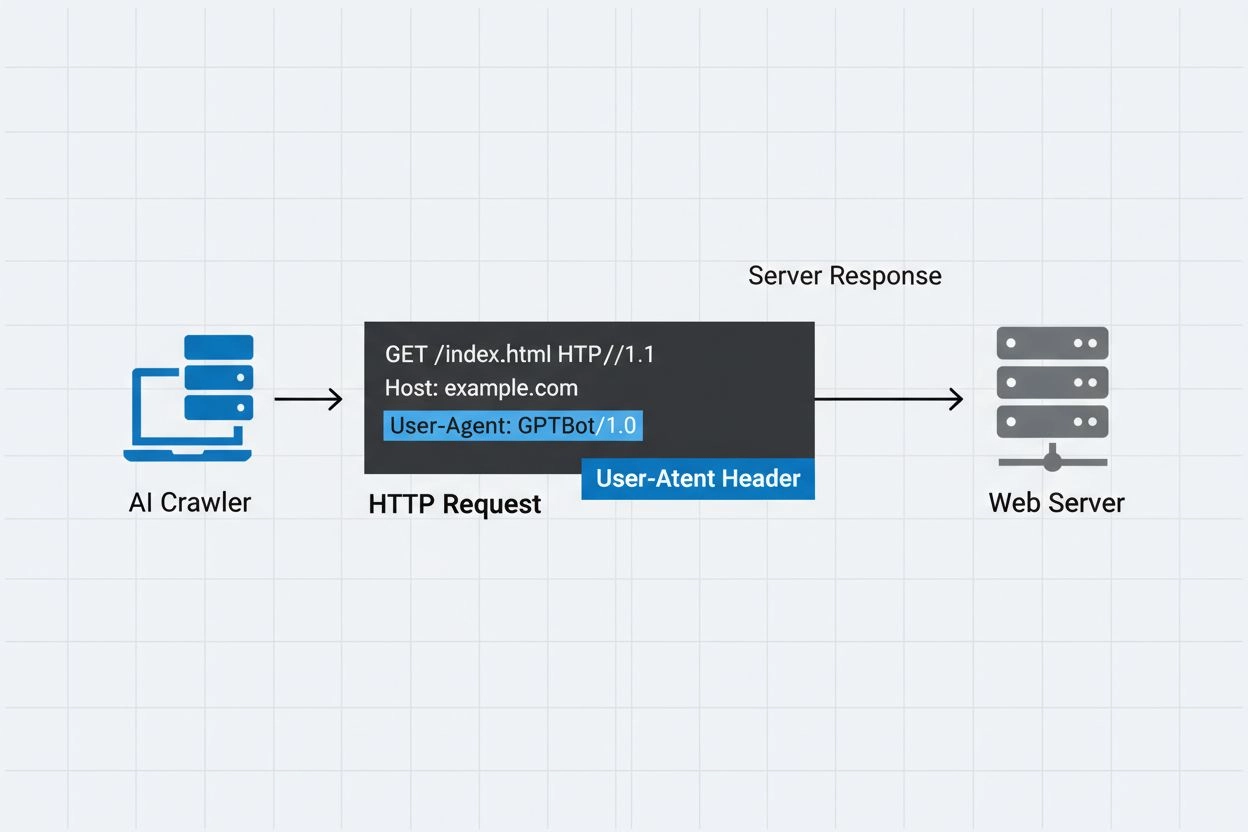
A cadeia de identificação que rastreadores de IA enviam aos servidores web nos cabeçalhos HTTP, usada para controle de acesso, monitoramento analítico e para distinguir bots legítimos de IA de raspadores maliciosos. Ela identifica o propósito, versão e origem do rastreador.
AI Crawler User-Agent
A cadeia de identificação que rastreadores de IA enviam aos servidores web nos cabeçalhos HTTP, usada para controle de acesso, monitoramento analítico e para distinguir bots legítimos de IA de raspadores maliciosos. Ela identifica o propósito, versão e origem do rastreador.
