
Date de antrenament
Datele de antrenament sunt setul de date folosit pentru a învăța modelele ML tipare și relații. Află cum calitatea datelor de antrenament influențează performan...
13 min citire

Antrenamentul cu date sintetice este procesul de antrenare a modelelor de inteligență artificială folosind date generate artificial, în locul informațiilor reale create de oameni. Această abordare răspunde deficitului de date, accelerează dezvoltarea modelelor și protejează confidențialitatea, dar introduce și provocări precum colapsul modelului și halucinațiile, care necesită gestionare și validare atentă.
Antrenamentul cu date sintetice este procesul de antrenare a modelelor de inteligență artificială folosind date generate artificial, în locul informațiilor reale create de oameni. Această abordare răspunde deficitului de date, accelerează dezvoltarea modelelor și protejează confidențialitatea, dar introduce și provocări precum colapsul modelului și halucinațiile, care necesită gestionare și validare atentă.
Antrenamentul cu date sintetice se referă la procesul de antrenare a modelelor de inteligență artificială folosind date generate artificial, în locul informațiilor reale create de oameni. Spre deosebire de antrenamentul AI tradițional, care se bazează pe seturi de date autentice colectate din sondaje, observații sau extragere web, datele sintetice sunt create prin algoritmi și metode computaționale care învață modele statistice din date existente sau generează date complet noi de la zero. Această schimbare fundamentală a metodologiei de antrenament abordează o provocare critică în dezvoltarea AI moderne: creșterea exponențială a cerințelor computaționale a depășit capacitatea umanității de a genera suficiente date reale, cercetările indicând că datele de antrenament generate de oameni ar putea fi epuizate în următorii câțiva ani. Antrenamentul cu date sintetice oferă o alternativă scalabilă și rentabilă, care poate fi generată la infinit, fără procesele consumatoare de timp de colectare, etichetare și curățare a datelor, ce ocupă până la 80% din timpul de dezvoltare AI tradițional.
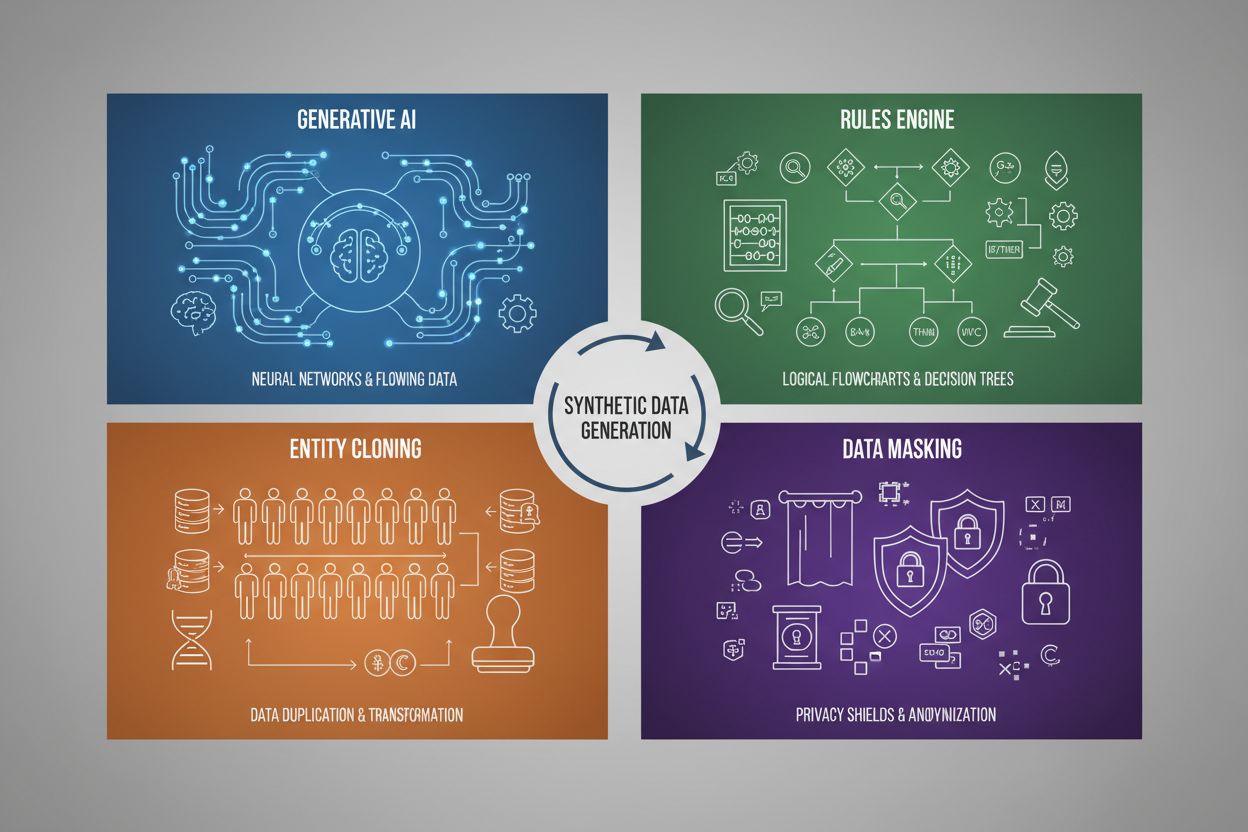
Generarea datelor sintetice utilizează patru tehnici principale, fiecare cu mecanisme și aplicații distincte:
| Tehnică | Cum funcționează | Caz de utilizare |
|---|---|---|
| AI Generativă (GAN-uri, VAE-uri, GPT) | Folosește modele de învățare profundă pentru a învăța modele și distribuții statistice din date reale, apoi generează noi mostre sintetice care mențin aceleași proprietăți și relații statistice. GAN-urile folosesc rețele adversariale unde un generator creează date false, iar un discriminator evaluează autenticitatea, creând rezultate din ce în ce mai realiste. | Antrenarea modelelor lingvistice mari precum ChatGPT, generarea de imagini sintetice cu DALL-E, crearea de seturi diverse de date text pentru sarcini de procesare a limbajului natural |
