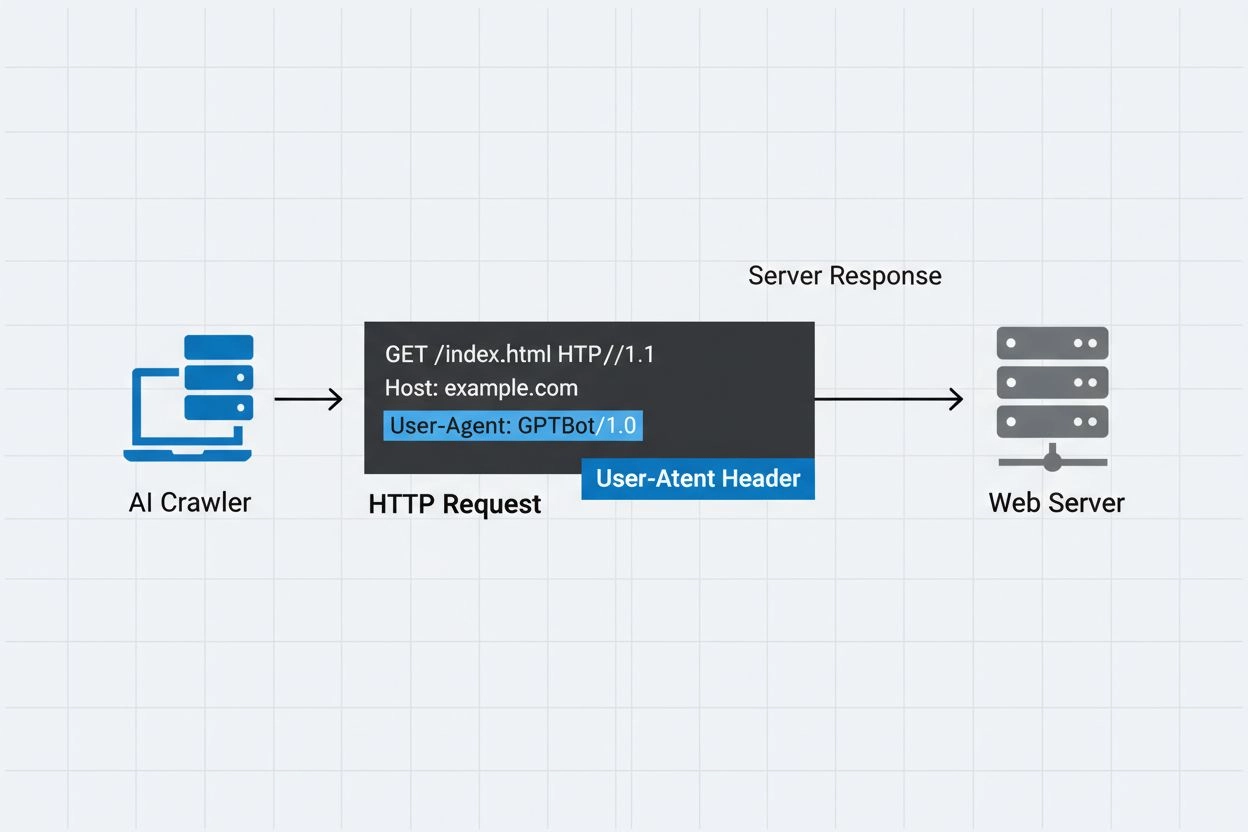
Identifikačný reťazec, ktorý AI crawleri posielajú webovým serverom v HTTP hlavičkách, používaný na riadenie prístupu, sledovanie analytiky a rozlišovanie medzi legitímnymi AI botmi a škodlivými scrapermi. Označuje účel, verziu a pôvod crawlera.
AI Crawler User-Agent
Identifikačný reťazec, ktorý AI crawleri posielajú webovým serverom v HTTP hlavičkách, používaný na riadenie prístupu, sledovanie analytiky a rozlišovanie medzi legitímnymi AI botmi a škodlivými scrapermi. Označuje účel, verziu a pôvod crawlera.
Definícia AI Crawler User-Agent
AI crawler user-agent je HTTP hlavičkový reťazec, ktorý identifikuje automatizované boty pristupujúce k webovému obsahu na účely trénovania umelej inteligencie, indexovania alebo výskumu. Tento reťazec slúži ako digitálna identita crawlera a komunikuje webovým serverom, kto žiada o prístup a aké sú jeho úmysly. User-agent je pre AI crawlerov kľúčový, pretože umožňuje majiteľom webstránok rozpoznať, sledovať a kontrolovať, ako ich obsah využívajú rôzne AI systémy. Bez správneho user-agent identifikátora je rozlíšenie medzi legitímnymi AI crawlermi a škodlivými botmi výrazne náročnejšie, preto je tento prvok základom zodpovedného web scrapingu a zberu dát.
