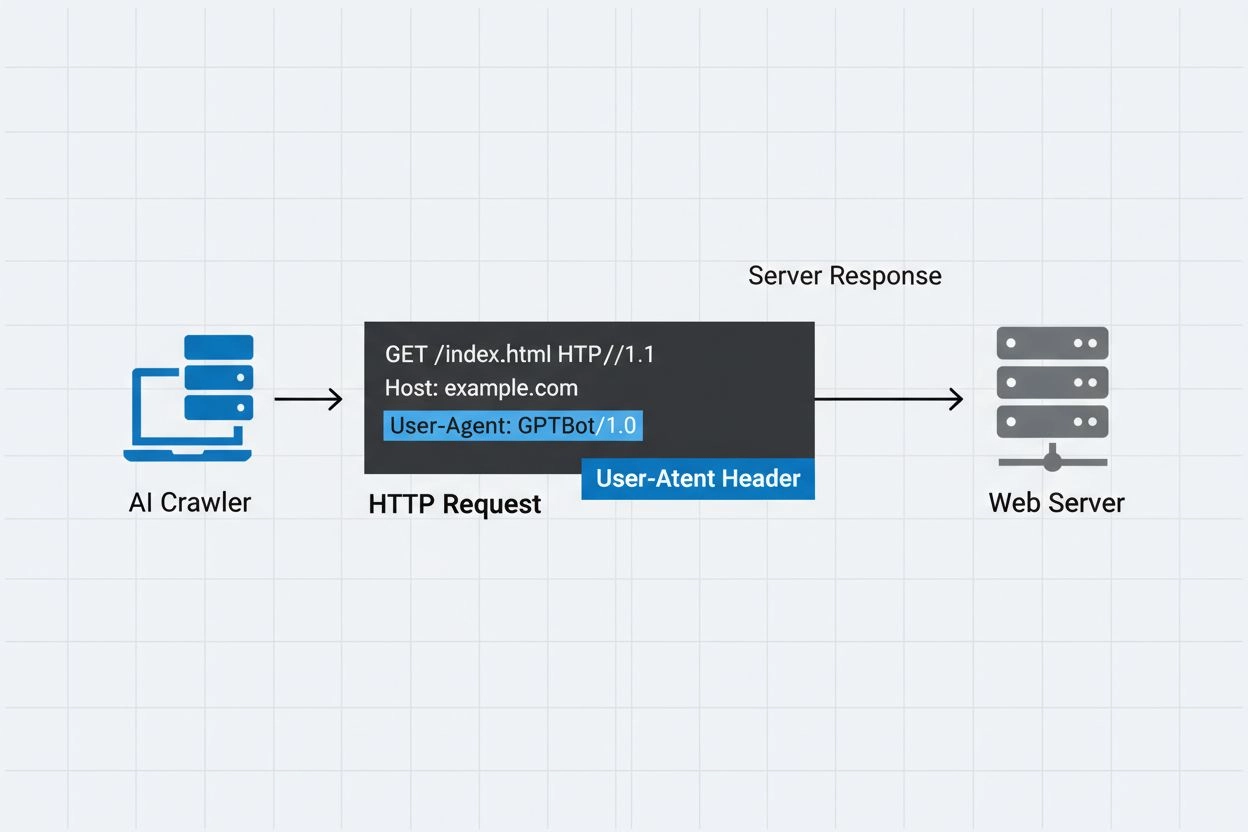
Den identifieringssträng som AI-crawlers skickar till webbservrar i HTTP-rubriker, används för åtkomstkontroll, analys och för att särskilja legitima AI-botar från skadliga skrapare. Den identifierar crawlerns syfte, version och ursprung.
AI Crawler User-Agent
Den identifieringssträng som AI-crawlers skickar till webbservrar i HTTP-rubriker, används för åtkomstkontroll, analys och för att särskilja legitima AI-botar från skadliga skrapare. Den identifierar crawlerns syfte, version och ursprung.