Definição de AI Crawler User-Agent
Um user-agent de rastreador de IA é uma cadeia no cabeçalho HTTP que identifica bots automatizados que acessam conteúdo web para fins de treinamento, indexação ou pesquisa em inteligência artificial. Essa cadeia serve como identidade digital do rastreador, informando aos servidores web quem está fazendo a solicitação e quais são suas intenções. O user-agent é fundamental para rastreadores de IA, pois permite que os proprietários de sites reconheçam, monitorem e controlem como seu conteúdo está sendo acessado por diferentes sistemas de IA. Sem uma identificação adequada de user-agent, distinguir entre rastreadores legítimos de IA e bots maliciosos torna-se significativamente mais difícil, tornando este um componente essencial das práticas responsáveis de coleta de dados e web scraping.
Comunicação HTTP e Cabeçalhos User-Agent
O cabeçalho user-agent é um componente crítico das requisições HTTP, aparecendo nos cabeçalhos que todo navegador e bot envia ao acessar um recurso web. Quando um rastreador faz uma solicitação a um servidor web, ele inclui metadados sobre si mesmo nos cabeçalhos HTTP, sendo a cadeia user-agent um dos identificadores mais importantes. Essa cadeia normalmente contém informações sobre o nome do rastreador, versão, organização operadora e, frequentemente, uma URL ou e-mail de contato para fins de verificação. O user-agent permite que servidores identifiquem o cliente solicitante e tomem decisões sobre servir conteúdo, limitar a taxa de requisições ou bloquear o acesso completamente. Abaixo estão exemplos de cadeias user-agent de grandes rastreadores de IA:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot)
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36; compatible; OAI-SearchBot/1.3; +https://openai.com/searchbot
Diversas empresas de IA de destaque operam seus próprios rastreadores com identificadores user-agent distintos e propósitos específicos. Esses rastreadores representam diferentes casos de uso dentro do ecossistema de IA:
GPTBot (OpenAI): Coleta dados de treinamento para o ChatGPT e outros modelos da OpenAI, respeita diretivas do robots.txt
ClaudeBot (Anthropic): Coleta conteúdo para treinamento dos modelos Claude, pode ser bloqueado via robots.txt
OAI-SearchBot (OpenAI): Indexa conteúdo web especificamente para funcionalidades de busca e recursos de pesquisa por IA
PerplexityBot (Perplexity AI): Rastreia a web para fornecer resultados de busca e capacidades de pesquisa em sua plataforma
Gemini-Deep-Research (Google): Realiza tarefas de pesquisa profunda para o modelo Gemini da Google
Meta-ExternalAgent (Meta): Coleta dados para iniciativas de treinamento e pesquisa em IA da Meta
Bingbot (Microsoft): Atua tanto para indexação de busca tradicional quanto para geração de respostas com IA
Cada rastreador possui faixas de IP e documentação oficial que proprietários de sites podem consultar para verificar legitimidade e implementar controles de acesso adequados.
Falsificação de User-Agent e Desafios de Verificação
Cadeias user-agent podem ser facilmente falsificadas por qualquer cliente ao fazer uma requisição HTTP, tornando-as insuficientes como mecanismo único de autenticação para identificar rastreadores de IA legítimos. Bots maliciosos frequentemente imitam cadeias populares de user-agent para disfarçar sua verdadeira identidade e burlar medidas de segurança de sites ou restrições do robots.txt. Para mitigar essa vulnerabilidade, especialistas em segurança recomendam o uso de verificação de IP como uma camada adicional de autenticação, checando se as solicitações vêm das faixas oficiais de IP publicadas pelas empresas de IA. O novo padrão RFC 9421 de Assinaturas de Mensagens HTTP fornece capacidades de verificação criptográfica, permitindo que rastreadores assinem digitalmente suas solicitações e servidores possam autenticar sua origem. No entanto, distinguir entre rastreadores reais e falsos permanece um desafio, pois agentes maliciosos determinados podem falsificar tanto user-agents quanto IPs usando proxies ou infraestrutura comprometida. Esse jogo de gato e rato entre operadores de rastreadores e donos de sites preocupados com segurança continua evoluindo na medida em que novas técnicas de verificação são desenvolvidas.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Usando robots.txt com Diretivas de User-Agent
