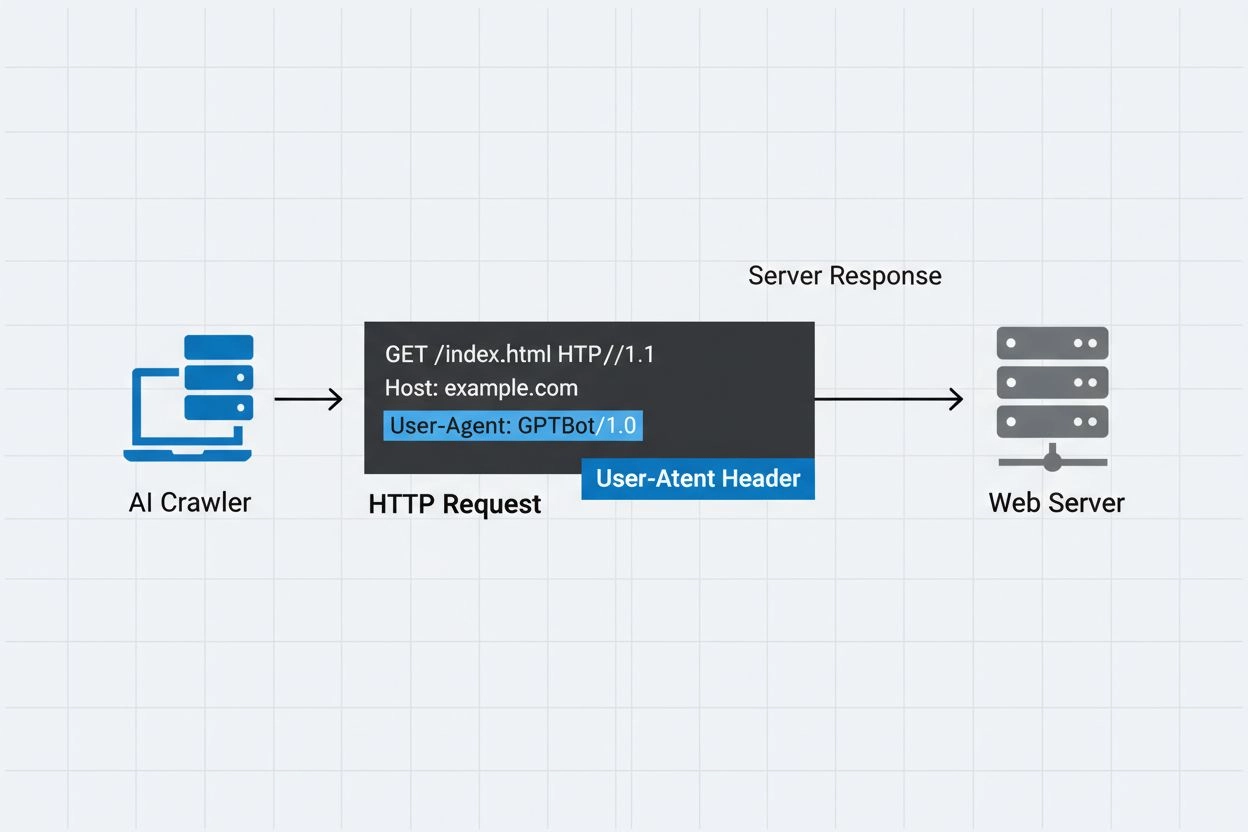
Identifikační řetězec, který AI crawlery posílají webovým serverům v HTTP hlavičkách, sloužící ke kontrole přístupu, sledování analytiky a rozlišení legitimních AI botů od škodlivých scraperů. Určuje účel, verzi a původ crawleru.
AI Crawler User-Agent
Identifikační řetězec, který AI crawlery posílají webovým serverům v HTTP hlavičkách, sloužící ke kontrole přístupu, sledování analytiky a rozlišení legitimních AI botů od škodlivých scraperů. Určuje účel, verzi a původ crawleru.