Definition av AI Crawler User-Agent
En AI crawler user-agent är en HTTP-headersträng som identifierar automatiserade botar som får åtkomst till webbinnehåll för artificiell intelligens-träning, indexering eller forskningsändamål. Denna sträng fungerar som crawlerns digitala identitet och kommunicerar till webbservrar vem som gör förfrågan och vad deras avsikter är. User-agenten är avgörande för AI-crawlers eftersom den låter webbplatsägare känna igen, spåra och kontrollera hur deras innehåll får åtkomst av olika AI-system. Utan korrekt user-agent-identifiering blir det betydligt svårare att särskilja mellan legitima AI-crawlers och skadliga botar, vilket gör den till en viktig komponent för ansvarsfull webbskrapning och datainsamling.
HTTP-kommunikation och User-Agent-rubriker
User-agent-rubriken är en kritisk del av HTTP-förfrågningar och förekommer i de förfrågningsrubriker som varje webbläsare och bot skickar när de får åtkomst till en webbresurs. När en crawler gör en förfrågan till en webbserver inkluderar den metadata om sig själv i HTTP-rubrikerna, där user-agent-strängen är en av de viktigaste identifierarna. Denna sträng innehåller vanligtvis information om crawlerns namn, version, organisationen som driver den och ofta en kontakt-URL eller e-post för verifieringsändamål. User-agenten gör det möjligt för servrar att identifiera den begärande klienten och fatta beslut om att leverera innehåll, begränsa förfrågningar eller helt blockera åtkomst. Nedan följer exempel på user-agent-strängar från stora AI-crawlers:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36; compatible; OAI-SearchBot/1.3; +https://openai.com/searchbot
Flera framstående AI-företag driver sina egna crawlers med särskilda user-agent-identifierare och syften. Dessa crawlers representerar olika användningsfall inom AI-ekosystemet:
GPTBot (OpenAI): Samlar in träningsdata för ChatGPT och andra OpenAI-modeller, respekterar robots.txt-direktiv
ClaudeBot (Anthropic): Samlar in innehåll för att träna Claude-modeller, kan blockeras via robots.txt
OAI-SearchBot (OpenAI): Indexerar webbinnehåll specifikt för sökfunktionalitet och AI-drivna sökfunktioner
PerplexityBot (Perplexity AI): Crawlar webben för att tillhandahålla sökresultat och forskningsmöjligheter i deras plattform
Gemini-Deep-Research (Google): Utför djupa forskningsuppgifter för Googles Gemini AI-modell
Meta-ExternalAgent (Meta): Samlar in data för Metas AI-träning och forskningsinitiativ
Bingbot (Microsoft): Tjänar dubbla syften för traditionell sökindexering och AI-generering av svar
Varje crawler har specifika IP-områden och officiell dokumentation som webbplatsägare kan hänvisa till för att verifiera legitimitet och införa lämpliga åtkomstkontroller.
User-Agent-spoofing och verifieringsutmaningar
User-agent-strängar kan enkelt förfalskas av vilken klient som helst som gör en HTTP-förfrågan, vilket gör dem otillräckliga som ensam autentiseringsmekanism för att identifiera legitima AI-crawlers. Skadliga botar förfalskar ofta populära user-agent-strängar för att dölja sin verkliga identitet och kringgå webbplatssäkerhet eller robots.txt-begränsningar. För att hantera denna sårbarhet rekommenderar säkerhetsexperter att använda IP-verifiering som ytterligare autentiseringslager och kontrollera att förfrågningar kommer från de officiella IP-områden som publiceras av AI-företag. Den framväxande standarden RFC 9421 HTTP Message Signatures möjliggör kryptografisk verifiering, vilket gör det möjligt för crawlers att digitalt signera sina förfrågningar så att servrar kan verifiera äkthet. Dock kvarstår utmaningen att särskilja riktiga och falska crawlers eftersom beslutsamma angripare kan förfalska både user-agent-sträng och IP-adress via proxies eller komprometterad infrastruktur. Denna katt-och-råtta-lek mellan crawler-operatörer och säkerhetsmedvetna webbplatsägare fortsätter att utvecklas i takt med att nya verifieringstekniker tas fram.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Använda robots.txt med User-Agent-direktiv
