
Dane treningowe
Dane treningowe to zbiór danych używany do nauki modeli ML wzorców i zależności. Dowiedz się, jak jakość danych treningowych wpływa na wydajność modeli AI, ich ...
11 min czytania

Trenowanie na danych syntetycznych to proces uczenia modeli sztucznej inteligencji przy użyciu sztucznie wygenerowanych danych, a nie rzeczywistych, stworzonych przez ludzi informacji. Takie podejście rozwiązuje problem niedoboru danych, przyspiesza rozwój modeli i chroni prywatność, jednocześnie wprowadzając wyzwania, takie jak degradacja modeli czy halucynacje, które wymagają starannego zarządzania i walidacji.
Trenowanie na danych syntetycznych to proces uczenia modeli sztucznej inteligencji przy użyciu sztucznie wygenerowanych danych, a nie rzeczywistych, stworzonych przez ludzi informacji. Takie podejście rozwiązuje problem niedoboru danych, przyspiesza rozwój modeli i chroni prywatność, jednocześnie wprowadzając wyzwania, takie jak degradacja modeli czy halucynacje, które wymagają starannego zarządzania i walidacji.
Trenowanie na danych syntetycznych odnosi się do procesu uczenia modeli sztucznej inteligencji przy użyciu sztucznie wygenerowanych danych, zamiast rzeczywistych informacji pochodzących od ludzi. W przeciwieństwie do tradycyjnego trenowania AI, które opiera się na autentycznych zbiorach danych zebranych w wyniku ankiet, obserwacji lub przeszukiwania internetu, dane syntetyczne powstają dzięki algorytmom i metodom obliczeniowym, które uczą się wzorców statystycznych z istniejących danych lub generują całkowicie nowe dane od podstaw. Ta fundamentalna zmiana w metodologii trenowania odpowiada na kluczowe wyzwanie współczesnego rozwoju AI: wykładniczy wzrost zapotrzebowania na moc obliczeniową wyprzedził ludzką zdolność do generowania wystarczającej ilości rzeczywistych danych, a badania wskazują, że zasoby danych treningowych wytworzonych przez ludzi mogą zostać wyczerpane w ciągu najbliższych kilku lat. Trenowanie na danych syntetycznych oferuje skalowalną, efektywną kosztowo alternatywę, którą można generować w nieskończoność, bez czasochłonnych procesów zbierania, etykietowania i czyszczenia danych, które pochłaniają nawet 80% czasu w tradycyjnym rozwoju AI.
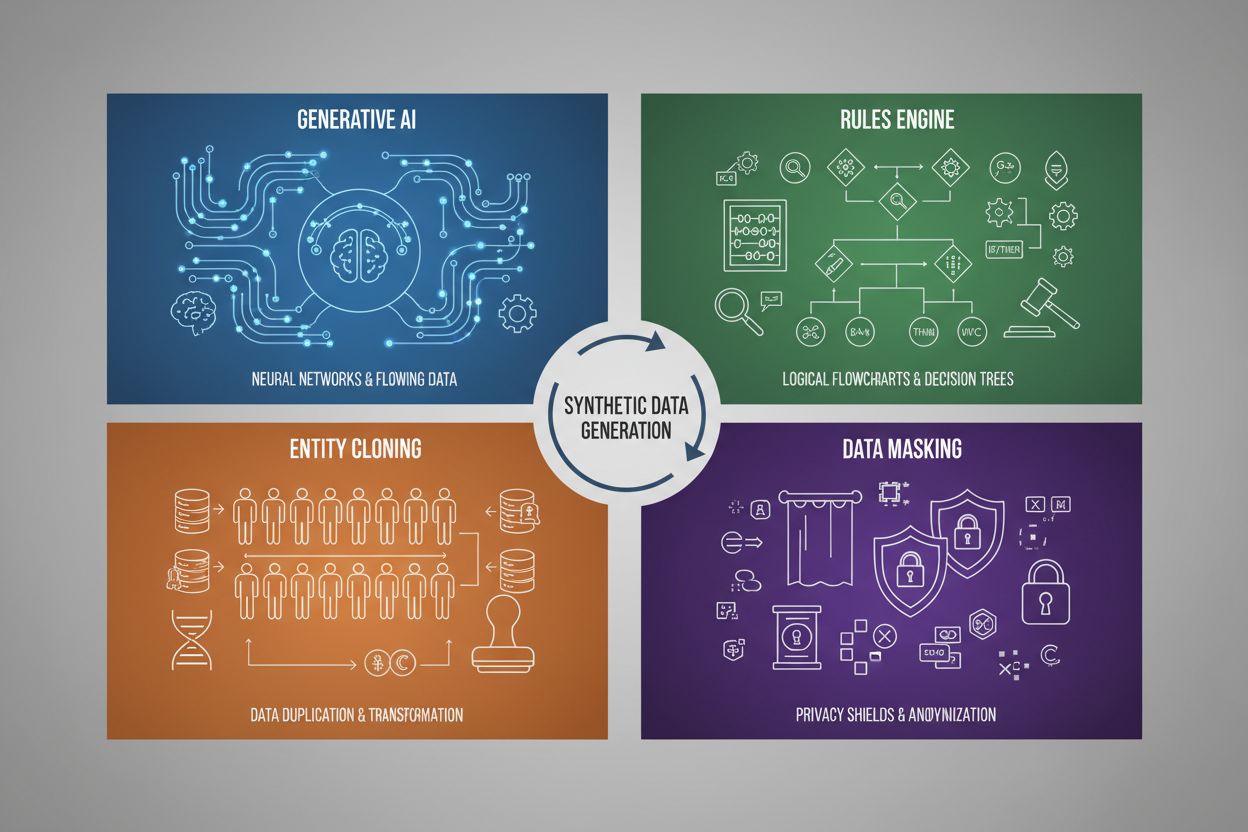