HTTP komunikácia a User-Agent hlavičky
User-agent hlavička je kľúčovou súčasťou HTTP požiadaviek, objavuje sa v request hlavičkách, ktoré každý prehliadač aj bot posiela pri prístupe k webovému zdroju. Keď crawler odošle požiadavku webovému serveru, v HTTP hlavičkách zahrnie metadáta o sebe, pričom user-agent reťazec je jedným z najdôležitejších identifikátorov. Tento reťazec typicky obsahuje informácie o názve crawlera, verzii, organizácii, ktorá ho prevádzkuje, a často aj kontaktnú URL alebo email na overenie. User-agent umožňuje serverom identifikovať žiadajúceho klienta a rozhodnúť, či obsah poskytnúť, obmedziť počet požiadaviek alebo prístup úplne zablokovať. Nižšie sú príklady user-agent reťazcov hlavných AI crawlerov:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36; compatible; OAI-SearchBot/1.3; +https://openai.com/searchbot
Názov crawlera
Účel
Príklad User-Agent
IP verifikácia
GPTBot
Zber tréningových dát
Mozilla/5.0…compatible; GPTBot/1.3
OpenAI IP rozsahy
ClaudeBot
Tréning modelu
Mozilla/5.0…compatible; ClaudeBot/1.0
Anthropic IP rozsahy
OAI-SearchBot
Indexovanie vyhľadávania
Mozilla/5.0…compatible; OAI-SearchBot/1.3
OpenAI IP rozsahy
PerplexityBot
Indexovanie vyhľadávania
Mozilla/5.0…compatible; PerplexityBot/1.0
Perplexity IP rozsahy
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Viaceré významné AI spoločnosti prevádzkujú vlastné crawlery s odlišnými user-agent identifikátormi a účelmi. Tieto crawlery predstavujú rôzne použitia v rámci AI ekosystému:
GPTBot (OpenAI): Zbiera tréningové dáta pre ChatGPT a ďalšie modely OpenAI, rešpektuje direktívy robots.txt
ClaudeBot (Anthropic): Získava obsah na trénovanie modelov Claude, možno ho blokovať cez robots.txt
OAI-SearchBot (OpenAI): Indexuje webový obsah špeciálne pre vyhľadávacie funkcie a AI-poháňané vyhľadávanie
PerplexityBot (Perplexity AI): Prechádza web za účelom poskytovania vyhľadávacích výsledkov a výskumných možností na svojej platforme
Gemini-Deep-Research (Google): Vykonáva hĺbkové výskumné úlohy pre AI model Gemini od Google
Meta-ExternalAgent (Meta): Zbiera dáta pre AI tréning a výskum spoločnosti Meta
Bingbot (Microsoft): Slúži na tradičné indexovanie vyhľadávania aj generovanie AI odpovedí
Každý crawler má špecifické IP rozsahy a oficiálnu dokumentáciu, ktorú môžu majitelia webstránok využiť na overenie legitímnosti a nastavenie správnych prístupových pravidiel.