Webbplatsägare kan styra crawler-åtkomst genom att ange user-agent-direktiv i deras robots.txt-fil, vilket möjliggör detaljerad kontroll över vilka crawlers som får åtkomst till vilka delar av deras webbplats. Robots.txt-filen använder user-agent-identifierare för att rikta in sig på specifika crawlers med anpassade regler, så att webbplatsägare kan tillåta vissa crawlers samtidigt som de blockerar andra. Här är ett exempel på robots.txt-konfiguration:
Även om robots.txt erbjuder en bekväm mekanism för crawler-kontroll, finns det viktiga begränsningar:
Robots.txt är endast rådgivande och inte tvingande; crawlers kan ignorera den
Förfalskade user-agents kan helt kringgå robots.txt-begränsningar
Serverbaserad verifiering genom IP-vitlistning ger starkare skydd
Web Application Firewall (WAF)-regler kan blockera förfrågningar från obehöriga IP-områden
Kombination av robots.txt och IP-verifiering skapar en mer robust åtkomstkontrollstrategi
Analysera crawler-aktivitet via serverloggar
Webbplatsägare kan använda serverloggar för att spåra och analysera AI-crawler-aktivitet och få insyn i vilka AI-system som besöker deras innehåll och hur ofta. Genom att granska HTTP-requestloggar och filtrera på kända AI-crawler-user-agents kan administratörer förstå bandbreddspåverkan och insamlingsmönster från olika AI-företag. Verktyg som logganalysplattformar, webbanalystjänster och egna skript kan parsa serverloggar för att identifiera crawlertrafik, mäta förfrågningsfrekvens och beräkna datavolymer. Denna insyn är särskilt viktig för innehållsskapare och publicister som vill förstå hur deras verk används för AI-träning och om de bör införa åtkomstbegränsningar. Tjänster som AmICited.com spelar en avgörande roll i detta ekosystem genom att övervaka och spåra hur AI-system citerar och refererar innehåll från webben, vilket ger skapare transparens kring deras innehålls användning i AI-träning. Att förstå crawler-aktivitet hjälper webbplatsägare att fatta välgrundade beslut om innehållspolicys och förhandla med AI-företag om rättigheter till dataanvändning.
Bästa praxis för hantering av AI-crawler-åtkomst
Effektiv hantering av AI-crawler-åtkomst kräver ett flerskiktat tillvägagångssätt som kombinerar flera verifierings- och övervakningstekniker:
Kombinera kontroll av user-agent och IP-verifiering – Lita aldrig enbart på user-agent-strängar; kontrollera alltid mot officiella IP-områden som publiceras av AI-företag
Underhåll uppdaterade IP-vitlistor – Se regelbundet över och uppdatera dina brandväggsregler med de senaste IP-områdena från OpenAI, Anthropic, Google och andra AI-leverantörer
Genomför regelbunden logganalys – Schemalägg periodiska granskningar av serverloggar för att identifiera misstänkt crawler-aktivitet och otillåtna åtkomstförsök
Särskilj olika typer av crawlers – Skilj på tränings-crawlers (GPTBot, ClaudeBot) och sök-crawlers (OAI-SearchBot, PerplexityBot) för att tillämpa lämpliga policyer
Tänk på etiska aspekter – Balansera åtkomstbegränsningar med det faktum att AI-träning gynnas av mångsidiga och högkvalitativa innehållskällor
Använd övervakningstjänster – Utnyttja plattformar som AmICited.com för att följa hur ditt innehåll används och citeras av AI-system, säkerställ korrekt attribuering och förstå ditt innehålls påverkan
Genom att följa dessa riktlinjer kan webbplatsägare behålla kontrollen över sitt innehåll samtidigt som de stödjer en ansvarsfull utveckling av AI-system.
Vanliga frågor
Vad är en user-agent-sträng?