Generowanie danych syntetycznych wykorzystuje cztery główne techniki, z których każda ma odmienne mechanizmy i zastosowania:
| Technika | Na czym polega | Zastosowanie |
|---|---|---|
| Sztuczna inteligencja generatywna (GAN, VAE, GPT) | Wykorzystuje modele głębokiego uczenia do nauki wzorców statystycznych i rozkładów z danych rzeczywistych, a następnie generuje nowe próbki syntetyczne zachowujące te same właściwości i zależności. GAN-y używają sieci generującej i dyskryminującej, które wzajemnie się doskonalą, tworząc coraz bardziej realistyczne dane. | Trenowanie dużych modeli językowych jak ChatGPT, generowanie syntetycznych obrazów (np. DALL-E), tworzenie zróżnicowanych zestawów tekstu do przetwarzania języka naturalnego |
| Silnik reguł | Stosuje z góry określone reguły logiczne i ograniczenia, by generować dane zgodnie z logiką biznesową, wiedzą domenową lub wymaganiami prawnymi. Podejście deterministyczne, zapewniające zgodność z ustalonymi wzorcami, bez użycia uczenia maszynowego. | Dane transakcji finansowych, rejestry medyczne z określonymi wymogami prawnymi, dane z czujników przemysłowych o znanych parametrach pracy |
| Klonowanie encji | Duplikuje i modyfikuje istniejące rzeczywiste rekordy poprzez transformacje, zakłócenia lub wariacje, tworząc nowe instancje przy zachowaniu kluczowych własności statystycznych. Pozwala rozszerzyć zbiór danych bez utraty autentyczności. | Powiększanie ograniczonych zbiorów danych w branżach regulowanych, dane treningowe do diagnozowania rzadkich chorób, zwiększanie liczby przykładów klas mniejszościowych |
| Maskowanie i anonimizacja danych | Ukrywa wrażliwe dane osobowe (PII), zachowując strukturę i relacje statystyczne, stosując tokenizację, szyfrowanie lub podstawienie wartości. Pozwala uzyskać syntetyczne wersje danych rzeczywistych z zachowaniem prywatności. | Zbiory danych medycznych i finansowych, dane o zachowaniach klientów, wrażliwe informacje w badaniach naukowych |
Trenowanie na danych syntetycznych znacząco obniża koszty, eliminując drogie procesy zbierania, oznaczania i czyszczenia danych, które tradycyjnie pochłaniają dużo zasobów i czasu. Organizacje mogą generować nieograniczoną liczbę próbek treningowych na żądanie, radykalnie przyspieszając cykle rozwoju modeli i umożliwiając szybkie iteracje oraz eksperymenty