Os proprietários de sites podem controlar o acesso de rastreadores especificando diretivas user-agent em seu arquivo robots.txt, permitindo controle granular sobre quais rastreadores podem acessar quais partes do site. O robots.txt utiliza identificadores user-agent para direcionar rastreadores específicos com regras personalizadas, possibilitando permitir alguns rastreadores enquanto bloqueia outros. Veja um exemplo de configuração no robots.txt:
Apesar do robots.txt fornecer um mecanismo conveniente de controle de rastreadores, ele apresenta limitações importantes:
O robots.txt é apenas consultivo e não obrigatório; rastreadores podem ignorá-lo
User-agents falsificados podem burlar completamente as restrições do robots.txt
A verificação no servidor através de listas de IPs autorizados fornece proteção mais forte
Regras de Web Application Firewall (WAF) podem bloquear solicitações de faixas de IP não autorizadas
A combinação de robots.txt com verificação de IP cria uma estratégia de controle de acesso mais robusta
Analisando Atividade de Rastreadores Através de Logs do Servidor
Os proprietários de sites podem aproveitar os logs do servidor para monitorar e analisar a atividade de rastreadores de IA, obtendo visibilidade sobre quais sistemas de IA acessam seu conteúdo e com que frequência. Ao examinar os registros de requisições HTTP e filtrar por user-agents conhecidos de rastreadores de IA, administradores de sites conseguem entender o impacto em banda e padrões de coleta de dados de diferentes empresas de IA. Ferramentas como plataformas de análise de logs, serviços de web analytics e scripts personalizados podem analisar os logs do servidor para identificar tráfego de rastreadores, medir frequência de requisições e calcular volumes de transferência de dados. Essa visibilidade é especialmente importante para criadores de conteúdo e editores que desejam entender como seu trabalho está sendo usado para treinamento de IA e se devem implementar restrições de acesso. Serviços como o AmICited.com desempenham papel crucial nesse ecossistema ao monitorar e rastrear como sistemas de IA citam e referenciam conteúdo da web, fornecendo transparência aos criadores sobre o uso de seu conteúdo em treinamentos de IA. Entender a atividade dos rastreadores ajuda os proprietários de sites a tomarem decisões informadas sobre suas políticas de conteúdo e a negociar com empresas de IA sobre direitos de uso de dados.
Melhores Práticas para Gerenciar o Acesso de Rastreadores de IA
Implementar um gerenciamento eficaz do acesso de rastreadores de IA requer uma abordagem em múltiplas camadas combinando diversas técnicas de verificação e monitoramento:
Combine checagem de user-agent com verificação de IP – Nunca confie apenas em cadeias user-agent; sempre cruze com as faixas de IP oficiais publicadas pelas empresas de IA
Mantenha listas de IPs autorizados atualizadas – Revise e atualize regularmente suas regras de firewall com as últimas faixas de IP da OpenAI, Anthropic, Google e outros provedores de IA
Implemente análise regular de logs – Agende revisões periódicas dos logs do servidor para identificar atividades suspeitas de rastreadores e tentativas de acesso não autorizadas
Distingua entre tipos de rastreadores – Diferencie rastreadores de treinamento (GPTBot, ClaudeBot) e de busca (OAI-SearchBot, PerplexityBot) para aplicar políticas apropriadas
Considere implicações éticas – Equilibre restrições de acesso com o fato de que o treinamento de IA se beneficia de fontes de conteúdo diversificadas e de alta qualidade
Use serviços de monitoramento – Aproveite plataformas como o AmICited.com para acompanhar como seu conteúdo está sendo usado e citado por sistemas de IA, garantindo a devida atribuição e entendendo o impacto do seu conteúdo
Seguindo essas práticas, proprietários de sites podem manter controle sobre seu conteúdo enquanto apoiam o desenvolvimento responsável de sistemas de IA.
Perguntas frequentes
O que é uma cadeia user-agent?
