
Busca Semântica
A busca semântica interpreta o significado e o contexto da consulta usando PLN e aprendizado de máquina. Saiba como ela difere da busca por palavras-chave, impu...
14 min de leitura

A correspondência semântica de consulta é uma técnica impulsionada por IA que entende a intenção do usuário e o significado por trás das consultas de pesquisa, entregando resultados relevantes mesmo quando as palavras-chave exatas não coincidem. Utiliza processamento de linguagem natural e aprendizado de máquina para interpretar contexto, sinônimos e relações entre conceitos, possibilitando experiências de busca mais precisas e intuitivas em sistemas de IA como GPTs, Perplexity e Google AI Overviews.
A correspondência semântica de consulta é uma técnica impulsionada por IA que entende a intenção do usuário e o significado por trás das consultas de pesquisa, entregando resultados relevantes mesmo quando as palavras-chave exatas não coincidem. Utiliza processamento de linguagem natural e aprendizado de máquina para interpretar contexto, sinônimos e relações entre conceitos, possibilitando experiências de busca mais precisas e intuitivas em sistemas de IA como GPTs, Perplexity e Google AI Overviews.
A correspondência semântica de consulta é uma tecnologia de busca sofisticada que entende o significado e a intenção por trás das consultas do usuário em vez de simplesmente corresponder palavras-chave individuais. Diferente da correspondência tradicional de palavras-chave, que busca coincidências exatas ou variações simples, a correspondência semântica analisa o significado contextual dos termos de busca para entregar resultados mais relevantes. Por exemplo, um sistema semântico reconheceria que “Como consertar a tela quebrada do meu celular?” e “Meu display do dispositivo está rachado” são essencialmente a mesma consulta, mesmo usando palavras completamente diferentes, enquanto um sistema baseado em palavras-chave trataria como buscas separadas.
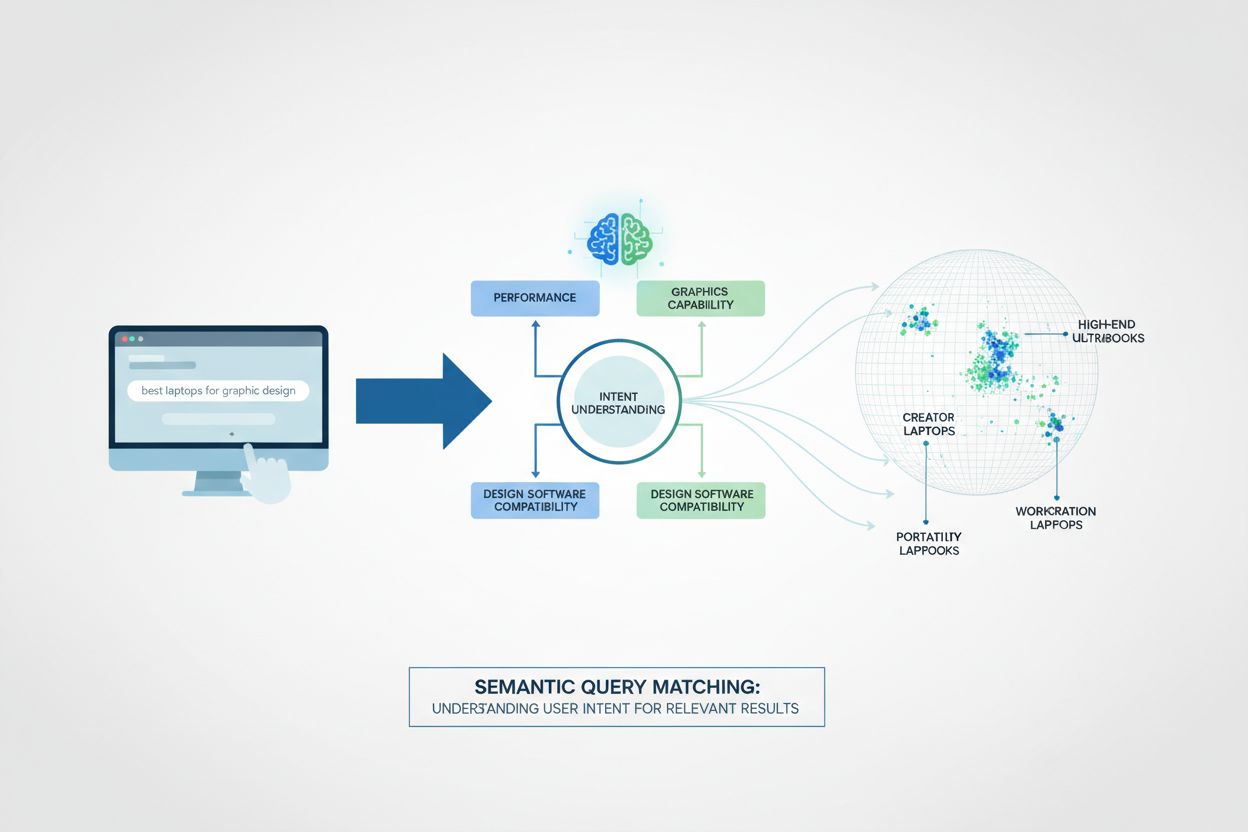
A correspondência semântica de consulta opera por meio de um processo técnico em múltiplas camadas que transforma tanto as consultas quanto os documentos em representações matemáticas chamadas embeddings. O sistema primeiro processa a linguagem natural com algoritmos de PLN para extrair significado e, então, converte essa compreensão em vetores de alta dimensão que capturam relações semânticas. Um mecanismo de pontuação de similaridade compara o vetor da consulta com os vetores dos documentos para classificar os resultados por relevância, e não pela frequência de palavras-chave. Essa abordagem permite que o sistema entenda sinônimos, contexto e intenção do usuário sem programação explícita para cada variação.
