
Trénovací data
Trénovací data jsou datová sada používaná k učení modelů strojového učení vzorům a vztahům. Zjistěte, jak kvalita trénovacích dat ovlivňuje výkon, přesnost a re...
11 min čtení

Trénink na syntetických datech je proces učení AI modelů pomocí uměle generovaných dat namísto reálných informací vytvořených lidmi. Tento přístup řeší nedostatek dat, urychluje vývoj modelů a zachovává soukromí, ale přináší i výzvy, jako je kolaps modelu a halucinace, které vyžadují pečlivé řízení a validaci.
Trénink na syntetických datech je proces učení AI modelů pomocí uměle generovaných dat namísto reálných informací vytvořených lidmi. Tento přístup řeší nedostatek dat, urychluje vývoj modelů a zachovává soukromí, ale přináší i výzvy, jako je kolaps modelu a halucinace, které vyžadují pečlivé řízení a validaci.
Trénink na syntetických datech označuje proces učení modelů umělé inteligence pomocí uměle vytvořených dat místo reálných informací vytvořených lidmi. Na rozdíl od tradičního tréninku AI, který spoléhá na autentické datové sady získané z průzkumů, pozorování nebo těžby webu, jsou syntetická data vytvářena algoritmy a výpočetními metodami, které se učí statistické vzorce ze stávajících dat nebo generují zcela nová data od nuly. Tento zásadní posun v metodice tréninku řeší kritický problém moderního vývoje AI: exponenciální růst výpočetních požadavků překonal schopnosti lidstva generovat dostatek reálných dat, přičemž výzkumy naznačují, že lidsky generovaná trénovací data mohou být během několika let vyčerpána. Trénink na syntetických datech nabízí škálovatelnou a nákladově efektivní alternativu, kterou lze generovat neomezeně bez časově náročných procesů sběru, označování a čištění dat, které zabírají až 80 % tradičního času vývoje AI.
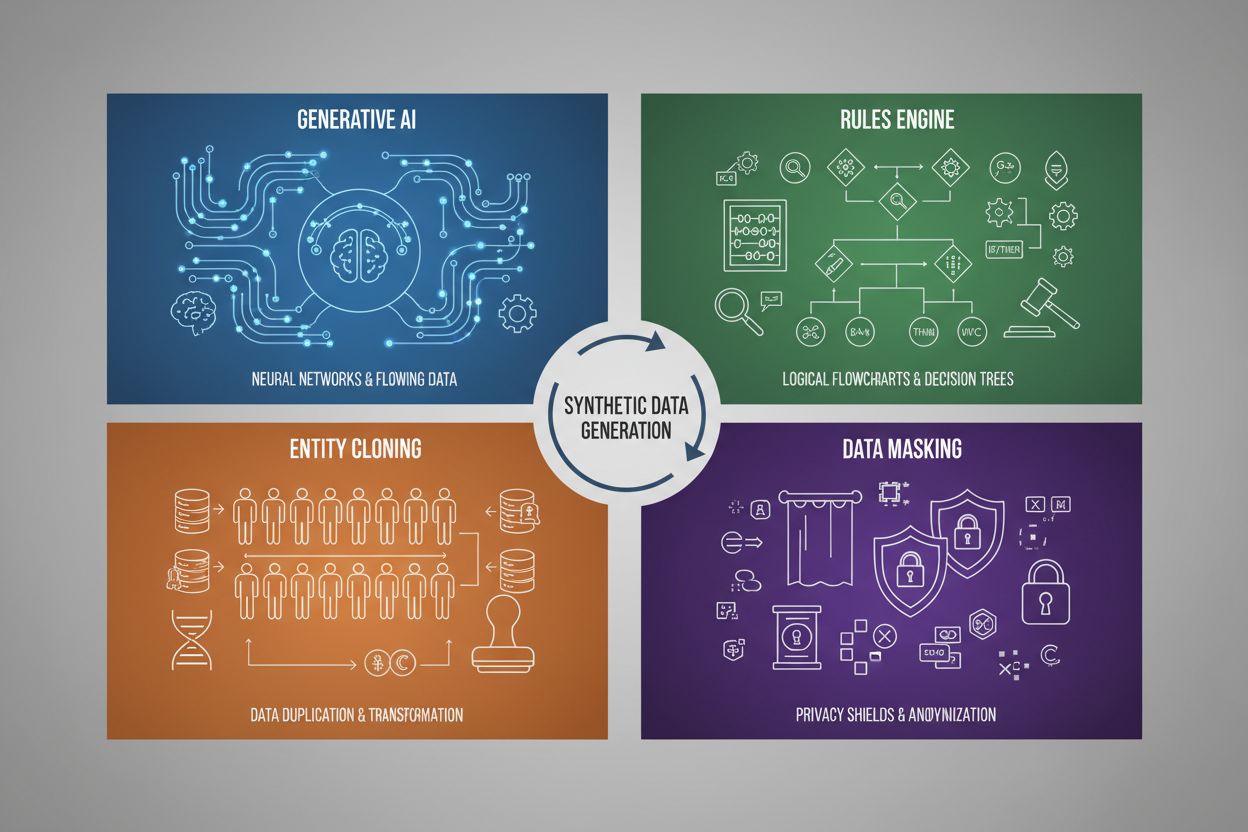
Generování syntetických dat využívá čtyři hlavní techniky, z nichž každá má odlišné mechanismy a uplatnění:
| Technika | Jak funguje | Použití |
|---|---|---|
| Generativní AI (GANs, VAEs, GPT) | Využívá modely hlubokého učení ke studiu statistických vzorců a rozdělení v reálných datech, poté generuje nové syntetické vzorky, které zachovávají stejné statistické vlastnosti a vztahy. GANs používají protivné sítě, kde generátor vytváří falešná data a diskriminátor hodnotí jejich autentičnost, čímž vznikají stále realističtější výstupy. | Trénink velkých jazykových modelů jako ChatGPT, generování syntetických obrázků pomocí DALL-E, tvorba různorodých textových dat pro úlohy zpracování přirozeného jazyka |
