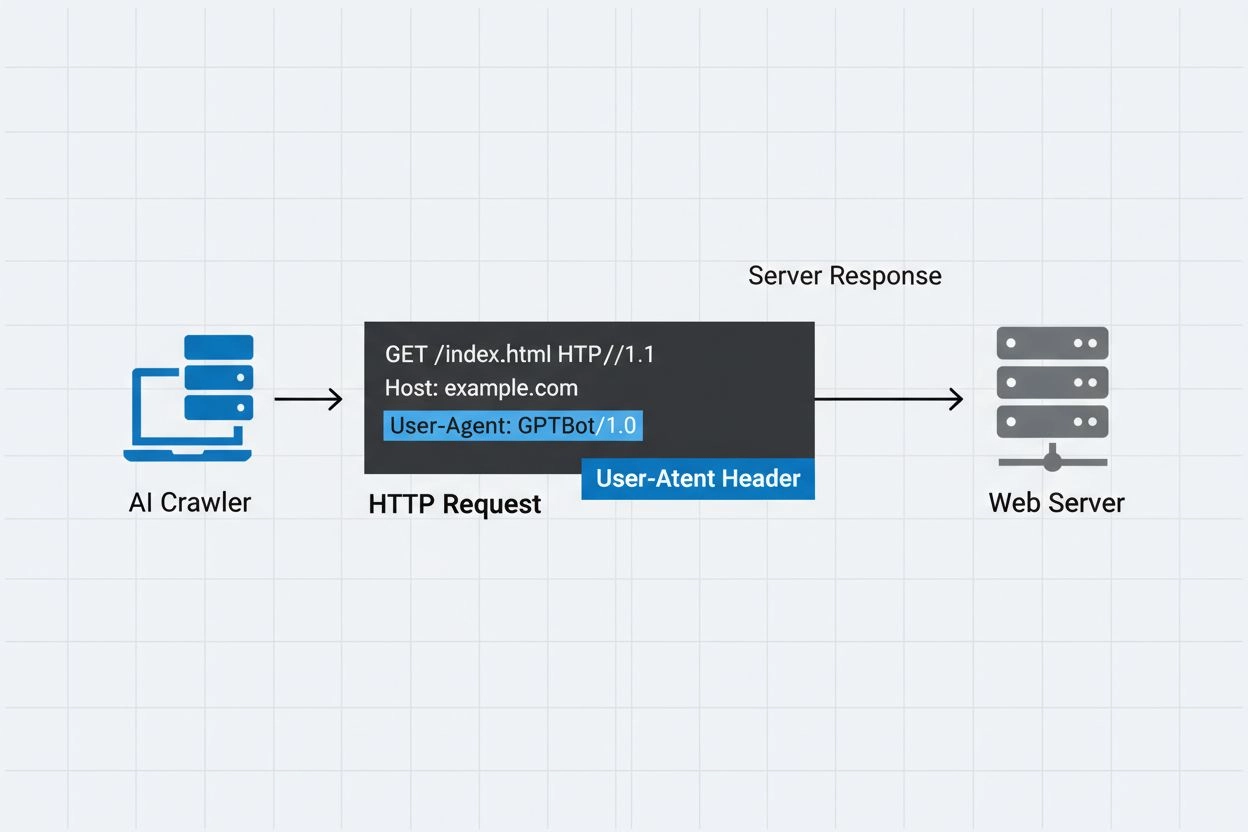
Identifikasjonsstrengen AI-crawlere sender til webservere i HTTP-headere, brukt for tilgangskontroll, analyse og for å skille legitime AI-boter fra ondsinnede skrapere. Den identifiserer crawlerens formål, versjon og opprinnelse.
AI Crawler User-Agent
Identifikasjonsstrengen AI-crawlere sender til webservere i HTTP-headere, brukt for tilgangskontroll, analyse og for å skille legitime AI-boter fra ondsinnede skrapere. Den identifiserer crawlerens formål, versjon og opprinnelse.