En user-agent är en HTTP-headersträng som identifierar klienten som gör en webbrequest. Den innehåller information om programvaran, operativsystemet och versionen av den begärande applikationen, oavsett om det är en webbläsare, crawler eller bot. Denna sträng gör det möjligt för webbservrar att identifiera och spåra olika typer av klienter som får åtkomst till deras innehåll.
Varför behöver AI-crawlers user-agent-strängar?
User-agent-strängar gör det möjligt för webbservrar att identifiera vilken crawler som får åtkomst till deras innehåll, så att webbplatsägare kan kontrollera åtkomst, spåra crawler-aktivitet och särskilja mellan olika typer av botar. Detta är avgörande för att hantera bandbredd, skydda innehåll och förstå hur AI-system använder dina data.
Kan user-agent-strängar förfalskas?
Ja, user-agent-strängar kan enkelt förfalskas eftersom de bara är textvärden i HTTP-headers. Därför är IP-verifiering och HTTP Message Signatures viktiga ytterligare verifieringsmetoder för att bekräfta en crawlers verkliga identitet och förhindra att skadliga botar utger sig för att vara legitima crawlers.
Hur blockerar jag specifika AI-crawlers?
Du kan använda robots.txt med user-agent-direktiv för att be crawlers att inte besöka din webbplats, men detta är inte tvingande. För starkare kontroll, använd serverbaserad verifiering, IP-vitlistning/svartlistning eller WAF-regler som kontrollerar både user-agent och IP-adress samtidigt.
Vad är skillnaden mellan GPTBot och OAI-SearchBot?
GPTBot är OpenAI:s crawler för att samla in träningsdata till AI-modeller som ChatGPT, medan OAI-SearchBot är utformad för sökindexering och för att driva sökfunktioner i ChatGPT. De har olika syften, crawl-hastigheter och IP-områden, vilket kräver olika åtkomstkontrollstrategier.
Hur kan jag verifiera om en crawler är legitim?
Kontrollera crawlerns IP-adress mot den officiella IP-listan som publiceras av crawler-operatören (t.ex. openai.com/gptbot.json för GPTBot). Legitim crawlers publicerar sina IP-områden och du kan verifiera att förfrågningar kommer från dessa områden med hjälp av brandväggsregler eller WAF-konfigurationer.
Vad är HTTP Message Signature-verifiering?
HTTP Message Signatures (RFC 9421) är en kryptografisk metod där crawlers signerar sina förfrågningar med en privat nyckel. Servrar kan verifiera signaturen med crawlerns publika nyckel från deras .well-known-mapp, vilket bevisar att förfrågan är autentisk och inte manipulerad.
Hur hjälper AmICited.com till med övervakning av AI-crawlers?
AmICited.com övervakar hur AI-system refererar och citerar ditt varumärke i GPTs, Perplexity, Google AI Overviews och andra AI-plattformar. Den spårar crawler-aktivitet och AI-omnämnanden, vilket hjälper dig att förstå din synlighet i AI-genererade svar och hur ditt innehåll används.
Övervaka ditt varumärke i AI-system
Följ hur AI-crawlers refererar och citerar ditt innehåll i ChatGPT, Perplexity, Google AI Overviews och andra AI-plattformar med AmICited.
Hur du Identifierar AI-crawlers i Serverloggar: Komplett Guide för Upptäckt
Lär dig identifiera och övervaka AI-crawlers som GPTBot, PerplexityBot och ClaudeBot i dina serverloggar. Upptäck user-agent-strängar, IP-verifieringsmetoder oc...
AI-crawlers förklarade: GPTBot, ClaudeBot och fler
Förstå hur AI-crawlers som GPTBot och ClaudeBot fungerar, deras skillnader från traditionella sökmotor-crawlers och hur du optimerar din webbplats för synlighet...
Hur du Tillåter AI-botar att Crawla din Webbplats: Komplett robots.txt & llms.txt-guide
Lär dig hur du tillåter AI-botar som GPTBot, PerplexityBot och ClaudeBot att crawla din webbplats. Konfigurera robots.txt, ställ in llms.txt och optimera för AI...
13 min läsning
Cookie-samtycke Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.