| Pravidlový engine | Aplikuje předem stanovená logická pravidla a omezení k tvorbě dat odpovídajících konkrétní obchodní logice, znalostem domény nebo regulatorním požadavkům. Tento deterministický přístup zajišťuje, že generovaná data odpovídají známým vzorcům a vztahům bez potřeby strojového učení. | Finanční transakční data, zdravotnické záznamy se speciálními požadavky na compliance, data ze senzorů ve výrobě s danými provozními parametry |
| Klonování entit | Duplikuje a modifikuje existující reálné datové záznamy pomocí transformací, perturbací nebo variací za účelem vytvoření nových instancí při zachování základních statistických vlastností a vztahů. Tato technika si udržuje autenticitu dat při rozšiřování velikosti datové sady. | Rozšiřování omezených datových sad v regulovaných odvětvích, tvorba trénovacích dat pro diagnostiku vzácných onemocnění, augmentace dat s nedostatkem minoritních tříd |
| Maskování a anonymizace dat | Skrývá citlivé osobní identifikovatelné informace (PII) při zachování struktury a statistických vztahů v datech pomocí technik jako tokenizace, šifrování nebo nahrazování hodnot. Vznikají tak syntetické verze reálných dat s ochranou soukromí. | Zdravotnická a finanční data, údaje o chování zákazníků, osobně citlivé informace ve výzkumných kontextech |
Trénink na syntetických datech přináší výrazné snížení nákladů eliminací drahých procesů sběru, anotace a čištění dat, které tradičně spotřebovávají značné zdroje a čas. Organizace si mohou na vyžádání generovat neomezené množství trénovacích vzorků, což dramaticky urychluje vývojové cykly modelů a umožňuje rychlé iterace a experimentování bez čekání na sběr reálných dat. Tato technika poskytuje silné možnosti augmentace dat, kdy vývojáři rozšiřují omezené datové sady a vytváří vyvážené trénovací sady řešící problém nevyváženosti tříd – což je zásadní problém, kdy některé kategorie jsou v reálných datech nedostatečně zastoupeny. Syntetická data jsou zvlášť cenná pro řešení nedostatku dat ve specializovaných oblastech, jako je medicínské zobrazování, diagnostika vzácných chorob nebo testování autonomních vozidel, kde by sběr dostatečného množství reálných příkladů byl finančně nebo eticky problematický. Zachování soukromí představuje další významnou výhodu, jelikož syntetická data lze generovat bez odhalení citlivých osobních údajů, což je ideální pro trénink modelů na zdravotnických záznamech, finančních datech či jiných regulovaných informacích. Dále syntetická data umožňují systematické snižování zkreslení tím, že vývojáři mohou záměrně vytvářet vyvážené a různorodé datové sady, které potlačují diskriminační vzorce přítomné v reálných datech – například generováním různorodých demografických zastoupení v tréninkových obrázcích, aby AI modely nereprodukovaly genderové či rasové stereotypy v oblasti náboru, půjčování či trestní justice.