bez oczekiwania na zebranie danych z rzeczywistości. Technika ta zapewnia potężne możliwości augmentacji danych, pozwalając deweloperom rozszerzać ograniczone zbiory danych i budować zbalansowane zestawy treningowe, rozwiązując problem niezrównoważonych klas – istotny tam, gdzie pewne kategorie są niedoreprezentowane w rzeczywistości. Dane syntetyczne są szczególnie wartościowe w zwalczaniu niedoboru danych w wyspecjalizowanych dziedzinach, takich jak obrazowanie medyczne, diagnoza rzadkich chorób czy testowanie pojazdów autonomicznych, gdzie zebranie odpowiedniej ilości przykładów realnych jest bardzo kosztowne lub nieetyczne. Zachowanie prywatności to kolejna istotna zaleta, ponieważ dane syntetyczne można generować bez ujawniania wrażliwych informacji osobowych – sprawdzają się więc idealnie do trenowania modeli na danych medycznych, finansowych czy innych regulowanych. Ponadto dane syntetyczne umożliwiają systematyczną redukcję uprzedzeń – programiści mogą celowo tworzyć zbalansowane, różnorodne zbiory, które przeciwdziałają dyskryminującym schematom obecnym w rzeczywistych danych, np. generując zróżnicowane demograficznie obrazy do treningu AI, by te nie powielały stereotypów płciowych czy rasowych w rekrutacji, finansach lub wymiarze sprawiedliwości.
Pomimo obietnic, trenowanie na danych syntetycznych wiąże się z istotnymi wyzwaniami technicznymi i praktycznymi, które mogą obniżyć wydajność modeli, jeśli nie będą odpowiednio zarządzane. Najważniejszym problemem jest degradacja modelu – zjawisko, w którym modele AI trenowane głównie na danych syntetycznych doświadczają poważnego spadku jakości, dokładności i spójności wyników. Wynika to z faktu, że dane syntetyczne, choć podobne statystycznie do rzeczywistych, nie oddają złożoności i przypadków brzegowych obecnych w autentycznych informacjach ludzkich – gdy modele uczą się na treściach generowanych przez AI, błędy i artefakty się nasilają, co prowadzi do stopniowej degradacji jakości kolejnych generacji danych syntetycznych.
Kluczowe wyzwania to:
Te wyzwania pokazują, że dane syntetyczne nie mogą całkowicie zastąpić rzeczywistych – muszą być starannie integrowane jako uzupełnienie autentycznych zbiorów, przy rygorystycznej kontroli jakości i nadzorze człowieka przez cały proces trenowania.