Definice AI Crawler User-Agent
AI crawler user-agent je řetězec v HTTP hlavičce, který identifikuje automatizované boty přistupující k webovému obsahu za účelem trénování umělé inteligence, indexace nebo výzkumu. Tento řetězec slouží jako digitální identita crawleru a sděluje webovým serverům, kdo provádí požadavek a jaký je jeho záměr. User-agent je pro AI crawlery zásadní, protože umožňuje vlastníkům webu rozpoznat, sledovat a řídit, jakým způsobem je jejich obsah přístupný různými AI systémy. Bez správné identifikace user-agenta je rozlišení mezi legitimními AI crawlery a škodlivými boty výrazně obtížnější, což z něj činí klíčovou součást odpovědného web scrapingu a sběru dat.
HTTP komunikace a User-Agent hlavičky
Hlavička user-agent je zásadní součástí HTTP požadavků a objevuje se v hlavičkách, které každý prohlížeč i bot posílají při přístupu k webovému zdroji. Když crawler odešle požadavek na webový server, zahrne o sobě metadata v HTTP hlavičkách, přičemž user-agent je jedním z nejdůležitějších identifikátorů. Tento řetězec obvykle obsahuje informace o názvu crawleru, jeho verzi, organizaci, která jej provozuje, a často také kontaktní URL nebo e-mail pro účely ověření. User-agent umožňuje serverům identifikovat žádajícího klienta a rozhodovat, zda obsah poskytnou, omezí frekvenci požadavků nebo zcela zablokují přístup. Níže jsou uvedeny příklady user-agent stringů od hlavních AI crawlerů:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36; compatible; OAI-SearchBot/1.3; +https://openai.com/searchbot
Několik významných AI společností provozuje vlastní crawlery s unikátními identifikátory user-agent a specifickými účely. Tyto crawlery zastupují různé případy užití v AI ekosystému:
GPTBot (OpenAI): Sbírá trénovací data pro ChatGPT a další modely OpenAI, respektuje direktivy robots.txt
ClaudeBot (Anthropic): Shromažďuje obsah pro trénování modelů Claude, lze jej zablokovat přes robots.txt
OAI-SearchBot (OpenAI): Indexuje webový obsah speciálně pro vyhledávací funkce a AI poháněné vyhledávání
PerplexityBot (Perplexity AI): Prochází web za účelem poskytování vyhledávacích výsledků a výzkumných možností ve své platformě
Gemini-Deep-Research (Google): Provádí hluboké výzkumné úkoly pro model Gemini od Google
Meta-ExternalAgent (Meta): Sbírá data pro trénování a výzkum AI iniciativ Meta
Bingbot (Microsoft): Slouží jak k tradiční indexaci vyhledávání, tak k AI generování odpovědí
Každý crawler má specifické IP rozsahy a oficiální dokumentaci, na kterou se mohou vlastníci webů odkazovat pro ověření legitimity a nastavení vhodných přístupových pravidel.
Podvržení user-agentů a ověřovací výzvy
User-agent stringy může snadno zfalšovat jakýkoliv klient, který vytváří HTTP požadavek, takže samy o sobě nejsou dostatečné jako jediný autentizační mechanismus pro identifikaci legitimních AI crawlerů. Škodlivé boty často napodobují populární user-agent stringy, aby zamaskovaly svou skutečnou identitu a obešly bezpečnostní opatření webu nebo omezení robots.txt. K vyřešení této zranitelnosti odborníci doporučují používat ověření podle IP adresy jako další ochrannou vrstvu a kontrolovat, že požadavky pocházejí z oficiálních IP rozsahů zveřejněných AI společnostmi. Nový standard RFC 9421 HTTP Message Signatures přináší kryptografické možnosti, které umožňují crawlerům digitálně podepsat své požadavky tak, aby servery mohly kryptograficky ověřit jejich pravost. Přesto zůstává rozlišení mezi skutečnými a falešnými crawlery náročné, protože odhodlaní útočníci mohou podvrhnout nejen user-agent, ale i IP adresu pomocí proxy nebo kompromitované infrastruktury. Tento nekonečný souboj mezi provozovateli crawlerů a bezpečnostně uvědomělými správci webů se vyvíjí s každou novou ověřovací technikou.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Použití robots.txt s direktivami user-agent