Um user-agent é uma cadeia de caracteres no cabeçalho HTTP que identifica o cliente que faz uma solicitação web. Contém informações sobre o software, sistema operacional e versão da aplicação requisitante, seja um navegador, rastreador ou bot. Essa cadeia permite que servidores web identifiquem e rastreiem diferentes tipos de clientes acessando seu conteúdo.
Por que rastreadores de IA precisam de cadeias user-agent?
As cadeias user-agent permitem que servidores web identifiquem qual rastreador está acessando seu conteúdo, possibilitando aos donos de sites controlar o acesso, monitorar a atividade dos rastreadores e distinguir entre diferentes tipos de bots. Isso é essencial para gerenciar banda, proteger conteúdo e entender como sistemas de IA estão usando seus dados.
Cadeias user-agent podem ser falsificadas?
Sim, cadeias user-agent podem ser facilmente falsificadas, já que são apenas valores de texto nos cabeçalhos HTTP. Por isso, a verificação de IP e as Assinaturas de Mensagens HTTP são métodos de verificação adicionais importantes para confirmar a identidade real de um rastreador e evitar que bots maliciosos se passem por rastreadores legítimos.
Como bloquear rastreadores de IA específicos?
Você pode usar o robots.txt com diretivas user-agent para solicitar que rastreadores não acessem seu site, mas isso não é obrigatório. Para um controle mais forte, utilize verificação no servidor, listas de IPs permitidos/bloqueados ou regras de WAF que verifiquem simultaneamente user-agent e endereço IP.
Qual a diferença entre GPTBot e OAI-SearchBot?
GPTBot é o rastreador da OpenAI para coletar dados de treinamento para modelos de IA como o ChatGPT, enquanto OAI-SearchBot é projetado para indexação de busca e recursos de pesquisa no ChatGPT. Eles têm propósitos, taxas de rastreamento e faixas de IP diferentes, exigindo estratégias distintas de controle de acesso.
Como verificar se um rastreador é legítimo?
Verifique o endereço IP do rastreador em relação à lista oficial de IPs publicada pelo operador do rastreador (por exemplo, openai.com/gptbot.json para o GPTBot). Rastreadores legítimos publicam suas faixas de IP, e você pode verificar se as solicitações vêm dessas faixas usando regras de firewall ou configurações de WAF.
O que é verificação de Assinatura de Mensagem HTTP?
HTTP Message Signatures (RFC 9421) é um método criptográfico onde os rastreadores assinam suas solicitações com uma chave privada. Os servidores podem verificar a assinatura usando a chave pública do rastreador disponível no diretório .well-known, comprovando que a solicitação é autêntica e não foi alterada.
Como o AmICited.com ajuda no monitoramento de rastreadores de IA?
O AmICited.com monitora como sistemas de IA referenciam e citam sua marca em GPTs, Perplexity, Google AI Overviews e outras plataformas de IA. Ele acompanha a atividade dos rastreadores e menções em IA, ajudando você a entender sua visibilidade em respostas geradas por IA e como seu conteúdo está sendo utilizado.
Monitore sua marca em sistemas de IA
Acompanhe como rastreadores de IA referenciam e citam seu conteúdo no ChatGPT, Perplexity, Google AI Overviews e outras plataformas de IA com o AmICited.
Como Identificar Crawlers de IA em Logs de Servidor: Guia Completo de Detecção
Aprenda como identificar e monitorar crawlers de IA como GPTBot, PerplexityBot e ClaudeBot em seus logs de servidor. Descubra strings de user-agent, métodos de ...
Como Permitir que Bots de IA Rastreiem Seu Site: Guia Completo de robots.txt & llms.txt
Aprenda como permitir que bots de IA como GPTBot, PerplexityBot e ClaudeBot rastreiem seu site. Configure o robots.txt, crie o llms.txt e otimize para visibilid...
Quais Crawlers de IA Devo Permitir? Guia Completo para 2025
Saiba quais crawlers de IA permitir ou bloquear no seu robots.txt. Guia abrangente cobrindo GPTBot, ClaudeBot, PerplexityBot e mais de 25 crawlers de IA com exe...
12 min de leitura
Consentimento de Cookies Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.