Wraz z rosnącym wykorzystaniem danych syntetycznych w trenowaniu modeli AI, marki stają przed nowym, kluczowym wyzwaniem: zapewnienie właściwej i korzystnej reprezentacji w wynikach i cytowaniach generowanych przez AI. Gdy duże modele językowe i systemy generatywne uczą się na danych syntetycznych, to właśnie jakość i charakter tych danych decydują o tym, jak marki są opisywane, rekomendowane i cytowane w wynikach wyszukiwania AI, odpowiedziach chatbotów czy automatycznie generowanych treściach. To rodzi poważne ryzyko dla bezpieczeństwa marki, ponieważ dane syntetyczne zawierające nieaktualne informacje, uprzedzenia konkurencyjne czy nieprecyzyjne opisy marki mogą zostać zakodowane w modelach AI, prowadząc do trwałego zniekształcenia wizerunku w milionach interakcji z użytkownikami. Dla organizacji korzystających z platform takich jak AmICited.com do monitorowania obecności marki w systemach AI, zrozumienie roli danych syntetycznych w trenowaniu modeli staje się niezbędne – marki potrzebują wglądu, czy cytowania i wzmianki AI pochodzą z rzeczywistych danych treningowych, czy ze źródeł syntetycznych, ponieważ wpływa to na wiarygodność i dokładność. Brak przejrzystości wokół wykorzystania danych syntetycznych w trenowaniu AI tworzy problemy z odpowiedzialnością: firmy nie mogą łatwo zweryfikować, czy ich wizerunek został prawidłowo odzwierciedlony w zbiorach syntetycznych używanych do trenowania modeli kształtujących percepcję konsumentów. Nowoczesne marki powinny priorytetowo traktować monitorowanie AI i śledzenie cytowań, by wcześnie wykrywać zniekształcenia, zabiegać o standardy transparentności wymagające ujawniania wykorzystania danych syntetycznych w trenowaniu AI oraz współpracować z platformami dostarczającymi wgląd w to, jak ich marka jest prezentowana w systemach AI uczonych zarówno na danych rzeczywistych, jak i syntetycznych. W miarę jak dane syntetyczne stają się dominującym paradygmatem trenowania do 2030 roku, monitorowanie marki przesunie się z tradycyjnego śledzenia mediów na kompleksowy wywiad AI dotyczący cytowań, a platformy śledzące obecność marki w systemach generatywnej AI staną się niezbędne do ochrony integralności marki i zapewnienia jej właściwego głosu w ekosystemie informacyjnym napędzanym przez AI.
Tradycyjne trenowanie AI opiera się na rzeczywistych danych zebranych od ludzi poprzez ankiety, obserwacje lub przeszukiwanie internetu, co jest czasochłonne i coraz trudniejsze. Trenowanie na danych syntetycznych wykorzystuje sztucznie generowane dane tworzone przez algorytmy uczące się wzorców statystycznych z istniejących danych lub generujące zupełnie nowe dane od podstaw. Dane syntetyczne mogą być produkowane nieskończenie na żądanie, radykalnie skracając czas i koszty rozwoju, a jednocześnie rozwiązując problemy związane z prywatnością.
Cztery podstawowe techniki to: 1) Sztuczna inteligencja generatywna (wykorzystanie GAN, VAE lub modeli GPT do uczenia się i replikowania wzorców danych), 2) Silnik reguł (stosowanie zdefiniowanej logiki biznesowej i ograniczeń), 3) Klonowanie encji (duplikowanie i modyfikowanie istniejących rekordów przy zachowaniu ich właściwości statystycznych), oraz 4) Maskowanie danych (anonimizacja wrażliwych informacji z zachowaniem struktury danych). Każda z tych technik służy innym zastosowaniom i ma swoje zalety.
Degradacja modelu (model collapse) pojawia się, gdy modele AI trenowane głównie na danych syntetycznych doświadczają poważnego pogorszenia jakości i dokładności wyników. Dzieje się tak, ponieważ dane syntetyczne, choć statystycznie podobne do rzeczywistych, nie posiadają złożoności i przypadków brzegowych charakterystycznych dla autentycznych informacji. Gdy modele uczą się na treściach generowanych przez AI, błędy i artefakty się kumulują, przez co każda kolejna generacja danych jest coraz gorszej jakości, aż do momentu, w którym wyniki stają się bezużyteczne.