Definisjon av AI Crawler User-Agent
En AI crawler user-agent er en HTTP-header-streng som identifiserer automatiserte boter som får tilgang til nettinnhold for kunstig intelligens-trening, indeksering eller forskningsformål. Denne strengen fungerer som crawlerens digitale identitet og kommuniserer til webservere hvem som gjør forespørselen og hva hensikten er. User-agenten er avgjørende for AI-crawlere fordi den lar nettstedseiere gjenkjenne, spore og kontrollere hvordan innholdet deres blir aksessert av ulike AI-systemer. Uten korrekt user-agent-identifikasjon blir det betydelig vanskeligere å skille mellom legitime AI-crawlere og ondsinnede boter, noe som gjør den til en essensiell del av ansvarlig webskraping og datainnsamling.
HTTP-kommunikasjon og User-Agent-headere
User-agent-headeren er en kritisk komponent i HTTP-forespørsler, og vises i forespørsels-headerene som alle nettlesere og boter sender når de får tilgang til en webressurs. Når en crawler gjør en forespørsel til en webserver, inkluderer den metadata om seg selv i HTTP-headerne, der user-agent-strengen er en av de viktigste identifikatorene. Denne strengen inneholder vanligvis informasjon om crawlerens navn, versjon, hvilken organisasjon som driver den, og ofte en kontakt-URL eller e-postadresse for verifisering. User-agenten lar servere identifisere klienten som forespør og ta avgjørelser om å levere innhold, begrense forespørsler eller blokkere tilgang helt. Under ser du eksempler på user-agent-strenger fra store AI-crawlere:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36; compatible; OAI-SearchBot/1.3; +https://openai.com/searchbot
Flere fremtredende AI-selskaper driver sine egne crawlere med distinkte user-agent-identifikatorer og formål. Disse crawlerne representerer ulike bruksområder innen AI-økosystemet:
GPTBot (OpenAI): Samler treningsdata til ChatGPT og andre OpenAI-modeller, respekterer robots.txt-direktiver
ClaudeBot (Anthropic): Henter innhold for trening av Claude-modeller, kan blokkeres via robots.txt
OAI-SearchBot (OpenAI): Indekserer nettinnhold spesielt for søkefunksjonalitet og AI-drevne søkefunksjoner
PerplexityBot (Perplexity AI): Crawler nettet for å gi søkeresultater og forskningsmuligheter på sin plattform
Gemini-Deep-Research (Google): Utfører dyptgående forskningsoppgaver for Googles Gemini AI-modell
Meta-ExternalAgent (Meta): Samler data til Metas AI-trenings- og forskningsinitiativer
Bingbot (Microsoft): Tjener dobbelt formål for tradisjonell søkeindeksering og AI-drevet svargenerering
Hver crawler har spesifikke IP-områder og offisiell dokumentasjon som nettstedseiere kan bruke for å verifisere legitimitet og implementere passende tilgangskontroller.
User-Agent-forfalskning og verifiseringsutfordringer
User-agent-strenger kan lett forfalskes av enhver klient som gjør en HTTP-forespørsel, noe som gjør dem utilstrekkelige som eneste autentiseringsmekanisme for å identifisere legitime AI-crawlere. Ondsinnede boter forfalsker ofte populære user-agent-strenger for å skjule sin sanne identitet og omgå nettstedets sikkerhetstiltak eller robots.txt-restriksjoner. For å håndtere denne sårbarheten anbefaler sikkerhetseksperter å bruke IP-verifisering som et ekstra autentiseringslag, ved å sjekke at forespørsler kommer fra de offisielle IP-områdene publisert av AI-selskaper. Den nye RFC 9421-standarden for HTTP Message Signatures gir kryptografiske verifikasjonsmuligheter, slik at crawlere kan signere forespørslene sine digitalt slik at servere kan verifisere ektheten kryptografisk. Likevel er det fortsatt utfordrende å skille mellom ekte og falske crawlere, fordi bestemte angripere kan forfalske både user-agent-strenger og IP-adresser gjennom proxyer eller kompromittert infrastruktur. Dette er et kappløp mellom crawler-operatører og sikkerhetsbevisste nettstedseiere som stadig utvikles etter hvert som nye verifiseringsteknikker introduseres.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Bruk av robots.txt med User-Agent-direktiver