| Aspecto | Busca Tradicional por Palavra-Chave | Correspondência Semântica de Consulta |
|---|---|---|
| Método de Correspondência | Correspondência exata ou parcial de palavras | Pontuação de similaridade baseada em significado |
| Compreensão de Intenção | Limitada; depende da presença de palavras-chave | Análise contextual profunda da intenção do usuário |
| Tratamento de Sinônimos | Exige listas manuais de sinônimos | Reconhece automaticamente equivalentes semânticos |
| Consciência de Contexto | Mínima; trata palavras isoladamente | Abrangente; analisa relações entre termos |
| Capacidade de Aprendizado | Estático; não melhora com o uso | Dinâmico; melhora com atualizações e feedback do modelo |
A base tecnológica da correspondência semântica de consulta repousa em vários componentes interconectados que atuam de forma conjunta:
A correspondência semântica de consulta tornou-se indispensável em diversos setores e aplicações. No e-commerce, ajuda clientes a encontrarem produtos usando descrições em linguagem natural em vez de nomes exatos — ao pesquisar “tênis confortáveis para corrida”, retorna calçados esportivos relevantes mesmo sem essas palavras exatas. Sistemas de atendimento ao cliente usam correspondência semântica para direcionar solicitações aos departamentos apropriados entendendo o problema subjacente, e não apenas com base em palavras-chave. Plataformas de busca corporativa permitem que funcionários encontrem documentos internos por meio de consultas conceituais. Sistemas modernos de IA como ChatGPT, Perplexity e Google AI Overviews dependem fortemente da correspondência semântica para entender a intenção do usuário e recuperar dados relevantes de treinamento. Mecanismos de recomendação de conteúdo utilizam correspondência semântica para sugerir artigos, vídeos e produtos baseados em significado, e não apenas em tags explícitas.
As vantagens da correspondência semântica de consulta elevam significativamente a experiência do usuário e a eficácia dos sistemas. Maior relevância garante que os usuários encontrem o que realmente procuram logo na primeira tentativa, reduzindo frustrações e repetições de busca. A tecnologia se destaca ao lidar com consultas ambíguas ou mal formuladas, entendendo a intenção mesmo quando o usuário não expressa exatamente o que precisa. O entendimento de sinônimos elimina a necessidade de o usuário adivinhar a terminologia correta — ao buscar por “automóvel”, “carro” ou “veículo”, sistemas semânticos reconhecem como equivalentes. Essa capacidade gera maior engajamento, pois os usuários descobrem conteúdos mais relevantes, resultando em mais satisfação e conversão. A experiência superior do usuário proporcionada pela correspondência semântica tornou-se indispensável em produtos digitais modernos.