| Motor de reguli | Aplică reguli logice și constrângeri predefinite pentru a genera date care respectă logica de afaceri, cunoștințele de domeniu sau cerințele de reglementare. Această abordare deterministă asigură că datele generate respectă modele și relații cunoscute fără a necesita învățare automată. | Date tranzacționale financiare, dosare medicale cu cerințe specifice de conformitate, date de senzori industriali cu parametri operaționali cunoscuți |
| Clonarea entităților | Duplică și modifică înregistrări reale existente aplicând transformări, perturbări sau variații pentru a crea noi instanțe, menținând în același timp proprietățile și relațiile statistice de bază. Această tehnică păstrează autenticitatea datelor și extinde dimensiunea setului de date. | Extinderea seturilor de date limitate în industrii reglementate, crearea de date de antrenament pentru diagnosticarea bolilor rare, augmentarea seturilor cu prea puține exemple din clase minoritare |
| Masca și anonimizarea datelor | Ascunde informațiile personale sensibile (PII) menținând structura și relațiile statistice ale datelor prin tehnici precum tokenizarea, criptarea sau înlocuirea valorilor. Astfel apar versiuni sintetice ale datelor reale care protejează confidențialitatea. | Seturi de date medicale și financiare, date despre comportamentul clienților, informații personale sensibile în cercetare |
Antrenamentul cu date sintetice aduce reduceri substanțiale de costuri prin eliminarea proceselor costisitoare de colectare, adnotare și curățare a datelor, care în mod tradițional consumă resurse și timp considerabile. Organizațiile pot genera un număr nelimitat de mostre pentru antrenament la cerere, accelerând dramatic ciclurile de dezvoltare ale modelelor și permițând iterații și experimente rapide fără a aștepta colectarea de date reale. Tehnica oferă capabilități puternice de augmentare a datelor, permițând dezvoltatorilor să extindă seturile de date limitate și să creeze seturi de antrenament echilibrate care să rezolve problemele de dezechilibru între clase—o problemă critică în care anumite categorii sunt subreprezentate în datele reale. Datele sintetice sunt deosebit de valoroase pentru abordarea deficitului de date în domenii specializate precum imagistica medicală, diagnosticarea bolilor rare sau testarea vehiculelor autonome, unde colectarea suficientor exemple reale este prohibitiv de costisitoare sau problematică din punct de vedere etic. Protejarea confidențialității reprezintă un avantaj major, deoarece datele sintetice pot fi generate fără a expune informații personale sensibile, fiind ideale pentru antrenarea modelelor pe dosare medicale, date financiare sau alte informații reglementate. În plus, datele sintetice permit reducerea sistematică a părtinirii, oferind dezvoltatorilor posibilitatea de a crea intenționat seturi de date echilibrate și diverse care să contracareze modelele discriminatorii prezente în datele reale—de exemplu, generarea de reprezentări demografice diverse în imagini de antrenament pentru a preveni perpetuarea stereotipurilor de gen sau rasiale în aplicații de recrutare, creditare sau justiție penală.