Nettstedseiere kan kontrollere crawler-tilgang ved å spesifisere user-agent-direktiver i robots.txt-filen, noe som gir detaljert kontroll over hvilke crawlere som får tilgang til hvilke deler av nettstedet. Robots.txt-filen bruker user-agent-identifikatorer for å målrette spesifikke crawlere med egendefinerte regler, slik at nettstedseiere kan tillate noen crawlere samtidig som de blokkerer andre. Her er et eksempel på robots.txt-konfigurasjon:
Selv om robots.txt gir en praktisk måte å kontrollere crawlere på, har den viktige begrensninger:
Robots.txt er kun rådgivende og ikke håndhevbar; crawlere kan ignorere den
Forfalskede user-agenter kan omgå robots.txt-restriksjoner helt
Server-side-verifisering gjennom IP-allowlisting gir sterkere beskyttelse
Web Application Firewall (WAF)-regler kan blokkere forespørsler fra uautoriserte IP-områder
Å kombinere robots.txt med IP-verifisering gir en mer robust tilgangskontrollstrategi
Analysere crawler-aktivitet gjennom serverlogger
Nettstedseiere kan bruke serverlogger til å spore og analysere AI-crawler-aktivitet, og få innsikt i hvilke AI-systemer som får tilgang til innholdet og hvor ofte. Ved å gjennomgå HTTP-forespørselslogger og filtrere etter kjente AI-crawler-user-agenter, kan administratorer forstå båndbreddebelastning og datainnsamlingsmønstre fra ulike AI-selskaper. Verktøy som logganalyseplattformer, webanalysetjenester og egendefinerte skript kan analysere serverlogger for å identifisere crawler-trafikk, måle forespørselsfrekvens og beregne datavolum. Denne synligheten er spesielt viktig for innholdsskapere og utgivere som ønsker å forstå hvordan arbeidet deres brukes til AI-trening og om de bør innføre tilgangsbegrensninger. Tjenester som AmICited.com spiller en viktig rolle i dette økosystemet ved å overvåke og spore hvordan AI-systemer siterer og refererer til innhold fra nettet, og gir skapere innsikt i hvordan innholdet deres brukes i AI-trening. Å forstå crawler-aktivitet hjelper nettstedseiere med å ta informerte beslutninger om innholdspolicyer og forhandle med AI-selskaper om bruksrettigheter.
Beste praksis for håndtering av AI-crawler-tilgang
Effektiv styring av AI-crawler-tilgang krever en flerlaget tilnærming som kombinerer flere verifikasjons- og overvåkingsteknikker:
Kombiner user-agent-sjekk med IP-verifisering – Stol aldri kun på user-agent-strenger; kryssjekk alltid med offisielle IP-områder publisert av AI-selskaper
Hold oppdaterte IP-allowlister – Gjennomgå og oppdater jevnlig brannmurreglene dine med de siste IP-områdene fra OpenAI, Anthropic, Google og andre AI-leverandører
Utfør regelmessig logganalyse – Planlegg periodiske gjennomganger av serverlogger for å identifisere mistenkelig crawler-aktivitet og uautorisert tilgang
Skill mellom crawler-typer – Skil mellom treningscrawlere (GPTBot, ClaudeBot) og søkecrawlere (OAI-SearchBot, PerplexityBot) for å anvende riktige policyer
Vurder etiske implikasjoner – Balanser tilgangsbegrensninger med realiteten om at AI-trening drar nytte av mangfoldige, høyverdige innholdskilder
Bruk overvåkingstjenester – Utnytt plattformer som AmICited.com for å spore hvordan innholdet ditt brukes og siteres av AI-systemer, sikre korrekt attribusjon og forstå innholdets effekt
Ved å følge disse praksisene kan nettstedseiere opprettholde kontroll over innholdet sitt samtidig som de støtter ansvarlig utvikling av AI-systemer.
Vanlige spørsmål
Hva er en user-agent-streng?