Apesar das vantagens, a correspondência semântica de consulta enfrenta desafios técnicos e práticos significativos. A complexidade computacional ainda é alta; processar vetores de alta dimensão e calcular similaridades entre milhões de documentos exige muito processamento e infraestrutura. Preocupações com privacidade de dados surgem porque sistemas semânticos analisam detalhadamente as consultas dos usuários, levantando questões sobre retenção e segurança dos dados. O treinamento dos modelos exige grandes volumes de dados de alta qualidade e muitos recursos computacionais, o que dificulta a adoção por organizações menores. A tecnologia traz risco de interpretações equivocadas — modelos semânticos podem retornar resultados irrelevantes com confiança se não entenderem o contexto ou encontrarem consultas fora do domínio. O clássico dilema entre latência e precisão implica que análises semânticas mais sofisticadas demoram mais, podendo prejudicar o desempenho em buscas em tempo real.
O AmICited.com utiliza correspondência semântica de consulta para revolucionar como marcas monitoram sua presença em conteúdos e respostas gerados por IA. Em vez de apenas rastrear menções exatas do nome da marca, a plataforma do AmICited.com entende a intenção e o contexto de como sistemas de IA mencionam marcas, produtos e empresas no ChatGPT, Perplexity, Google AI Overviews e outras grandes plataformas de IA. O enfoque semântico permite detectar referências indiretas, menções comparativas e citações contextuais que o monitoramento por palavras-chave não captaria. Essa compreensão mais profunda oferece às marcas visibilidade abrangente sobre como seus produtos são apresentados aos usuários — inteligência essencial para manter reputação e posição no mercado. As capacidades semânticas do AmICited.com funcionam de forma integrada a ferramentas complementares como o FlowHunt.io, especializado em otimização de fluxos de trabalho, criando um ecossistema completo para monitoramento de IA e inteligência de marcas. Ao entender o significado semântico por trás das respostas geradas por IA, o AmICited.com ajuda marcas a identificar oportunidades, corrigir equívocos e otimizar sua presença no universo da informação impulsionada por IA.
A correspondência semântica de consulta continua evoluindo para implementações mais sofisticadas e eficientes. A correspondência multimodal representa a fronteira, permitindo que sistemas compreendam consultas e as correlacionem com imagens, vídeos e áudios usando estruturas semânticas unificadas. Pesquisadores desenvolvem modelos de embeddings mais eficientes que mantêm compreensão semântica com menor demanda computacional, tornando a busca semântica acessível até para pequenas empresas. Personalização aprimorada permitirá que sistemas semânticos adaptem a correspondência levando em conta preferências individuais, histórico de busca e contexto. Integração com sistemas de IA emergentes expandirá a correspondência semântica além da busca tradicional, alcançando IA conversacional, assistentes de voz e sistemas autônomos. Esforços de padronização estão estabelecendo frameworks e benchmarks comuns para correspondência semântica, facilitando interoperabilidade e comparação entre plataformas. À medida que essas tecnologias amadurecem, a correspondência semântica de consulta se tornará uma expectativa padrão, e não mais um recurso premium.
A correspondência semântica entende intenção e significado, enquanto a pesquisa por palavra-chave busca correspondências exatas de palavras. A correspondência semântica pode encontrar resultados relevantes mesmo quando as palavras-chave exatas não são usadas, reconhecendo que diferentes frases podem expressar o mesmo conceito.
Embeddings vetoriais convertem texto em representações numéricas que capturam significado. Conceitos semelhantes são posicionados próximos no espaço vetorial, permitindo que o sistema encontre conteúdos semanticamente relacionados ao calcular distâncias entre vetores.
Processamento de Linguagem Natural (PLN), modelos de aprendizado de máquina como BERT e GPT, embeddings vetoriais e grafos de conhecimento trabalham juntos para entender a intenção da consulta e relacioná-la ao conteúdo relevante.
Sim, a correspondência semântica é excelente em entender sinônimos e variações semânticas. Reconhece que 'carro', 'veículo' e 'automóvel' têm significados semelhantes e pode corresponder consultas usando qualquer um desses termos sem configuração manual.
Ela entrega resultados mais relevantes de forma mais rápida, reduz a necessidade de os usuários refinarem suas buscas e permite a formulação de consultas mais natural e conversacional, sem exigir correspondência exata de palavras-chave.
Os desafios principais incluem complexidade computacional, preocupações com privacidade de dados, necessidade de treinamento contínuo do modelo, potencial de interpretações equivocadas e o equilíbrio entre precisão e velocidade de resposta.
A correspondência semântica permite que sistemas como o AmICited.com entendam a intenção por trás do conteúdo gerado por IA e rastreiem menções à marca mesmo quando nomes exatos não são usados, proporcionando monitoramento abrangente de visibilidade da marca.