User-Agent spoofing a výzvy pri overovaní
User-agent reťazce môže ľubovoľný klient pri HTTP požiadavke jednoducho sfalšovať, preto samotné použitie user-agentu ako autentifikačného mechanizmu na identifikáciu legitímnych AI crawlerov nestačí. Škodlivé boty často predstierajú populárne user-agent reťazce, aby zakryli svoju pravú identitu a obišli bezpečnostné opatrenia webstránok alebo obmedzenia robots.txt. Na riešenie tejto zraniteľnosti odborníci odporúčajú používať IP verifikáciu ako ďalšiu vrstvu overenia, teda kontrolovať, či požiadavky prichádzajú z oficiálnych IP rozsahov zverejnených AI spoločnosťami. Nový štandard RFC 9421 HTTP Message Signatures umožňuje kryptografické overenie, vďaka čomu môžu crawlery svoje požiadavky digitálne podpisovať a servery následne overiť ich autentickosť. Napriek tomu je rozlíšenie medzi skutočnými a falošnými crawlermi náročné, pretože odhodlaní útočníci môžu sfalšovať nielen user-agent reťazce, ale aj IP adresy prostredníctvom proxy alebo kompromitovanej infraštruktúry. Táto neustála hra na mačku a myš medzi operátormi crawlerov a bezpečnostne uvedomelými majiteľmi stránok sa vyvíja spolu s novými overovacími technikami.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Použitie robots.txt s User-Agent direktívami
Majitelia webstránok môžu riadiť prístup crawlerov zadaním user-agent direktív v súbore robots.txt, čím získajú detailnú kontrolu nad tým, ktoré crawlery môžu pristupovať k rôznym častiam ich webu. Súbor robots.txt využíva user-agent identifikátory na cielenie konkrétnych crawlerov špecifickými pravidlami, čo umožňuje povoliť niektoré crawlery a iné zablokovať. Príklad konfigurácie robots.txt:
Robots.txt síce poskytuje pohodlný mechanizmus na riadenie crawlerov, má však dôležité obmedzenia:
Robots.txt je len odporúčací a nie vynútiteľný; crawlery ho môžu ignorovať
Sfalšované user-agenty môžu úplne obísť obmedzenia robots.txt
Server-side verifikácia pomocou IP allowlistingu poskytuje silnejšiu ochranu
Pravidlá Web Application Firewallu (WAF) môžu blokovať požiadavky z neautorizovaných IP rozsahov
Kombinácia robots.txt s IP overovaním vytvára robustnejšiu stratégiu riadenia prístupu
Analýza aktivity crawlerov cez serverové logy
Majitelia webstránok môžu využiť serverové logy na sledovanie a analýzu aktivity AI crawlerov, čím získajú prehľad o tom, ktoré AI systémy pristupujú k ich obsahu a ako často. Preskúmaním HTTP logov a filtrovaním podľa známych user-agent reťazcov AI crawlerov môžu správcovia stránok pochopiť vplyv na šírku pásma a vzorce zberu dát zo strany rôznych AI spoločností. Nástroje ako platformy na analýzu logov, webová analytika či vlastné skripty dokážu spracovať serverové logy s cieľom identifikovať crawlerovú prevádzku, merať frekvenciu požiadaviek a počítať objemy prenesených dát. Táto transparentnosť je zvlášť dôležitá pre tvorcov obsahu a vydavateľov, ktorí chcú pochopiť, ako sa ich práca využíva na AI trénovanie a či by mali implementovať prístupové obmedzenia. Služby ako AmICited.com zohrávajú v tomto ekosystéme kľúčovú úlohu monitorovaním a sledovaním, ako AI systémy citujú a odkazujú obsah z celého webu, čím poskytujú tvorcom prehľad o využití ich obsahu pri trénovaní AI systémov. Pochopenie aktivity crawlerov pomáha majiteľom stránok robiť informované rozhodnutia o obsahu a vyjednávať s AI spoločnosťami o právach na využívanie dát.
Najlepšie postupy pre správu prístupu AI crawlerov
Efektívne riadenie prístupu AI crawlerov si vyžaduje viacvrstvový prístup kombinujúci niekoľko overovacích a monitorovacích techník:
Kombinujte kontrolu user-agentov s IP overovaním – Nikdy sa nespoliehajte len na user-agent reťazce; vždy ich porovnávajte s oficiálnymi IP rozsahmi zverejnenými AI spoločnosťami
Udržiavajte aktuálne IP allowlisty – Pravidelne kontrolujte a aktualizujte firewall pravidlá s najnovšími IP rozsahmi od OpenAI, Anthropic, Google a ďalších AI poskytovateľov
Zavádzajte pravidelnú analýzu logov – Naplánujte si pravidelné prehliadky serverových logov na identifikáciu podozrivej aktivity crawlerov a pokusov o neoprávnený prístup
Rozlišujte medzi typmi crawlerov – Oddeľujte tréningové crawlery (GPTBot, ClaudeBot) od vyhľadávacích crawlerov (OAI-SearchBot, PerplexityBot) a aplikujte vhodné politiky
Zvážte etické dôsledky – Nájdite rovnováhu medzi obmedzením prístupu a uvedomením si, že AI tréning profituje z rôznych a kvalitných zdrojov obsahu
Využívajte monitorovacie služby – Využite platformy ako AmICited.com na sledovanie, ako AI systémy využívajú a citujú váš obsah, zabezpečte si správne pripisovanie a pochopte vplyv vášho obsahu
Dodržiavaním týchto postupov môžu majitelia stránok udržať kontrolu nad svojím obsahom a zároveň podporovať zodpovedný rozvoj AI systémov.
Najčastejšie kladené otázky
Čo je user-agent reťazec?