În ciuda potențialului său, antrenamentul cu date sintetice introduce provocări tehnice și practice semnificative care pot compromite performanța modelelor dacă nu sunt gestionate cu atenție. Cea mai importantă problemă este colapsul modelului, un fenomen în care modelele AI antrenate extensiv pe date sintetice suferă o degradare severă a calității, acurateței și coerenței rezultatelor. Acest lucru are loc deoarece datele sintetice, deși statistic similare cu datele reale, nu conțin complexitatea subtilă și cazurile limită prezente în informațiile autentice generate de oameni—când modelele sunt antrenate pe conținut generat de AI, ele încep să amplifice erorile și artefactele, creând o problemă cumulativă în care fiecare generație de date sintetice devine din ce în ce mai slabă calitativ.
Principalele provocări includ:
Aceste provocări subliniază de ce datele sintetice nu pot înlocui singure datele reale—ci trebuie integrate cu atenție ca supliment la seturile de date autentice, cu asigurare riguroasă a calității și supraveghere umană pe tot parcursul procesului de antrenament.
Pe măsură ce datele sintetice devin tot mai răspândite în antrenamentul modelelor AI, brandurile se confruntă cu o nouă provocare critică: asigurarea unei reprezentări corecte și favorabile în rezultatele și citările generate de AI. Când modelele lingvistice mari și sistemele AI generative sunt antrenate pe date sintetice, calitatea și caracteristicile acelor date sintetice influențează direct modul în care brandurile sunt descrise, recomandate și citate în rezultatele căutărilor AI, răspunsurile chatbot-urilor și generarea automată de conținut. Aceasta creează o problemă semnificativă de siguranță a brandului, deoarece datele sintetice care conțin informații învechite, părtinire concurențială sau descrieri inexacte ale brandului pot fi încorporate în modelele AI, ducând la denaturări persistente în milioane de interacțiuni cu utilizatorii. Pentru organizațiile care folosesc platforme precum AmICited.com pentru a-și monitoriza prezența brandului în sistemele AI, înțelegerea rolului datelor sintetice în antrenamentul modelelor devine esențială—brandurile au nevoie de vizibilitate asupra faptului dacă citările și menționările AI provin din date reale de antrenament sau din surse sintetice, deoarece acest lucru afectează credibilitatea și acuratețea. Lipsa de transparență privind utilizarea datelor sintetice în antrenamentul AI creează provocări de responsabilitate: companiile nu pot determina cu ușurință dacă informațiile lor despre brand au fost reprezentate corect în seturile sintetice folosite la antrenarea modelelor care influențează percepția consumatorilor. Brandurile vizionare ar trebui să acorde prioritate monitorizării AI și urmăririi citărilor pentru a detecta devreme denaturările, să susțină standarde de transparență care să impună dezvăluirea utilizării datelor sintetice în antrenamentul AI și să colaboreze cu platforme care oferă perspective asupra modului în care brandul lor apare în sisteme AI antrenate cu date reale și sintetice. Pe măsură ce datele sintetice devin paradigma dominantă de antrenament până în 2030, monitorizarea brandului va migra de la urmărirea media tradițională la inteligență completă a citărilor AI, făcând indispensabile platformele care urmăresc reprezentarea brandului în sistemele AI generative pentru protejarea integrității și asigurarea coerenței vocii brandului în ecosistemul informațional condus de AI.
Antrenamentul AI tradițional se bazează pe date reale colectate de la oameni prin sondaje, observații sau extragere web, ceea ce este consumator de timp și din ce în ce mai rar. Antrenamentul cu date sintetice folosește date generate artificial create de algoritmi care învață modele statistice din date existente sau generează date complet noi de la zero. Datele sintetice pot fi produse infinit la cerere, reducând dramatic timpul și costurile de dezvoltare și abordând preocupările legate de confidențialitate.