Gdy modele AI uczą się na danych syntetycznych, jakość i charakter tych danych bezpośrednio wpływają na to, jak marki są opisywane, rekomendowane i cytowane w wynikach AI. Słabej jakości dane syntetyczne zawierające nieaktualne informacje lub uprzedzenia konkurencji mogą zostać zakorzenione w modelach AI, prowadząc do trwałego zniekształcenia wizerunku marki w milionach interakcji z użytkownikami. To rodzi wyzwania dla bezpieczeństwa marki i wymaga monitorowania oraz transparentności w zakresie wykorzystania danych syntetycznych w trenowaniu AI.
Nie, dane syntetyczne powinny uzupełniać, a nie zastępować rzeczywiste dane. Choć mają one istotne zalety – koszt, szybkość, prywatność – nie są w stanie w pełni oddać złożoności, różnorodności i przypadków brzegowych obecnych w danych tworzonych przez ludzi. Najskuteczniejsze podejście to łączenie danych syntetycznych i rzeczywistych, przy rygorystycznej kontroli jakości i nadzorze człowieka, aby zapewnić dokładność i niezawodność modeli.
Dane syntetyczne zapewniają znacznie lepszą ochronę prywatności, ponieważ nie zawierają rzeczywistych wartości z oryginalnych zbiorów danych i nie mają powiązań jeden do jednego z prawdziwymi osobami. W przeciwieństwie do tradycyjnego maskowania czy anonimizacji, gdzie nadal istnieje ryzyko ponownej identyfikacji, dane syntetyczne są tworzone całkowicie od podstaw na podstawie wzorców. Dzięki temu idealnie nadają się do trenowania modeli na wrażliwych informacjach, takich jak dane medyczne, finansowe czy behawioralne, bez ujawniania prawdziwych danych osobowych.
Dane syntetyczne pozwalają systematycznie redukować uprzedzenia, umożliwiając twórcom celowe tworzenie zbalansowanych, różnorodnych zbiorów danych, które przeciwdziałają dyskryminującym wzorcom obecnym w rzeczywistości. Przykładowo, można wygenerować obrazy zróżnicowane demograficznie, by AI nie utrwalały stereotypów płciowych lub rasowych. Jest to szczególnie ważne w rekrutacji, udzielaniu kredytów czy wymiarze sprawiedliwości, gdzie uprzedzenia mogą mieć poważne konsekwencje.
Ponieważ do 2030 roku dane syntetyczne staną się dominującym paradygmatem trenowania, marki muszą wiedzieć, jak ich informacje są reprezentowane w systemach AI. Jakość danych syntetycznych wpływa bezpośrednio na cytowania i wzmianki o marce w wynikach AI. Marki powinny monitorować swoją obecność w systemach AI, zabiegać o standardy transparentności wymagające ujawniania użycia danych syntetycznych oraz korzystać z platform takich jak AmICited.com do śledzenia reprezentacji marki i wczesnego wykrywania zniekształceń.
Dowiedz się, jak Twoja marka jest reprezentowana w systemach AI trenowanych na danych syntetycznych. Śledź cytowania, monitoruj dokładność i dbaj o bezpieczeństwo marki w ekosystemie informacji napędzanym przez AI.
Dane treningowe to zbiór danych używany do nauki modeli ML wzorców i zależności. Dowiedz się, jak jakość danych treningowych wpływa na wydajność modeli AI, ich ...

Porównaj optymalizację danych treningowych i strategie pobierania w czasie rzeczywistym dla AI. Dowiedz się, kiedy używać fine-tuningu, a kiedy RAG, jakie są ko...

Dyskusja społecznościowa o wpływaniu na dane treningowe AI dotyczące Twojej marki. Rzetelne spostrzeżenia na temat tego, jak tworzenie treści wpływa na to, czeg...
Zgoda na Pliki Cookie
Używamy plików cookie, aby poprawić jakość przeglądania i analizować nasz ruch. See our privacy policy.