User-agent je HTTP hlavičkový reťazec, ktorý identifikuje klienta vykonávajúceho webovú požiadavku. Obsahuje informácie o softvéri, operačnom systéme a verzii žiadajúcej aplikácie, či už ide o prehliadač, crawler alebo bot. Tento reťazec umožňuje webovým serverom identifikovať a sledovať rôzne typy klientov pristupujúcich k ich obsahu.
Prečo AI crawleri potrebujú user-agent reťazce?
User-agent reťazce umožňujú webovým serverom identifikovať, ktorý crawler pristupuje k ich obsahu, čo umožňuje majiteľom stránok riadiť prístup, sledovať aktivitu crawlerov a rozlišovať medzi rôznymi typmi botov. Je to nevyhnutné pre správu šírky pásma, ochranu obsahu a pochopenie toho, ako AI systémy využívajú vaše dáta.
Dajú sa user-agent reťazce sfalšovať?
Áno, user-agent reťazce sa dajú ľahko sfalšovať, pretože sú to len textové hodnoty v HTTP hlavičkách. Preto je dôležitá IP verifikácia a HTTP Message Signatures ako ďalšie metódy overenia na potvrdenie skutočnej identity crawlera a zabránenie škodlivým botom predstierať legitímnych crawlerov.
Ako môžem zablokovať konkrétnych AI crawlerov?
Môžete použiť robots.txt s user-agent direktívami na vyžiadanie, aby crawleri nepristupovali na vašu stránku, no toto nie je vynútiteľné. Pre silnejšiu kontrolu použite serverové overenie, IP allowlisting/blocklisting alebo WAF pravidlá, ktoré súčasne kontrolujú user-agent aj IP adresu.
Aký je rozdiel medzi GPTBot a OAI-SearchBot?
GPTBot je crawler spoločnosti OpenAI na zber tréningových dát pre AI modelyako ChatGPT, zatiaľ čo OAI-SearchBot je určený na indexovanie vyhľadávania a poháňanie vyhľadávacích funkcií v ChatGPT. Majú rôzne účely, rýchlosti crawlovania a IP rozsahy, čo si vyžaduje rozdielne stratégie riadenia prístupu.
Ako môžem overiť, či je crawler legitímny?
Skontrolujte IP adresu crawlera podľa oficiálneho IP zoznamu zverejneného prevádzkovateľom crawlera (napr. openai.com/gptbot.json pre GPTBot). Legitímni crawleri zverejňujú svoje IP rozsahy a môžete overiť, že požiadavky pochádzajú z týchto rozsahov pomocou firewall pravidiel alebo WAF konfigurácie.
Čo je overenie HTTP Message Signature?
HTTP Message Signatures (RFC 9421) je kryptografická metóda, pri ktorej crawleri podpisujú svoje požiadavky súkromným kľúčom. Servery môžu overiť podpis pomocou verejného kľúča crawlera z ich .well-known adresára, čím sa preukáže, že požiadavka je autentická a nebola pozmenená.
Ako AmICited.com pomáha s monitorovaním AI crawlerov?
AmICited.com sleduje, ako AI systémy odkazujú a citujú vašu značku v GPT, Perplexity, Google AI Overviews a ďalších AI platformách. Sleduje aktivitu crawlerov a AI zmienky, čo vám pomáha pochopiť vašu viditeľnosť v AI-generovaných odpovediach a ako je váš obsah využívaný.
Sledujte svoju značku v AI systémoch
Sledujte, ako AI crawleri odkazujú a citujú váš obsah v ChatGPT, Perplexity, Google AI Overviews a ďalších AI platformách pomocou AmICited.
Ktorým AI crawlerom by ste mali povoliť prístup? Kompletný sprievodca pre rok 2025
Zistite, ktorým AI crawlerom povoliť alebo zablokovať prístup vo vašom robots.txt. Komplexný sprievodca pokrývajúci GPTBot, ClaudeBot, PerplexityBot a ďalších 2...
Ako identifikovať AI crawlerov v serverových logoch: Kompletný sprievodca detekciou
Zistite, ako identifikovať a monitorovať AI crawlery ako GPTBot, PerplexityBot a ClaudeBot vo vašich serverových logoch. Objavte user-agent reťazce, metódy over...
Zistite, ako spravovať prístup AI crawlerov k obsahu vašej webovej stránky. Pochopte rozdiel medzi trénovacími a vyhľadávacími crawlermi, implementujte pravidlá...
6 min čítania
Súhlas s cookies Používame cookies na vylepšenie vášho prehliadania a analýzu našej návštevnosti. See our privacy policy.