Cele patru tehnici principale sunt: 1) AI generativă (folosind GAN-uri, VAE-uri sau modele GPT pentru a învăța și a replica modele de date), 2) Motor de reguli (aplicarea logicii de afaceri și a constrângerilor predefinite), 3) Clonarea entităților (duplicarea și modificarea înregistrărilor existente păstrând proprietățile statistice), și 4) Masca de date (anonimizarea informațiilor sensibile păstrând structura datelor). Fiecare tehnică deservește cazuri de utilizare diferite și are avantaje distincte.
Colapsul modelului apare atunci când modelele AI antrenate extensiv pe date sintetice experimentează o degradare severă a calității și acurateței rezultatelor. Acest lucru se întâmplă deoarece datele sintetice, deși statistic similare cu datele reale, nu au complexitatea subtilă și cazurile limită ale informațiilor autentice. Când modelele sunt antrenate pe conținut generat de AI, ele amplifică erorile și artefactele, creând o problemă cumulativă în care fiecare generație devine din ce în ce mai slabă calitativ, ajungând în final la rezultate inutilizabile.
Când modelele AI sunt antrenate pe date sintetice, calitatea și caracteristicile acelor date sintetice influențează direct modul în care brandurile sunt descrise, recomandate și citate în rezultatele AI. Datele sintetice de calitate slabă, care conțin informații învechite sau părtinire în favoarea concurenței, pot fi încorporate în modelele AI, ducând la o reprezentare incorectă și persistentă a brandului în milioane de interacțiuni. Aceasta creează o problemă de siguranță a brandului ce necesită monitorizare și transparență privind utilizarea datelor sintetice în antrenamentul AI.
Nu, datele sintetice ar trebui să completeze, nu să înlocuiască, datele reale. Deși datele sintetice oferă avantaje semnificative în cost, viteză și confidențialitate, ele nu pot replica complet complexitatea, diversitatea și cazurile limită ale datelor autentice generate de oameni. Cea mai eficientă abordare combină date sintetice și reale, cu asigurare riguroasă a calității și supraveghere umană pentru a garanta acuratețea și fiabilitatea modelului.
Datele sintetice oferă o protecție superioară a confidențialității deoarece nu conțin valori reale din seturile de date originale și nu au relații unu-la-unu cu persoane reale. Spre deosebire de tehnicile tradiționale de mască sau anonimizare care pot prezenta riscuri de reidentificare, datele sintetice sunt create complet de la zero pe baza unor modele învățate. Astfel, sunt ideale pentru antrenarea modelelor pe informații sensibile precum dosare medicale, date financiare sau informații comportamentale personale fără a expune datele reale ale indivizilor.
Datele sintetice permit reducerea sistematică a părtinirii, oferind dezvoltatorilor posibilitatea de a crea intenționat seturi de date echilibrate și diverse care să contracareze modelele discriminatorii din datele reale. De exemplu, dezvoltatorii pot genera reprezentări demografice diverse în imagini de antrenament pentru a preveni perpetuarea stereotipurilor de gen sau rasiale de către modelele AI. Această capacitate este deosebit de valoroasă în aplicații precum recrutarea, creditarea și justiția penală, unde părtinirea poate avea consecințe serioase.
Pe măsură ce datele sintetice devin paradigma dominantă de antrenament până în 2030, brandurile trebuie să înțeleagă cum sunt reprezentate informațiile lor în sistemele AI. Calitatea datelor sintetice afectează direct citările și menționările brandului în rezultatele AI. Brandurile ar trebui să-și monitorizeze prezența în sistemele AI, să susțină standarde de transparență care impun divulgarea utilizării datelor sintetice și să utilizeze platforme precum AmICited.com pentru a urmări reprezentarea brandului și a detecta devreme denaturările.
Descoperă cum este reprezentat brandul tău în sistemele AI antrenate cu date sintetice. Urmărește citările, monitorizează acuratețea și asigură siguranța brandului în ecosistemul informațional condus de AI.
Datele de antrenament sunt setul de date folosit pentru a învăța modelele ML tipare și relații. Află cum calitatea datelor de antrenament influențează performan...

Ghid complet pentru retragerea din colectarea datelor de antrenare AI pe ChatGPT, Perplexity, LinkedIn și alte platforme. Află instrucțiuni pas cu pas pentru a-...
Află cum să-ți optimizezi conținutul pentru includerea în datele de antrenament AI. Descoperă cele mai bune practici pentru ca website-ul tău să fie descoperit ...
Consimțământ Cookie
Folosim cookie-uri pentru a vă îmbunătăți experiența de navigare și a analiza traficul nostru. See our privacy policy.