Přes svůj potenciál přináší trénink na syntetických datech významné technické a praktické výzvy, které mohou při nedostatečném řízení zhoršit výkonnost modelu. Nejkritičtější je kolaps modelu, což je jev, kdy modely AI trénované převážně na syntetických datech výrazně ztrácejí kvalitu, přesnost a koherenci výstupů. Dochází k tomu proto, že syntetická data, byť statisticky podobná reálným, postrádají jemnou komplexnost a okrajové případy autentických informací – pokud se modely trénují na AI-generovaném obsahu, začínají chyby a artefakty zesilovat, čímž vzniká kumulativní problém, kdy každá další generace syntetických dat je nekvalitnější.
Klíčové výzvy zahrnují:
Tyto výzvy zdůrazňují, proč samotná syntetická data nemohou nahradit reálná data – musí být pečlivě integrována jako doplněk k autentickým datovým sadám s důslednou kontrolou kvality a lidským dohledem po celou dobu tréninkového procesu.
S rostoucím využitím syntetických dat při tréninku AI modelů čelí značky nové zásadní výzvě: zajistit přesnou a příznivou reprezentaci ve výstupech a citacích generovaných AI. Pokud se velké jazykové modely a generativní AI systémy trénují na syntetických datech, kvalita a charakter těchto dat přímo ovlivňuje, jak jsou značky popisovány, doporučovány a citovány ve výsledcích AI vyhledávání, odpovědích chatbotů i automatizované tvorbě obsahu. To vytváří významné riziko pro bezpečnost značky, protože syntetická data obsahující zastaralé informace, zaujatost konkurence nebo nepřesné popisy značky se mohou do AI modelů pevně zabudovat a vést k trvalé dezinterpretaci napříč miliony uživatelských interakcí. Pro organizace využívající platformy jako AmICited.com ke sledování přítomnosti značky v AI systémech je pochopení role syntetických dat při tréninku klíčové – značky potřebují mít přehled, zda citace a zmínky v AI pocházejí z reálných trénovacích dat nebo syntetických zdrojů, protože to ovlivňuje důvěryhodnost a přesnost. Nedostatek transparentnosti ohledně využití syntetických dat při tréninku AI vytváří problémy s odpovědností: společnosti nemohou snadno zjistit, zda byly jejich informace správně reprezentovány v syntetických datových sadách použitých pro trénink modelů, které ovlivňují vnímání spotřebitelů. Progresivní značky by měly upřednostnit AI monitoring a sledování citací pro včasné odhalení dezinterpretací, prosazovat standardy transparentnosti vyžadující zveřejnění využití syntetických dat při tréninku AI a spolupracovat s platformami, které poskytují přehled, jak je jejich značka zobrazována napříč AI systémy trénovanými jak na reálných, tak syntetických datech. S tím, jak se syntetická data stanou do roku 2030 dominantním tréninkovým paradigmatem, se monitoring značky přesune od sledování tradičních médií ke komplexní AI inteligenci citací – platformy sledující reprezentaci značky napříč generativními AI systémy se stanou nepostradatelnými pro ochranu integrity značky a zajištění přesného brandového hlasu v AI-informačním ekosystému.
Tradiční trénink AI spoléhá na reálná data shromážděná od lidí prostřednictvím průzkumů, pozorování nebo těžby webu, což je časově náročné a stále obtížnější. Trénink na syntetických datech využívá uměle generovaná data vytvořená algoritmy, které se učí statistické vzorce z existujících dat nebo generují zcela nová data od nuly. Syntetická data lze vytvářet neomezeně na požádání, což dramaticky snižuje dobu a náklady na vývoj a zároveň řeší otázky soukromí.