En user-agent er en HTTP-header-streng som identifiserer klienten som gjør en webforespørsel. Den inneholder informasjon om programvaren, operativsystemet og versjonen til applikasjonen som forespør, enten det er en nettleser, crawler eller bot. Denne strengen lar webservere identifisere og spore ulike typer klienter som får tilgang til innholdet deres.
Hvorfor trenger AI-crawlere user-agent-strenger?
User-agent-strenger lar webservere identifisere hvilken crawler som får tilgang til innholdet, slik at nettstedseiere kan kontrollere tilgang, spore crawler-aktivitet og skille mellom ulike typer boter. Dette er essensielt for å håndtere båndbredde, beskytte innhold og forstå hvordan AI-systemer bruker dataene dine.
Kan user-agent-strenger forfalskes?
Ja, user-agent-strenger kan lett forfalskes siden de bare er tekstverdier i HTTP-headere. Derfor er IP-verifisering og HTTP Message Signatures viktige tilleggsmetoder for å bekrefte en crawlers ekte identitet og forhindre at ondsinnede boter utgir seg for å være legitime crawlere.
Hvordan kan jeg blokkere bestemte AI-crawlere?
Du kan bruke robots.txt med user-agent-direktiver for å be crawlere om ikke å få tilgang til nettstedet ditt, men dette er ikke håndhevbart. For sterkere kontroll, bruk server-side-verifisering, IP-allowlisting/blocklisting eller WAF-regler som sjekker både user-agent og IP-adresse samtidig.
Hva er forskjellen mellom GPTBot og OAI-SearchBot?
GPTBot er OpenAI sin crawler for å samle inn treningsdata til AI-modeller som ChatGPT, mens OAI-SearchBot er laget for søkeindeksering og for å drive søkefunksjoner i ChatGPT. De har ulike formål, crawl-hastigheter og IP-områder, og krever forskjellig tilgangskontroll.
Hvordan kan jeg verifisere om en crawler er legitim?
Sjekk crawlerens IP-adresse mot den offisielle IP-listen publisert av crawler-operatøren (for eksempel openai.com/gptbot.json for GPTBot). Legitime crawlere publiserer sine IP-områder, og du kan verifisere at forespørsler kommer fra disse områdene med brannmurregler eller WAF-konfigurasjoner.
Hva er HTTP Message Signature-verifisering?
HTTP Message Signatures (RFC 9421) er en kryptografisk metode der crawlere signerer forespørslene sine med en privat nøkkel. Servere kan verifisere signaturen ved å bruke crawlerens offentlige nøkkel fra deres .well-known-katalog, og bekrefte at forespørselen er ekte og ikke har blitt manipulert.
Hvordan hjelper AmICited.com med overvåking av AI-crawlere?
AmICited.com overvåker hvordan AI-systemer refererer til og siterer merkevaren din på GPT-er, Perplexity, Google AI Overviews og andre AI-plattformer. Den sporer crawler-aktivitet og AI-omtaler, slik at du forstår synligheten din i AI-genererte svar og hvordan innholdet ditt brukes.
Overvåk merkevaren din i AI-systemer
Følg med på hvordan AI-crawlere refererer til og siterer innholdet ditt på ChatGPT, Perplexity, Google AI Overviews og andre AI-plattformer med AmICited.
Hvordan identifisere AI-crawlere i serverlogger: Komplett veiledning for deteksjon
Lær hvordan du identifiserer og overvåker AI-crawlere som GPTBot, PerplexityBot og ClaudeBot i serverloggene dine. Oppdag user-agent-strenger, IP-verifiseringsm...
Lær hvordan du administrerer AI-crawlertilgang til innholdet på nettsiden din. Forstå forskjellen mellom treningscrawlere og søkecrawlere, implementer robots.tx...
Hvilke AI-crawlere bør jeg gi tilgang? Komplett guide for 2025
Lær hvilke AI-crawlere du bør tillate eller blokkere i robots.txt-filen din. Omfattende guide som dekker GPTBot, ClaudeBot, PerplexityBot og 25+ AI-crawlere med...
10 min lesing
Informasjonskapselsamtykke Vi bruker informasjonskapsler for å forbedre din surfeopplevelse og analysere vår trafikk. See our privacy policy.