI cytują i odwołują się do Twojej marki w GPT, Perplexity, Google AI Overviews i innych platformach AI. Śledzi aktywność crawlerów i wzmianki AI, pomagając zrozumieć widoczność w odpowiedziach AI i sposób wykorzystania Twoich treści.
Monitoruj swoją markę w systemach AI
Śledź, jak AI crawlery cytują i odwołują się do Twoich treści w ChatGPT, Perplexity, Google AI Overviews i innych platformach AI dzięki AmICited.
Jak zidentyfikować crawlery AI w logach serwera: Kompletny przewodnik po wykrywaniu
Dowiedz się, jak identyfikować i monitorować crawlery AI takie jak GPTBot, PerplexityBot i ClaudeBot w logach serwera. Poznaj ciągi user-agent, metody weryfikac...
Jakim Crawlerom AI Pozwolić na Dostęp? Kompletny Przewodnik na 2025
Dowiedz się, którym crawlerom AI pozwolić, a które zablokować w swoim pliku robots.txt. Kompleksowy przewodnik obejmujący GPTBot, ClaudeBot, PerplexityBot oraz ...
Dowiedz się, jak działają AI crawlers takie jak GPTBot i ClaudeBot, czym różnią się od tradycyjnych crawlerów wyszukiwarek oraz jak zoptymalizować swoją stronę ...
12 min czytania
Zgoda na Pliki Cookie Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.