Vlastníci webů mohou řídit přístup crawlerů zadáním direktiv user-agent v souboru robots.txt, což umožňuje detailní kontrolu, které crawlery mohou přistupovat k jednotlivým částem webu. Soubor robots.txt využívá identifikátory user-agent k cílení na konkrétní crawlery pomocí vlastních pravidel, čímž umožňuje povolit některým crawlerům přístup a jiným jej zamezit. Zde je příklad konfigurace robots.txt:
Ačkoliv robots.txt poskytuje pohodlný mechanismus pro řízení crawlerů, má svá zásadní omezení:
Robots.txt je pouze doporučení a není vymahatelný; crawlery jej mohou ignorovat
Podvržené user-agenty mohou omezení robots.txt zcela obejít
Serverové ověření přes povolování IP adres poskytuje silnější ochranu
Web Application Firewall (WAF) může blokovat požadavky z nepovolených IP rozsahů
Kombinace robots.txt a ověření IP vytváří robustnější strategii řízení přístupu
Analýza aktivity crawlerů pomocí serverových logů
Vlastníci webů mohou využít serverové logy ke sledování a analýze aktivity AI crawlerů a získat přehled o tom, které AI systémy přistupují k jejich obsahu a jak často. Analýzou HTTP logů a filtrováním známých user-agent řetězců AI crawlerů mohou správci webů porozumět dopadu na šířku pásma i vzorcům sběru dat různých AI společností. Nástroje jako platformy pro analýzu logů, webová analytika nebo vlastní skripty umožňují zpracovat logy serveru, identifikovat provoz crawlerů, měřit frekvenci požadavků i objem přenesených dat. Tento přehled je zvlášť důležitý pro tvůrce obsahu a vydavatele, kteří chtějí zjistit, jak je jejich práce využívána pro trénování AI a zda mají implementovat přístupová omezení. Služby jako AmICited.com hrají v tomto ekosystému klíčovou roli tím, že monitorují a sledují, jak AI systémy citují a odkazují obsah z webu, a poskytují tvůrcům transparentnost o využití jejich obsahu při trénování AI. Pochopení aktivity crawlerů pomáhá vlastníkům webů dělat informovaná rozhodnutí o obsahu a jednat s AI společnostmi o právech na využití dat.
Nejlepší postupy pro správu přístupu AI crawlerů
Efektivní správa přístupu AI crawlerů vyžaduje víceúrovňový přístup kombinující několik ověřovacích a monitorovacích technik:
Kombinujte kontrolu user-agent s ověřením IP – Nikdy se nespoléhejte pouze na user-agent řetězce; vždy kontrolujte i oficiální IP rozsahy zveřejněné AI společnostmi
Udržujte aktuální seznamy povolených IP – Pravidelně revidujte a aktualizujte firewallová pravidla podle nejnovějších IP rozsahů od OpenAI, Anthropic, Google a dalších AI poskytovatelů
Provádějte pravidelnou analýzu logů – Naplánujte pravidelné kontroly serverových logů pro identifikaci podezřelé aktivity crawlerů a nepovolených pokusů o přístup
Rozlišujte typy crawlerů – Odlište crawlery pro trénování (GPTBot, ClaudeBot) od crawlerů pro vyhledávání (OAI-SearchBot, PerplexityBot) a aplikujte vhodné politiky
Zvažte etické aspekty – Vyvažte omezení přístupu s faktem, že trénování AI prospívá různorodým a kvalitním zdrojům obsahu
Využívejte monitorovací služby – Využijte platformy jako AmICited.com ke sledování, jak je váš obsah používán a citován AI systémy, zajistěte správné přiřazení a pochopte dopad svého obsahu
Díky těmto postupům mohou správci webů udržet kontrolu nad svým obsahem a zároveň podpořit odpovědný rozvoj AI systémů.
Často kladené otázky
Co je user-agent string?