Čtyři hlavní techniky jsou: 1) Generativní AI (využití GANs, VAEs nebo GPT modelů k učení a replikaci datových vzorců), 2) Pravidlový engine (aplikace předem definované obchodní logiky a omezení), 3) Klonování entit (duplikace a úprava existujících záznamů při zachování statistických vlastností) a 4) Maskování dat (anonymizace citlivých informací při zachování struktury dat). Každá technika slouží jiným účelům a má specifické výhody.
Kolaps modelu nastává, když AI modely intenzivně trénované na syntetických datech podstatně ztrácejí kvalitu a přesnost výstupů. Důvodem je, že syntetická data, byť statisticky podobná reálným, postrádají jemnou komplexnost a okrajové případy autentických informací. Při tréninku na AI-generovaném obsahu modely chyby a artefakty zesilují, což vede k postupnému snižování kvality každé další generace až po nevyužitelné výstupy.
Když se AI modely trénují na syntetických datech, kvalita a charakter těchto dat přímo ovlivňuje, jak jsou značky popisovány, doporučovány a citovány ve výstupech AI. Nekvalitní syntetická data obsahující zastaralé informace nebo zaujatost konkurence se mohou do AI modelů pevně zabudovat, což vede k trvalé dezinterpretaci značky v milionech uživatelských interakcí. To představuje riziko pro bezpečnost značky, které vyžaduje monitorování a transparentnost ohledně využití syntetických dat při tréninku AI.
Ne, syntetická data by měla reálná data doplňovat, nikoli nahrazovat. Ačkoliv syntetická data přinášejí významné výhody v oblasti nákladů, rychlosti a ochrany soukromí, nemohou plně nahradit komplexnost, rozmanitost a okrajové případy obsažené v autentických lidských datech. Nejefektivnější přístup kombinuje syntetická a reálná data s důslednou kontrolou kvality a lidským dohledem pro zajištění přesnosti a spolehlivosti modelu.
Syntetická data poskytují vynikající ochranu soukromí, protože neobsahují žádné skutečné hodnoty z původních datových sad a nemají žádné přímé vazby na reálné osoby. Na rozdíl od tradičních technik maskování nebo anonymizace dat, které stále mohou nést riziko znovuidentifikace, jsou syntetická data vytvářena zcela od nuly na základě naučených vzorců. Díky tomu jsou ideální pro trénink modelů na citlivých informacích, jako jsou zdravotní záznamy, finanční data nebo osobní chování, bez ohrožení reálných osobních údajů.
Syntetická data umožňují systematické snižování zkreslení tím, že vývojářům dovolují záměrně vytvářet vyvážené a různorodé datové sady, které vyvažují diskriminační vzorce v reálných datech. Například lze generovat různorodé demografické zastoupení v tréninkových obrázcích, aby AI modely nereprodukovaly genderové či rasové stereotypy. Tato schopnost je zvlášť cenná v oblastech jako je nábor, poskytování půjček nebo trestní justice, kde může mít zkreslení vážné důsledky.
S tím, jak se syntetická data stanou do roku 2030 dominantním tréninkovým paradigmatem, je důležité, aby značky rozuměly, jak je jejich informace reprezentována v AI systémech. Kvalita syntetických dat přímo ovlivňuje citace a zmínky značky ve výstupech AI. Značky by měly sledovat svou přítomnost napříč AI systémy, prosazovat standardy transparentnosti vyžadující zveřejnění použití syntetických dat a využívat platformy jako AmICited.com ke sledování reprezentace značky a včasnému odhalení dezinterpretací.
Zjistěte, jak je vaše značka prezentována napříč AI systémy trénovanými na syntetických datech. Sledujte citace, monitorujte přesnost a zajistěte bezpečnost značky v AI-informačním ekosystému.
Trénovací data jsou datová sada používaná k učení modelů strojového učení vzorům a vztahům. Zjistěte, jak kvalita trénovacích dat ovlivňuje výkon, přesnost a re...

Kompletní průvodce odhlášením ze shromažďování dat pro AI trénink na ChatGPT, Perplexity, LinkedIn a dalších platformách. Naučte se krok za krokem chránit svá d...

Porovnejte optimalizaci trénovacích dat a strategie real-time retrievalu pro AI. Zjistěte, kdy použít fine-tuning vs. RAG, nákladové dopady a hybridní přístupy ...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.