Embora a correspondência semântica esteja se tornando mais comum, ambas as abordagens coexistem. Muitos sistemas modernos usam abordagens híbridas, combinando compreensão semântica com correspondência de palavras-chave para resultados ótimos.
O AmICited.com usa correspondência semântica de consulta para rastrear menções à sua marca no ChatGPT, Perplexity e Google AI Overviews — entendendo não apenas o que é dito, mas a intenção por trás disso.
A busca semântica interpreta o significado e o contexto da consulta usando PLN e aprendizado de máquina. Saiba como ela difere da busca por palavras-chave, impu...
Descubra como a pesquisa semântica utiliza IA para compreender a intenção e o contexto do usuário. Veja como ela difere da busca por palavras-chave e por que é ...
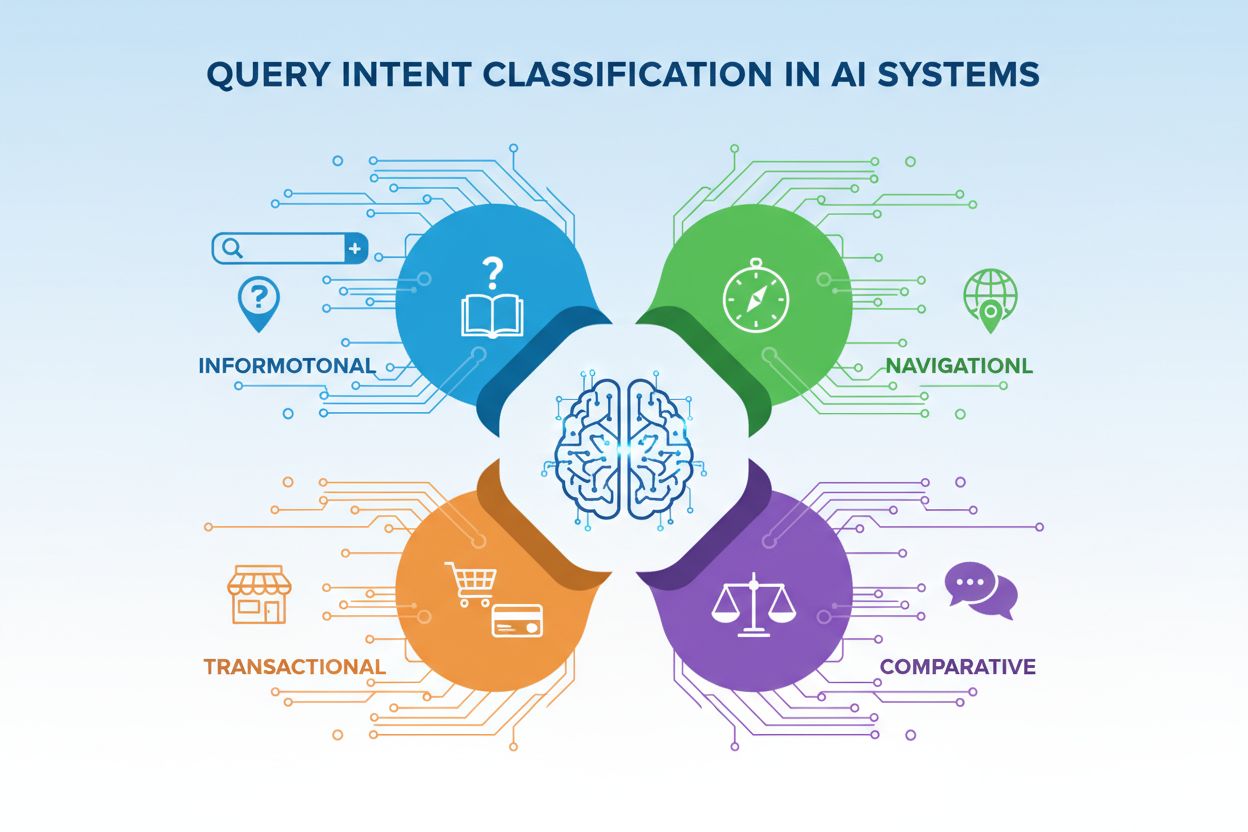
Saiba mais sobre Classificação de Intenção de Consulta – como sistemas de IA categorizam consultas de usuários por intenção (informacional, navegacional, transa...
Consentimento de Cookies
Usamos cookies para melhorar sua experiência de navegação e analisar nosso tráfego. See our privacy policy.