User-agent je HTTP hlavičkový řetězec, který identifikuje klienta provádějícího webový požadavek. Obsahuje informace o softwaru, operačním systému a verzi požadující aplikace, ať už jde o prohlížeč, crawler nebo bota. Tento řetězec umožňuje webovým serverům identifikovat a sledovat různé typy klientů přistupujících k jejich obsahu.
Proč AI crawlery potřebují user-agent stringy?
User-agent stringy umožňují webovým serverům identifikovat, který crawler přistupuje k jejich obsahu, což webovým správcům umožňuje řídit přístup, sledovat aktivitu crawlerů a rozlišit různé typy botů. To je zásadní pro správu přenosové kapacity, ochranu obsahu a pochopení, jak AI systémy využívají vaše data.
Lze user-agent stringy zfalšovat?
Ano, user-agent stringy lze snadno podvrhnout, protože jsou to pouze textové hodnoty v HTTP hlavičkách. Proto je důležitá ověřovací metoda přes IP adresy a HTTP Message Signatures jako dodatečné ověřovací mechanismy k potvrzení pravé identity crawleru a prevenci před škodlivými boty, kteří se vydávají za legitimní crawlery.
Jak mohu zablokovat konkrétní AI crawlery?
Můžete použít robots.txt s direktivami user-agent, abyste crawlerům doporučili, aby na váš web nechodili, ale toto není vynutitelné. Pro silnější kontrolu využijte serverové ověření, povolování/zakazování IP adres nebo WAF pravidla, která kontrolují současně jak user-agent, tak IP adresu.
Jaký je rozdíl mezi GPTBot a OAI-SearchBot?
GPTBot je crawler od OpenAI pro sběr trénovacích dat pro AI modely jako ChatGPT, zatímco OAI-SearchBot je určen pro indexaci vyhledávání a podporu vyhledávacích funkcí v ChatGPT. Mají odlišné účely, rychlosti crawlů a IP rozsahy, což vyžaduje různé strategie řízení přístupu.
Jak ověřím, že je crawler legitimní?
Zkontrolujte IP adresu crawleru oproti oficiálnímu IP seznamu zveřejněnému provozovatelem crawleru (např. openai.com/gptbot.json pro GPTBot). Legitimní crawlery zveřejňují své IP rozsahy a můžete ověřit, že požadavky přicházejí právě z těchto rozsahů pomocí firewallových pravidel nebo WAF konfigurací.
Co je ověřování HTTP Message Signature?
HTTP Message Signatures (RFC 9421) je kryptografická metoda, při které crawlery podepisují své požadavky soukromým klíčem. Servery mohou ověřit podpis pomocí veřejného klíče crawleru z jejich .well-known adresáře, čímž prokážou, že požadavek je autentický a nebyl změněn.
Jak AmICited.com pomáhá s monitoringem AI crawlerů?
AmICited.com monitoruje, jak AI systémy odkazují a citují vaši značku napříč GPTs, Perplexity, Google AI Overviews a dalšími AI platformami. Sleduje aktivitu crawlerů a zmínky v AI, což vám pomáhá pochopit vaši viditelnost v AI-generovaných odpovědích a jak je váš obsah využíván.
Monitorujte svou značku v AI systémech
Sledujte, jak AI crawlery odkazují a citují váš obsah napříč ChatGPT, Perplexity, Google AI Overviews a dalšími AI platformami s AmICited.
Jak identifikovat AI crawlery v serverových logách: Kompletní průvodce detekcí
Naučte se, jak identifikovat a monitorovat AI crawlery jako GPTBot, PerplexityBot a ClaudeBot ve vašich serverových logách. Objevte user-agent řetězce, metody o...
Pochopte, jak fungují AI crawleři jako GPTBot a ClaudeBot, v čem se liší od tradičních crawlerů vyhledávačů a jak optimalizovat svůj web pro viditelnost ve vyhl...
Které AI crawlery povolit? Kompletní průvodce pro rok 2025
Zjistěte, které AI crawlery povolit nebo blokovat ve vašem robots.txt. Komplexní průvodce zahrnující GPTBot, ClaudeBot, PerplexityBot a 25+ AI crawlerů s ukázka...
10 min čtení
Souhlas s cookies Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.